
データ フローの構築
データ フローの作成
まず、新しいデータ フローを作成します。
-
Launcher メニューから、 [分析] > [作成] または [分析] > [データの準備] を選択します。
-
[データ フロー] をクリックします。
[新しいデータ フローを作成] ダイアログが開きます。
-
該当する項目にデータ フローの [名前] を入力します。
-
該当するドロップダウン リストから、データ フローを保存する [スペース] を選択します。
-
[説明] を追加して、データ フローの目的を文書化します。
-
データ フローに [タグ] を追加して、見つけやすくします。
-
必要に応じて、 [データ フローを開く] チェックボックスをオンにして、作成されたデータ フローを直接表示します。
-
[作成] をクリックします。
空のデータ フローが開き、ナビゲーション ヘッダーの [概要] タブが表示されます。新しいデータ フローは、後から Qlik Cloud の [分析] > [ホーム] ページで確認することもできます。
データ フローの概要で確認できる情報の詳細については、「データ フローのナビゲート」を参照してください。
データ フローの設計を開始するには、ナビゲーション ヘッダーの [エディター] タブに移動します。
ソースを選択する
データ フローの最初の構成要素は、準備するデータを含むソースです。カタログまたは接続からの任意のデータを使用できます。
データセットからデータを追加する
カタログに保存されるデータセットは、ファイル (.qvd、xls、csv、parquet、json など) またはデータベースやデータ ウェアハウスのテーブルに基づくことができます。サポートされている形式のリストについては、「ファイル形式」を参照してください。
データ プロジェクトの一部として Qlik Talend Data Integration で作成されたデータセットを使用して、データ フローを作成することもできます。
データ フローのソースとしてデータセットを選択するには、次を実行します。
-
左側のパネルの [ソース] タブから [データセット] ソースをドラッグして、キャンバスにドロップします。
データ カタログ ウィンドウが開き、以前にアップロードしたデータセットを参照したり、 [データ ファイルをアップロード] をクリックしてコンピューター上のファイルを参照し、その場でアップロードしたりできます。
警告メモ300 MB を超える大きなファイルをアップロードする場合、処理に時間がかかることがあります。ウィンドウを閉じないでください。進行状況はスピナーに表示されますが、最初は空である可能性があります。 -
ロードするデータを選択します。
-
データセットまたはデータ製品からすべてのデータをロードするには、その行に対応するチェックボックスを選択します。
-
データ製品から特定のデータセットをロードするには、データ製品名の横にある矢印をクリックします。ロードするデータセットを選択します。
-
データセットから特定のテーブルまたは項目をロードするには、データセットの名前の横にある [項目を表示] をクリックします。ロードするテーブルから項目を選択します。
-
コンピューターからファイルをアップロードするには、[ファイルのアップロード] をクリックして、コンピューター上のファイルを検索し、利用可能なデータセットのリストに追加します。
情報メモデータはタイプ (データセットまたはデータ製品) でフィルタリングできます。データ製品は、一部のサブスクリプションでのみ利用可能です。詳細については、「データ製品の使用」を参照してください。 -
-
検索とフィルターを使用して、リストから 1 つ以上のデータセットの前のチェックボックスを選択し、 [次へ] をクリックします。
カタログ内の接続から追加されたデータセットを選択し、複数の接続が一致する場合は、ドロップダウン リストを使用して、使用する特定の接続を選択できます。
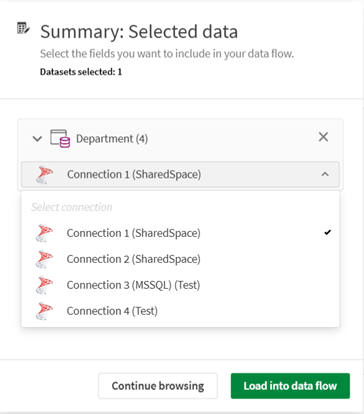
-
[概要] タブでは、選択したデータセットを確認し、そこに含まれる項目をチェックし、必要に応じて一部を除外することができます。[データ フローにロード] をクリックします。
ソースがキャンバスに追加され、他のノードに接続する必要があるという警告が表示されます。

ソースがキャンバスに配置されると、ソースをクリックして [プロパティ] パネルにアクセスし、ソースのスキーマが更新された場合など、 必要に応じて選択した項目を編集できます。
csv ファイルのアップロードと構成
以前にカタログにアップロードしたか、プロセス中に直接アップロードした csv ファイル データセットをソースとして使用していて、プレビューでデータが正しく表示されない場合は、ファイルが適切にフォーマットされていない可能性があります。
たとえば、区切り記号としてカンマを使用するこの顧客データは、1 つの列に表示されます。

ファイルのフォーマットが不適切であるか、アップロード中に区切り記号が正しく検出されませんでした。この問題をトラブルシューティングするには、データセット設定に移動する必要があります。
-
Launcher メニューから、 [分析] > [カタログ] を選択します。
-
修正するデータセットを開きます。
データセットの概要には、フォーマット エラーの可能性があるという警告が表示されます。
-
警告メッセージから [ファイル形式の設定] へのリンクをクリックするか、概要の右上にある [他のアクション] メニューを使用します。
区切り記号が誤ってセミコロンに設定されていることがわかります。

-
[区切り記号] ドロップダウン リストから、 [カンマ] を選択します。
適切な区切り記号を選択すると、プレビューは異なる項目を正しく表示するようになりました。

-
[Save] (保存)をクリックします。
-
データ フローに戻り、キャンバスが空でなかった場合は古いソースを削除して、再度追加します。今回は、ソースに適切なデータセット構成が反映されます。
接続からデータを追加する
Qlik Cloud とデータ フローは、データ ソースへのさまざまな接続をサポートします。詳細については、「サポートされるデータ ソースのリスト」を参照してください。
現在サポートされていない接続タイプは次のとおりです。
データ フローのソースとして接続を選択するには、次を実行します。
-
左側のパネルの [ソース] タブから [接続] ソースをドラッグして、キャンバスにドロップします。
接続の選択 ウィンドウが開き、以前に作成した接続を参照したり、 [接続を作成] をクリックして認証後に新しい接続を即座に定義したりできます。
-
検索とフィルターを使用して、リストから接続の前のチェックボックスを選択し、 [次へ] をクリックします。
-
接続に応じて、ファイルを参照したり、データへのパスを入力したり、データベースからテーブルを選択したりできるようになります。
-
ソース データを選択したら、 [保存] または [完了] をクリックします。
ソースがキャンバスに追加され、別のノードに接続する必要があることを示す警告が表示されます。

ソースがキャンバスに配置されると、ソースをクリックして [プロパティ] パネルにアクセスし、ソースのスキーマが更新された場合など、 必要に応じて選択した項目を編集できます。
プロセッサーを追加する
プロセッサは、データ フローで使用できるさまざまな準備機能を含む構成要素です。入力されたデータを受け取り、準備したデータをフローの次のステップに返します。プロセッサーにより、ライブ プレビューを使用して、さまざまなデータに対して複雑な抽出、改善、およびクリーニング操作を実行できます。利用可能な機能の詳細については、「データ フロー プロセッサー」を参照してください。
最初のプロセッサーをデータ ソースに接続するには、次を実行します。
-
次のいずれかを実行できます。
-
左側のパネルの [プロセッサー]タブから、選択したプロセッサーをドラッグし、ソースの横のキャンバスにドロップします。

ソースとプロセッサーを手動で接続する必要があります。ソース ノードの右側にあるドットをクリックし、リンクを押したままプロセッサー ノードの左側にあるドットまでドラッグしてリンクを作成します。

-
ソースのアクション メニューをクリックし、 [プロセッサーを追加] を選択して、希望するプロセッサーをクリックします。

プロセッサーはキャンバス上に配置され、ソースに自動的に接続されます。
-
-
プロセッサーをクリックして、右側のパネルで構成を開始します。
各プロセッサーに応じて、利用できるさまざまな機能と構成するパラメーターは異なります。詳細については、各プロセッサーのドキュメントを参照してください。
-
[Save] (保存)をクリックします。
-
データを準備するために必要な数のプロセッサーを追加して接続します。
[プレビュー] パネルで [データ プレビュー] スイッチを有効にすると、プロセッサーがデータのサンプルに与える影響を確認できます。歯車アイコンをクリックしてプレビューの [設定] を開き、サンプル サイズを最大 10000 行まで設定します。また、 [スクリプト] スイッチを有効にすると、この時点でデータ フローに相当する Qlik スクリプトを確認できます。
ターゲットを選択する
データ フローを終了するには、最後のプロセッサーをターゲット ノードに接続する必要があります。次の 2 つのターゲット タイプから選択できます。
-
Qlik Cloud のカタログに保存されているファイルのデータ ファイル。
-
Qlik Cloud の接続として追加された外部ソースに書き込むための接続。
どちらのオプションでも、準備データを .qvd、.parquet、.txt、または .csv ファイルとしてエクスポートできます。
ターゲットを残りのフローに接続するには、次を実行します。
-
次のいずれかを実行できます。
-
左側のパネルの [ターゲット] タブから、選択したターゲット タイプをドラッグし、最後のプロセッサーの横のキャンバスにドロップします。

以前にプロセッサーを接続したのと同じ方法で、最後のプロセッサーをターゲットに手動で接続します。
-
最後のプロセッサーのアクション メニューをクリックし、 [ターゲットを追加] を選択して、選択したターゲットをクリックします。

-
-
ターゲットをクリックして、右側のパネルで構成を開始します。
情報メモ[データ ファイル] の場合、希望するスペースの特定のフォルダーに書き込むことができます。たとえば、個人スペースに folder_name というフォルダーを作成した場合、ターゲットのファイル名として folder_name/data_flow_output.qvd を使用します。結果のファイルはフォルダーに直接送信されます。 -
[Save] (保存)をクリックします。
少なくとも 1 つのソース、1 つのターゲット、およびオプションのプロセッサーがあれば、データ フローを実行できるようになりました。
データ フローを実行する
データ フローのすべてのノードが接続され、構成され、OK としてマークされている場合、緑色のチェック マークは、データ フローが有効であるとみなされ、実行可能であることを示します。この時点で、キャンバスの右上にある [スクリプトをプレビュー] ボタンを使用して、バックグラウンドで生成される完全なスクリプトを確認できます。

-
[フロー実行] をクリックしてデータの処理を開始します。
実行のステータスを示す通知が開きます。
-
フローが正常に完了すると、出力された準備済みデータは、ターゲットに応じてさまざまな場所で確認できます。
-
[カタログ] 内の他のアセットと一緒に、およびデータ ファイルのデータ フロー [概要] の [出力] セクション
-
接続ベースのデータセットのデータ フロー [概要] の [出力] セクション
フローが失敗した場合、何が問題だったのかを特定するために実行ログを開くことができます。
-
この準備されたデータを、Qlik Predict 実験またはビジュアライゼーション アプリケーションのクリーンなソースとして使用できるようになりました。