
构建数据流
创建数据流
首先创建一个新的数据流。
-
从启动器菜单开始,选择分析 > 创建或分析 > 准备数据。
-
单击数据流。
创建新数据流对话框打开。
-
在相应的字段中,输入数据流的名称。
-
从相应的下拉列表中,选择要在哪个空间中保存数据流。
-
添加描述以记录数据流的目的。
-
为数据流添加一些标签,使其更容易查找。
-
(可选)选择打开数据流复选框,以便在创建应用程序后直接查看应用程序。
-
单击创建。
您的空数据流打开后,就会到达导航头的概览选项卡。以后还可以在 Qlik Cloud 的 分析 > 主页页面中找到新的数据流。
有关在数据流概览中可以找到的信息的更多信息,请参阅数据流导航 。
要开始设计数据流,请转到导航标题的编辑器选项卡。
选择一个源
数据流的第一个构件是包含要准备数据的容器源。您可以使用目录或连接中的任何数据。
从数据集添加数据
目录中存储的数据集可以是基于文件的(.qvd、.xls、.csv、.parquet、.json 等),也可以是数据库和数据仓库中的表。有关支持的格式列表,请参阅文件格式。
作为数据项目的一部分在 Qlik Talend Data Integration 中创建的数据集也可用于创建数据流。
选择数据集作为数据流的源:
-
从左侧面板的源选项卡中,拖放一个数据集源到画布上。
此时会打开数据目录窗口,您可以在这里浏览之前上传的数据集,或单击上传数据文件浏览计算机上的文件并即时上传。
警告注释上传大于 300 MB 的大文件时,上传过程可能需要一些时间。不要关闭窗口,进度显示在一个旋转器上,开始时可能看起来是空的。 -
选择您希望加载的数据。
-
要从数据集或数据产品加载所有数据,请选择该行对应的复选框。
-
要从数据产品加载特定数据集,请单击数据产品名称旁边的箭头。选择要加载的数据集。
-
要从数据集加载某些表或字段,请单击数据集名称旁边的 查看字段。从要加载的表中选择字段。
-
要从计算机上传文件,请单击 上传文件 以浏览计算机上的文件,并将其添加到可用数据集列表中。
信息注释您可以按类型(数据集或数据产品)筛选数据。数据产品仅在某些订阅中可用。有关更多信息,请参阅Working with data products。 -
-
使用搜索和筛选器,从列表中选择一个或多个数据集前面的复选框,然后单击下一步。
当选择从目录中的连接添加的数据集,并且多个连接匹配时,您可以使用下拉列表选择要使用的特定连接。
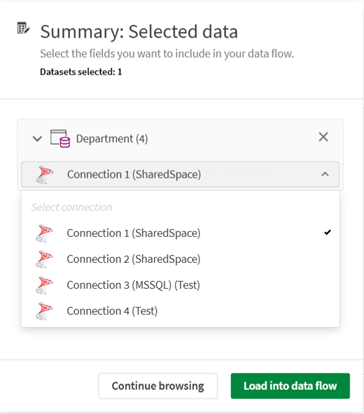
-
在汇总选项卡中,您可以查看所选的数据集,检查其中包含的字段,并根据需要排除某些字段。点击加载到数据流中。
源会被添加到画布上,并提示您需要将它们连接到其他节点。

将源放到画布上后,如果需要,例如源的模式已更新,可以单击它并访问属性面板来编辑所选字段。
上传和配置 csv 文件
如果您使用 csv 文件数据集作为数据源,无论是之前上传到您的目录中还是在处理过程中直接上传,而数据在预览中显示不正确,这可能意味着文件格式不正确。
例如,使用逗号作为分隔符的客户数据显示在单列中。

文件格式不正确,或者在上传过程中未正确检测到分隔符。要解决这个问题,您需要进入数据集设置。
-
从启动器菜单中选择分析 > 目录。
-
打开数据集以进行修正。
在数据集概览中,您可以看到一个警告,提示可能存在格式错误。
-
点击警告信息中的文件格式设置链接,或使用概览右上方的更多操作菜单。
您可以看到,分隔符被错误地设置为分号。

-
从分隔符下拉列表中选择逗号。
有了预期的分隔符,预览现在可以正确显示不同的字段。

-
单击保存。
-
回到数据流中,如果画布不是空的,删除过时的数据源,然后重新添加。这次,源将反映正确的数据集配置。
从连接添加数据
Qlik Cloud 和数据流支持与数据源的各种连接。更多信息,请参阅支持的数据源列表。
目前不支持的连接类型仅有以下几种:
选择连接作为数据流的源:
-
从左侧面板的源选项卡中,拖放一个连接源到画布上。
此时将打开选择连接窗口,您可以浏览以前创建的连接,或单击创建连接在验证后即时定义一个新连接。
-
使用搜索和筛选器,从列表中选择连接前面的复选框,然后单击下一步。
-
根据连接的不同,您可以浏览文件、输入数据路径或从数据库中选择数据表。
-
选择数据源后,单击保存或完成。
源会被添加到画布上,并提示您需要将它连接到另一个节点。

将源放到画布上后,如果需要,例如源的模式已更新,可以单击它并访问属性面板来编辑所选字段。
添加处理器
处理器是包含数据流中不同准备功能的构件容器。它们接收传入的数据,并将准备好的数据流返回给下一步数据流。处理器可让您通过实时预览对各种数据执行复杂的提取、改进和清理操作。有关可用功能的更多信息,请参阅 数据流处理器 全文。
将第一处理器连接到数据源:
-
您可以:
-
从左侧面板的处理器选项卡中,拖放您选择的处理器,并将其放置在画布上源的旁边。

您需要手动连接源和处理器。单击源节点右侧的圆点,按住不放,然后将链接拖动到处理器节点左侧的圆点,即可创建链接。

-
单击源的操作菜单,选择添加处理器,然后单击所选处理器。

处理器被放置在画布上,并自动与源连接。
-
-
单击处理器,开始在右侧面板中对其进行配置。
可用的功能和需要配置的参数每台处理器各有不同。有关更多信息,请参阅各个处理器文档。
-
单击保存。
-
根据需要添加和连接处理器,以准备数据。
激活预览面板中的数据预览开关,查看处理器对样本数据的处理效果。单击齿轮图标打开预览设置,最多可配置 10000 行样本。您还可以激活脚本开关,查看此时数据流的 Qlik 脚本等价物。
选择目标
要结束数据流,需要将最后一个处理器连接到目标节点。您可以选择两种目标类型:
-
数据文件,用于存储在您的 Qlik Cloud 目录中的文件。
-
连接,在 Qlik Cloud 中写入添加为连接的外部源。
这两个选项都允许您将准备好的数据导出为 .qvd、.parquet、.txt 或 .csv 文件。
将目标连接到流程的其他部分:
-
您可以:
-
从左面板的目标选项卡中拖动您选择的目标类型,并将其放在画布上最后一个处理器旁边。

按照之前连接处理器的方式,手动将最后一个处理器连接到目标机。
-
单击最后一个处理器的操作菜单,选择添加目标,然后单击所选目标。

-
-
单击目标,开始在右侧面板中对其进行配置。
信息注释如果是数据文件,可以在所需空间的特定文件夹中写入。例如,如果您在个人空间创建了名为 folder_name 的文件夹,请使用 folder_name/data_flow_output.qvd 作为目标文件的文件名。生成的文件将直接发送到您的文件夹。 -
单击保存。
现在只需最少一个源、一个目标和一个可选处理器,数据流就可以运行了。
运行数据流
当数据流的所有节点都已连接、配置并标记为确定时,绿色复选标记表示数据流被视为有效,可以运行。此时,可以使用画布右上方的预览脚本按钮,查看将在幕后生成的完整脚本。

-
单击运行数据流开始处理数据。
打开通知,显示运行状态。
-
当数据流成功完成后,可以根据目标在不同的地方找到已输出的准备数据:
-
在目录中的其他资产中,以及在数据流概览的输出部分的数据文件中
-
在基于连接的数据集的数据流概览的输出部分。
如果流失败,您可以打开运行日志以帮助您查明问题所在。
-
您现在可以将这些准备好的数据作为干净的数据源,为 Qlik Predict 实验提供素材,或在可视化应用程序中使用。