
Bygga upp ett dataflöde
Skapa ett dataflöde
Börja med att skapa ett nytt dataflöde.
-
I menyn Start väljer du Analys > Skapa eller Analys > Förbereda data.
-
Klicka på Dataflöde.
Dialogen Skapa ett nytt dataflöde öppnas.
-
I motsvarande fält anger du ett Namn för ditt dataflöde.
-
Välj i den motsvarande listrutan i vilket Utrymme du vill spara dataflödet.
-
Lägg till en Beskrivning för att dokumentera syftet med dataflödet.
-
Lägg till några Taggar i dataflödet för att göra den lättare att hitta.
-
Du kan även markera kryssrutan Öppna dataflöde för att visa dataflödet direkt när det har skapats.
-
Klicka på Skapa.
Ditt tomma dataflöde öppnas och du kommer till fliken Översikt i navigeringsrubriken. Det nya dataflödet kan också hittas senare på sidan Analytics > Home i Qlik Cloud.
För mer information om vilken information du kan hitta i översikten över ditt dataflöde, se Navigering av dataflöden.
För att börja utforma ditt dataflöde går du till fliken Redigerare i navigeringsrubriken.
Välj en källa
Den första byggstenen i ditt dataflöde är den källa som innehåller de data du vill förbereda. Du kan använda alla data från din katalog eller från en koppling.
Lägga till data från en datauppsättning
Datauppsättningar som lagras i din katalog kan baseras på filer (.qvd,.xls,.csv,.parquet,.json osv.) eller tabeller från databaser och datalager. Se Filformat för en lista över format som stöds.
Datauppsättningar som skapats i Qlik Talend Data Integration som en del av ett dataprojekt kan också användas för att skapa dataflöden.
Så här väljer du en datauppsättning som källa för ditt dataflöde:
-
Dra en Datauppsättningskälla från fliken Källor i den vänstra panelen och släpp den på arbetsytan.
Fönstret Datakatalog öppnas, där du kan bläddra efter tidigare uppladdade datauppsättningar eller klicka på Ladda upp datafil för att bläddra efter filer på din dator och ladda upp dem direkt.
Anteckning om varningNär du laddar upp stora filer som är större än 300 MB kan processen ta lite tid. Stäng inte fönstret, utan framstegen visas på en snurra som kan se tom ut i början. -
Välj data som du vill ladda.
-
Om du vill ladda all data från en datamängd eller dataprodukt markerar du kryssrutan som motsvarar den raden.
-
Om du vill ladda vissa datamängder från en dataprodukt klickar du på pilen bredvid dataproduktens namn. Välj de datamängder du vill ladda.
-
För att ladda vissa tabeller eller fält från en datauppsättning klickar du på Visa fält bredvid datauppsättningens namn. Välj fälten från tabellerna som du vill ladda.
-
För att ladda upp filer från din dator klickar du på Ladda upp fil för att bläddra efter filer på din dator och lägga till dem i listan över tillgängliga datauppsättningar.
Anteckning om informationDu kan filtrera data efter typ (datauppsättningar eller dataprodukter). Dataprodukter är endast tillgängliga i vissa prenumerationer. Mer information finns i Working with data products. -
-
Använd sökfunktionen och filter och markera kryssrutan framför en eller flera datauppsättningar från listan och klicka på Nästa.
När du väljer en datauppsättning som lagts till från en koppling i katalogen och flera kopplingar matchar kan du använda en listruta för att välja den specifika koppling som ska användas.
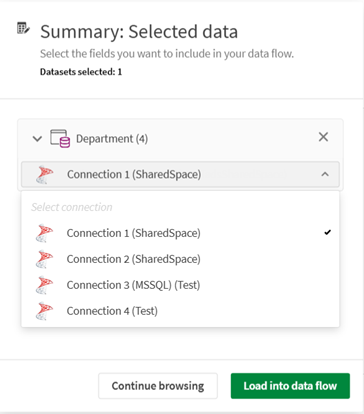
-
På fliken Sammanfattning kan du granska de datauppsättningar du har valt, kontrollera vilka fält de innehåller och utesluta vissa om du vill. Klicka på Ladda till dataflöde.
Källan eller källorna läggs till på arbetsytan, med en varning om att du måste koppla dem till andra noder.

När en källa har placerats på arbetsytan kan du klicka på den och öppna panelen Egenskaper för att redigera de valda fälten om det behövs, till exempel om källans schema har uppdaterats.
Ladda upp och konfigurera en csv-fil
Om du använder en csv-filsdatauppsättning som källa, antingen tidigare uppladdad till din katalog eller direkt uppladdad under processen, och data inte visas korrekt i förhandsgranskningen, kan det betyda att filen inte är korrekt formaterad.
Till exempel visas dessa kunddata som använder kommatecken som separator i en enda kolumn.

Filen var antingen felaktigt formaterad eller så upptäcktes inte separatorn korrekt under uppladdningen. För att felsöka det här problemet måste du gå till inställningarna för datauppsättningen.
-
Välj Analyser > Katalog från Start-menyn.
-
Öppna datauppsättningen för att fixa.
I översikten över datauppsättningen kan du se en varning som säger att det finns ett potentiellt formateringsfel.
-
Klicka på länken till Inställningar för filformat i varningsmeddelandet eller använd menyn Fler åtgärder längst upp till höger i översikten.
Du kan se att avgränsaren felaktigt har angetts som Semikolon.

-
Välj Komma i listrutan för Avgränsare.
Med den förväntade avgränsaren visar förhandsgranskningen nu de olika fälten på rätt sätt.

-
Klicka på Spara.
-
Tillbaka i ditt dataflöde, ta bort den föråldrade källan om arbetsytan inte var tom, och lägg till den igen. Den här gången kommer källan att återspegla rätt datauppsättningskonfiguration.
Lägga till data från en koppling
Qlik Cloud och dataflöden stöder en mängd olika kopplingar till datakällor. Se Lista över datakällor som stöds för mer information.
De enda kopplingstyper som för närvarande inte stöds är följande:
Så här väljer du en koppling som källa för ditt dataflöde:
-
Dra en Kopplingskälla från fliken Källor i den vänstra panelen och släpp den på arbetsytan.
Fönstret Välj koppling öppnas där du kan bläddra efter tidigare skapade kopplingar eller klicka på Skapa koppling för att definiera en ny koppling direkt efter autentiseringen.
-
Använd sökfunktionen och filter och markera kryssrutan framför en eller flera kopplingar från listan och klicka på Nästa.
-
Beroende på koppling kan du bläddra i filer, ange en sökväg till dina data eller välja tabeller från en databas.
-
När du har valt datakälla klickar du på Spara eller Slutför.
Källan läggs till på arbetsytan, med en varning om att du måste koppla den till en annan nod.

När en källa har placerats på arbetsytan kan du klicka på den och öppna panelen Egenskaper för att redigera de valda fälten om det behövs, till exempel om källans schema har uppdaterats.
Lägg till processorer
Processorer är de byggstenar som innehåller de olika förberedelsefunktioner som finns tillgängliga i ett dataflöde. De tar emot inkommande data och returnerar förberedda data till nästa steg i flödet. Processorer gör att du kan utföra komplexa extraktioner, förbättringar och rensningar av olika data med förhandsgranskning i realtid. Se hela Processorer för dataflöde för mer information om tillgängliga funktioner.
För att koppla en första processor till din datakälla:
-
Du kan antingen:
-
Dra den processor du vill använda från fliken Processorer i den vänstra panelen och släpp den på arbetsytan bredvid din källa.

Du måste göra en manuell koppling mellan källan och processorn. Skapa en länk genom att klicka på punkten till höger om källnoden, håll kvar och dra länken till punkten till vänster om processornoden.

-
Klicka på källans åtgärdsmeny, välj Lägg till processor och klicka på den processor du vill använda.

Processorn placeras på arbetsytan och kopplas automatiskt till källan.
-
-
Klicka på processorn för att börja konfigurera den i den högra panelen.
Vilka funktioner som finns tillgängliga och vilka parametrar som ska konfigureras beror på varje processor. Se dokumentationen för den enskilda processorn för mer information.
-
Klicka på Spara.
-
Lägg till och koppla in så många processorer som behövs för att förbereda dina data.
Aktivera omkopplaren Förhandsgranska data i panelen Förhandsgranska för att se effekterna av en processor på ett urval av dina data. Klicka på kugghjulsikonen för att öppna förhandsgranskningen Inställningar och konfigurera urvalsstorleken upp till 10000 rader. Du kan också aktivera Skript-omkopplaren för att titta på Qlik Skripts motsvarighet till ditt dataflöde vid den här datapunkten.
Välja ett mål
För att avsluta dataflödet måste du koppla den sista processorn till en målnod. Du kan välja mellan två olika typer av mål:
-
Datafiler för filer som lagras i din katalog i Qlik Cloud.
-
Kopplingar för att skriva i en extern källa läggs till som koppling i Qlik Cloud.
Båda alternativen gör att du kan exportera de förberedda data som en .qvd-, .parquet-, .txt- eller .csv-fil.
För att koppla ett mål till resten av flödet:
-
Du kan antingen:
-
Dra den måltyp du vill använda från fliken Mål i den vänstra panelen och släpp den på arbetsytan bredvid din senaste processor.

Koppla den sista processorn manuellt till målet på samma sätt som du kopplat processorer tidigare.
-
Klicka på den sista processorns åtgärdsmeny, välj Lägg till mål och klicka på det mål som du vill använda.

-
-
Klicka på målet för att börja konfigurera det i den högra panelen.
Anteckning om informationNär det gäller Datafiler kan du skriva i en specifik mapp på önskat utrymme. Om du t.ex. har skapat en mapp som heter mapp_namn i ditt personliga utrymme använder du mapp_namn/data_flow_output.qvd som filnamn för ditt mål. Den resulterande filen kommer att skickas direkt till din mapp. -
Klicka på Spara.
Med ett minimum av en källa, ett mål och en valfri processor kan dataflödet nu köras.
Köra dataflödet
När alla noder i ditt dataflöde är kopplade, konfigurerade och markerade som OK, visar en grön bock att dataflödet anses vara giltigt och kan köras. I det här läget kan du använda knappen Förhandsgranska skript uppe till höger på arbetsytan för att titta på hela det skript som kommer att genereras bakom kulisserna.

-
Klicka på Kör flöde för att börja bearbeta data.
Ett meddelande öppnas för att visa status för körningen.
-
När flödet har slutförts korrekt kan de förberedda data som har matats ut hittas på olika platser enligt målet:
-
I din Katalog bland dina andra tillgångar och i delavsnittet Utdata i Dataflödesöversikten för datafiler
-
I delavsnittet Utdata i Dataflödesöversikten för kopplingsbaserade datauppsättningar.
Om flödet misslyckas kan du öppna körloggen för att få hjälp med att identifiera vad som gick fel.
-
Du kan nu använda dessa förberedda data som ren källa för att mata ett Qlik Predict-experiment, eller i en visualiseringsapplikation.