
Procesor skryptu Qlik
Tworzy lub przekształca dane wejściowe za pomocą skryptu Qlik.
Procesor Skrypt Qlik umożliwia bezpośrednie wprowadzanie skryptu Qlik w edytorze tekstu w celu przygotowania danych lub ładowania danych, gdy jest używany jako wejście. Skierowany do bardziej zaawansowanych użytkowników, pozwala na korzystanie z całej składni Qlik, jeśli wolisz ręcznie kodować określone operacje podczas manipulowania tabelami.
Użycie
-
Aby użyć procesora Scrypt w przepływie danych, kod dodany w edytorze musi być zgodny ze schematem danych przychodzących oraz działaniami przygotowawczymi, które zostały wykonane do tego momentu. Ponadto skrypt musi przestrzegać pewnych zasad:
-
Skrypt musi zawierać instrukcję resident, aby użyć tabeli pochodzącej z przepływu wejściowego.
resident tablenameWięcej informacji zawiera temat Load.
-
Należy dołączyć instrukcję NoConcatenate.
NoConcatenate LOAD A,BWięcej informacji zawiera temat NoConcatenate.
-
Po dodaniu skryptu dla określonej operacji, którą chcesz wykonać, musisz na końcu dołączyć instrukcję drop table, aby usunąć tabelę przychodzącą i zachować tylko wygenerowane dane wyjściowe.
drop table tablenameWięcej informacji zawiera temat Drop table.
- Gdy procesor jest używany jako węzeł wejściowy, można mieć maksymalnie dwa przepływy wyjściowe, aby załadować dwie różne tabele.
- Gdy procesor jest używany jako węzeł pośredniczący, można mieć wiele przepływów wejściowych i maksymalnie dwa przepływy wyjściowe.
- W przepływie danych można użyć maksymalnie 50 procesorów skryptu Qlik.
Właściwości
| Właściwość | Konfiguracja |
|---|---|
| Scrypt |
Wprowadź swój skrypt Qlik w edytorze tekstu, który zawiera następujący symbol zastępczy z wymaganymi instrukcjami. Nazwy tabel wejściowych są wymienione nad edytorem skryptów. Odpowiadają one wejściom podłączonym do procesora. Kliknij nazwę tabeli, aby wstawić ją bezpośrednio do skryptu. |
Aby zmienić nazwę procesora lub edytować jego opis, wskaż myszą nazwę lub opis do zmiany w panelu Właściwości i kliknij ikonę ![]() Edytuj.
Edytuj.
Korzystanie z widoku skondensowanego
W panelu po prawej stronie można wykonywać szybkie aktualizacje procesora bez otwierania pełnego edytora. Możesz:
-
Wpisywać tekst bezpośrednio w polu Scrypt.
-
Dodawać tabele wejściowe do skryptu, klikając je w sekcji Tabele wejściowe.
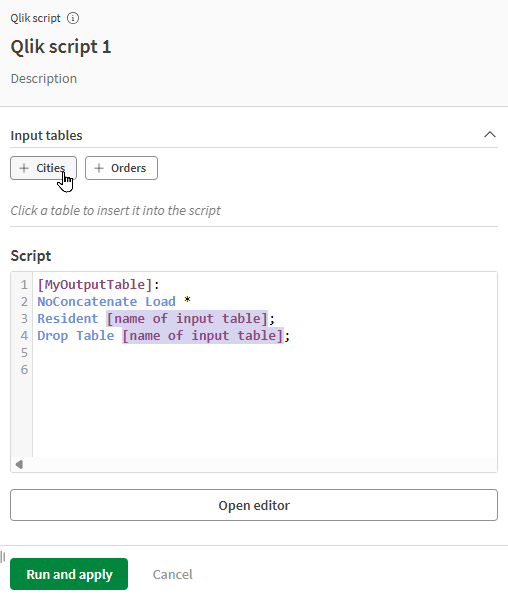
Aby uzyskać więcej opcji i zaawansowanych funkcji, otwórz edytor skryptów. Zobacz Korzystanie z edytora skryptów.
Korzystanie z edytora skryptów
Kliknięcie przycisku Otwórz edytor w panelu konfiguracji otwiera potężny Edytor skryptów, który pomaga w pisaniu skryptu Qlik. Z łatwością wstawiaj tabele, nazwy pól lub funkcje, otwieraj dokumentację, wstawiaj skrypty i sprawdzaj poprawność swojego skryptu.
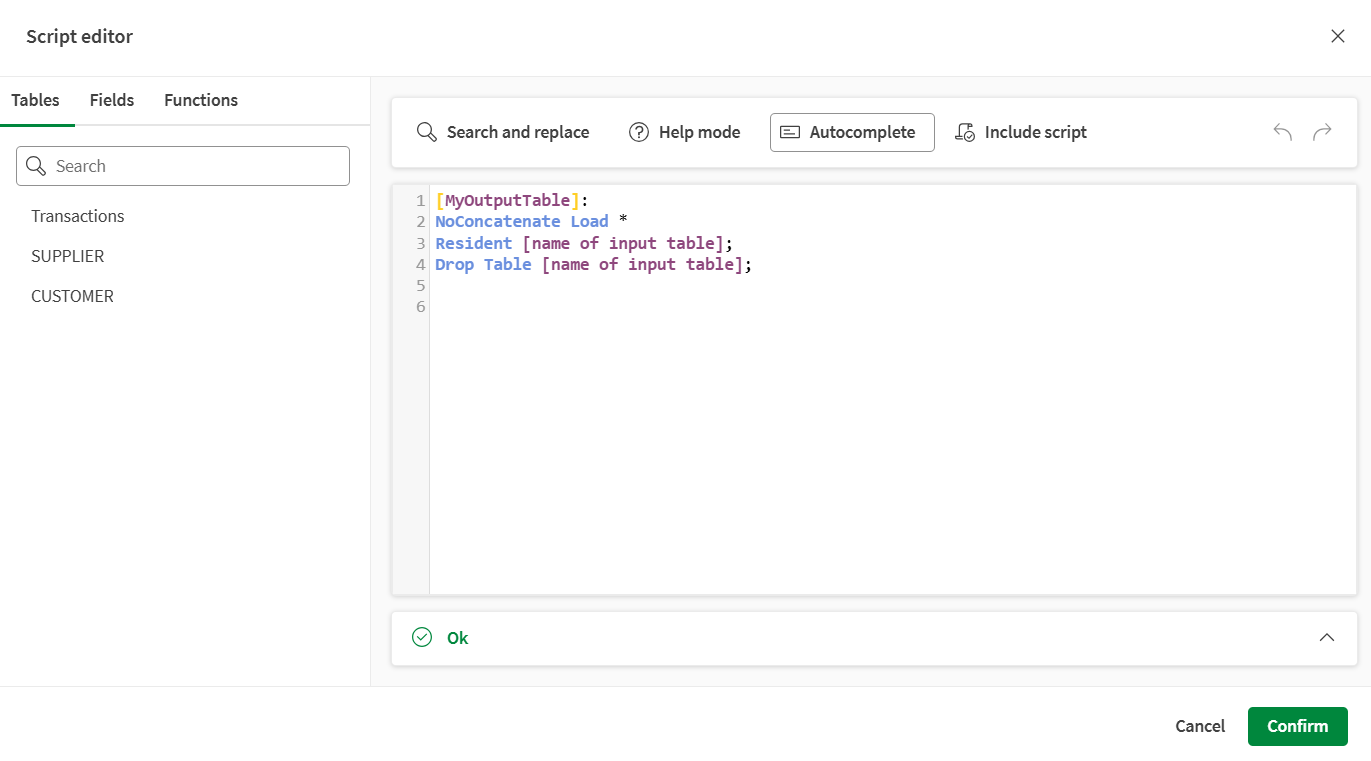
W lewym panelu można przeglądać tabele i pola aktualnie załadowane w przepływie danych oraz przeglądać szeroką gamę funkcji skryptu Qlik. Ten panel jest podzielony na trzy karty:
-
Tabele, gdzie wymienione są tabele załadowane w przepływie. Wskaż myszą dowolną z nazw tabel i kliknij +, aby wstawić ją bezpośrednio do skryptu.
-
Pola, gdzie wymienione są pola dostępne w tym momencie przepływu. Wskaż myszą dowolną z nazw pól i kliknij +, aby wstawić ją bezpośrednio do wyrażenia.
-
Funkcje, gdzie można przeglądać funkcje Qlik. Możesz użyć pola wyszukiwania, aby poszukać określonej funkcji, lub użyć listy rozwijanej Kategoria funkcji, aby je przefiltrować.
Wskaż myszą dowolną z funkcji i kliknij +, aby wstawić ją bezpośrednio do wyrażenia.
-
Jeśli wybierzesz przełącznik Przewodnik objaśniający, po kliknięciu funkcji wyświetlony zostanie krótki opis i link do dokumentacji.
-
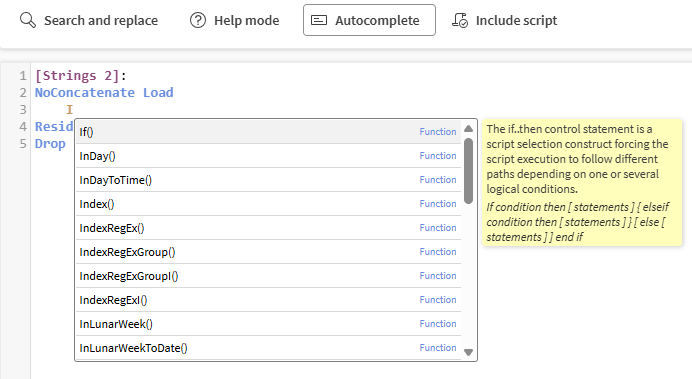
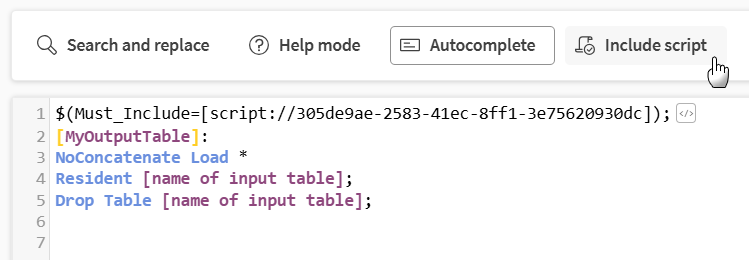
W górnym panelu można włączyć lub wyłączyć trzy narzędzia, które pomagają i prowadzą podczas pisania skryptu, użyć skrótu do wstawiania skryptu z innych plików, a także przycisków cofania i ponawiania, aby naprawić potencjalne błędy.
-
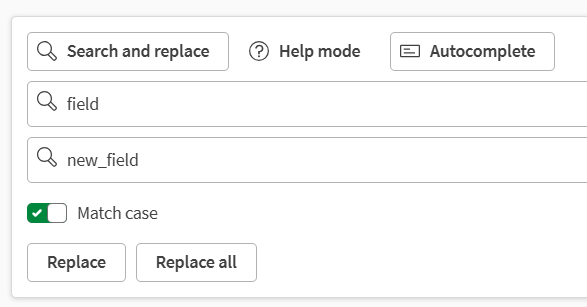
Wyszukaj i zamień, aby automatycznie szukać określonych wartości i w razie potrzeby je zamieniać.
-
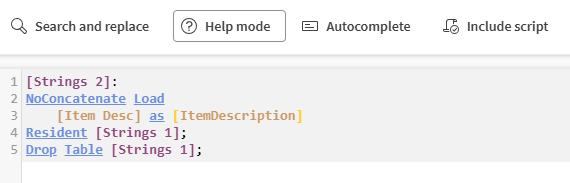
Tryb pomocy, aby zamienić dowolną funkcję napisaną w skrypcie w klikalne linki, które przeniosą Cię do dokumentacji.
-
Autouzupełnianie, aby wyświetlać sugestie podczas pisania, wraz z krótkim opisem i przykładem funkcji.
-
Dołącz skrypt, aby wstawiać skrypty. Zobacz Wstawianie innych skryptów do skryptów ładowania.
Dolny panel opisuje wszelkie potencjalne błędy w skrypcie, takie jak nieprawidłowe nazwy pól lub nieprawidłowe wyrażenia.
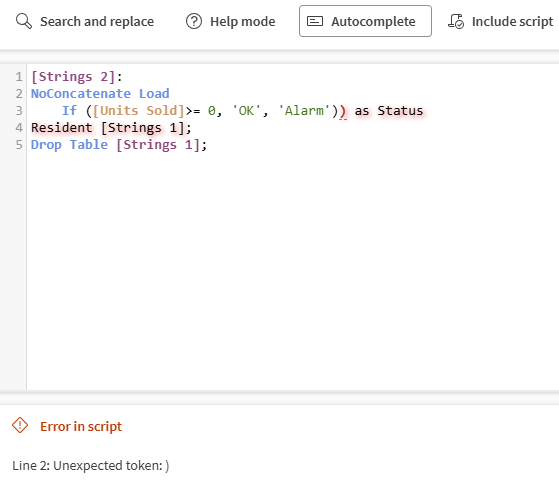
Gdy panel stanu pokazuje zielone Ok, skrypt jest prawidłowy. Kliknij Potwierdź, aby użyć tego skryptu dla procesora skryptu Qlik i wrócić do edytora przepływu danych. Następnie możesz zweryfikować konfigurację procesora.
Przykłady
-
Ładowanie wielu tabel o tym samym schemacie do jednego wejścia dla przepływu. W tym przykładzie użyto dwóch plików .txt z katalogu, z tymi samymi polami, ale z inną zawartością. Ponadto to wyrażenie doda pole do śledzenia, z której tabeli pochodzą dane, i wygeneruje liczbę całkowitą jako numer identyfikacyjny:
[MyTable_1]: LOAD 'table1' as source_table, [firstname], [lastname], [nationality] FROM [lib://DataFiles/MyTable_1.txt] (txt, codepage is 28591, embedded labels, delimiter is ',', msq); [MyTable_2]: CONCATENATE (MyTable_1) LOAD 'table2' as source_table, [firstname], [lastname], [nationality] FROM [lib://DataFiles/MyTable_2.txt] (txt, codepage is 28591, embedded labels, delimiter is ',', msq); [NewTable]: LOAD recno() as id, * RESIDENT MyTable_1; drop table MyTable_1;Więcej informacji zawiera temat Concatenate.
-
Utwórz tabelę wbudowaną z edytowalnymi danymi jako wejście dla przepływu:
MyTable: Load * Inline [ Country, Year, Sales Argentina, 2014, 66295.03 Argentina, 2015, 140037.89 Austria, 2014, 54166.09 Austria, 205,182739.87 ];Więcej informacji zawiera temat Using inline loads to load data.
-
Ładowanie wszystkich plików z folderu jako wejścia dla przepływu. Ten przykład iteruje po wszystkich plikach z określonym rozszerzeniem w folderze i ładuje je do pojedynczej tabeli. Zastąp nazwę połączenia danych i ścieżkę folderu własnymi wartościami oraz dostosuj rozszerzenie pliku i ustawienia formatu w razie potrzeby:
SET vFolderPath = 'lib://YourDataConnection/FolderName'; FOR EACH vFile IN filelist('$(vFolderPath)/*.csv') LOAD * FROM [$(vFile)] (txt, utf8, embedded labels, delimiter is ','); NEXTWięcej informacji zawiera temat For each..next.
Więcej przykładów wyrażeń skryptu zawiera temat Regular statements oraz Script and chart functions.