
Progettazione di un flusso di dati
Creazione di un flusso di dati
Per iniziare, creare un nuovo flusso di dati.
-
Dal menu di avvio, selezionare Analisi > Crea o Analisi > Prepara dati.
-
Fare clic su Flusso di dati.
Si apre la finestra di dialogo Crea un nuovo flusso di dati.
-
Nel campo corrispondente, inserire un Nome per il flusso di dati.
-
Dall'elenco a comparsa corrispondente, selezionare lo Spazio in cui si desidera salvare il flusso di dati.
-
Aggiungere una Descrizione per documentare lo scopo del flusso di dati.
-
Aggiungere alcuni Tag al flusso di dati per renderlo più facile da trovare.
-
Facoltativamente, selezionare la casella di selezione Apri flusso di dati per visualizzare direttamente il flusso di dati dopo la sua creazione.
-
Fare clic su Crea.
Il flusso di dati vuoto si apre e viene visualizzata la scheda Panoramica dell'intestazione di navigazione. Il nuovo flusso di dati è disponibile anche in seguito nella pagina Analisi > Home di Qlik Cloud.
Per maggiori informazioni sulle informazioni che è possibile trovare nella panoramica del flusso di dati, consultare Navigazione dei flussi di dati.
Per iniziare a progettare un flusso di dati, andare alla scheda Editor dell'intestazione di navigazione.
Selezione di una sorgente
Il primo elemento del flusso di dati è la sorgente che contiene i dati che si desidera preparare. È possibile utilizzare qualsiasi dato dal proprio catalogo o da una connessione.
Aggiunta di dati da un set di dati
I set di dati archiviati nel catalogo possono essere basati su file (.qvd, .xls, .csv, .parquet, .json, ecc.) o sulle tabelle di database e data warehouse. Vedere Formati file per l'elenco dei formati supportati.
I set di dati creati in Qlik Talend Data Integration nell'ambito di un progetto dati possono essere utilizzati anche per creare flussi di dati.
Per selezionare un set di dati come sorgente del flusso di dati:
-
Dalla scheda Sorgenti del pannello di sinistra, trascinare una sorgente del Set di dati e rilasciarla sulla tela.
Viene visualizzata la finestra Catalogo dati, dove è possibile cercare i set di dati caricati in precedenza, oppure fare clic su Carica file di dati per cercare i file sul computer e caricarli istantaneamente.
Nota di avvisoQuando caricano file di grandi dimensioni, superiori a 300 MB, il processo può richiedere un po' di tempo. Non chiudere la finestra, i progressi vengono visualizzati tramite una rotella che all'inizio può sembrare vuota. -
Selezionare i dati che si desidera caricare.
-
Per caricare tutti i dati da un set di dati o un prodotto di dati, selezionare la casella di controllo corrispondente a tale riga.
-
Per caricare determinati set di dati da un prodotto di dati, fare clic sulla freccia accanto al nome del prodotto di dati. Selezionare i set di dati che si desidera caricare.
-
Per caricare determinate tabelle o campi da un set di dati, fare clic su Visualizza campi accanto al nome del set di dati. Selezionare i campi dalle tabelle che si desidera caricare.
-
Per caricare file dal computer, fare clic su Carica file per cercare file sul computer e aggiungerli all'elenco dei set di dati disponibili.
Nota informaticaÈ possibile filtrare i dati per tipo (set di dati o prodotti di dati). I prodotti di dati sono disponibili solo in alcuni abbonamenti. Per ulteriori informazioni, vedere Working with data products. -
-
Utilizzando la ricerca e i filtri, selezionare la casella di controllo davanti a uno o più set di dati dell'elenco e fare clic su Avanti.
Quando si seleziona un set di dati aggiunto da una connessione nel catalogo e più connessioni corrispondono, è possibile utilizzare un elenco a discesa per selezionare la connessione specifica da utilizzare.
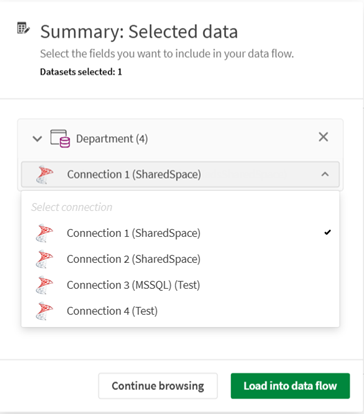
-
Nella scheda Riepilogo, è possibile verificare i set di dati selezionati, controllare i campi che contengono ed escluderne alcuni, se si desidera. Fare clic su Carica nel flusso di dati.
La sorgente o le sorgenti vengono aggiunte alla tela, con un avviso che indica la necessità di collegarle ad altri nodi.

Una volta posizionata una sorgente sulla tela, è possibile fare clic su di essa e accedere al pannello Proprietà per modificare i campi selezionati, se necessario, ad esempio se lo schema della sorgente è stato aggiornato.
Caricamento e configurazione un file csv
Se come sorgente si utilizza un set di dati per il file csv, caricato precedentemente nel catalogo o caricato direttamente durante il processo, e i dati non vengono visualizzati correttamente nell'anteprima, potrebbe significare che il file non è formattato correttamente.
Ad esempio, i dati del cliente che utilizzano la virgola come separatore vengono visualizzati in una singola colonna.

Il file è formattato male, oppure il separatore non è stato rilevato correttamente durante il caricamento. Per risolvere questo problema, è necessario andare alle impostazioni del set di dati.
-
Dal menu Launcher, selezionare Analisi > Catalogo.
-
Aprire il set di dati da correggere.
Nella panoramica del set di dati, è possibile visualizzare un avviso che indica un potenziale errore di formattazione.
-
Fare clic sul collegamento a Impostazioni formato file dal messaggio di avviso o utilizzare il menu Altre azioni in alto a destra nella panoramica.
È possibile notare che il delimitatore è stato erroneamente impostato come Punto e virgola.

-
Dall'elenco a discesa dei Delimitatore, selezionare Virgola.
Con il delimitatore previsto, l'anteprima ora mostra correttamente i diversi campi.

-
Fare clic su Salva.
-
Tornando al flusso di dati, eliminare la sorgente obsoleta, se la tela non era vuota, quindi aggiungerla nuovamente. Questa volta, la sorgente rifletterà la configurazione corretta per il set di dati.
Aggiunta di dati da una connessione
Qlik Cloud e i flussi di dati supportano una serie di connessioni alle sorgenti dati. Per maggiori informazioni, consultare l'elenco delle sorgenti dati supportate.
Gli unici tipi di connessione attualmente non supportati sono i seguenti:
Per selezionare una connessione come sorgente del flusso di dati:
-
Dalla scheda Sorgenti del pannello di sinistra, trascinare una sorgente di Connessioni e rilasciarla sulla tela.
Viene visualizzata la finestra Seleziona connessione, dove è possibile cercare le connessioni create in precedenza, oppure fare clic su Crea connessione per definirne una nuova subito dopo l'autenticazione.
-
Utilizzando la ricerca e i filtri, selezionare la casella di controllo davanti a una connessione dall'elenco e fare clic su Avanti.
-
A seconda della connessione, sarà possibile sfogliare i file, inserire un percorso ai dati o selezionare le tabelle da un database.
-
Dopo aver selezionato i dati di origine, fare clic su Salva o Fine.
La sorgente viene aggiunta alla tela, con un avviso che indica la necessità di collegarla a un altro nodo.

Una volta posizionata una sorgente sulla tela, è possibile fare clic su di essa e accedere al pannello Proprietà per modificare i campi selezionati, se necessario, ad esempio se lo schema della sorgente è stato aggiornato.
Aggiunta di processori
I processori sono i blocchi predefiniti che contengono le diverse funzioni di preparazione disponibili in un flusso di dati. Ricevono i dati in arrivo e restituiscono i dati preparati alla fase successiva del flusso. I processori consentono di eseguire operazioni di estrazione, miglioramento e pulizia complesse su dati diversi, con un'anteprima live. Per maggiori informazioni sulle funzioni disponibili, consultare Processori del flusso di dati.
Per connettere un primo processore alla sorgente dati:
-
È possibile eseguire le seguenti azioni:
-
Dalla scheda Processori del pannello di sinistra, trascinare il processore desiderato e rilasciarlo sulla tela accanto alla sorgente.

Sarà necessario connettere manualmente la sorgente e il processore. Creare un collegamento facendo clic sul punto a destra del nodo di origine, quindi tenere premuto e trascinare il collegamento sul punto a sinistra del nodo del processore.

-
Fare clic sul menu di azione della sorgente, selezionare Aggiungi processore, quindi fare clic sul processore desiderato.

Il processore viene posizionato sulla tela e connesso automaticamente alla sorgente.
-
-
Fare clic sul processore per iniziare a configurarlo nel pannello di destra.
Le diverse funzioni disponibili e i parametri da configurare dipendono da ciascun processore. Per ulteriori informazioni, consultare la documentazione relativa al processore.
-
Fare clic su Salva.
-
Aggiungere e connettere il numero di processori necessari per preparare i dati.
Attivare l'interruttore Anteprima dati nel pannello Anteprima per visualizzare gli effetti di un processore su un campione dei dati. Fare clic sull'icona dell'ingranaggio per aprire l'anteprima Impostazioni e configurare la dimensione campione fino a 10.000 righe. A questo punto, è possibile anche attivare l'interruttore Script per visualizzare l'equivalente di Qlik Script del flusso di dati.
Selezionare una destinazione
Per terminare il flusso di dati, è necessario connettere l'ultimo processore a un nodo di destinazione. È possibile scegliere tra due tipi di destinazioni:
-
File di dati per i file archiviati nel catalogo dell'utente in Qlik Cloud.
-
Connessioni, che consente di scrivere in una sorgente esterna aggiunta come connessione in Qlik Cloud.
Entrambe le opzioni consentono di esportare i dati preparati come file .qvd, .parquet, .txt o .csv.
Per connettere una destinazione al resto del flusso:
-
È possibile eseguire le seguenti azioni:
-
Dalla scheda Destinazioni del pannello di sinistra, trascinare il tipo di destinazione desiderato, quindi rilasciarlo sulla tela accanto all'ultimo processore.

Connettere manualmente l'ultimo processore alla destinazione nello stesso modo in cui i processori sono stati connessi anteriormente.
-
Fare clic sul menu di azione dell'ultimo processore, selezionare Aggiungi destinazione, quindi fare clic sulla destinazione desiderata.

-
-
Fare clic sulla destinazione per iniziare a configurarla nel pannello di destra.
Nota informaticaNel caso dei File di dati, è possibile scrivere in una cartella specifica dello spazio desiderato. Se si è creata una cartella denominata nome_cartella nel proprio spazio personale, ad esempio, utilizzare nome_cartella/output_flusso_dati.qvd come nome file per la destinazione. Il file risultante verrà inviato direttamente alla cartella. -
Fare clic su Salva.
Impostando almeno una sorgente, una destinazione e un processore opzionale, è possibile eseguire il flusso di dati.
Esecuzione del flusso di dati
Quando tutti i nodi del flusso di dati sono connessi, configurati e contrassegnati come OK, un segno di spunta verde indica che il flusso di dati è considerato valido e può essere eseguito. A questo punto, è possibile utilizzare il pulsante Anteprima script presente in alto a destra della tela per vedere lo script completo che verrà generato in background.

-
Fare clic su Esegui flusso per avviare l'elaborazione dei dati.
Viene visualizzata una notifica per mostrare lo stato dell'esecuzione.
-
Quando il flusso viene completato con successo, i dati preparati che sono stati generati come output possono essere trovati in posizioni diverse a seconda della destinazione:
-
Nel Catalogo, tra le altre risorse, e nella sezione Output della Panoramica del flusso di dati per i file di dati
-
Nella sezione Output della Panoramica del flusso di dati per i set di dati basati sulla connessione.
Se il flusso dovesse fallire, puoi aprire il log di esecuzione per aiutarti a identificare cosa è andato storto.
-
Ora è possibile utilizzare questi dati preparati come sorgente pulita per alimentare un esperimento Qlik Predict oppure in un'app per la visualizzazione dei dati.