
Mirroring dei dati in un data warehouse cloud
Le attività di mirror consentono di interrogare i dati memorizzati nel proprio Qlik Open Lakehouse dai propri data warehouse cloud. I dati si riflettono nel warehouse senza duplicazioni. Le tabelle con mirroring garantiscono che i costi di archiviazione e ingegnerizzazione siano minimi e mantengono un'unica fonte di verità.
Dopo l'onboarding dei dati in un Qlik Open Lakehouse, è possibile eseguire il mirroring dei dati nel proprio data warehouse cloud utilizzando le tabelle mirror. I dati in Iceberg possono essere interrogati utilizzando un motore di query che supporta nativamente Iceberg, come Amazon Athena. Tuttavia, le tabelle mirror sono ideali quando si desidera implementare l'architettura lakehouse Iceberg aperta e continuare a utilizzare il motore di query del proprio data warehouse. L'attività Mirror data automatizza il processo di rendere accessibili le tabelle Iceberg dichiarandole come tabelle e viste esterne nel proprio data warehouse. Il data warehouse si riferisce alla tabella Iceberg come a una vista esterna perché non gestisce la tabella, ma si limita a leggerla. Le tabelle e le viste esterne consentono di interrogare i dati Iceberg nel proprio data warehouse senza migrare i dati o la gestione delle tabelle nel data warehouse.
L'attività di mirror esegue le istruzioni DDL necessarie per creare le tabelle e le viste esterne. La tabella (schema) viene visualizzata nel data warehouse, insieme alle tabelle delle modifiche e della cronologia, ma se si osserva la definizione della tabella, questa viene visualizzata come una vista creata sopra la tabella esterna. I consumatori di dati possono interrogare le viste come se i dati fossero memorizzati nel proprio ambiente di data warehouse. I dati con mirroring offrono prestazioni elevate, poiché Qlik continua a gestire e ottimizzare i dati.
Sono supportati i seguenti data warehouse:
-
Amazon Redshift
-
Databricks
-
Snowflake
Mirroring su più data warehouse
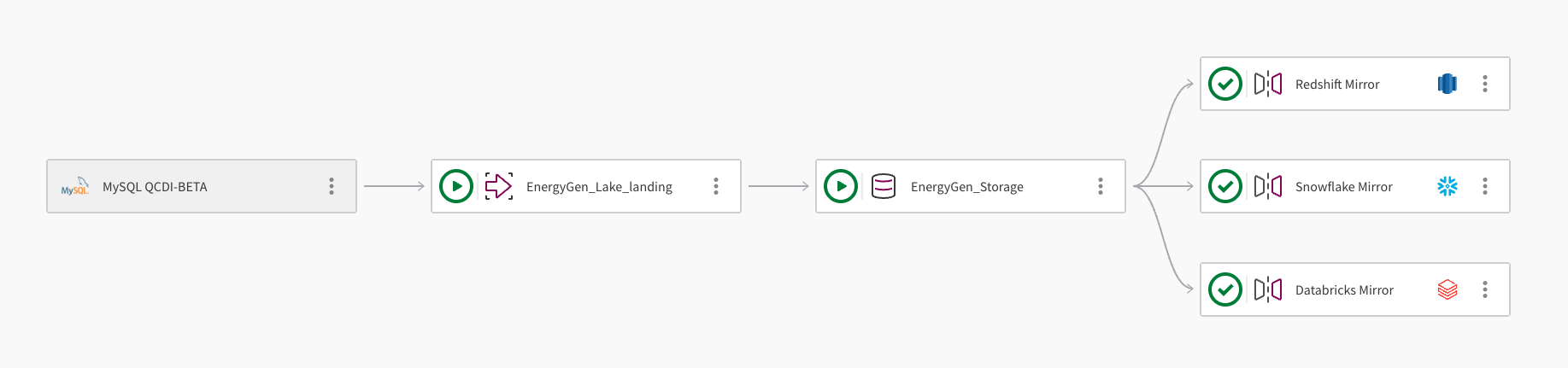
Un singolo dataset può essere sottoposto a mirroring su più data warehouse cloud. L'immagine seguente mostra come un progetto di pipeline Qlik Open Lakehouse possa essere utilizzato per eseguire il mirroring dei dati su Amazon Redshift, Snowflake e Databricks:
-
La pipeline acquisisce i dati da un database MySQL utilizzando la connessione MySQL QCDI-BETA.
-
L'attività di trasferimento Lake, EnergyGen_Lake_landing, acquisisce i dati grezzi in un bucket Amazon S3.
-
Successivamente, l'attività di archiviazione EnergyGen_Storage copia i dati in una posizione S3 per memorizzarli nel formato Apache Iceberg.
-
L'attività Mirror data, Redshift Mirror, crea le viste necessarie per consentire l'interrogazione dei dati da Amazon Redshift e aggiorna automaticamente i dati.
-
Viene aggiunta una seconda attività Mirror data, Snowflake Mirror, per creare le viste necessarie per consentire l'interrogazione dei dati da Snowflake. L'attività di mirror utilizza il meccanismo di aggiornamento gestito da Qlik, che consente trasformazioni a valle.
-
Viene aggiunta una terza attività Mirror data, Databricks Mirror, per consentire l'interrogazione dei dati da Databricks tramite un catalogo esterno in Databricks Unity Catalog.
Meccanismo di aggiornamento
Il meccanismo di aggiornamento disponibile dipende dal provider del data warehouse cloud, come dettagliato di seguito.
Amazon Redshift
I dati con mirroring su Amazon Redshift vengono aggiornati automaticamente e non è necessario pianificare o eseguire l'attività. Tutti i nomi di tabelle e viste vengono convertiti in lettere minuscole in Amazon Redshift, poiché Qlik Open Lakehouse non supporta nomi di oggetti sensibili alle maiuscole/minuscole (database, schema, tabella o colonna).
Snowflake
Snowflake punta ai metadati che riflettono l'ultimo snapshot dei dati disponibili all'interno di Iceberg. Esistono due modi per aggiornare i metadati:
-
gestito da Qlik: questa opzione richiede un warehouse Snowflake attivo e include il monitoraggio e l'anteprima dei dati. Selezionare questa opzione quando si desidera creare trasformazioni a valle, nonché monitorare e pianificare l'attività. Qlik è proprietaria dell'operazione di aggiornamento dei metadati, pertanto è possibile configurarla manualmente, ad esempio per l'esecuzione ogni 30 minuti. Questa opzione è particolarmente rilevante per le trasformazioni multi-tabella, poiché i metadati di tutte le tabelle si aggiornano simultaneamente. Sebbene si possa perdere parte del guadagno in tempo reale offerto dall'aggiornamento gestito da Snowflake, si mantiene la coerenza tra le tabelle. Per le trasformazioni multi-tabella, è possibile attivare l'aggiornamento con la frequenza necessaria. Qlik consiglia di impostare l'attivazione basata su eventi sulle attività di trasformazione a valle che seguono l'attività di mirror pianificata.
-
gestito da Snowflake: un'operazione serverless che sfrutta l'infrastruttura Snowpipe senza richiedere o attivare un warehouse di calcolo. Questa opzione è consigliata quando non si richiedono trasformazioni a valle. L'intervallo di aggiornamento viene configurato quando si crea l'integrazione del catalogo Snowflake. Per monitorare lo stato dell'aggiornamento automatico, interrogare SYSTEM$AUTO_REFRESH_STATUS in Snowflake. Qlik perde la proprietà del processo e non è in grado di monitorare le attività di questo tipo.
The parquet file 'tg_open_lakehouse/bronze/sales/tables/tg_sales_ingestion_bronze__internal.order_details__internal/data/hdr__scd_partition=asset_state/2025_09_12_00_37_asset_state_apply-4bcbb2eb-4ad3-4d88-bea6-ea611576624e.parquet' for table 'OPENLAKEHOUSE."snowflake_mirror__internal"."ext__order_details"' was inaccessible.
Databricks
Il catalogo esterno di Databricks legge i metadati Iceberg direttamente da AWS Glue. Dopo aver eseguito l'attività di mirror, l'ultimo snapshot dei dati è disponibile per l'interrogazione in Databricks senza ulteriori passaggi di aggiornamento.
Prerequisites
I seguenti requisiti si applicano a tutte le destinazioni di data warehouse supportate:
-
Un'attività Mirror data può essere aggiunta solo dopo che è stata creata un'attività di archiviazione in un progetto Qlik Open Lakehouse.
-
Un'attività di archiviazione può avere più attività Mirror data, ciascuna destinata a un data warehouse diverso.
-
Un'attività Mirror data può essere associata a una sola attività di archiviazione.
-
Per eseguire trasformazioni, creare un progetto di data warehouse e utilizzare l'attività Mirror data come origine. Il progetto e l'attività di mirror devono utilizzare la stessa piattaforma di data warehouse, ad esempio Redshift.
Per eseguire il mirroring dei dati, configurare le impostazioni per il data warehouse di destinazione.
Amazon Redshift
-
Una connessione al database del data warehouse in cui si desidera eseguire il mirroring dei dati. Facoltativamente, è possibile creare una nuova connessione durante la creazione dell'attività di mirror. Per ulteriori informazioni, vedere Amazon Redshift.
-
Un ruolo IAM assunto da Redshift con autorizzazioni di lettura per Glue Data Catalog. Il seguente script fornisce le autorizzazioni necessarie per accedere al catalogo. Assicurarsi di sostituire <ICEBERG_BUCKET_NAME> con il nome del proprio bucket:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "glue:GetDatabase", "glue:GetDatabases", "glue:GetTable", "glue:GetTables", "glue:GetPartition", "glue:GetPartitions" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "s3:GetObject", "s3:ListBucket" ], "Resource": [ "arn:aws:s3:::<ICEBERG_BUCKET_NAME>", "arn:aws:s3:::<ICEBERG_BUCKET_NAME>/*" ] } }Questo ruolo richiede la seguente relazione di attendibilità:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "redshift-serverless.amazonaws.com" }, "Action": "sts:AssumeRole" }, { "Effect": "Allow", "Principal": { "Service": "redshift.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }Nota informaticaPer ulteriori informazioni, vedere Criteri IAM per Amazon Redshift Spectrum. -
Uno schema esterno in Redshift che punta al database dell'attività di archiviazione. È necessario creare uno schema Redshift esterno eseguendo il comando CREATE EXTERNAL SCHEMA e puntando al database interno dell'attività di archiviazione Iceberg di origine. I consumatori esterni devono consumare dalle viste di consumo dello schema dell'attività di mirror. Per creare lo schema esterno, utilizzare la seguente sintassi, assicurandosi che la proprietà DATABASE sia il database creato dall'attività di archiviazione:
CREATE EXTERNAL SCHEMA <local_schema_name>
FROM DATA CATALOG
DATABASE '<database_name>'
IAM_ROLE 'arn:aws:iam::<AWS account-id>:role/<role-name>'
REGION '<aws-region>'
Snowflake
-
Una connessione al database del data warehouse in cui si desidera eseguire il mirroring dei dati. Facoltativamente, è possibile creare una nuova connessione durante la creazione dell'attività di mirror. Per ulteriori informazioni, vedere Snowflake.
-
Un volume esterno Snowflake. Questo garantisce a Snowflake un accesso limitato alla propria posizione S3. Per configurare il volume, vedere Configurare un volume esterno per Amazon S3.
-
Un'integrazione di AWS Glue Data Catalog. Ciò consente a Snowflake di connettersi ai dati conservati nel formato di tabella aperta Iceberg nel proprio archivio di oggetti. Per configurare un'integrazione del catalogo, vedere Configurare un'integrazione del catalogo per AWS Glue.
Databricks
-
Una connessione all'area di lavoro Databricks in cui si desidera eseguire il mirroring dei dati. Facoltativamente, è possibile creare una nuova connessione durante la creazione dell'attività di mirror. Per ulteriori informazioni, vedere Databricks.
-
I seguenti oggetti devono essere configurati in AWS e Databricks prima di creare l'attività di mirror:
-
Una connessione Glue in AWS. Ciò consente a Databricks di federare le query dei metadati tramite AWS Glue Data Catalog. Per ulteriori informazioni, vedere AWS Glue > Connessione ai dati.
-
Una credenziale di servizio collegata ad AWS in Databricks Unity Catalog. Questo concede a Databricks le autorizzazioni necessarie per accedere ai servizi AWS. Per ulteriori informazioni, vedere Databricks > Creare credenziali di servizio.
-
Una posizione esterna in Databricks Unity Catalog che punta al proprio bucket S3. Questo autorizza Databricks a leggere i dati Iceberg nel percorso S3 gestito dall'attività di archiviazione. Per ulteriori informazioni, vedere Databricks > Posizioni esterne.
-
Un catalogo esterno in Databricks Unity Catalog. Questo espone le tabelle Iceberg registrate in AWS Glue como tabelle interrogabili in Databricks. Per ulteriori informazioni, vedere Databricks > Cataloghi esterni.
-
Creazione di un'attività Mirror data
Per eseguire il mirroring dei dati nel proprio data warehouse, procedere come segue:
-
Aprire il progetto che contiene l'attività di archiviazione per i dati di cui si desidera eseguire il mirroring.
-
Fare clic su
 Altre azioni sull'attività di archiviazione. Selezionare Mirror data e configurarla:
Altre azioni sull'attività di archiviazione. Selezionare Mirror data e configurarla: -
Nome: inserire un nome per l'attività di mirror.
-
Descrizione: facoltativamente, descrivere lo scopo dell'attività.
-
Data warehouse: selezionare il data warehouse di destinazione.
-
Connessione:
-
Per utilizzare una connessione esistente, fare clic su Seleziona per aprire la finestra di dialogo Connessione sorgente sicura. Scegliere lo Spazio in cui si trova la connessione, quindi selezionare la connessione. Fare clic su Modifica per modificare le proprietà della connessione.
-
Per creare una nuova connessione, fare clic su Crea connessione per aprire la finestra di dialogo Crea connessione e seguire le istruzioni.
-
-
Database: inserire il nome del database in cui si desidera eseguire il mirroring dei dati.
-
Per eseguire il mirroring su Amazon Redshift:
-
Schema esterno: inserire il nome dello schema in cui verranno create le viste.
Nota informaticaTutti i nomi di tabelle e viste vengono convertiti in lettere minuscole in Amazon Redshift.
-
-
Per eseguire il mirroring su Snowflake:
-
Volume esterno Snowflake: inserire il nome del volume esterno creato in Snowflake.
-
Integrazione catalogo Snowflake: inserire il nome dell'integrazione del catalogo creata in Snowflake.
-
Selezionare la modalità di aggiornamento dei dati in Snowflake:
-
gestito da Qlik: selezionare questa opzione se si desidera creare trasformazioni a valle. Ciò richiede un warehouse Snowflake attivo ed è monitorato da Qlik.
-
gestito da Snowflake: selezionare questa opzione quando non si desidera eseguire trasformazioni a valle. Un warehouse Snowflake non è richiesto e pertanto non è monitorato da Qlik. Questo viene amministrato e monitorato in Snowflake.
-
-
-
Per eseguire il mirroring su Databricks:
-
Catalogo Databricks: inserire il nome del Databricks Unity Catalog. Di solito è hive_metastore.
-
Catalogo esterno Databricks: inserire il nome del catalogo esterno Databricks connesso ad AWS Glue.
-
-
Fare clic su OK per creare l'attività di mirror e aggiungerla all'attività di archiviazione nella propria pipeline.
-
Fare clic su
Altre azioni sull'attività di mirror e selezionare Apri. Assicurarsi di visualizzare la vista Progettazione. -
Per selezionare un sottoinsieme dei dataset disponibili, fare clic su Seleziona dati sorgente e rimuovere i dataset indesiderati.
-
Fare clic su Prepara per creare gli oggetti esterni ed eseguire il mirroring dei dati.
Esecuzione di trasformazioni
Se è necessario trasformare i dati, è possibile creare un progetto Redshift, Snowflake o Databricks e utilizzare un'attività Mirror data all'interno del proprio progetto Qlik Open Lakehouse come origine. L'origine dell'attività di mirror deve essere la stessa piattaforma di data warehouse cloud del progetto. Ad esempio, quando si crea un progetto Amazon Redshift per eseguire trasformazioni, è necessario utilizzare un'attività Mirror data di Amazon Redshift come origine.
Visualizzazione delle informazioni sull'attività
Fare clic su ![]() sulla barra dei menu per visualizzare le informazioni sull'attività, ad esempio:
sulla barra dei menu per visualizzare le informazioni sull'attività, ad esempio:
-
Proprietario
-
Spazio
-
Piattaforma dati
-
ID progetto
-
ID tempo di esecuzione attività dati
Eliminazione di un'attività Mirror data
Quando si elimina un'attività di mirror, gli schemi interni e le viste creati dall'attività di mirror vengono eliminati. Gli schemi esterni e la tabella in Redshift non vengono eliminati. Se una tabella viene eliminata da AWS Glue, ad esempio quando un utente elimina il dataset nell'archiviazione o elimina l'intera attività di archiviazione, la modifica si riflette automaticamente nello schema esterno di Redshift. La tabella viene rimossa e non deve essere eliminata separatamente. Come procedura consigliata, eliminare completamente lo schema esterno se non è più in uso.
Per eliminare un'attività Mirror data, procedere come segue:
-
Sull'attività Mirror data che si desidera eliminare, fare clic sul menu
 Altre azioni sull'attività e selezionare Elimina.
Altre azioni sull'attività e selezionare Elimina. -
Nella finestra di dialogo di conferma, fare clic su Elimina.