
Spiegeln von Daten in einem Cloud Data Warehouse
Mit Spiegelaufgaben können Sie über Cloud Data Warehouses Daten abfragen, die in Ihrem Qlik Open Lakehouse gespeichert sind. Die Daten werden in Ihrem Warehouse ohne Duplizierung wiedergegeben. Gespiegelte Tabellen sorgen dafür, dass die Speicher- und Entwicklungskosten minimal sind und eine einzige „Single Source of Truth“ erhalten bleibt.
Nach dem Onboarding Ihrer Daten in ein Qlik Open Lakehouse können Sie die Daten mithilfe von Spiegeltabellen in Ihrem Cloud Data Warehouse spiegeln. Die Daten in Iceberg können mit einer Abfrage-Engine abgefragt werden, die Iceberg nativ unterstützt, wie z. B. Amazon Athena. Spiegeltabellen sind jedoch ideal, wenn Sie die offene Iceberg-Lakehouse-Architektur implementieren und die Abfrage-Engine Ihres Data Warehouse weiterhin verwenden möchten. Die Spiegeldatenaufgabe automatisiert den Prozess, Iceberg-Tabellen in Snowflake zugänglich zu machen, indem sie als externe Tabellen und Ansichten in Ihrem Data Warehouse deklariert werden. Das Data Warehouse bezeichnet die Iceberg-Tabelle als externe Ansicht, weil es die Tabelle nicht verwaltet, sondern nur aus ihr liest. Mit externen Tabellen und Ansichten können Sie Ihre Iceberg-Daten in Ihrem Data Warehouse abfragen, ohne Daten oder die Verwaltung Ihrer Tabellen zu Ihrem Data Warehouse zu migrieren.
Die Spiegelaufgabe führt die erforderlichen DDL-Anweisungen aus, um die externen Tabellen und Ansichten zu erstellen. Die Tabelle (Schema) wird im Data Warehouse zusammen mit den Änderungs- und Verlaufstabellen angezeigt, aber wenn Sie sich die Tabellendefinition ansehen, wird sie als eine Ansicht angezeigt, die über der externen Tabelle erstellt wurde. Datennutzer können die Ansichten so abfragen, als ob die Daten in ihrer Data Warehouse-Umgebung gespeichert wären. Gespiegelte Daten bieten eine hohe Leistung, da Qlik die Daten weiterhin verwaltet und optimiert.
Die folgenden Data Warehouses werden unterstützt:
-
Amazon Redshift
-
Databricks
-
Snowflake
Spiegelung in mehrere Data Warehouses
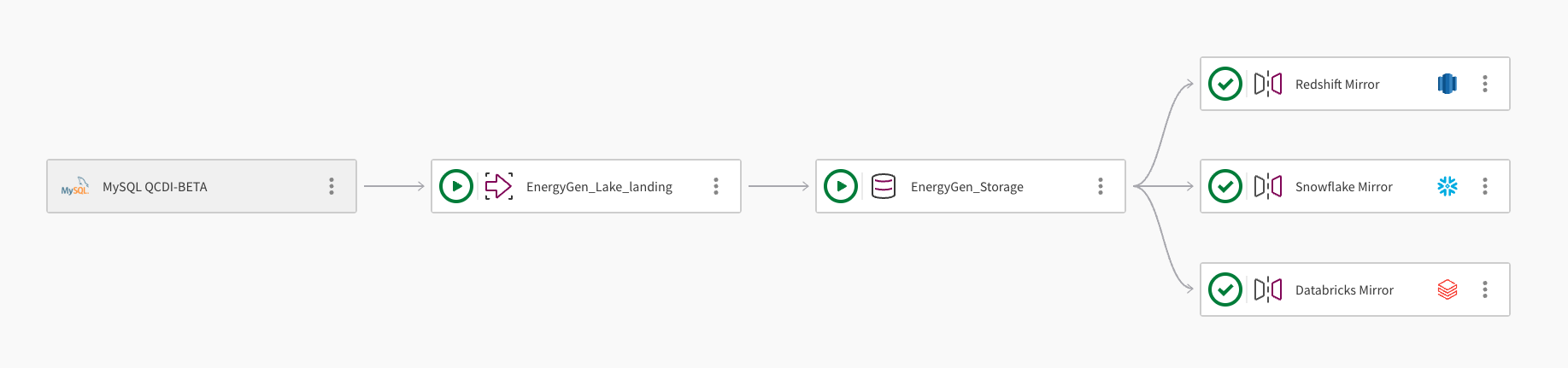
Ein einzelner Datensatz kann in mehrere Cloud Data Warehouses gespiegelt werden. Die folgende Abbildung zeigt die Verwendung eines Qlik Open Lakehouse Pipeline-Projekts zum Spiegeln von Daten in Amazon Redshift, Snowflake und Databricks:
-
Die Pipeline liest Daten aus einer MySQL-Datenbank über die Verbindung MySQL QCDI-BETA ein.
-
Die Lake-Bereitstellungsaufgabe EnergyGen_Lake_landing liest die Rohdaten in ein Amazon S3-Bucket ein.
-
Als Nächstes kopiert die Speicheraufgabe EnergyGen_Storage die Daten an einen S3-Standort, um die Daten im Apache Iceberg-Format zu speichern.
-
Die Spiegeldatenaufgabe Redshift-Spiegel erstellt die notwendigen Ansichten, um die Abfrage der Daten aus Amazon Redshift zu ermöglichen, und aktualisiert die Daten automatisch.
-
Eine zweite Spiegeldatenaufgabe mit der Bezeichnung Snowflake-Spiegel wird hinzugefügt, um die notwendigen Ansichten zu erstellen, damit die Daten aus Snowflake abgefragt werden können.Die Spiegelaufgabe verwendet den von Qlik verwalteten Aktualisierungsmechanismus, der nachgelagerte Umwandlungen ermöglicht.
-
Eine dritte Mirror-Datenaufgabe, Databricks-Spiegel, wird hinzugefügt, um die Abfrage der Daten aus Databricks über einen Fremdkatalog im Databricks Unity Catalog zu ermöglichen.
Aktualisierungsmechanismus
Der Ihnen zur Verfügung stehende Aktualisierungsmechanismus hängt von Ihrem Cloud Data Warehouse-Anbieter ab (siehe folgende Beschreibung).
Amazon Redshift
In Amazon Redshift gespiegelte Daten werden automatisch aktualisiert, und es ist nicht erforderlich, die Aufgabe zu planen oder auszuführen. Alle Tabellen- und Ansichtsnamen werden in Amazon Redshift in Kleinbuchstaben umgewandelt, da Qlik Open Lakehouse keine Objektnamen (Datenbank, Schema, Tabelle oder Spalte) unterstützt, bei denen die Groß- und Kleinschreibung beachtet wird.
Snowflake
Snowflake verweist auf die Metadaten, die den neuesten Schnappschuss der verfügbaren Daten in Iceberg wiedergeben. Es gibt zwei Möglichkeiten, die Metadaten zu aktualisieren:
-
Von Qlik verwaltet: Diese Option erfordert ein aktives Snowflake-Warehouse und beinhaltet Überwachung und Datenvorschau. Wählen Sie diese Option, wenn Sie nachgelagerte Umwandlungen erstellen und die Aufgabe überwachen und planen möchten. Qlik besitzt den Vorgang der Metadatenaktualisierung, sodass Sie diesen manuell konfigurieren können, z. B. so, dass er alle 30 Minuten ausgeführt wird. Diese Option ist besonders wichtig für Umwandlungen mit mehreren Tabellen, da die Metadaten für alle Tabellen gleichzeitig aktualisiert werden. Sie verlieren zwar einen Teil des Echtzeitgewinns, den die von Snowflake verwaltete Aktualisierung bietet, aber Sie behalten die Konsistenz zwischen den Tabellen bei. Bei Umwandlungen mit mehreren Tabellen können Sie die Aktualisierung so oft wie nötig auslösen. Qlik empfiehlt, dass Sie die ereignisbasierte Auslösung für nachgelagerte Umwandlungsaufgaben festlegen, die der geplanten Spiegelaufgabe folgen.
-
Von Snowflake verwaltet: Ein serverloser Vorgang, der die Snowpipe-Infrastruktur nutzt, ohne ein Berechnungs-Warehouse zu benötigen oder zu aktivieren. Diese Option wird empfohlen, wenn Sie keine nachgelagerten Umwandlungen benötigen. Das Aktualisierungsintervall wird konfiguriert, wenn Sie die Snowflake-Katalogintegration erstellen. Um den Status der automatischen Aktualisierung zu überwachen, fragen Sie in Snowflake den Wert SYSTEM$AUTO_REFRESH_STATUS ab. Qlik ist nicht mehr Besitzer des Prozesses und kann Aufgaben dieses Typs nicht überwachen.
The parquet file 'tg_open_lakehouse/bronze/sales/tables/tg_sales_ingestion_bronze__internal.order_details__internal/data/hdr__scd_partition=asset_state/2025_09_12_00_37_asset_state_apply-4bcbb2eb-4ad3-4d88-bea6-ea611576624e.parquet' for table 'OPENLAKEHOUSE."snowflake_mirror__internal"."ext__order_details"' was inaccessible.
Databricks
Der Databricks-Fremdkatalog liest Iceberg-Metadaten direkt aus AWS Glue. Nachdem Sie die Spiegelaufgabe ausgeführt haben, steht der neueste Datenschnappschuss in Databricks ohne zusätzliche Aktualisierungsschritte zur Abfrage zur Verfügung.
Voraussetzungen
Die folgenden Anforderungen gelten für alle unterstützten Data Warehouse-Ziele:
-
Eine Spiegeldatenaufgabe kann erst hinzugefügt werden, nachdem eine Speicheraufgabe in einem Qlik Open Lakehouse Projekt erstellt wurde.
-
Eine Speicheraufgabe kann mehrere Spiegeldatenaufgaben umfassen, wobei jede auf ein anderes Data Warehouse abzielt.
-
Eine Spiegeldatenaufgabe kann nur mit einer Speicheraufgabe verknüpft werden.
-
Zur Durchführung von Umwandlungen erstellen Sie ein Data Warehouse-Projekt und verwenden die Spiegeldatenaufgabe als Quelle. Das Projekt und die Spiegelaufgabe müssen dieselbe Data Warehouse-Plattform verwenden, wie z. B. Redshift.
Konfigurieren Sie zum Spiegeln der Daten die Einstellungen für Ihr Ziel-Data Warehouse.
Amazon Redshift
-
Eine Verbindung zu der Data Warehouse-Datenbank, in die Sie Ihre Daten spiegeln möchten. Optional können Sie während der Erstellung der Spiegelaufgabe eine neue Verbindung erstellen. Weitere Informationen finden Sie unter Amazon Redshift.
-
Eine von Redshift übernommene IAM-Rolle mit Leseberechtigungen für den Glue Data Catalog. Das folgende Skript stellt die erforderlichen Berechtigungen für den Zugriff auf Ihren Katalog bereit. Stellen Sie sicher, dass Sie <ICEBERG_BUCKET_NAME> durch den Bucket-Namen ersetzen:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "glue:GetDatabase", "glue:GetDatabases", "glue:GetTable", "glue:GetTables", "glue:GetPartition", "glue:GetPartitions" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "s3:GetObject", "s3:ListBucket" ], "Resource": [ "arn:aws:s3:::<ICEBERG_BUCKET_NAME>", "arn:aws:s3:::<ICEBERG_BUCKET_NAME>/*" ] } }Diese Rolle erfordert die folgende Vertrauensbeziehung:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "redshift-serverless.amazonaws.com" }, "Action": "sts:AssumeRole" }, { "Effect": "Allow", "Principal": { "Service": "redshift.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }InformationshinweisWeitere Informationen finden Sie unter IAM-Richtlinien für Amazon Redshift Spectrum. -
Ein externes Schema in Redshift, das auf die Datenbank der Speicheraufgabe verweist. Sie müssen ein externes Redshift-Schema erstellen, indem Sie den Befehl CREATE EXTERNAL SCHEMA ausführen und auf die interne Datenbank des quellseitigen Iceberg-Speicheraufgabe verweisen. Externe Verbraucher sollten die Verbrauchsansichten des Spiegelaufgabenschemas verwenden. Erstellen Sie Ihr externes Schema mithilfe der folgenden Syntax und stellen Sie sicher, dass es sich bei der Eigenschaft DATABASE um die von der Speicheraufgabe erstellte Datenbank handelt:
CREATE EXTERNAL SCHEMA <local_schema_name>
FROM DATA CATALOG
DATABASE '<database_name>'
IAM_ROLE 'arn:aws:iam::<AWS account-id>:role/<role-name>'
REGION '<aws-region>'
Snowflake
-
Eine Verbindung zu der Data Warehouse-Datenbank, in die Sie Ihre Daten spiegeln möchten. Optional können Sie während der Erstellung der Spiegelaufgabe eine neue Verbindung erstellen. Weitere Informationen finden Sie unter Snowflake.
-
Ein externes Snowflake-Volume. Dadurch erhält Snowflake einen eingeschränkten Zugriff auf Ihren S3-Speicherort. Informationen zum Konfigurieren des Volumes finden Sie unter Konfigurieren eines externen Volumes für Amazon S3.
-
Eine AWS Glue Data Catalog-Integration. Dadurch kann Snowflake eine Verbindung zu Daten herstellen, die im offenen Iceberg-Tabellenformat in Ihrem Objektspeicher gespeichert sind. Informationen zum Konfigurieren einer Katalogintegration finden Sie unter Konfigurieren einer Katalogintegration für AWS Glue.
Databricks
-
Eine Verbindung zu dem Databricks-Arbeitsbereich, in dem Sie Ihre Daten spiegeln möchten. Optional können Sie während der Erstellung der Spiegelaufgabe eine neue Verbindung erstellen. Weitere Informationen finden Sie unter Databricks.
-
Die folgenden Objekte müssen in AWS und Databricks konfiguriert werden, bevor die Spiegelaufgabe erstellt wird:
-
Eine Glue-Verbindung in AWS. Dies ermöglicht Databricks, Metadatenabfragen über den AWS Glue Data Catalog zu föderieren. Weitere Informationen finden Sie unter AWS Glue: Verbinden mit Daten.
-
Mit AWS verknüpfte Dienstanmeldedaten in Databricks Unity Catalog. Dies erteilt Databricks die Berechtigungen, die für den Zugriff auf AWS-Dienste erforderlich sind. Weitere Informationen finden Sie unter Databricks > Dienstanmeldedaten erstellen.
-
Ein externer Speicherort in Databricks Unity Catalog, der auf Ihren S3-Bucket verweist. Dies autorisiert Databricks, Iceberg-Daten in dem S3-Pfad zu lesen, der von der Speicheraufgabe verwaltet wird. Weitere Informationen finden Sie unter Databricks > Externe Speicherorte.
-
Ein Fremdkatalog im Databricks Unity Catalog. Dies macht die in AWS Glue registrierten Iceberg-Tabellen als abfragbare Tabellen in Databricks verfügbar. Weitere Informationen finden Sie unter Databricks > Fremdkataloge.
-
Erstellen einer Spiegeldatenaufgabe
Um Daten in Ihrem Data Warehouse zu spiegeln, gehen Sie wie folgt vor:
-
Öffnen Sie das Projekt, das die Speicheraufgabe für die Daten enthält, die Sie spiegeln möchten.
-
Klicken Sie auf
 Weitere Aktionen für die Speicheraufgabe. Wählen Sie Daten spiegeln aus und konfigurieren Sie sie:
Weitere Aktionen für die Speicheraufgabe. Wählen Sie Daten spiegeln aus und konfigurieren Sie sie: -
Name: Geben Sie einen Namen für Ihre Spiegelaufgabe ein.
-
Beschreibung: Beschreiben Sie optional den Zweck der Aufgabe.
-
Data Warehouse: Wählen Sie Ihr Ziel-Data Warehouse aus.
-
Verbindung:
-
Um eine bestehende Verbindung zu verwenden, klicken Sie auf Auswählen, um das Dialogfeld Sichere Quellverbindung zu öffnen. Wählen Sie den Bereich, in dem sich Ihre Verbindung befindet, und dann die Verbindung aus. Klicken Sie auf Bearbeiten, um die Eigenschaften der Verbindung zu ändern.
-
Um eine neue Verbindung zu erstellen, klicken Sie auf Verbindung erstellen, um das Dialogfeld Verbindung erstellen zu öffnen, und folgen Sie den Anweisungen.
-
-
Datenbank: Geben Sie den Namen der Datenbank ein, in der Sie die Daten spiegeln möchten.
-
So führen Sie eine Spiegelung in Amazon Redshift durch:
-
Externes Schema: Geben Sie den Namen des Schemas ein, in dem die Ansichten erstellt werden.
InformationshinweisAlle Tabellen- und Ansichtsnamen werden in Amazon Redshift in Kleinbuchstaben umgewandelt.
-
-
So führen Sie eine Spiegelung in Snowflake durch:
-
Externes Snowflake-Volume: Geben Sie den Namen des in Snowflake erstellten externen Volumes ein.
-
Snowflake-Katalogintegration: Geben Sie den Namen der in Snowflake erstellten Katalogintegration ein.
-
Wählen Sie aus, wie Sie Ihre Daten in Snowflake aktualisieren möchten:
-
Von Qlik verwaltet: Wählen Sie diese Option, wenn Sie nachgelagerte Umwandlungen erstellen möchten. Dies erfordert ein aktives Snowflake Warehouse und wird von Qlik überwacht.
-
Von Snowflake verwaltet: Wählen Sie diese Option, wenn Sie keine nachgelagerten Umwandlungen erstellen möchten. Ein Snowflake-Warehouse ist nicht erforderlich und wird daher nicht von Qlik überwacht. Dieser Vorgang wird in Snowflake verwaltet und überwacht.
-
-
-
So führen Sie eine Spiegelung in Databricks durch:
-
Databricks-Katalog: Geben Sie den Namen des Databricks Unity Catalog ein. Dies ist normalerweise hive_metastore.
-
Databricks-Fremdkatalog: Geben Sie den Namen des Databricks-Fremdkatalogs ein, der mit AWS Glue verbunden ist.
-
-
Klicken Sie auf OK, um die Spiegelaufgabe zu erstellen und zur Speicheraufgabe in Ihrer Pipeline hinzuzufügen.
-
Klicken Sie auf
Weitere Aktionen für die Spiegelaufgabe und wählen Sie Öffnen aus. Vergewissern Sie sich, dass Sie die Ansicht Design anzeigen. -
Um eine Teilmenge der verfügbaren Datensätze auszuwählen, klicken Sie auf Quelldaten auswählen und entfernen Sie alle unerwünschten Datensätze.
-
Klicken Sie auf Vorbereiten, um die externen Objekte zu erstellen und die Daten zu spiegeln.
Durchführen von Umwandlungen
Wenn Sie Ihre Daten umwandeln müssen, können Sie ein Redshift-, Snowflake- oder Databricks-Projekt erstellen und eine Spiegeldatenaufgabe innerhalb Ihres Qlik Open Lakehouse Projekts als Quelle verwenden. Die Quelle der Spiegelaufgabe muss mit der Cloud Data Warehouse-Plattform des Projekts übereinstimmen. Wenn Sie beispielsweise ein Amazon Redshift-Projekt zur Durchführung von Umwandlungen erstellen, müssen Sie eine Amazon Redshift-Spiegeldatenaufgabe als Quelle verwenden.
Anzeigen von Aufgabeninformationen
Klicken Sie in der Menüleiste auf ![]() , um Aufgabeninformationen anzuzeigen, wie zum Beispiel:
, um Aufgabeninformationen anzuzeigen, wie zum Beispiel:
-
Besitzer
-
Bereich
-
Datenplattform
-
Projekt-ID
-
Datenaufgaben-Laufzeit-ID
Löschen einer Spiegeldatenaufgabe
Wenn Sie eine Spiegelaufgabe löschen, werden die von der Spiegelaufgabe erstellten internen Schemas und Ansichten gelöscht. Externe Schemas und Tabellen in Redshift werden nicht gelöscht. Wenn eine Tabelle beispielsweise aus AWS Glue gelöscht wird, weil ein Benutzer den Datensatz im Speicher entfernt oder die gesamte Speicheraufgabe löscht, wird die Änderung automatisch im externen Redshift-Schema übernommen. Die Tabelle wird entfernt und muss nicht separat gelöscht werden. Es wird dazu geraten, das externe Schema vollständig zu löschen, wenn es nicht mehr verwendet wird.
Gehen Sie zum Löschen einer Spiegeldatenaufgabe folgendermaßen vor:
-
Klicken Sie für die Spiegeldatenaufgabe, die Sie löschen möchten, auf das Menü
 Weitere Aktionen und wählen Sie Löschen aus.
Weitere Aktionen und wählen Sie Löschen aus. -
Klicken Sie im Bestätigungsdialogfeld auf Löschen.