
Sample-processor
Behoud alleen de eerste rijen of een willekeurige subset van rijen.
De Sample-processor stelt u in staat om een specifiek aantal of percentage records uit uw invoerstroom te selecteren en het datamonster representatiever te maken voor de gehele dataset.
Gebruik
-
De Sample-processor heeft één invoerstroom nodig en kan slechts één uitvoerstroom genereren.
-
Het gebruik van deze processor zal de gegevens ongesorteerd maken als een Sort-processor werd gebruikt in de invoerstroom.
Eigenschappen
Eigenschappen om te configureren om een subset van records uit de invoer te selecteren.
| Eigenschap | Configuratie |
|---|---|
| Steekproefmethode |
Selecteer of u een vast aantal rijen of een percentage van het totale aantal rijen uit de invoerstroom wilt extraheren:
|
| Aantal rijen om te extraheren | Voer het aantal rijen in dat moet worden behouden. |
| Steekproefverhouding (%) | Voer het percentage rijen in dat moet worden behouden. |
| Stratumveld | Selecteer in de vervolgkeuzelijst het veld dat moet worden gebruikt als stratum. |
Om de naam van de processor te wijzigen of de beschrijving te bewerken, gaat u met de muisaanwijzer op de naam of beschrijving staan om naar het eigenschappenvenser te gaan en klikt u op het pictogram ![]() Bewerken.
Bewerken.
Voorbeeld
In dit voorbeeld werkt u met een dataset die informatie bevat over verkooptransacties uit drie regio's: Oost, West en Centraal.
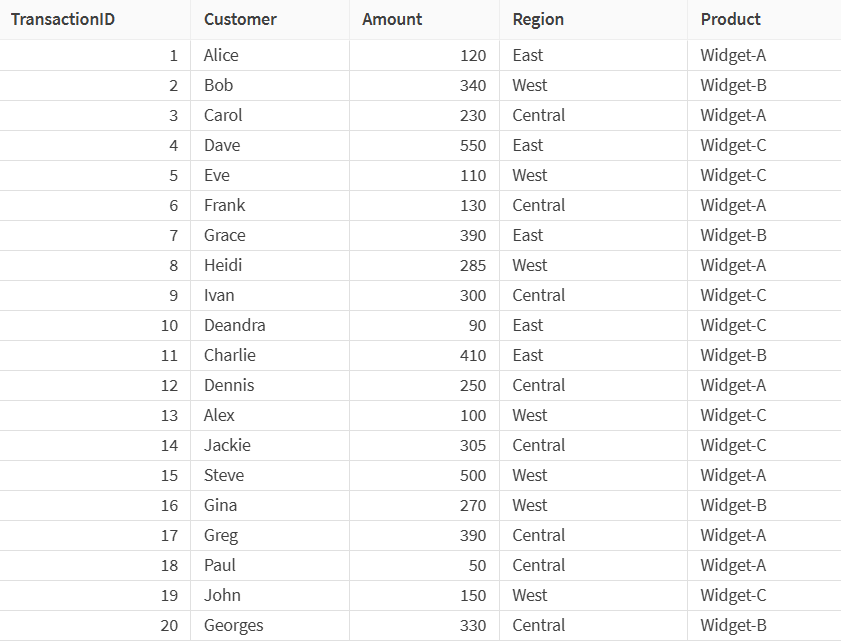
Momenteel bevat de steekproef 20 rijen, maar u wilt de omvang ervan verkleinen, terwijl u ervoor zorgt dat elke regio gelijkmatig wordt vertegenwoordigd in de bemonsterde gegevens. U gebruikt de processor Steekproef om de omvang van de steekproef te wijzigen.
Selecteer in de processoreigenschappen Willekeurige gestratificeerde steekproeftrekking als bemonsteringsmethode, stel de Steekproefverhouding (%) in op 50 en selecteer Regio als stratumveld.
Het instellen van de gestratificeerde steekproeftrekking op 50% betekent dat de steekproef na afronding ongeveer de helft van de rijen uit elke regio zal bevatten.
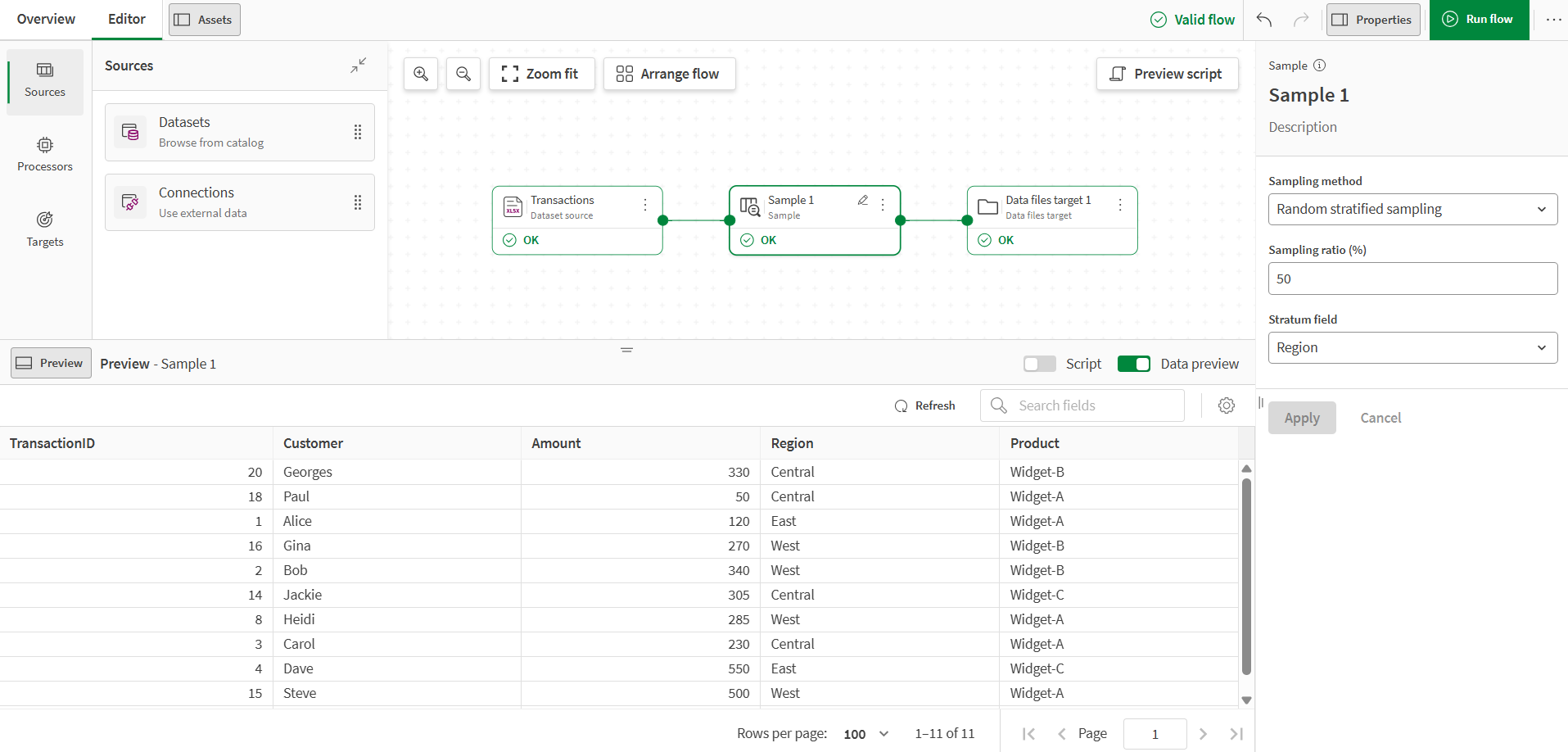
In de uitvoer van de processor bevat de steekproef nu nog maar ongeveer de helft van de rijen van het origineel, met behoud van dezelfde distributie van regio's.