
Procesor Fork
Duplikuje dane do dwóch identycznych wyjść.
Procesor Fork może być użyty do zduplikowania przepływu wejściowego i wygenerowania do dziesięciu identycznych przepływów wyjściowych, które mogą być przetwarzane w różny sposób w zależności od potrzeb.
Użycie
Procesor Fork wymaga jednego przepływu wejściowego i co najmniej dwóch przepływów wyjściowych.
Właściwości
Procesor Fork nie wymaga żadnej konfiguracji.
Aby zmienić nazwę procesora lub edytować jego opis, wskaż myszą nazwę lub opis do zmiany w panelu Właściwości i kliknij ikonę ![]() Edytuj.
Edytuj.
Przykład: Eksportowanie stanu pośredniego przepływu danych
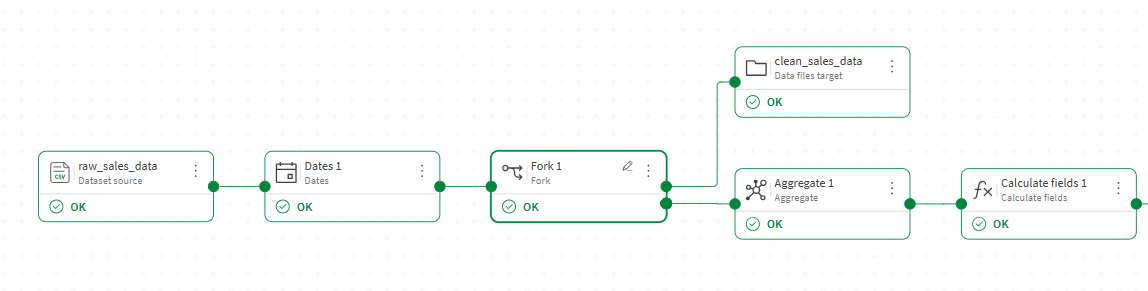
W tym przykładzie masz przepływ, który czyści i normalizuje surowe dane dotyczące sprzedaży. Chcesz zapisać wyczyszczone dane na etapie pośrednim jako plik, podczas gdy reszta przepływu przechodzi przez kolejne procesory, takie jak agregacja.
-
W edytorze przepływu danych dodaj procesor Fork po ostatnim procesorze, który generuje stan pośredni, który chcesz wyeksportować.
-
Podłącz jedno wyjście procesora Fork do węzła docelowego i skonfiguruj go tak, aby zapisać dane pośrednie jako plik, na przykład clean_sales_data.qvd.
-
Podłącz drugie wyjście do następnego procesora w głównym przepływie, na przykład procesora Agreguj, i kontynuuj dodawanie procesorów oraz celu, aby ukończyć przepływ.
-
Kliknij Uruchom przepływ.
Przykład: Eksportowanie przepływu danych do dwóch różnych formatów wyjściowych
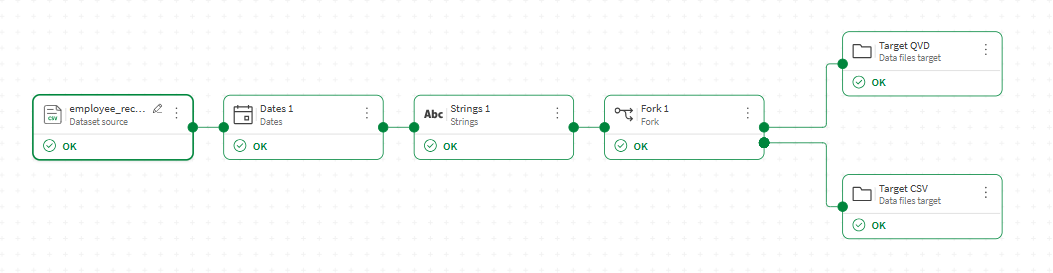
W tym przykładzie chcesz wyeksportować ten sam zestaw danych jako plik .qvd do użytku w aplikacjach analitycznych Qlik oraz jako plik .csv, aby udostępnić go zewnętrznym interesariuszom.
-
W edytorze przepływu danych dodaj procesor Fork po ostatnim procesorze w przepływie.
-
Podłącz jedno wyjście procesora Fork do celu Pliki danych. Skonfiguruj go tak, aby eksportować jako plik .qvd.
-
Podłącz drugie wyjście do innego celu Pliki danych. Skonfiguruj go tak, aby eksportować jako plik .csv.
-
Kliknij Uruchom przepływ.