
Processore di campionamento
Mantiene solo le prime righe o un sottogruppo casuale di righe.
Il processore di Campionamento consente di selezionare un numero specifico o una percentuale di record dal flusso di input e rendere il campione di dati più rappresentativo per l'intero set di dati.
Uso
-
Il processore Campionamento richiede un flusso di input e può generare un solo flusso di output.
-
L'utilizzo di questo processore annullerà l'ordinamento dei dati se è stato utilizzato un processore di Ordinamento nel flusso di input.
Proprietà
Proprietà da configurare per selezionare un sottoinsieme di record dall'input.
| Proprietà | Configurazione |
|---|---|
| Metodo di campionamento |
Selezionare se si desidera estrarre un numero fisso di righe o una percentuale delle righe totali dal flusso di input:
|
| Numero di righe da estrarre | Inserire il numero di righe da mantenere. |
| Intervallo di campionamento (%) | Inserire la percentuale di righe da mantenere. |
| Campo strato | Dall'elenco a discesa, selezionare il campo da utilizzare come strato. |
Per rinominare il processore o modificarne la descrizione, posizionare il mouse sul nome o sulla descrizione clic sull'icona per modificare il pannello Proprietà, quindi fare clic sull'icona ![]() Modifica.
Modifica.
Esempio
In questo esempio, si utilizza un set di dati contenente informazioni sulle transazioni di vendita di tre regioni: Est, Ovest e Centrale.
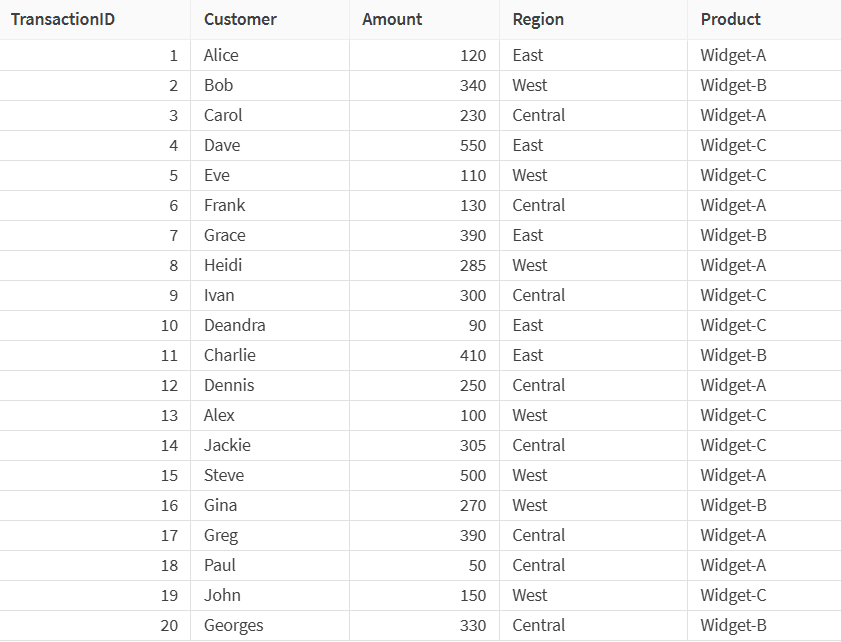
Attualmente, il campione contiene 20 righe, ma si desidera ridurne le dimensioni, assicurandosi che ogni regione sia equamente rappresentata nei dati campionati. Per modificare la dimensione del campione, si utilizzerà il processore Campionamento.
Nelle proprietà del processore, selezionare Campionamento stratificato casuale come metodo di campionamento, impostare il valore del Rapporto di campionamento (%) su 50 e selezionare Regione come campo strato.
Impostare il campionamento stratificato al 50% significa che il campione conterrà circa la metà delle righe da ogni regione dopo l'arrotondamento.
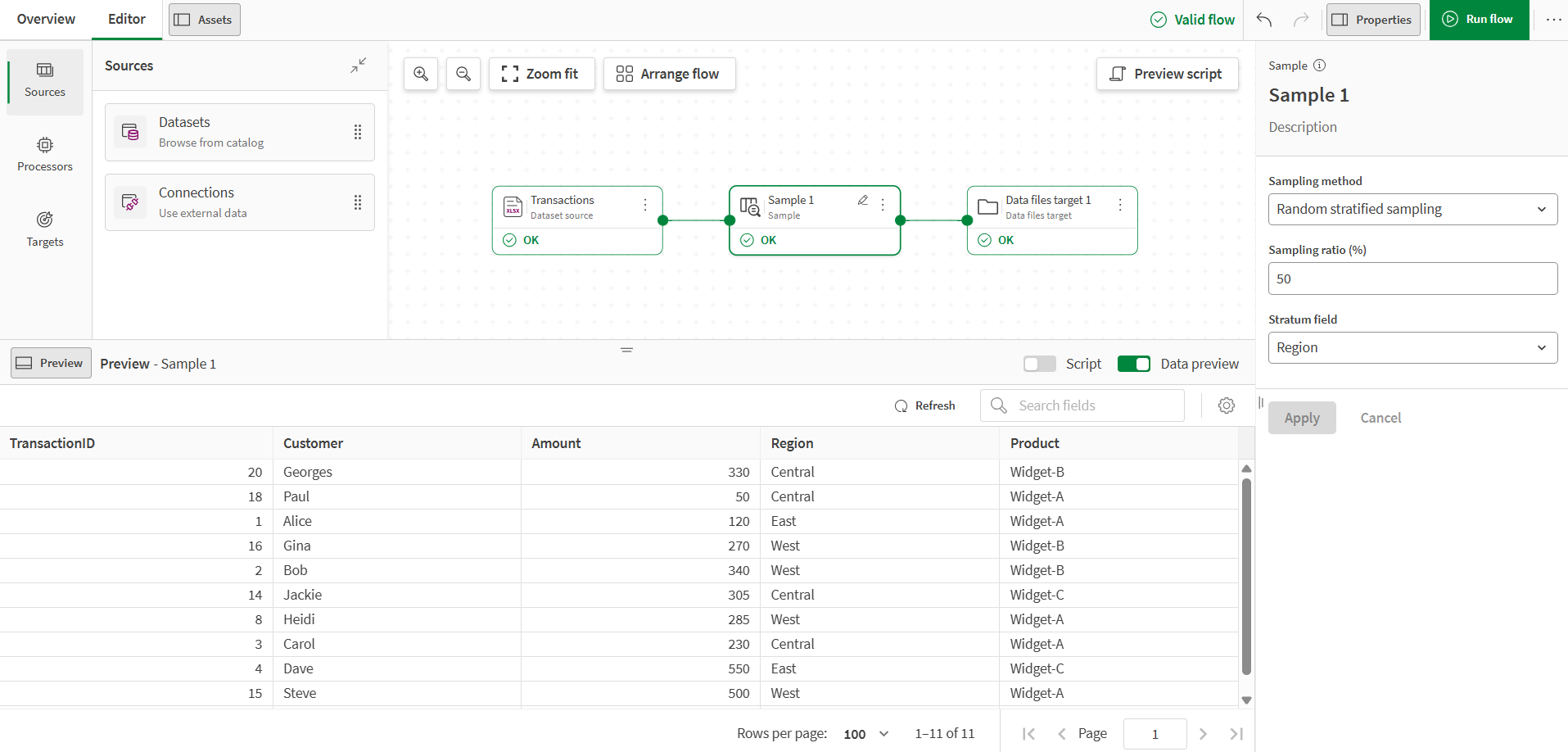
Nell'output del processore, il campione ora contiene solo circa la metà delle righe dell'originale, mantenendo la stessa distribuzione delle regioni.