
클라우드 데이터 웨어하우스로 데이터 미러링
미러 태스크를 사용하면 클라우드 데이터 웨어하우스에서 Qlik 오픈 레이크하우스에 저장된 데이터를 쿼리할 수 있습니다. 데이터는 중복 없이 웨어하우스에 반영됩니다. 미러링된 테이블은 스토리지 및 엔지니어링 비용을 최소화하고 단일 진실 공급원(single source of truth)을 유지합니다.
데이터를 Qlik 오픈 레이크하우스에 온보딩한 후 미러 테이블을 사용하여 데이터를 클라우드 데이터 웨어하우스로 미러링할 수 있습니다. Iceberg의 데이터는 Amazon Athena와 같이 기본적으로 Iceberg를 지원하는 쿼리 엔진을 사용하여 쿼리할 수 있습니다. 그러나 미러 테이블은 개방형 Iceberg 레이크하우스 아키처를 구현하고 데이터 웨어하우스 쿼리 엔진을 계속 사용하려는 경우에 이상적입니다. 데이터 미러링 태스크는 Iceberg 테이블을 데이터 웨어하우스의 외부 테이블 및 뷰로 선언하여 액세스할 수 있도록 하는 프로세스를 자동화합니다. 데이터 웨어하우스는 테이블을 관리하지 않고 읽기만 하므로 Iceberg 테이블을 외부 뷰로 참조합니다. 외부 테이블 및 뷰를 사용하면 데이터를 마이그레이션하거나 테이블 관리를 데이터 웨어하우스로 이전하지 않고도 데이터 웨어하우스에서 Iceberg 데이터를 쿼리할 수 있습니다.
미러 태스크는 외부 테이블 및 뷰를 생성하는 데 필요한 DDL 문을 실행합니다. 테이블(스키마)은 변경 사항 및 이력 테이블과 함께 데이터 웨어하우스에 표시되지만, 테이블 정의를 보면 외부 테이블 위에 생성된 뷰로 표시됩니다. 데이터 소비자는 데이터가 자신의 데이터 웨어하우스 환경에 저장된 것처럼 뷰를 쿼리할 수 있습니다. Qlik에서 데이터를 계속 관리하고 최적화하므로 미러링된 데이터는 높은 성능을 제공합니다.
다음 데이터 웨어하우스가 지원됩니다.
-
Amazon Redshift
-
Databricks
-
Snowflake
여러 데이터 웨어하우스로 미러링
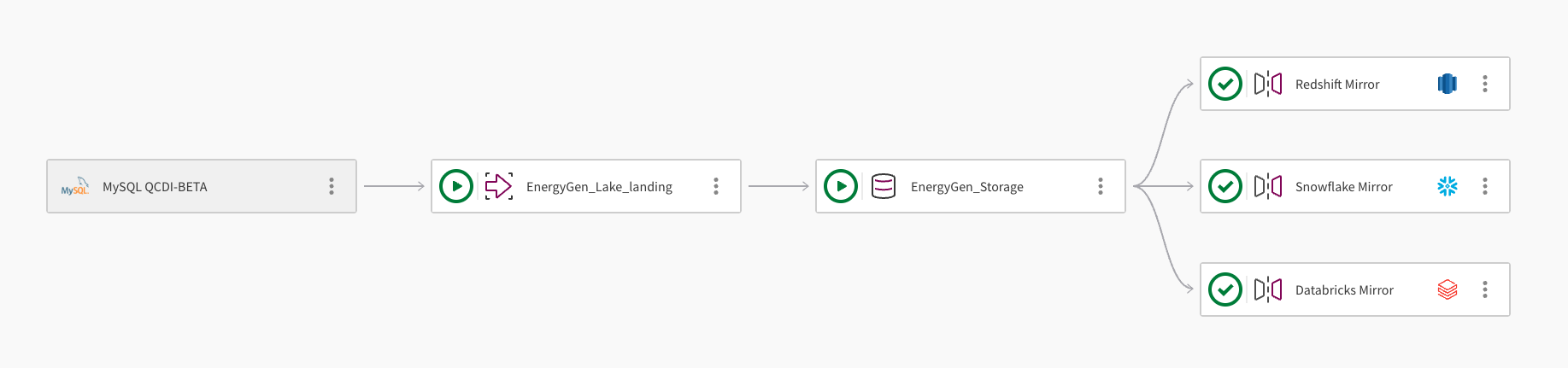
단일 데이터 세트를 여러 클라우드 데이터 웨어하우스로 미러링할 수 있습니다. 다음 이미지는 Qlik 오픈 레이크하우스 파이프라인 프로젝트를 사용하여 Amazon Redshift, Snowflake 및 Databricks로 데이터를 미러링하는 방법을 보여 줍니다:
-
파이프라인은 연결 MySQL QCDI-BETA를 사용하여 MySQL 데이터베이스에서 데이터를 수집합니다.
-
레이크 랜딩 태스크인 EnergyGen_Lake_landing은 원시 데이터를 Amazon S3 버킷으로 수집합니다.
-
다음으로 스토리지 태스크인 EnergyGen_Storage는 데이터를 S3 위치로 복사하여 Apache Iceberg 형식으로 저장합니다.
-
데이터 미러링 태스크인 Redshift Mirror는 Amazon Redshift에서 데이터를 쿼리할 수 있도록 필요한 뷰를 생성하고 데이터를 자동으로 새로 고칩니다.
-
두 번째 데이터 미러링 태스크인 Snowflake Mirror가 추가되어 Snowflake에서 데이터를 쿼리할 수 있도록 필요한 뷰를 생성합니다. 미러 태스크는 다운스트림 변환을 허용하는 Qlik-managed 새로 고침 메커니즘을 사용합니다.
-
세 번째 데이터 미러링 태스크인 Databricks Mirror가 추가되어 Databricks Unity Catalog의 외부 카탈로그를 통해 Databricks에서 데이터를 쿼리할 수 있도록 합니다.
새로 고침 메커니즘
사용 가능한 새로 고침 메커니즘은 아래에 자세히 설명된 대로 클라우드 데이터 웨어하우스 공급자에 따라 다릅니다.
Amazon Redshift
Amazon Redshift로 미러링된 데이터는 자동으로 새로 고쳐지므로 태스크를 예약하거나 실행할 필요가 없습니다. Qlik 오픈 레이크하우스는 대소문자를 구분하는 개체 이름(데이터베이스, 스키마, 테이블 또는 열)을 지원하지 않으므로 Amazon Redshift에서 모든 테이블 및 뷰 이름은 소문자로 변환됩니다.
Snowflake
Snowflake는 Iceberg 내에서 사용 가능한 데이터의 최신 스냅샷을 반영하는 메타데이터를 가리킵니다. 메타데이터를 새로 고치는 방법에는 두 가지가 있습니다:
-
Qlik-managed: 이 옵션은 활성 Snowflake 웨어하우스가 필요하며 모니터링 및 데이터 미리 보기를 포함합니다. 다운스트림 변환을 생성하고 태스크를 모니터링 및 예약하려는 경우 이 옵션을 선택합니다. Qlik가 메타데이터 새로 고침 작업을 소유하므로 이를 수동으로 구성하여(예: 30분마다 실행) 설정할 수 있습니다. 이 옵션은 모든 테이블의 메타데이터가 동시에 업데이트되므로 다중 테이블 변환에 특히 유용합니다. Snowflake-managed 새로 고침이 제공하는 실시간 이점 중 일부를 잃을 수 있지만 테이블 간의 일관성은 유지됩니다. 다중 테이블 변환의 경우 필요한 만큼 자주 새로 고침을 트리거할 수 있습니다. Qlik는 예약된 미러 태스크를 따르는 다운스트림 변환 태스크에 이벤트 기반 트리거를 설정할 것을 권장합니다.
-
Snowflake-managed: 컴퓨팅 웨어하우스를 요구하거나 활성화하지 않고 Snowpipe 인프라를 활용하는 서버리스 작업입니다. 이 옵션은 다운스트림 변환이 필요하지 않은 경우 권장됩니다. 새로 고침 간격은 Snowflake 카탈로그 통합을 생성할 때 구성됩니다. 자동 새로 고침 상태를 모니터링하려면 Snowflake에서 SYSTEM$AUTO_REFRESH_STATUS를 쿼리합니다. Qlik는 프로세스 소유권을 잃게 되며 이 유형의 태스크를 모니터링할 수 없습니다.
The parquet file 'tg_open_lakehouse/bronze/sales/tables/tg_sales_ingestion_bronze__internal.order_details__internal/data/hdr__scd_partition=asset_state/2025_09_12_00_37_asset_state_apply-4bcbb2eb-4ad3-4d88-bea6-ea611576624e.parquet' for table 'OPENLAKEHOUSE."snowflake_mirror__internal"."ext__order_details"' was inaccessible.
Databricks
Databricks 외부 카탈로그는 AWS Glue에서 직접 Iceberg 메타데이터를 읽습니다. 미러 태스크를 실행한 후 추가 새로 고침 단계 없이 Databricks에서 최신 데이터 스냅샷을 쿼리할 수 있습니다.
전제 조건
지원되는 모든 데이터 웨어하우스 대상에 다음 요구 사항이 적용됩니다:
-
데이터 미러링 태스크는 Qlik 오픈 레이크하우스 프로젝트에 스토리지 태스크가 생성된 후에만 추가할 수 있습니다.
-
스토리지 태스크는 각각 다른 데이터 웨어하우스를 대상으로 하는 여러 데이터 미러링 태스크를 가질 수 있습니다.
-
데이터 미러링 태스크는 하나의 스토리지 태스크에만 연결할 수 있습니다.
-
변환을 수행하려면 데이터 웨어하우스 프로젝트를 생성하고 데이터 미러링 태스크를 소스로 사용합니다. 프로젝트와 미러 태스크는 동일한 데이터 웨어하우스 플랫폼(예: Redshift)을 사용해야 합니다.
데이터를 미러링하려면 대상 데이터 웨어하우스에 대한 설정을 구성합니다.
Amazon Redshift
-
데이터를 미러링할 데이터 웨어하우스 데이터베이스에 대한 연결입니다. 선택적으로 미러 태스크 생성 중에 새 연결을 생성할 수 있습니다. 자세한 내용은 Amazon Redshift를 참조하십시오.
-
Glue Data Catalog 읽기 권한이 있는 Redshift가 수임하는 IAM 역할입니다. 다음 스크립트는 카탈로그에 액세스하는 데 필요한 권한을 제공합니다. <ICEBERG_BUCKET_NAME>을 버킷 이름으로 바꾸십시오:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "glue:GetDatabase", "glue:GetDatabases", "glue:GetTable", "glue:GetTables", "glue:GetPartition", "glue:GetPartitions" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "s3:GetObject", "s3:ListBucket" ], "Resource": [ "arn:aws:s3:::<ICEBERG_BUCKET_NAME>", "arn:aws:s3:::<ICEBERG_BUCKET_NAME>/*" ] } }이 역할에는 다음과 같은 신뢰 관계가 필요합니다:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "redshift-serverless.amazonaws.com" }, "Action": "sts:AssumeRole" }, { "Effect": "Allow", "Principal": { "Service": "redshift.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }정보 메모자세한 내용은 IAM policies for Amazon Redshift Spectrum을 참조하십시오. -
스토리지 태스크 데이터베이스를 가리키는 Redshift의 외부 스키마입니다. CREATE EXTERNAL SCHEMA 명령을 실행하고 소스 Iceberg 스토리지 태스크 내부 데이터베이스를 가리켜 외부 Redshift 스키마를 생성해야 합니다. 외부 소비자는 미러 태스크 스키마 소비 뷰에서 소비해야 합니다. 외부 스키마를 생성하려면 다음 구문을 사용하고, DATABASE 속성이 스토리지 태스크에 의해 생성된 데이터베이스인지 확인하십시오:
CREATE EXTERNAL SCHEMA <local_schema_name>
FROM DATA CATALOG
DATABASE '<database_name>'
IAM_ROLE 'arn:aws:iam::<AWS account-id>:role/<role-name>'
REGION '<aws-region>'
Snowflake
-
데이터를 미러링할 데이터 웨어하우스 데이터베이스에 대한 연결입니다. 선택적으로 미러 태스크 생성 중에 새 연결을 생성할 수 있습니다. 자세한 내용은 Snowflake를 참조하십시오.
-
Snowflake 외부 볼륨입니다. 이를 통해 Snowflake에 S3 위치에 대한 제한된 액세스 권한을 부여합니다. 볼륨을 구성하려면 Configure an external volume for Amazon S3를 참조하십시오.
-
AWS Glue Data Catalog 통합입니다. 이를 통해 Snowflake는 오브젝트 스토어의 Iceberg 개방형 테이블 형식으로 보관된 데이터에 연결할 수 있습니다. 카탈로그 통합을 구성하려면 Configure a catalog integration for AWS Glue를 참조하십시오.
Databricks
-
데이터를 미러링할 Databricks 작업 공간에 대한 연결입니다. 선택적으로 미러 태스크 생성 중에 새 연결을 생성할 수 있습니다. 자세한 내용은 Databricks를 참조하십시오.
-
미러 태스크를 생성하기 전에 AWS 및 Databricks에서 다음 개체를 구성해야 합니다:
-
AWS의 Glue 연결입니다. 이를 통해 Databricks는 AWS Glue Data Catalog를 통해 메타데이터 쿼리를 연합할 수 있습니다. 자세한 내용은 AWS Glue > Connecting to data를 참조하십시오.
-
Databricks Unity Catalog의 AWS 연결 서비스 자격 증명입니다. 이를 통해 Databricks에 AWS 서비스에 액세스하는 데 필요한 권한을 부여합니다. 자세한 내용은 Databricks > Create service credentials를 참조하십시오.
-
S3 버킷을 가리키는 Databricks Unity Catalog의 외부 위치입니다. 이를 통해 Databricks가 스토리지 태스크에서 관리하는 S3 경로의 Iceberg 데이터를 읽을 수 있도록 승인합니다. 자세한 내용은 Databricks > External locations를 참조하십시오.
-
Databricks Unity Catalog의 외부 카탈로그입니다. 이를 통해 AWS Glue에 등록된 Iceberg 테이블을 Databricks에서 쿼리 가능한 테이블로 노출합니다. 자세한 내용은 Databricks > Foreign catalogs를 참조하십시오.
-
데이터 미러링 태스크 생성
데이터 웨어하우스로 데이터를 미러링하려면 다음을 수행합니다:
-
미러링할 데이터의 스토리지 태스크가 포함된 프로젝트를 엽니다.
-
스토리지 태스크에서
 추가 작업을 클릭합니다. Select 데이터 미러링을 선택하고 구성합니다:
추가 작업을 클릭합니다. Select 데이터 미러링을 선택하고 구성합니다: -
이름: 미러 태스크의 이름을 입력합니다.
-
설명: 선택적으로 태스크의 목적을 설명합니다.
-
데이터 웨어하우스: 대상 데이터 웨어하우스를 선택합니다.
-
연결:
-
기존 연결을 사용하려면 선택을 클릭하여 보안 소스 연결 대화 상자를 엽니다. 연결이 있는 공간을 선택한 다음 연결을 선택합니다. 연결 속성을 수정하려면 편집을 클릭합니다.
-
새 연결을 생성하려면 연결 생성을 클릭하여 연결 생성 대화 상자를 열고 지침을 따릅니다.
-
-
데이터베이스: 데이터를 미러링할 데이터베이스의 이름을 입력합니다.
-
Amazon Redshift로 미러링하려면 다음을 수행합니다:
-
외부 스키마: 뷰가 생성될 스키마의 이름을 입력합니다.
정보 메모Amazon Redshift에서 모든 테이블 및 뷰 이름은 소문자로 변환됩니다.
-
-
Snowflake로 미러링하려면 다음을 수행합니다:
-
Snowflake 외부 볼륨: Snowflake에서 생성된 외부 볼륨의 이름을 입력합니다.
-
Snowflake 카탈로그 통합: Snowflake에서 생성된 카탈로그 통합의 이름을 입력합니다.
-
Snowflake에서 데이터를 새로 고칠 방법을 선택합니다:
-
Qlik-managed: 다운스트림 변환을 생성하려는 경우 이 옵션을 선택합니다. 이 옵션은 활성 Snowflake 웨어하우스가 필요하며 Qlik에 의해 모니터링됩니다.
-
Snowflake-managed: 다운스트림 변환을 수행하지 않으려는 경우 이 옵션을 선택합니다. Snowflake 웨어하우스가 필요하지 않으므로 Qlik에 의해 모니터링되지 않습니다. 이는 Snowflake에서 관리 및 모니터링됩니다.
-
-
-
Databricks로 미러링하려면 다음을 수행합니다:
-
Databricks 카탈로그: Databricks Unity Catalog의 이름을 입력합니다. 일반적으로 hive_metastore입니다.
-
Databricks 외부 카탈로그: AWS Glue에 연결된 Databricks 외부 카탈로그의 이름을 입력합니다.
-
-
확인 을 클릭하여 미러 태스크를 생성하고 파이프라인의 스토리지 태스크에 추가합니다.
-
미러 태스크에서
추가 작업을 클릭하고 열기를 선택합니다. 디자인 뷰가 표시되는지 확인합니다. -
사용 가능한 데이터 세트의 하위 세트를 선택하려면 소스 데이터 선택을 클릭하고 원하지 않는 데이터 세트를 제거합니다.
-
외부 개체를 생성하고 데이터를 미러링하려면 준비를 클릭합니다.
변환 수행
데이터를 변환해야 하는 경우 Redshift, Snowflake 또는 Databricks 프로젝트를 생성하고 Qlik 오픈 레이크하우스 프로젝트 내의 데이터 미러링 태스크를 소스로 사용할 수 있습니다. 미러 태스크 소스는 프로젝트와 동일한 클라우드 데이터 웨어하우스 플랫폼이어야 합니다. 예를 들어 변환을 수행하기 위해 Amazon Redshift 프로젝트를 생성할 때 Amazon Redshift 데이터 미러링 태스크를 소스로 사용해야 합니다.
작업 정보 보기
메뉴 막대에서 ![]() 를 클릭하여 작업 정보를 볼 수 있습니다(예:).
를 클릭하여 작업 정보를 볼 수 있습니다(예:).
-
소유자
-
공간
-
데이터 플랫폼
-
프로젝트 ID
-
데이터 작업 런타임 ID
데이터 미러링 태스크 삭제
미러 태스크를 삭제하면 미러 태스크에 의해 생성된 내부 스키마 및 뷰가 삭제(drop)됩니다. Redshift의 외부 스키마 및 테이블은 삭제되지 않습니다. 예를 들어 사용자가 스토리지에서 데이터 세트를 삭제하거나 전체 스토리지 태스크를 삭제하여 AWS Glue에서 테이블이 삭제되면 변경 사항이 Redshift 외부 스키마에 자동으로 반영됩니다. 테이블이 제거되므로 별도로 삭제할 필요가 없습니다. 모범 사례로, 외부 스키마를 더 이상 사용하지 않는 경우 완전히 삭제하십시오.
데이터 미러링 태스크를 삭제하려면 다음을 수행합니다:
-
삭제하려는 데이터 미러링 태스크에서 태스크의
 추가 작업 메뉴를 클릭하고 삭제를 선택합니다.
추가 작업 메뉴를 클릭하고 삭제를 선택합니다. -
확인 대화 상자에서 삭제를 클릭합니다.