
Processore di script Qlik
Crea o trasforma gli input utilizzando lo script Qlik.
Il processore Qlik script consente di inserire direttamente lo script Qlik in un editor di testo per preparare i dati o caricare i dati quando utilizzato come input. Rivolto agli utenti più esperti, consente di trarre vantaggio dall'intera sintassi Qlik se si preferisce codificare manualmente determinate operazioni durante la manipolazione delle tabelle.
Utilizzo
-
Per utilizzare il processore Script in un flusso di dati, il codice aggiunto nell'editor deve essere coerente con lo schema dei dati in ingresso e con le azioni di preparazione eseguite fino a questo punto. Inoltre, lo script deve seguire alcune regole:
-
Lo script deve contenere un'istruzione resident per utilizzare la tabella proveniente dal flusso di input.
resident tablenamePer ulteriori informazioni, vedere Load.
-
È necessario includere un'istruzione NoConcatenate.
NoConcatenate LOAD A,BPer ulteriori informazioni, vedere NoConcatenate.
-
Dopo aver aggiunto lo script per l'operazione specifica che si desidera eseguire, è necessario includere un'istruzione drop table alla fine per eliminare la tabella in ingresso e mantenere solo l'output generato.
drop table tablenamePer ulteriori informazioni, vedere Drop table.
- Quando si utilizza il processore come nodo di input, è possibile avere un massimo di due flussi di output, per caricare due tabelle diverse.
- Quando si utilizza il processore come nodo intermedio, è possibile avere più flussi di input e un massimo di due flussi di output.
- È possibile utilizzare un massimo di 50 processori di script Qlik in un flusso di dati.
Proprietà
| Proprietà | Configurazione |
|---|---|
| Script |
Inserire lo script Qlik nell'editor di testo che include il seguente segnaposto con le istruzioni richieste. I nomi delle tabelle di input sono elencati sopra lo Script editor. Corrispondono agli input collegati al processore. Fare clic sul nome di una tabella per inserirlo direttamente nello script. |
Per rinominare il processore o modificarne la descrizione, posizionare il mouse sul nome o sulla descrizione da modificare nel pannello Proprietà e fare clic sull'icona ![]() Modifica.
Modifica.
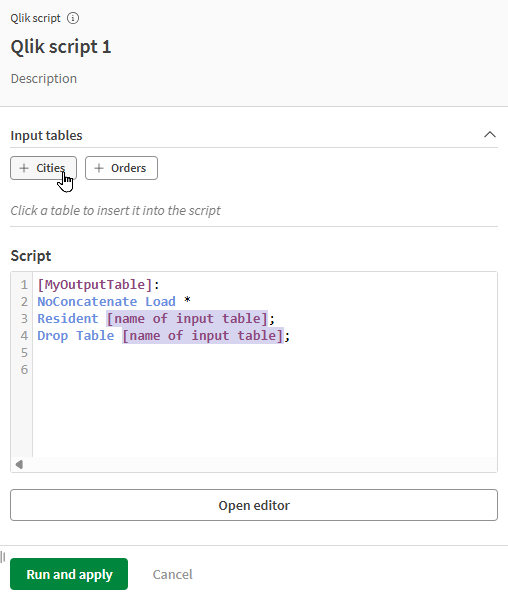
Utilizzo della vista condensata
Nel pannello sul lato destro, è possibile eseguire aggiornamenti rapidi al processore senza aprire l'editor completo. È possibile:
-
Digitare il testo direttamente nello Script.
-
Aggiungere tabelle di input allo script facendovi clic sotto Tabelle di input.
Per ulteriori opzioni e funzionalità avanzate, aprire lo Script editor. Vedere Utilizzo dello Script editor.
Utilizzo dello Script editor
Facendo clic sul pulsante Apri editor nel pannello di configurazione si apre un potente Script editor, per aiutarti a scrivere il tuo script Qlik. Inserisci facilmente tabelle, nomi di campi o funzioni, apri la documentazione, inserisci script e verifica la validità del tuo script.
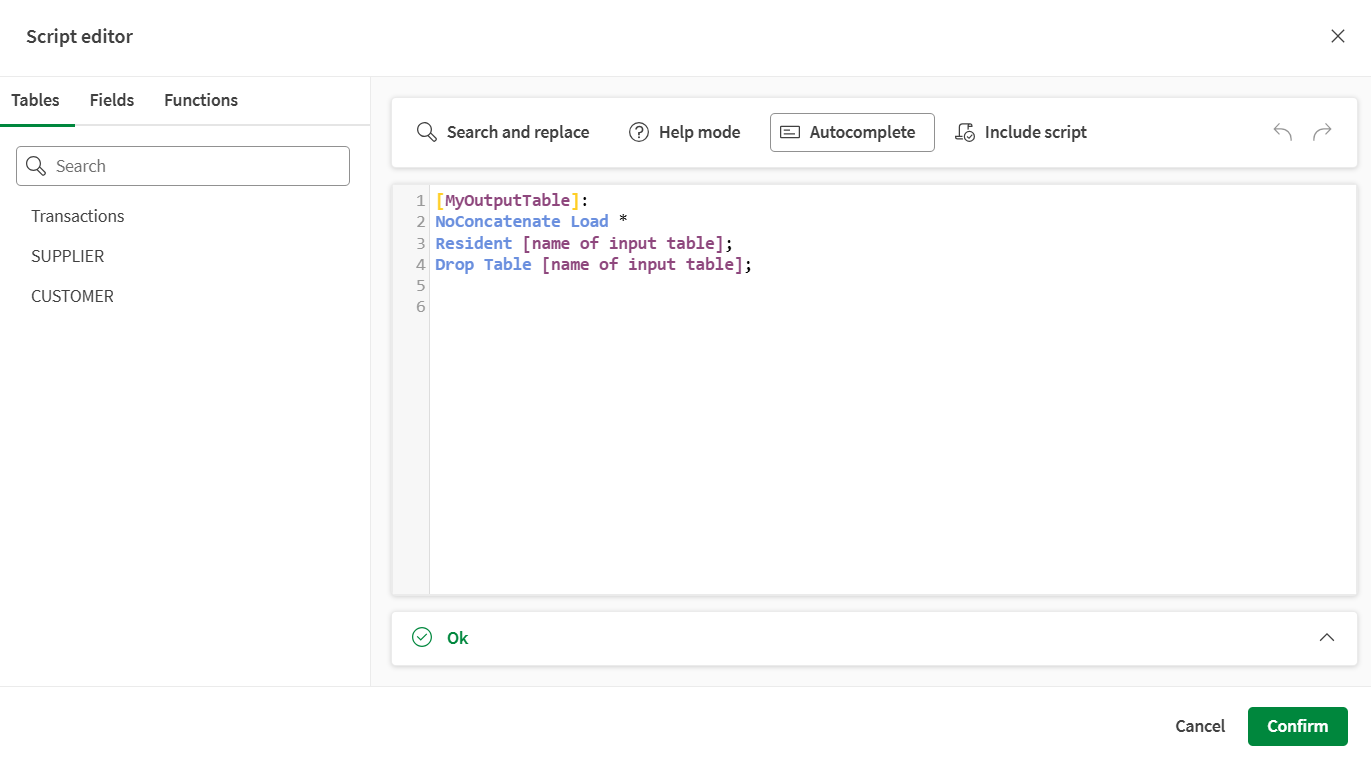
Nel pannello di sinistra, è possibile visualizzare le tabelle e i campi attualmente caricati nel flusso di dati e sfogliare un'ampia gamma di funzioni di script Qlik. Questo pannello è organizzato in tre schede:
-
Tabelle, dove sono elencate le tabelle caricate nel flusso. Posizionare il mouse su uno qualsiasi dei nomi delle tabelle e fare clic su + per inserirlo direttamente nello script.
-
Campi, dove sono elencati i campi disponibili in questo punto del flusso. Posizionare il mouse su uno qualsiasi dei nomi dei campi e fare clic su + per inserirlo direttamente nell'espressione.
-
Funzioni, dove è possibile sfogliare le funzioni Qlik. È possibile utilizzare il campo di ricerca per cercare una funzione specifica o utilizzare il menu a discesa Categoria funzione per filtrarle.
Posizionare il mouse su una qualsiasi delle funzioni e fare clic su + per inserirla direttamente nell'espressione.
-
Se si seleziona l'interruttore Guida esplicativa, verranno visualizzati una breve descrizione e un collegamento alla documentazione quando si fa clic su una funzione.
-
Nel pannello superiore, è possibile abilitare o disabilitare tre strumenti per aiutarti e guidarti durante la scrittura dello script, utilizzare una scorciatoia per inserire script da altri file, nonché i pulsanti Annulla e Ripeti per correggere potenziali errori.
-
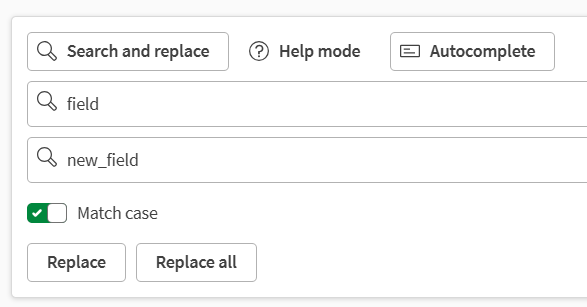
Cerca e sostituisci, per cercare automaticamente valori specifici e sostituirli se necessario.
-
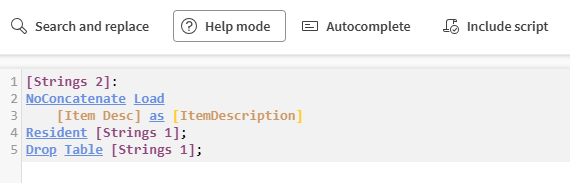
Modalità guida, per trasformare qualsiasi funzione scritta nello script in collegamenti selezionabili che porteranno alla documentazione.
-
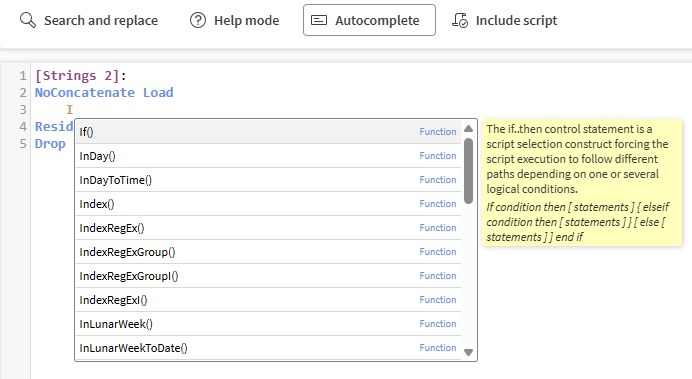
Completamento automatico, per visualizzare suggerimenti durante la digitazione, con una breve descrizione e un esempio di una funzione.
-
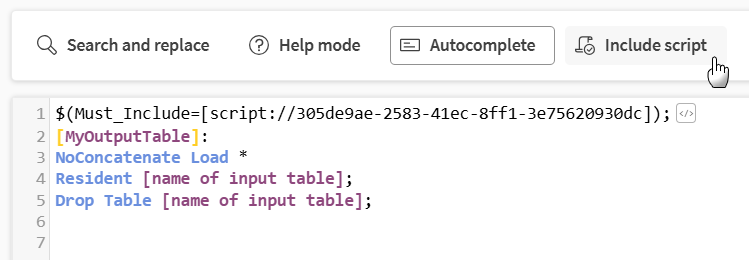
Includi script, per inserire script. Vedere Inserimento di altri script negli script di caricamento.
Il pannello inferiore descrive qualsiasi potenziale errore con lo script, come nomi di campi errati o espressioni non valide.
Quando il pannello di stato mostra un Ok verde, lo script è valido. Fare clic su Conferma per utilizzare questo script per il processore di script Qlik e tornare all'editor del flusso di dati. È quindi possibile convalidare la configurazione del processore.
Esempi
-
Caricamento di più tabelle con lo stesso schema in un unico input per il flusso. Questo esempio utilizza due file .txt dal catalogo, con gli stessi campi, ma con un contenuto diverso. Inoltre, questa espressione aggiungerà un campo per tracciare quali dati provengono da quale tabella e genererà un numero intero come numero ID:
[MyTable_1]: LOAD 'table1' as source_table, [firstname], [lastname], [nationality] FROM [lib://DataFiles/MyTable_1.txt] (txt, codepage is 28591, embedded labels, delimiter is ',', msq); [MyTable_2]: CONCATENATE (MyTable_1) LOAD 'table2' as source_table, [firstname], [lastname], [nationality] FROM [lib://DataFiles/MyTable_2.txt] (txt, codepage is 28591, embedded labels, delimiter is ',', msq); [NewTable]: LOAD recno() as id, * RESIDENT MyTable_1; drop table MyTable_1;Per ulteriori informazioni, vedere Concatenate.
-
Creare una tabella inline con dati modificabili come input per il flusso:
MyTable: Load * Inline [ Country, Year, Sales Argentina, 2014, 66295.03 Argentina, 2015, 140037.89 Austria, 2014, 54166.09 Austria, 205,182739.87 ];Per ulteriori informazioni, vedere Using inline loads to load data.
-
Caricamento di tutti i file da una cartella come input per il flusso. Questo esempio itera su tutti i file con un'estensione specificata in una cartella e li carica in un'unica tabella. Sostituire il nome di connessione dati e il percorso della cartella con i propri valori e regolare l'estensione del file e le impostazioni del formato in base alle necessità:
SET vFolderPath = 'lib://YourDataConnection/FolderName'; FOR EACH vFile IN filelist('$(vFolderPath)/*.csv') LOAD * FROM [$(vFile)] (txt, utf8, embedded labels, delimiter is ','); NEXTPer ulteriori informazioni, vedere For each..next.
Per ulteriori esempi di espressioni di script, vedere Regular statements e Script and chart functions.