
样本处理器
仅保留第一行或行的随机子集。
样本处理器可让您从输入流中选择特定数量或百分比的记录,并使数据样本更能代表整个数据集。
使用
-
样本处理器需要一个输入流,只能生成一个输出流。
-
如果输入流中使用了排序处理器,则使用此处理器将让数据取消排序。
属性
要配置的属性,用于从输入中选择记录子集。
| 属性 | 配置 |
|---|---|
| 采样方法 |
选择您是要从输入流中提取固定行数还是总行数的百分比:
|
| 要提取的行数 | 输入要保留的行数。 |
| 采样率 (%) | 输入要保留的行的百分比。 |
| Stratum 字段 | 从下拉列表内,选择用作分层的字段。 |
要重命名处理器或编辑其描述,请将鼠标指向属性面板中要更改的名称或描述,然后单击 ![]() 编辑图标。
编辑图标。
示例
在此示例中,您正在处理一个包含来自三个区域(东部、西部及中部)的销售交易信息的数据集。
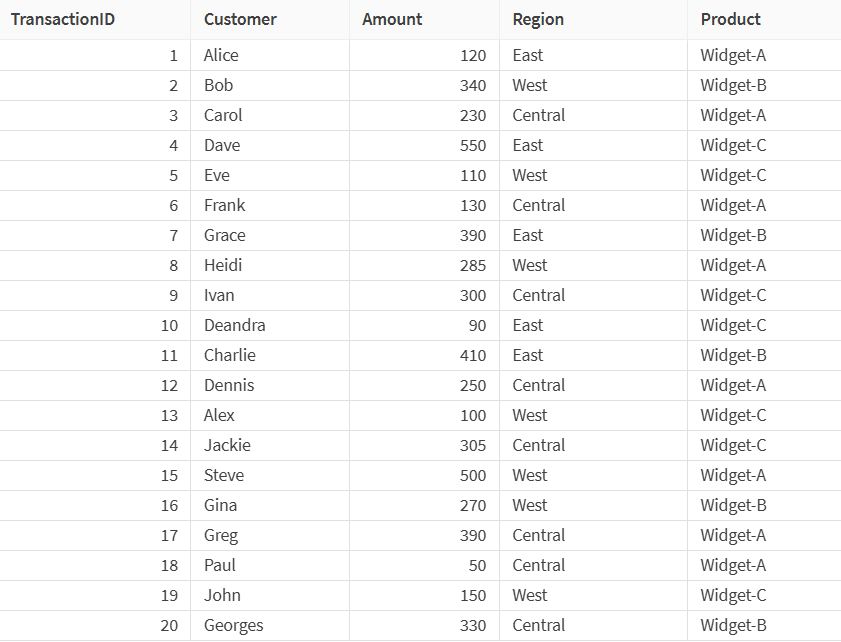
当前,样本包含 20 行,但是您希望减小其大小,同时确保每个区域在采样数据中得到均匀表示。您将使用样本处理器来更改样本大小。
在处理器属性中,选择随机分层抽样作为采样方法,将采样比 (%) 设置为 50,并选择区域作为分层字段。
将分层抽样设置为 50% 意味着样本在四舍五入后将包含每个区域大约一半的行。
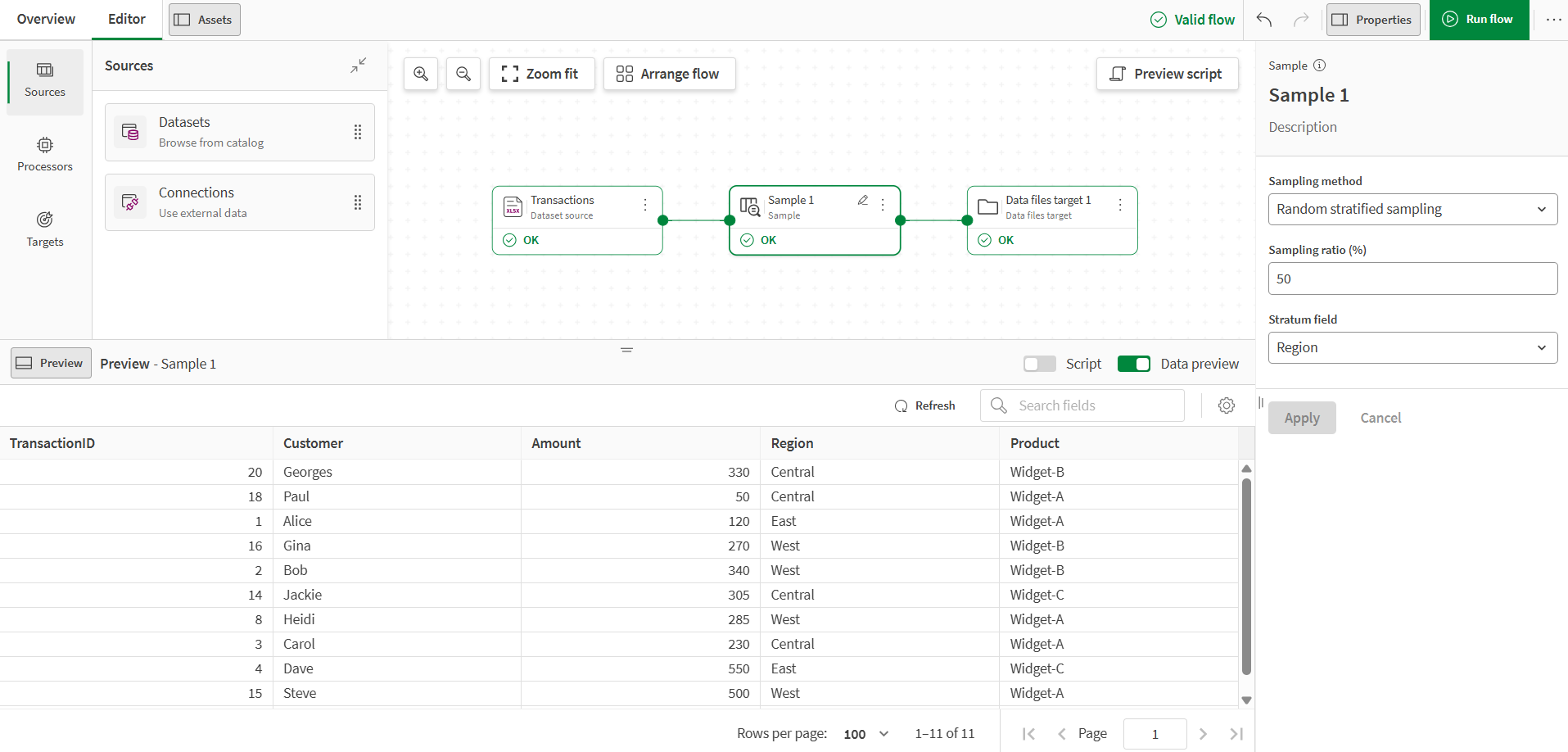
在处理器输出中,样本现在只包含原始数据大约一半的行,同时保持相同的区域分布。