
Fork-processor
Kopierar data till två identiska utdata.
Fork-processorn kan användas för att kopiera indataflödet och mata ut upp till tio identiska utdataflöden som kan bearbetas på olika sätt beroende på dina behov.
Användning
Fork-processorn kräver ett indataflöde och minst två utdataflöden.
Egenskaper
Fork-processorn kräver ingen konfiguration.
För att byta namn på processorn eller redigera dess beskrivning, håll muspekaren över namnet eller beskrivningen som ska ändras i panelen Egenskaper och klicka på ikonen ![]() Redigera.
Redigera.
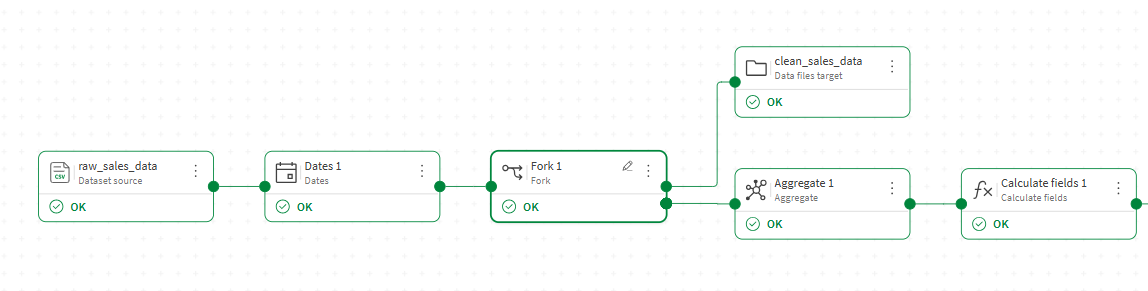
Exempel: Exportera ett mellanliggande tillstånd för dataflödet
I det här exemplet har du ett flöde som rensar och normaliserar råa försäljningsdata. Du vill spara de rensade data i ett mellanliggande steg som en fil, medan resten av flödet fortsätter genom ytterligare processorer som till exempel en aggregering.
-
I dataflödesredigeraren lägger du till en Fork-processor efter den sista processorn som producerar det mellanliggande tillstånd du vill exportera.
-
Anslut en utdata från Fork-processorn till en målnod och konfigurera den för att spara de mellanliggande data som en fil, till exempel clean_sales_data.qvd.
-
Anslut den andra utdata till nästa processor i ditt huvudflöde, till exempel en Aggregate-processor, och fortsätt att lägga till processorer och ett mål för att slutföra flödet.
-
Klicka på Kör flöde.
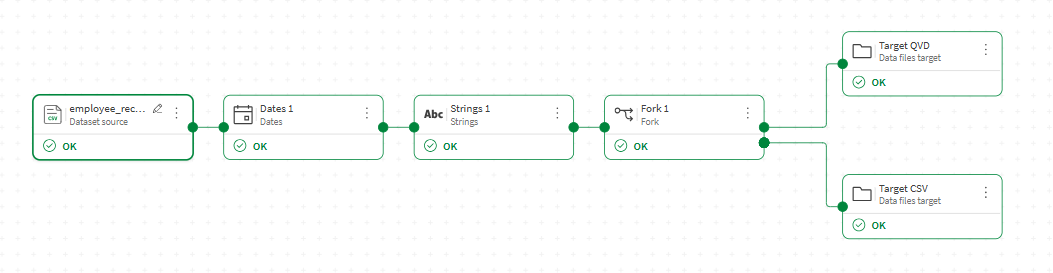
Exempel: Exportera ett dataflöde till två olika utdataformat
I det här exemplet vill du exportera samma datauppsättning som en .qvd-fil för användning i Qlik-analysappar, och som en .csv-fil för att dela med externa intressenter.
-
I dataflödesredigeraren lägger du till en Fork-processor efter den sista processorn i ditt flöde.
-
Anslut en utdata från Fork-processorn till ett Datafiler-mål. Konfigurera det för att exportera som en .qvd-fil.
-
Anslut den andra utdata till ett annat Datafiler-mål. Konfigurera det för att exportera som en .csv-fil.
-
Klicka på Kör flöde.