
Построение потока данных
Создание потока данных
Начните с создания нового потока данных.
-
В меню средства запуска выберите Аналитика > Создать или Аналитика > Подготовка данных.
-
Щелкните Поток данных.
Откроется диалоговое окно Создание нового потока данных.
-
В соответствующем поле введите Имя для потока данных.
-
В соответствующем раскрывающемся списке выберите Пространство, в котором требуется сохранить поток данных.
-
Добавьте Описание, чтобы изложить цель потока данных.
-
Добавьте несколько тегов в поток данных, чтобы пользователям было легче его найти.
-
Также можно установить флажок Открыть поток данных, чтобы просмотреть поток данных сразу после создания.
-
Нажмите Создать.
Откроется пустой поток данных, выберите вкладку Обзор на панели навигации. Новый поток данных также можно найти позже, выбрав Аналитика > Главная в Qlik Cloud.
Для получения дополнительной информации о том, какие сведения можно найти на странице обзора потока данных, см. раздел Навигация по потокам данных.
Чтобы начать проектирование потока данных, перейдите на вкладку Редактор на панели навигации.
Выбор источника
Первый кирпичик для постройки потока данных ― это источник, содержащий данные, которые требуется подготовить. Можно использовать любые данные из каталога или из подключения.
Добавление данных из набора данных
Наборы данных, хранящиеся в каталоге, могут быть основаны на файлах (.qvd,.xls,.csv,.parquet,.json и т. д.) или на таблицах данных из баз и хранилищ данных. Для ознакомления со списком поддерживаемых форматов см. раздел Форматы файлов.
Наборы данных, созданные в Qlik Talend Data Integration в рамках проекта данных, также можно использовать для создания потоков данных.
Чтобы выбрать набор данных в качестве источника для потока данных, выполните следующие действия.
-
На вкладке Источники левой панели перетащите источник Наборы данных на холст.
Откроется окно Каталог данных, в котором можно просмотреть ранее загруженные наборы данных, или нажмите кнопку Загрузить файл данных, чтобы найти файлы на компьютере и сразу загрузить их.
Примечание к предупреждениюПри загрузке больших файлов, размер которых превышает 300 МБ, процесс может занять некоторое время. Не закрывайте окно, прогресс отображается на счетчике, который вначале может выглядеть пустым. -
Выберите данные для загрузки.
-
Чтобы загрузить все данные из набора данных или продукта данных, установите флажок, соответствующий этой строке.
-
Чтобы загрузить определенные наборы данных из продукта данных, нажмите стрелку рядом с именем продукта данных. Выберите наборы данных, которые вы хотите загрузить.
-
Чтобы загрузить определенные таблицы или поля из набора данных, нажмите Просмотреть поля рядом с именем набора данных. Выберите поля из таблиц, которые требуется загрузить.
-
Чтобы загрузить файлы с компьютера, нажмите Загрузить файл, чтобы найти файлы на компьютере и добавить их в список доступных наборов данных.
Примечание к информацииМожно отфильтровать данные по типу (наборы данных или продукты данных). Продукты данных доступны только в некоторых подписках. Для получения дополнительной информации см. раздел Working with data products. -
-
Используя поиск и фильтры, установите флажок напротив одного или нескольких наборов данных из списка и нажмите Далее.
Если при выборе набора данных, добавленного из подключения в каталоге, имеется несколько соответствующих подключений, можно выбрать нужное подключение в раскрывающемся списке.
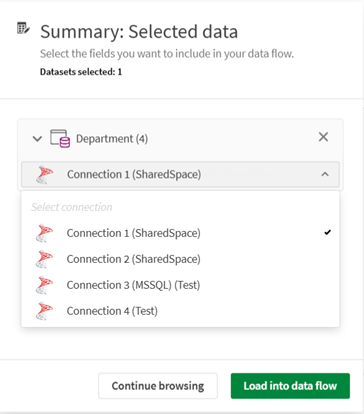
-
На вкладке Сводка можно просмотреть выбранные наборы данных, проверить содержащиеся в них поля и исключить при необходимости некоторые из них. Щелкните Загрузить в поток данных.
Источник или источники добавляются на холст с предупреждением о том, что необходимо подключить их к другим узлам.

После того как источник размещен на холсте, его можно щелкнуть и перейти на панель Свойства, чтобы при необходимости отредактировать выбранные поля, например, если схема источника обновлена.
Загрузка и настройка файла csv
Если в качестве источника данных используется файл csv, ранее загруженный в каталог или загруженный непосредственно в процессе работы, а данные не отображаются должным образом в предварительном просмотре, это может означать, что файл неправильно отформатирован.
Например, данные о клиенте, в которых в качестве разделителя используется запятая, отображаются в одном столбце.

Либо файл был плохо отформатирован, либо разделитель не был правильно определен во время загрузки. Чтобы устранить эту проблему, необходимо перейти к параметрам набора данных.
-
В меню средства запуска выберите Аналитика > Каталог.
-
Откройте набор данных, который требуется исправить.
В обзоре набора данных может отображаться предупреждение о возможной ошибке форматирования.
-
Щелкните ссылку Параметры формата файла в предупреждении или воспользуйтесь меню Дополнительные действия в правом верхнем углу окна обзора.
Как можно видеть, что в качестве разделителя ошибочно выбран вариант Точка с запятой.

-
В раскрывающемся списке Разделитель выберите Запятая.
После выбора правильного разделителя в предварительном просмотре теперь правильно отображаются различные поля.

-
Нажмите Сохранить.
-
Вернитесь в поток данных, удалите устаревший источник данных, если холст не был пустым, и добавьте его снова. На этот раз источник будет отражать правильную конфигурацию набора данных.
Добавление данных из подключения
Qlik Cloud и потоки данных поддерживают различные варианты подключения к источникам данных. Для получения дополнительной информации см. раздел Список поддерживаемых источников данных.
В настоящее время не поддерживаются только следующие типы подключений:
Чтобы выбрать подключение в качестве источника для потока данных, выполните следующие действия.
-
На вкладке Источники левой панели перетащите источник Подключения на холст.
Откроется окно Выбор подключения, в котором можно просмотреть ранее созданные подключения или нажать Создать подключение, чтобы создать новое сразу после аутентификации.
-
Используя поиск и фильтры, установите флажок напротив подключения из списка и нажмите Далее.
-
В зависимости от подключения, можно будет просматривать файлы, указывать путь к данным или выбирать таблицы данных из базы данных.
-
Выбрав источник данных нажмите Сохранить или Готово.
Источник добавляется на холст с предупреждением о том, что его необходимо подключить к другому узлу.

После того как источник размещен на холсте, его можно щелкнуть и перейти на панель Свойства, чтобы при необходимости отредактировать выбранные поля, например, если схема источника обновлена.
Добавление процессоров
Процессоры ― это строительные блоки, которые содержат различные функции подготовки данных, доступные в потоке данных. Они получают входящие данные и возвращают подготовленные данные на следующий этап потока. Процессоры позволяют выполнять сложные операции извлечения, улучшения и очистки различных данных с предварительным просмотром в реальном времени. Для получения дополнительной информации о доступных функциях см. полный Процессоры потоков данных.
Чтобы подключить первый процессор к источнику данных, выполните следующие действия.
-
Можно либо:
-
На вкладке Процессоры левой панели перетащите выбранный процессор на холст рядом с источником.

Потребуется вручную подключить источник к процессору. Создайте ссылку, щелкнув точку справа от узла источника и, удерживая, перетащив ссылку на точку слева от узла процессора.

-
Щелкните меню действий источника, выберите Добавить процессор и щелкните выбранный процессор.

Процессор помещается на холст и автоматически подключается к источнику.
-
-
Щелкните процессор, чтобы начать его настройку на правой панели.
Различные доступные функции и параметры для настройки зависят от конкретного процессора. Для получения дополнительной информации см. документацию по конкретному процессору.
-
Нажмите Сохранить.
-
Добавьте и подключите столько процессоров, сколько необходимо для подготовки данных.
Активируйте переключатель Предварительный просмотр данных на панели Предварительный просмотр, чтобы увидеть влияние процессора на образец данных. Щелкните значок шестеренки, чтобы открыть предварительный просмотр Параметры и настроить размер выборки максимум 10 000 строк. Также можно активировать переключатель Скрипт, чтобы просмотреть эквивалент Qlik Script для потока данных на текущем этапе работы.
Выбор цели
Чтобы завершить поток данных, необходимо подключить последний процессор к целевому узлу. Можно выбрать один из двух типов целей:
-
Файлы данных для файлов, которые хранятся в каталоге в Qlik Cloud.
-
Подключения для записи во внешний источник, добавленный в качестве подключения в Qlik Cloud.
Оба варианта позволяют экспортировать подготовленные данные как файл .qvd, .parquet, .txt или .csv.
Подключение цели к остальному потоку
-
Можно либо:
-
На вкладке Цели левой панели перетащите выбранную цель на холст рядом с последним процессором.

Вручную подключите последний процессор к цели так же, как подключали процессоры ранее.
-
Щелкните меню действий последнего процессора, выберите Добавить цель и щелкните выбранную цель.

-
-
Щелкните цель, чтобы начать ее настройку на правой панели.
Примечание к информацииПри выборе варианта Файлы данных можно выполнять запись в определенную папку нужного пространства. Например, если в личном пространстве создана папка с названием folder_name, используйте folder_name/data_flow_output.qvd в качестве имени файла для цели. Полученный файл будет отправлен прямо в эту папку. -
Нажмите Сохранить.
Теперь, когда настроен минимум один источник данных, одна цель и дополнительный процессор, поток данных можно запускать.
Запуск потока данных
Когда все узлы потока данных подключены, настроены и имеют пометку OK, зеленая галочка показывает, что поток данных считается действительным и может быть запущен. На этом этапе можно воспользоваться кнопкой Предпросмотр скрипта в правом верхнем углу холста, чтобы просмотреть полный скрипт, который будет создан за кадром.

-
Щелкните Запустить поток данных, чтобы начать обработку данных.
Откроется уведомление с информацией о состоянии выполнения.
-
После успешного завершения потока выведенные подготовленные данные можно найти в разных местах в соответствии с настроенной целью:
-
В Каталоге среди других ресурсов и в разделе Выходные данные на экране Обзор потока данных для файлов данных
-
В разделе Выходные на экране Обзор потока данных для наборов данных на основе подключения.
Если поток завершится сбоем, вы можете открыть журнал выполнения, чтобы определить, что пошло не так.
-
Теперь можно использовать эти подготовленные данные в качестве очищенного источника данных для Qlik Predict эксперимента или в приложении для визуализации данных.