
Tworzenie przepływu danych
Tworzenie przepływu danych
Zacznij od utworzenia nowego przepływu danych.
-
Z menu Launcher wybierz kolejno Analytics> Utwórz lub Analytics > Przygotowanie danych.
-
Kliknij Przepływ danych.
Zostanie otwarte okno dialogowe Tworzenie nowego przepływu danych.
-
W odpowiednim polu wprowadź Nazwę przepływu danych.
-
Z listy rozwijanej wybierz Przestrzeń, w której chcesz zapisać przepływ danych.
-
Dodaj Opis, aby udokumentować cel przepływu danych.
-
Dodaj do przepływu danych Znaczniki, aby można go było łatwiej znaleźć.
-
Opcjonalnie zaznacz pole wyboru Otwórz przepływ danych, aby bezpośrednio wyświetlić przepływ danych po jego utworzeniu.
-
Kliknij Utwórz.
Pusty przepływ danych zostanie otwarty i przejdziesz do karty Przegląd w nagłówku nawigacji. Nowy przepływ danych można również znaleźć później na stronie Analytics > Strona główna w Qlik Cloud.
Więcej na temat informacji, które można znaleźć w przeglądzie przepływu danych, zawiera temat Nawigacja po przepływach danych.
Aby rozpocząć projektowanie przepływu danych, przejdź do karty Edytor w nagłówku nawigacji.
Wybieranie źródła
Pierwszym elementem składowym przepływu danych jest źródło zawierające dane, które chcesz przygotować. Można użyć dowolnych danych z katalogu lub z połączenia.
Dodawanie danych z zestawu danych
Zestawy danych przechowywane w katalogu mogą być oparte na plikach (.qvd, .xls, .csv, .parquet, .json itp.) lub tabelach z baz danych i hurtowni danych. Lista obsługiwanych formatów znajduje się w sekcji Formaty plików.
Zestawy danych utworzone w Qlik Talend Data Integration w ramach projektu danych mogą być również wykorzystywane do tworzenia przepływów danych.
Aby wybrać zestaw danych jako źródło przepływu danych:
-
Z karty Źródła w lewym panelu przeciągnij źródło Zestawy danych i upuść je na kanwie.
Zostanie otwarte okno Katalog danych, w którym można wyszukać wcześniej przesłane zestawy danych lub kliknąć przycisk Prześlij plik danych, aby wyszukać pliki na komputerze i przesłać je na bieżąco.
OstrzeżenieW przypadku przesyłania dużych plików o rozmiarze przekraczającym 300 MB proces ten może zająć trochę czasu. Nie zamykaj okna — postęp jest wyświetlany na okrągłym wskaźniku przetwarzania, który na początku może wyglądać na pusty. -
Wybierz dane do załadowania.
-
Aby załadować wszystkie dane z zestawu danych lub produktu danych, zaznacz pole wyboru odpowiadające temu wierszowi.
-
Aby załadować określone zestawy danych z produktu danych, kliknij strzałkę obok nazwy produktu danych. Wybierz zestawy danych, które chcesz załadować.
-
Aby załadować określone tabele lub pola z zestawu danych, kliknij Wyświetl pola obok nazwy zestawu danych. Wybierz pola z tabel do załadowania.
-
Aby przesłać pliki z komputera, kliknij Prześlij plik, aby przeglądać pliki na komputerze i dodać je do listy dostępnych zestawów danych.
InformacjaMożesz filtrować dane według typu (zestawy danych lub produkty danych). Produkty danych są dostępne tylko w niektórych subskrypcjach. Więcej informacji zawiera temat Working with data products. -
-
Korzystając z wyszukiwania i filtrów, zaznacz pole wyboru przed jednym lub kilkoma zestawami danych z listy i kliknij przycisk Dalej.
Podczas wybierania zestawu danych dodanego z połączenia w katalogu, gdy pasuje większa liczba połączeń, można użyć listy rozwijanej, aby wybrać konkretne połączenie.
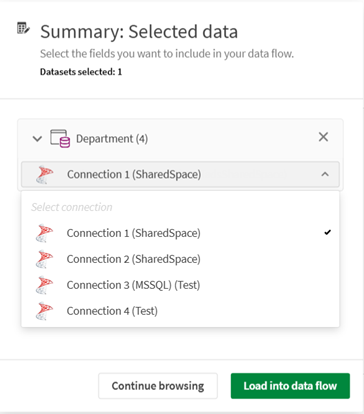
-
Na karcie Podsumowanie można przejrzeć wybrane zestawy danych, sprawdzić zawarte w nich pola i wykluczyć niektóre z nich. Kliknij Załaduj do przepływu danych.
Źródła są dodawane do kanwy z ostrzeżeniem o konieczności połączenia ich z innymi węzłami.

Po umieszczeniu źródła na kanwie można je kliknąć i uzyskać dostęp do panelu Właściwości, aby w razie potrzeby edytować wybrane pola, jeśli na przykład schemat źródła został zaktualizowany.
Przesyłanie i konfigurowanie pliku csv
Jeśli jako źródło danych używany jest zestaw danych w formacie csv, wcześniej przesłany do katalogu lub przesłany bezpośrednio w trakcie procesu, a dane nie są wyświetlane prawidłowo w podglądzie, może to oznaczać, że plik nie jest prawidłowo sformatowany.
Na przykład te dane klienta, które używają przecinka jako separatora, są wyświetlane w jednej kolumnie.

Plik został źle sformatowany lub separator nie został poprawnie wykryty podczas przesyłania. Aby rozwiązać ten problem, należy przejść do ustawień zestawu danych.
-
Z menu Launcher wybierz Analytics > Katalog.
-
Otwórz zestaw danych do naprawy.
W przeglądzie zestawu danych można zobaczyć ostrzeżenie o potencjalnym błędzie formatowania.
-
Kliknij łącze do Ustawień formatu pliku z komunikatu ostrzegawczego lub użyj menu Więcej działań w prawym górnym rogu przeglądu.
Widać, że separator został błędnie ustawiony jako Średnik.

-
Z listy rozwijanej Ogranicznik wybierz Przecinek.
Podgląd z oczekiwanym separatorem poprawnie pokazuje teraz różne pola.

-
Kliknij przycisk Zapisz.
-
Po powrocie do przepływu danych usuń nieaktualne źródło danych, jeśli kanwa nie była pusta, i dodaj je ponownie. Tym razem źródło będzie odzwierciedlać właściwą konfigurację zestawu danych.
Dodawanie danych z połączenia
Qlik Cloud i przepływy danych obsługują różne połączenia ze źródłami danych. Więcej informacji można znaleźć na Liście obsługiwanych źródeł danych.
Jedynymi obecnie nieobsługiwanymi typami połączeń są:
Aby wybrać połączenie jako źródło przepływu danych:
-
Z karty Źródła w lewym panelu przeciągnij źródło Połączenia i upuść je na kanwie.
Otworzy się okno Wybierz połączenie, w którym można przeglądać wcześniej utworzone połączenia lub kliknąć Utwórz połączenie, aby zdefiniować nowe połączenie po uwierzytelnieniu.
-
Korzystając z wyszukiwania i filtrów, zaznacz pole wyboru połączenia z listy i kliknij przycisk Dalej.
-
W zależności od połączenia będziesz można przeglądać pliki, wprowadzić ścieżkę do danych lub wybierać tabele z bazy danych.
-
Po wybraniu danych źródłowych kliknij przycisk Zapisz lub Zakończ.
Źródło zostanie dodane do kanwy z ostrzeżeniem o konieczności połączenia go z innym węzłem.

Po umieszczeniu źródła na kanwie można je kliknąć i uzyskać dostęp do panelu Właściwości, aby w razie potrzeby edytować wybrane pola, jeśli na przykład schemat źródła został zaktualizowany.
Dodawanie procesorów
Procesory są jak klocki do układania, które zawierają różne funkcje przygotowania dostępne w przepływie danych. Odbierają one przychodzące dane i zwracają przygotowane dane do następnego kroku przepływu. Procesory umożliwiają wykonywanie złożonych operacji wyodrębniania, ulepszania i czyszczenia różnorodnych danych z podglądem na żywo. Więcej informacji na temat dostępnych funkcji można znaleźć w temacie Procesory przepływu danych.
Aby połączyć pierwszy procesor ze źródłem danych:
-
Możesz wybrać jedną z opcji:
-
Na karcie Procesory w lewym panelu przeciągnij wybrany procesor i upuść go na kanwie obok źródła.

Konieczne będzie ręczne połączenie źródła i procesora. Utwórz łącze, klikając kropkę po prawej stronie węzła źródłowego oraz przytrzymując i przeciągając łącze do kropki po lewej stronie węzła procesora.

-
Kliknij menu działań źródła, wybierz Dodaj procesor i kliknij wybrany procesor.

Procesor jest umieszczony na płótnie i automatycznie połączony ze źródłem.
-
-
Kliknij procesor, aby rozpocząć jego konfigurację w prawym panelu.
Różne dostępne funkcje i parametry do skonfigurowania zależą od poszczególnych procesorów. Więcej informacji na ten temat można znaleźć w dokumentacji określonego procesora.
-
Kliknij przycisk Zapisz.
-
Dodaj i połącz tyle procesorów, ile potrzeba do przygotowania danych.
Aktywny przełącznik Podgląd danych w panelu Podgląd pozwala zobaczyć efekty działania procesora na próbce danych. Kliknij ikonę koła zębatego, aby otworzyć Ustawienia podglądu i skonfigurować rozmiar próbki do 10 000 wierszy. Można również aktywować przełącznik Skrypt, aby wyświetlić odpowiednik skryptu Qlik dla przepływu danych w tym punkcie.
Wybieranie celu
Aby zakończyć przepływ danych, należy połączyć ostatni procesor z węzłem docelowym. Do wyboru są dwa typy miejsc docelowych:
-
Pliki danych dla plików przechowywanych w katalogu w usłudze Qlik Cloud.
-
Połączenia do zapisu w zewnętrznym źródle dodane jako połączenie w Qlik Cloud.
Obie opcje pozwalają eksportować przygotowane dane jako plik .qvd, .parquet, .txt lub .csv.
Aby połączyć miejsce docelowe z resztą przepływu:
-
Możesz wybrać jedną z opcji:
-
Na karcie Procesory w lewym panelu przeciągnij wybrany procesor i upuść go na kanwie obok źródła.

Ręcznie połącz ostatni procesor z miejscem docelowym tak samo jak poprzednio.
-
Kliknij menu działań źródła, wybierz Dodaj miejsce docelowe i kliknij wybrany procesor.

-
-
Kliknij miejsce docelowe, aby rozpocząć jego konfigurację w prawym panelu.
InformacjaW przypadku Plików danych można zapisywać w określonym folderze żądanej przestrzeni. Jeśli na przykład masz folder o nazwie nazwa_folderu w swojej przestrzeni prywatnej, użyj nazwa_folderu/wyjscie-przeplywu_danych.qvd jako nazwy pliku docelowego. Plik wynikowy zostanie przesłany bezpośrednio do Twojego folderu. -
Kliknij przycisk Zapisz.
Mając co najmniej jedno źródło danych, jedno miejsce docelowe i opcjonalny procesor, można teraz uruchomić przepływ danych.
Uruchamianie przepływu danych
Gdy wszystkie węzły przepływu danych są połączone, skonfigurowane i oznaczone jako OK, zielony znacznik wyboru wskazuje, że przepływ danych jest uznany za prawidłowy i może zostać uruchomiony. W tym momencie można użyć przycisku Podgląd skryptu w prawym górnym rogu kanwy, aby spojrzeć na pełny skrypt, który zostanie wygenerowany w tle.

-
Kliknij przycisk Uruchom przepływ, aby rozpocząć przetwarzanie danych.
Zostanie wyświetlone powiadomienie informujące o statusie uruchomienia.
-
Po pomyślnym zakończeniu przepływu przygotowane dane wyjściowe można znaleźć w różnych miejscach w zależności od miejsca docelowego:
-
W Katalogu wśród innych zasobów oraz w sekcji Dane wyjściowe w Przeglądzie przepływu danych w przypadku plików danych
-
W sekcji Dane wyjściowe w Przeglądzie przepływu danych w przypadku zestawów danych opartych na połączeniu.
Jeśli przepływ zakończy się niepowodzeniem, możesz otworzyć dziennik uruchomienia, aby pomóc Ci zidentyfikować, co poszło nie tak.
-
Tak przygotowane dane można teraz wykorzystać jako czyste źródło danych do eksperymentu Qlik Predict lub w aplikacji do wizualizacji.