
Een gegevensstroom opbouwen
Een gegevensstroom maken
Begin met het maken van een nieuwe gegevensstroom.
-
Selecteer Analyses > Maken of Analyses > Gegevens voorbereiden in het startmenu.
-
Klik op Gegevensstroom.
Het dialoogvenster Nieuwe gegevensstroom maken wordt geopend.
-
Geef in het bijbehorende veld een naam op voor uw gegevensstroom.
-
Selecteer in de bijbehorende vervolgkeuzelijst in welke ruimte u de gegevensstroom wilt opslaan.
-
Voeg een beschrijving toe om het doel van de gegevensstroom vast te leggen.
-
Voeg Labels toe aan de gegevensstroom zodat het makkelijk te vinden is.
-
Schakel desgewent het selectievakje Gegevensstroom openen in om de gegevensstroom direct te tonen nadat deze is gemaakt.
-
Klik op Maken.
Uw lege gegevensstroom wordt geopend en u komt op het tabblad Overzicht van de navigatiekop. De nieuwe gegevensstroom vindt u later ook op de pagina Analyses > Start van Qlik Cloud.
Zie Navigeren door gegevensstromen voor meer informatie over de informatie die u kunt vinden in het overzicht van uw gegevensstroom.
Om te beginnen met het ontwerpen van uw gegevensstroom, gaat u naar het tabblad Editor van de navigatiekop.
Een bron selecteren
De eerste bouwsteen van uw gegevensstroom is de bron die de gegevens bevat die u wilt voorbereiden. U kunt alle gegevens uit uw catalogus of uit een verbinding gebruiken.
Gegevens toevoegen vanuit een gegevensverzameling
Gegevensverzamelingen die in uw catalogus zijn opgeslagen, kunnen gebaseerd zijn op bestanden (.qvd,.xls,.csv,.parquet,.json, etc.) of tabellen uit databases en datawarehouses. Zie Bestandsindelingen voor de lijst met ondersteunde indelingen.
Gegevensverzamelingen die zijn gemaakt in Qlik Talend Data Integration als onderdeel van een gegevensproject kunnen ook worden gebruikt om gegevensstromen te maken.
Om een gegevensverzameling als bron voor uw gegevensstroom te selecteren:
-
Sleep in het tabblad Bronnen van het linkervenster een Gegevensverzamelingen-bron en zet deze op het canvas neer.
Het venster Gegevenscatalogus wordt geopend, waar u kunt bladeren naar eerder geüploade gegevensverzamelingen of klik op Gegevensbestand uploaden om naar bestanden op uw computer te bladeren en deze direct te uploaden.
WaarschuwingBij het uploaden van grote bestanden groter dan 300 MB kan het proces enige tijd duren. Sluit het venster niet, de voortgang wordt weergegeven op een spinner die er in het begin misschien leeg uitziet. -
Selecteer de gegevens die u wilt laden.
-
Om alle gegevens van een dataset of gegevensproduct te laden, selecteert u het selectievakje dat overeenkomt met die rij.
-
Om bepaalde datasets van een gegevensproduct te laden, klikt u op de pijl naast de naam van het gegevensproduct. Selecteer de datasets die u wilt laden.
-
Om bepaalde tabellen of velden uit een gegevensset te laden, klikt u op Velden weergeven naast de naam van de gegevensset. Selecteer de velden die u wilt laden in de tabellen.
-
Om bestanden vanaf uw computer te uploaden, klikt u op Bestand uploaden om op uw computer naar bestanden te bladeren en deze toe te voegen aan de lijst met beschikbare gegevenssets.
InformatieU kunt de gegevens filteren op type (gegevenssets of gegevensproducten). Gegevensproducten zijn alleen beschikbaar in sommige abonnementen. Ga voor meer informatie naar Working with data products. -
-
Gebruik de zoek- en filterfuncties om een of meer gegevensverzamelingen uit uw lijst aan te vinken en klik op Volgende.
Wanneer u een gegevensverzameling selecteert die aan een verbinding in de catalogus is toegevoegd, en er komen meerdere verbindingen overeen, dan kunt u een vervolgkeuzelijst gebruiken om de specifieke verbinding te selecteren die u wilt gebruiken.
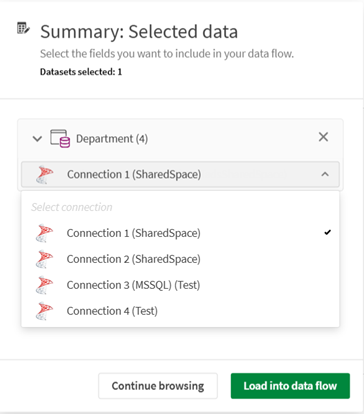
-
Op het tabblad Samenvatting kunt u de gegevensverzamelingen bekijken die u hebt geselecteerd, de velden controleren die ze bevatten en er desgewenst enkele uitsluiten. Klik op Laden in gegevensstroom.
De bron of bronnen worden toegevoegd aan het canvas, met een waarschuwing dat u ze moet verbinden met andere knooppunten.

Zodra een bron op het canvas is geplaatst, kunt u erop klikken en het venster Eigenschappen openen om de geselecteerde velden zo nodig te bewerken, bijvoorbeeld als het schema van de bron is bijgewerkt.
Een csv-bestand uploaden en configureren
Als u een gegevensverzameling in een csv-bestand als bron gebruikt, hetzij eerder geüpload naar uw catalogus of direct geüpload tijdens het proces, en de gegevens worden niet goed weergegeven in het voorbeeld, dan kan dit betekenen dat het bestand niet goed geformatteerd is.
Deze klantgegevens die bijvoorbeeld een komma als scheidingsteken gebruiken, worden in een enkele kolom weergegeven.

Het bestand was slecht geformatteerd of het scheidingsteken werd niet correct gedetecteerd tijdens het uploaden. Om dit probleem op te lossen, moet u naar de instellingen van de gegevensverzameling gaan.
-
Selecteer Analyses > Catalogus in het startmenu.
-
Open de gegevensverzameling om problemen op te lossen.
In het overzicht van de gegevensverzameling ziet u een waarschuwing dat er een mogelijke opmaakfout is.
-
Klik op de link naar de Instellingen bestandsindeling in het waarschuwingsbericht of gebruik het menu Meer acties rechtsboven in het overzicht.
U kunt zien dat het scheidingsteken ten onrechte is ingesteld als Puntkomma.

-
Selecteer Komma in de vervolgkeuzelijst Scheidingsteken.
Met het verwachte scheidingsteken toont het voorbeeld nu correct de verschillende velden.

-
Klik op Opslaan.
-
Verwijder in uw gegevensstroom de verouderde gegevensbron als het canvas niet leeg was, en voeg deze opnieuw toe. Deze keer zal de bron de juiste configuratie voor de gegevensverzameling weergeven.
Gegevens van een verbinding toevoegen
Qlik Cloud en gegevensstromen ondersteunen verschillende verbindingen naar gegevensbronnen. Zie de Lijst van ondersteunde gegevensbronnen voor meer informatie.
De enige verbindingstypen die momenteel niet worden ondersteund, zijn de volgende:
Om een verbinding als bron voor uw gegevensstroom te selecteren:
-
Sleep in het tabblad Bronnen van het linkervenster een Verbindingen-bron en zet deze op het canvas neer.
Het venster Verbinding selecteren wordt geopend, waar u kunt zoeken naar eerder gemaakte verbindingen of klik op Verbinding maken om een nieuwe verbinding te definiëren na de authenticatie.
-
Gebruik de zoek- en filterfuncties om een of meer verbindingen uit uw lijst aan te vinken en klik op Volgende.
-
Afhankelijk van de verbinding kunt u door bestanden bladeren, een pad naar uw gegevens invoeren of tabellen uit een database selecteren.
-
Klik na het selecteren van de gegevensbron op Opslaan of Voltooien.
De bron wordt toegevoegd aan het canvas, met een waarschuwing dat u ze moet verbinden met een ander knooppunt.

Zodra een bron op het canvas is geplaatst, kunt u erop klikken en het venster Eigenschappen openen om de geselecteerde velden zo nodig te bewerken, bijvoorbeeld als het schema van de bron is bijgewerkt.
Processoren toevoegen
Processoren zijn de bouwstenen die de verschillende functies voor gegevensvoorbereiding bevatten die beschikbaar zijn in een gegevensstroom. Zij ontvangen de binnenkomende gegevens en sturen de voorbereide gegevens terug naar de volgende stap van de gegevensstroom. Met processoren kunt u complexe extraheer-, verbeter- en opschoningsbewerkingen uitvoeren op diverse gegevens met een live voorbeeld. Zie de volledige Processoren voor gegevensstroom voor meer informatie over de beschikbare functies.
Om een eerste processor met uw gegevensbron te verbinden:
-
U kunt ofwel:
-
Sleep op het tabblad Processoren van het linkervenster de processor van uw keuze en zet deze op het canvas naast uw bron.

U moet de bron en de processor handmatig verbinden. Maak een koppeling door op de punt rechts van het bronknooppunt te klikken, deze vast te houden en de koppeling naar de punt links van het processorknooppunt te slepen.

-
Klik op het actiemenu van de bron, selecteer Processor toevoegen en klik op de gewenste processor.

De processor wordt op het canvas geplaatst en automatisch verbonden met de bron.
-
-
Klik op de processor om deze in het rechtervenster te configureren.
De verschillende beschikbare functies en de te configureren parameters zijn afhankelijk van elke processor. Zie de documentatie van de afzonderlijke processor voor meer informatie.
-
Klik op Opslaan.
-
Voeg zoveel processoren toe als nodig en verbind ze met elkaar om uw gegevens voor te bereiden.
Activeer de schakelaar Gegevensvoorbeeld in het venster Voorbeeld om de effecten van een processor op een voorbeeld van uw gegevens te zien. Klik op het tandwielpictogram om de voorbeeldinstellingen te openen en configureer de steekproefgrootte tot 10000 rijen. U kunt ook de schakelaar Script activeren om op dit punt naar het Qlik Script-equivalent van uw gegevensstroom te kijken.
Een doel selecteren
Om de gegevensstroom te beëindigen, moet u de laatste processor verbinden met een doelknooppunt. U kunt kiezen uit twee doeltypen:
-
Gegevensbestanden voor bestanden die zijn opgeslagen in uw catalogus in Qlik Cloud.
-
Verbindingen om in een externe bron te schrijven die is toegevoegd als verbinding in Qlik Cloud.
Met beide opties kunt u de voorbereide gegevens exporteren als .qvd-, .parquet-, .txt- of .csv-bestand.
Om een doel met de rest van de stroom te verbinden:
-
U kunt ofwel:
-
Sleep op het tabblad Doelen van het linkervenster het doeltype van uw keuze en zet deze op het canvas naast de laatste processor.

Verbind de laatste processor handmatig met het doel op dezelfde manier waarop u eerder processoren hebt verbonden.
-
Klik op het actiemenu van de bron, selecteer Doel toevoegen en klik op het gewenste doel.

-
-
Klik op het doel om deze in het rechtervenster te configureren.
InformatieIn het geval van Gegevensbestanden kunt u in een specifieke map van de gewenste ruimte schrijven. Als u bijvoorbeeld een map genaamd folder_name in uw persoonlijke ruimte hebt gemaakt, gebruik dan folder_name/data_flow_output.qvd als bestandsnaam voor uw doel. Het resulterende bestand wordt direct naar uw map gestuurd. -
Klik op Opslaan.
Met minimaal één bron, één doel en een optionele processor kan de gegevensstroom nu worden uitgevoerd.
De gegevensstroom uitvoeren
Wanneer alle knooppunten van uw gegevensstroom verbonden en geconfigureerd zijn en als OK gemarkeerd zijn, geeft een groen vinkje aan dat de gegevensstroom als geldig wordt beschouwd en uitgevoerd kan worden. Op dit punt kunt u de knop Voorbeeld script rechtsboven op het canvas gebruiken om het volledige script te bekijken dat op de achtergrond zal worden gegenereerd.

-
Klik op Gegevensstroom uitvoeren om de gegevens te verwerken.
Er wordt een melding geopend om de status van de uitvoering weer te geven.
-
Wanneer de gegevensstroom met succes is voltooid, kunnen de voorbereide gegevens die zijn uitgevoerd op verschillende plaatsen worden gevonden, afhankelijk van het doel:
-
In uw catalogus tussen uw andere bedrijfsmiddelen en in de sectie Uitvoer van het gegevensstroomoverzicht voor gegevensbestanden
-
In de sectie Uitvoer van het gegevensstroomoverzicht voor op verbindingen gebaseerde gegevensverzamelingen.
Mocht de flow mislukken, dan kunt u het uitvoeringslogboek openen om u te helpen identificeren wat er misging.
-
U kunt deze voorbereide gegevens nu gebruiken als schone gegevensbron voor een Qlik Predict-experiment, of in een visualisatie-applicatie.