
샘플 프로세서
첫 번째 행 또는 행의 임의 하위 집합만 유지합니다.
샘플 프로세서를 사용하면 입력 흐름에서 특정 수 또는 비율의 레코드를 선택하여 데이터 샘플이 전체 데이터 세트를 더 잘 대표하도록 만들 수 있습니다.
사용량
-
샘플 프로세서는 하나의 입력 흐름이 필요하고 하나의 출력 흐름만 생성할 수 있습니다.
-
이 프로세서를 사용하면 입력 흐름에서 정렬 프로세서가 사용된 경우 데이터가 정렬되지 않은 상태가 됩니다.
속성
입력에서 레코드의 하위 집합을 선택하도록 구성할 속성입니다.
| 속성 | 구성 |
|---|---|
| 샘플링 방법 |
입력 흐름에서 고정된 수의 행을 추출할지 또는 전체 행의 백분율을 추출할지 선택합니다:
|
| 추출할 행 수 | 유지할 행의 수를 입력합니다. |
| 샘플링 비율(%) | 유지할 행의 비율을 입력합니다. |
| 계층 필드 | 드롭다운 목록에서 계층으로 사용할 필드를 선택합니다. |
프로세서의 이름을 바꾸거나 설명을 편집하려면 속성 패널에서 변경할 이름이나 설명 위에 마우스를 놓고 ![]() 편집 아이콘을 클릭합니다.
편집 아이콘을 클릭합니다.
예제
이 예시에서는 동부, 서부, 중부 세 지역의 판매 거래 정보를 포함하는 데이터세트에서 작업합니다.
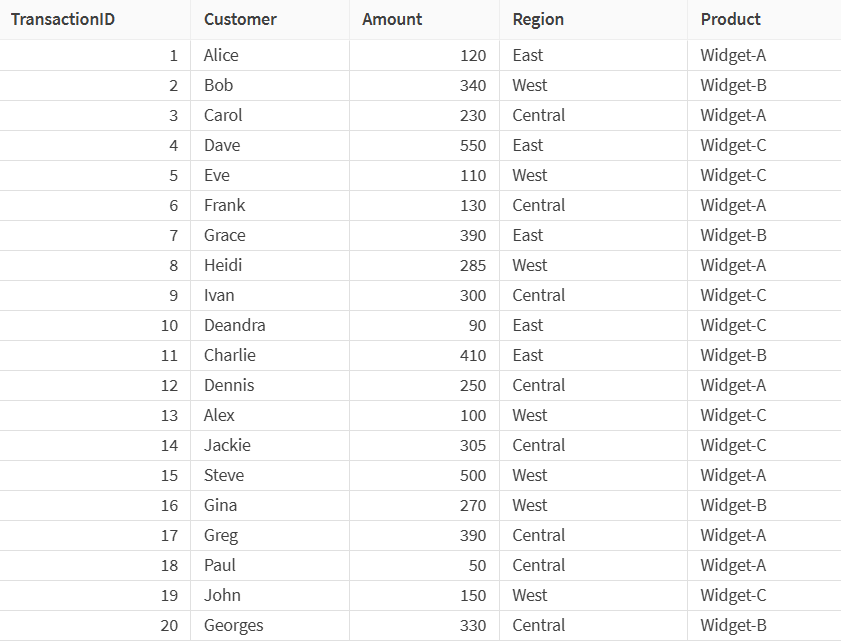
현재 샘플에는 20개의 행이 포함되어 있지만, 각 지역이 샘플링된 데이터에 균등하게 표현되도록 하면서 크기를 줄이고자 합니다. 샘플 크기를 변경하려면 샘플 프로세서를 사용합니다.
프로세서 속성에서 무작위 계층 샘플링을 샘플링 방법으로 선택하고, 샘플링 비율(%)을 50으로 설정한 다음, 지역을 계층 필드로 선택합니다.
계층 샘플링을 50%로 설정하면 반올림 후 각 지역에서 대략 절반의 행이 샘플에 포함됩니다.

프로세서의 출력에서 샘플은 이제 원본 행의 약 절반만 포함하며, 동일한 지역 분포를 유지합니다.