
Qlik-skriptprocessor
Skapar eller transformerar indata med hjälp av Qlik-skript.
Qlik-skript-processorn låter dig ange Qlik-skript direkt i en textredigerare för att förbereda data, eller ladda data när den används som indata. Den riktar sig till mer avancerade användare, och du kan dra nytta av hela Qlik-syntaxen om du föredrar att koda vissa åtgärder manuellt när du manipulerar tabeller.
Användning
-
För att använda Skript-processorn i ett dataflöde måste koden som du lägger till i redigeraren vara konsekvent med schemat för inkommande data och de förberedelseåtgärder som har utförts fram till denna punkt. Dessutom måste skriptet följa vissa regler:
-
Skriptet måste innehålla en resident-sats för att använda tabellen som kommer från indataflödet.
resident tablenameMer information finns i Load.
-
Du måste inkludera en NoConcatenate-sats.
NoConcatenate LOAD A,BMer information finns i NoConcatenate.
-
När du har lagt till skriptet för den specifika åtgärd du vill utföra måste du inkludera en drop table-sats i slutet för att ta bort den inkommande tabellen och bara behålla de genererade utdata.
drop table tablenameMer information finns i Drop table.
- När du använder processorn som indatanod kan du ha högst två utdataflöden för att ladda två olika tabeller.
- När du använder processorn som en mellanliggande nod kan du ha flera indataflöden och högst två utdataflöden.
- Du kan använda högst 50 Qlik-skriptprocessorer i ett dataflöde.
Egenskaper
| Egenskap | Konfiguration |
|---|---|
| Skript |
Ange ditt Qlik-skript i textredigeraren som inkluderar följande platshållare med de nödvändiga satserna. Namnen på dina indatatabeller listas ovanför skriptredigeraren. De motsvarar de indata som är kopplade till processorn. Klicka på ett tabellnamn för att infoga det direkt i skriptet. |
För att byta namn på processorn eller redigera dess beskrivning, peka med musen över namnet eller beskrivningen som ska ändras i panelen Egenskaper och klicka på ikonen ![]() Redigera.
Redigera.
Använda den komprimerade vyn
I panelen på höger sida kan du utföra snabba uppdateringar av processorn utan att öppna hela redigeraren. Du kan:
-
Skriva text direkt i Skript.
-
Lägga till indatatabeller i skriptet genom att klicka på dem under Indatatabeller.
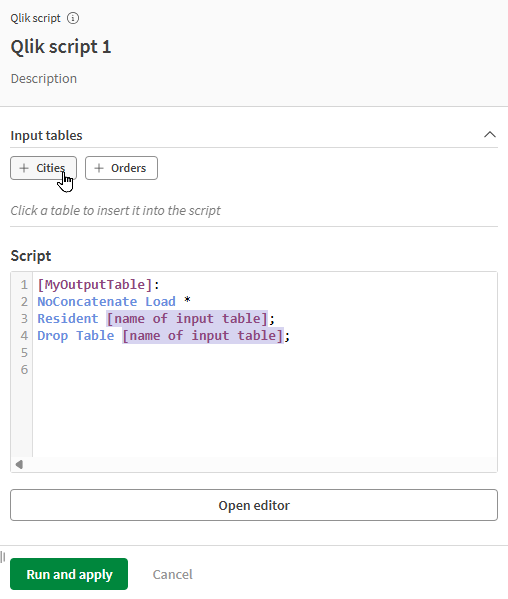
För fler alternativ och avancerad funktionalitet, öppna skriptredigeraren. Se Använda skriptredigeraren.
Använda skriptredigeraren
Genom att klicka på knappen Öppna redigerare i konfigurationspanelen öppnas en kraftfull Skriptredigerare som hjälper dig att skriva ditt Qlik-skript. Infoga enkelt tabeller, fältnamn eller funktioner, öppna dokumentation, infoga skript och kontrollera giltigheten för ditt skript.
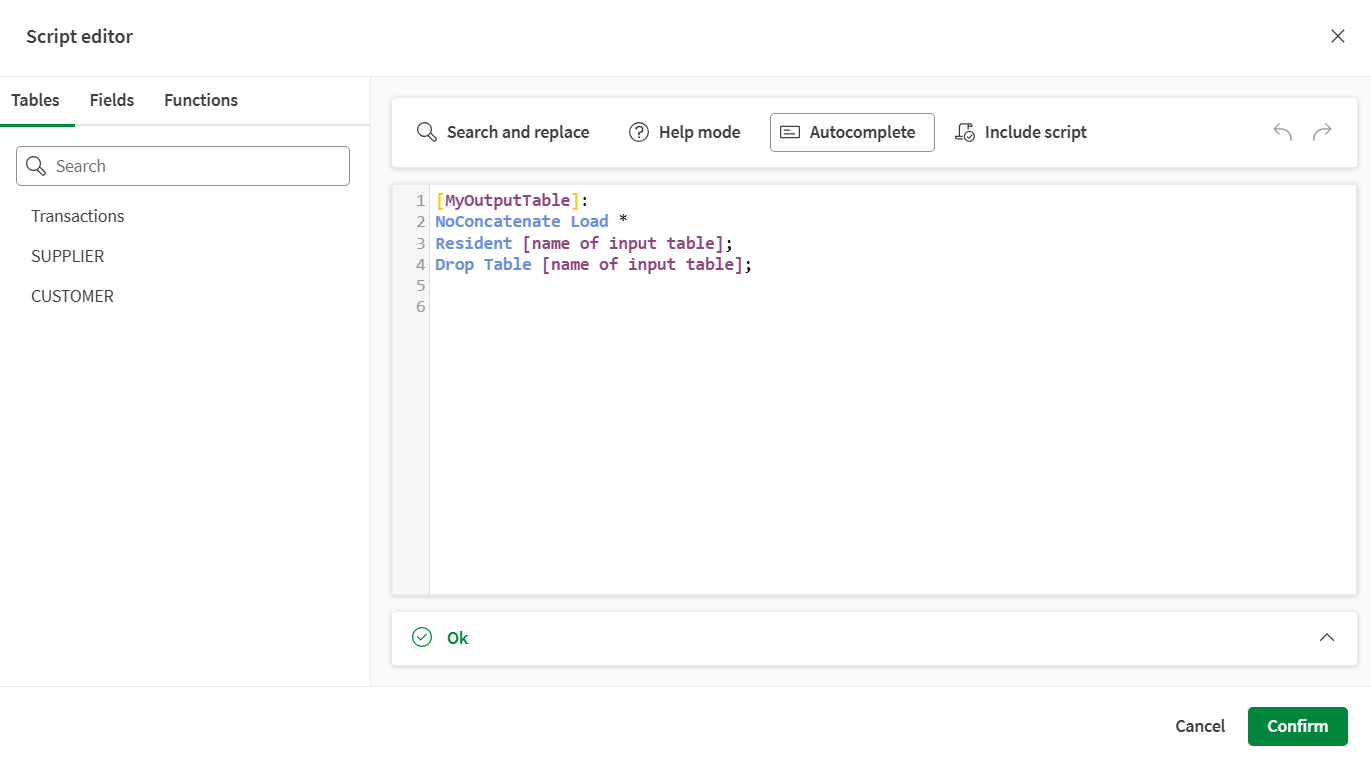
I den vänstra panelen kan du visa de tabeller och fält som för närvarande är laddade i ditt dataflöde och bläddra bland ett brett utbud av Qlik-skriptfunktioner. Den här panelen är organiserad i tre flikar:
-
Tabeller, där tabellerna som laddats i flödet listas. Peka med musen över något av tabellnamnen och klicka på + för att infoga det direkt i skriptet.
-
Fält, där de fält som är tillgängliga vid denna punkt i flödet listas. Peka med musen över något av fältnamnen och klicka på + för att infoga det direkt i uttrycket.
-
Funktioner, där du kan bläddra bland Qlik-funktioner. Du kan använda sökfältet för att leta efter en specifik funktion, eller använda listrutan Funktionskategori för att filtrera dem.
Peka med musen över någon av funktionerna och klicka på + för att infoga den direkt i uttrycket.
-
Om du väljer reglaget Förklaringsguide visas en kort beskrivning och en länk till dokumentationen när du klickar på en funktion.
-
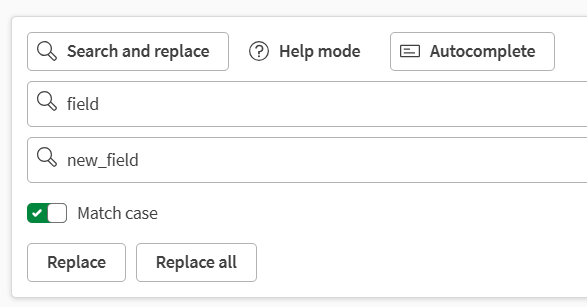
I den övre panelen kan du aktivera eller inaktivera tre verktyg för att hjälpa och vägleda dig när du skriver skript, använda en genväg för att infoga skript från andra filer, samt ångra- och gör om-knappar för att åtgärda eventuella misstag.
-
Sök och ersätt, för att automatiskt leta efter specifika värden och ersätta dem vid behov.
-
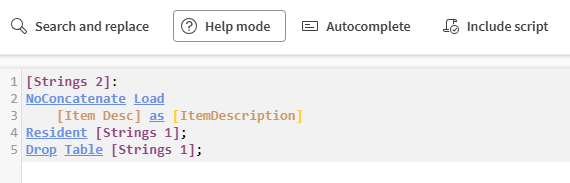
Hjälpläge, för att förvandla alla funktioner du skriver i skriptet till klickbara länkar som tar dig till dokumentationen.
-
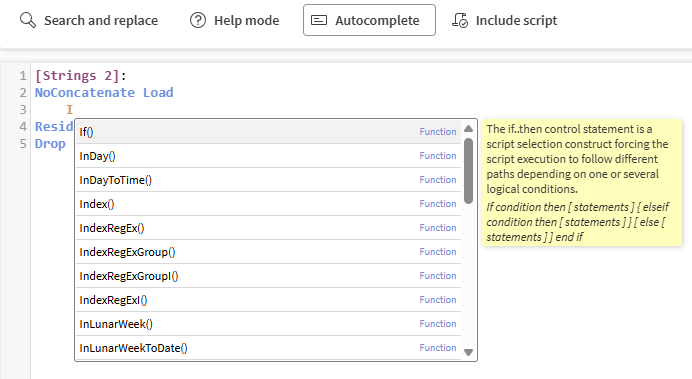
Komplettera automatiskt, för att visa förslag medan du skriver, med en kort beskrivning och ett exempel på en funktion.
-
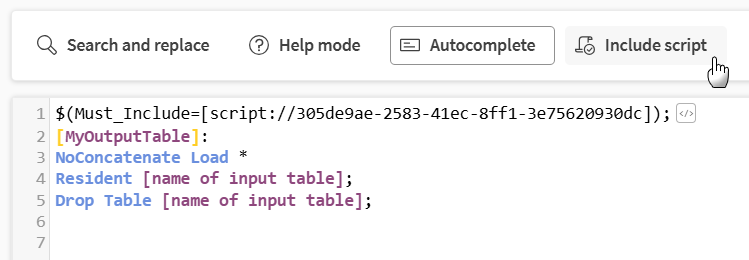
Inkludera skript, för att infoga skript. Se Infoga andra skript i laddningsskript.
Den nedre panelen beskriver eventuella fel med ditt skript, till exempel felaktiga fältnamn eller ogiltiga uttryck.
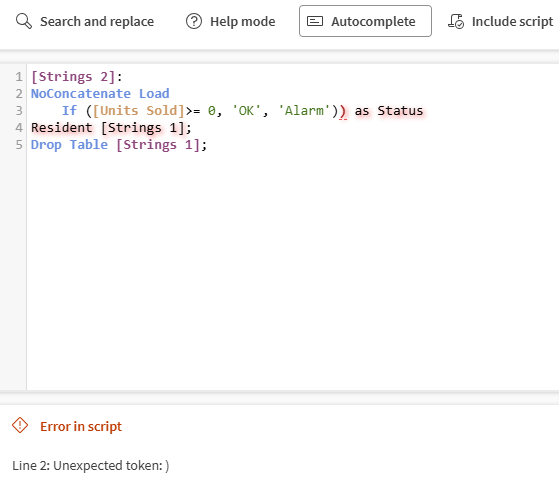
När statuspanelen visar ett grönt Ok är ditt skript giltigt. Klicka på Bekräfta för att använda detta skript för din Qlik-skriptprocessor och gå tillbaka till dataflödesredigeraren. Du kan sedan validera processorkonfigurationen.
Exempel
-
Ladda flera tabeller med samma schema till en indata för ditt flöde. Det här exemplet använder två .txt-filer från din katalog, med samma fält, men med olika innehåll. Dessutom kommer detta uttryck att lägga till ett fält för att spåra vilka data som kommer från vilken tabell, och generera ett heltal som id-nummer:
[MyTable_1]: LOAD 'table1' as source_table, [firstname], [lastname], [nationality] FROM [lib://DataFiles/MyTable_1.txt] (txt, codepage is 28591, embedded labels, delimiter is ',', msq); [MyTable_2]: CONCATENATE (MyTable_1) LOAD 'table2' as source_table, [firstname], [lastname], [nationality] FROM [lib://DataFiles/MyTable_2.txt] (txt, codepage is 28591, embedded labels, delimiter is ',', msq); [NewTable]: LOAD recno() as id, * RESIDENT MyTable_1; drop table MyTable_1;Mer information finns i Konkatenera.
-
Skapa en inline-tabell med redigerbara data som indata för ditt flöde:
MyTable: Load * Inline [ Country, Year, Sales Argentina, 2014, 66295.03 Argentina, 2015, 140037.89 Austria, 2014, 54166.09 Austria, 205,182739.87 ];Mer information finns i Använda inline-laddningar för att ladda data.
-
Ladda alla filer från en mapp som indata för ditt flöde. Det här exemplet itererar över alla filer med en angiven filändelse i en mapp och laddar dem i en enda tabell. Ersätt datakopplingsnamnet och mappsökvägen med dina egna värden, och justera filändelsen och formatinställningarna efter behov:
SET vFolderPath = 'lib://YourDataConnection/FolderName'; FOR EACH vFile IN filelist('$(vFolderPath)/*.csv') LOAD * FROM [$(vFile)] (txt, utf8, embedded labels, delimiter is ','); NEXTMer information finns i For each..next.
Fler exempel på skriptuttryck finns i Vanliga satser och Skript- och diagramfunktioner.