
クラウド データ ウェアハウスへのデータのミラーリング
ミラーリング タスクを使用すると、クラウド データ ウェアハウスから Qlik Open Lakehouse に保存されているデータを照会できます。データは複製されることなくクラウド データ ウェアハウスに反映されます。ミラーリングされたテーブルは、ストレージとエンジニアリングのコストを最小限に抑え、唯一の信頼できる情報源を維持します。
Qlik Open Lakehouse にデータをオンボードした後、ミラー テーブルを使用してデータをクラウド データ ウェアハウスにミラーリングすることができます。Iceberg のデータは、Amazon Athena のような Iceberg をネイティブにサポートするクエリ エンジンを使って照会できます。しかし、ミラー テーブルは、オープンな Iceberg レイクハウス アーキテクチャを実装したいと思っており、クエリ エンジンとしてクラウド データ ウェアハウスを使用し続けたい場合に最適です。ミラー データ タスクは、Iceberg テーブルをデータ ウェアハウスの外部テーブルおよびビューとして宣言する中、アクセス可能にするプロセスを自動化します。データ ウェアハウスは Iceberg テーブルを外部ビューとして参照しています。これは Iceberg テーブルを管理せず、読み込みのみを行うためです。外部テーブルとビューを使用すると、データやテーブルの管理をデータ ウェアハウスに移行することなく、Iceberg データをデータ ウェアハウスで照会できます。
ミラー タスクは、外部テーブルとビューを作成するために必要な DDL ステートメントを実行します。テーブル (スキーマ) はデータ ウェアハウスでは変更履歴テーブルと一緒に表示されますが、テーブル定義を見ると、外部テーブルの上に作成されたビューとして表示されます。データ コンシューマーは、データがデータ ウェアハウス環境に保存されているかのようにビューにクエリを実行できます。ミラーリングされたデータは、Qlik によるデータの管理と最適化が継続されるため、高いパフォーマンスを発揮します。
次のデータウェアハウスがサポートされています。
-
Amazon Redshift
-
Databricks
-
Snowflake
複数のデータウェアハウスにミラーリング
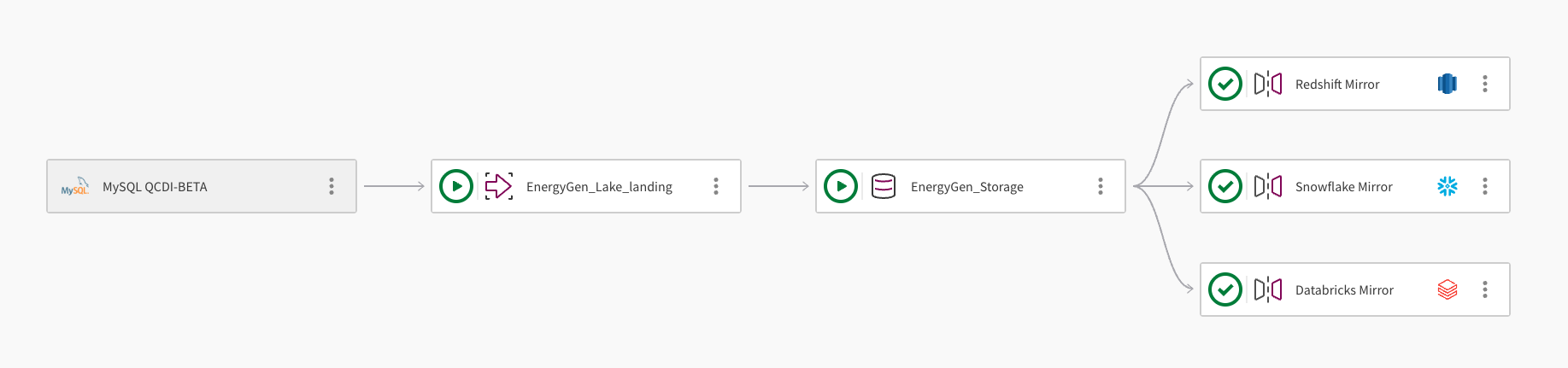
単一のデータセットを複数のクラウド データ ウェアハウスにミラーリングできます。以下の画像は、Qlik Open Lakehouse パイプライン プロジェクトを Amazon Redshift、Snowflake、Databricks にデータをミラーリングするためにどのように使用できるかを示しています。
-
パイプラインは、接続 MySQL QCDI-BETA を使用して MySQL データベースからデータを取り込みます。
-
Lake ランディング タスク、EnergyGen_Lake_landing は、生データを Amazon S3 バケットに取り込みます。
-
次に、ストレージ タスクである EnergyGen_Storage は、データをS3の場所にコピーして、Apache Iceberg 形式でデータを保存します。
-
ミラー データ タスクである Redshift Mirror は、Amazon Redshift からデータをクエリできるように必要なビューを作成し、データを自動的に更新します。
-
2 番目のミラー データ タスクである Snowflake Mirror が追加され、Snowflake からデータをクエリできるようにするために必要なビューが作成されます。ミラー タスクは、ダウンストリームの変換を可能にする Qlik 管理の更新メカニズムを使用します。
-
Databricks Unity Catalog 内の外部カタログを介して Databricks からデータをクエリできるように、3 つ目の Mirror データタスクであるDatabricks Mirror が追加されました。
リフレッシュ メカニズム
利用可能な更新メカニズムは、クラウド データ ウェアハウス プロバイダーによって異なります。詳細は以下のとおりです。
Amazon Redshift
Amazon Redshift にミラーリングされたデータは自動的に更新され、タスクをスケジュールしたり実行したりする必要はありません。Amazon Redshift では、すべてのテーブル名とビュー名が小文字に変換されます。Qlik Open Lakehouse は、大文字と小文字を区別するオブジェクト名 (データベース、スキーマ、テーブル、または列) をサポートしていないためです。
Snowflake
Snowflake は、Iceberg 内の利用可能なデータの最新のスナップショットを反映したメタデータをポイントします。メタデータを更新するには 2 つの方法があります。
-
Qlik 管理: このオプションにはアクティブな Snowflake ウェアハウスが必要で、モニタリングとデータ プレビューが含まれます。このオプションは、ダウンストリーム変換を作成し、タスクを監視してスケジュールする場合に選択します。Qlik はメタデータのリフレッシュ処理を所有しているため、たとえば30分ごとに実行するように手動で設定できます。このオプションは、すべてのテーブルのメタデータが同時に更新されるため、複数テーブルの変換に特に関係します。Snowflake 管理リフレッシュが提供するリアルタイムの利点を失うかもしれませんが、テーブル間の一貫性は維持されます。複数テーブルの変換では、必要に応じて何度でもリフレッシュをトリガーできます。Qlik はスケジュールされたミラー タスクに従うダウンストリーム変換タスクにイベントベースのトリガーを設定することをお勧めします。
-
Snowflake 管理: コンピュート ウェアハウスを必要とせず、アクティブにすることなく、Snowpipe インフラストラクチャを活用するサーバーレス オペレーション。このオプションは、ダウンストリーム変換を必要としない場合にお勧めします。リフレッシュ間隔は、Snowflake カタログ統合を作成するときに設定します。自動リフレッシュのステータスを監視するには、Snowflake の SYSTEM$AUTO_REFRESH_STATUS を照会します。Qlik はプロセスの所有権を失い、この種のタスクを監視できなくなります。
The parquet file 'tg_open_lakehouse/bronze/sales/tables/tg_sales_ingestion_bronze__internal.order_details__internal/data/hdr__scd_partition=asset_state/2025_09_12_00_37_asset_state_apply-4bcbb2eb-4ad3-4d88-bea6-ea611576624e.parquet' for table 'OPENLAKEHOUSE."snowflake_mirror__internal"."ext__order_details"' was inaccessible.
Databricks
Databricks の外部カタログは、AWS Glue から Iceberg メタデータを直接読み取ります。ミラータスクを実行すると、追加の更新手順なしに最新のデータスナップショットを Databricks でクエリできます。
前提条件
サポートされているすべてのデータ ウェアハウス ターゲットには、次の要件が適用されます。
-
ミラー データ タスクは、Qlik Open Lakehouse プロジェクトでストレージ タスクが作成された後にのみ追加できます。
-
ストレージ タスクには複数のミラー データ タスクを含めることができ、それぞれが異なるデータ ウェアハウスをターゲットとします。
-
ミラー データ タスクは 1 つのストレージ タスクにのみ関連付けることができます。
-
変換を実行するには、データ ウェアハウス プロジェクトを作成し、ミラー データ タスクをソースとして使用します。プロジェクトとミラー タスクでは、同じデータ ウェアハウス プラットフォーム (Redshift など) を使用する必要があります。
データをミラーリングするには、ターゲット データ ウェアハウスの設定を構成します。
Amazon Redshift
-
データをミラーリングするデータ ウェアハウス データベースへの接続。オプションで、ミラー タスクの作成中に新しい接続を作成することもできます。詳細については、「Amazon Redshift」を参照してください。
-
Glue データカタログの読み取り権限を持つ Redshift によって引き受けられた IAM ロール。次のスクリプトは、カタログにアクセスするために必要な権限を提供します。<ICEBERG_BUCKET_NAME> をご自身のバケット名に置き換えてください:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "glue:GetDatabase", "glue:GetDatabases", "glue:GetTable", "glue:GetTables", "glue:GetPartition", "glue:GetPartitions" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "s3:GetObject", "s3:ListBucket" ], "Resource": [ "arn:aws:s3:::<ICEBERG_BUCKET_NAME>", "arn:aws:s3:::<ICEBERG_BUCKET_NAME>/*" ] } }このロールには以下の信頼関係が必要です:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "redshift-serverless.amazonaws.com" }, "Action": "sts:AssumeRole" }, { "Effect": "Allow", "Principal": { "Service": "redshift.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }情報メモ詳細については、「Amazon Redshift Spectrum の IAM ポリシー」を参照してください。 -
ストレージ タスク データベースを指す Redshift の外部スキーマ。 CREATE EXTERNAL SCHEMA コマンドを実行し、ソースの Iceberg ストレージ タスクの内部データベースを指定して、外部 Redshift スキーマを作成する必要があります。外部コンシューマーは、ミラー タスク スキーマ消費ビューから消費する必要があります。外部スキーマを作成するには、次の構文を使用し、DATABASEプロパティがストレージ タスクによって作成されたデータベースであることを確認します。
CREATE EXTERNAL SCHEMA <local_schema_name>
FROM DATA CATALOG
DATABASE '<database_name>'
IAM_ROLE 'arn:aws:iam::<AWS account-id>:role/<role-name>'
REGION '<aws-region>'
Snowflake
-
データをミラーリングするデータ ウェアハウス データベースへの接続。オプションで、ミラー タスクの作成中に新しい接続を作成することもできます。詳細については、「Snowflake」を参照してください。
-
Snowflake 外部ボリューム。これにより、Snowflake は S3 のロケーションへのアクセスを制限されます。ボリュームを設定するには、「Amazon S3 用の外部ボリュームの設定」を参照してください。
-
AWS Glue データ カタログとの統合。これにより、Snowflake はオブジェクト ストア内の Iceberg オープン テーブル形式で保持されているデータに接続できるようになります。カタログ統合を構成するには、「AWS Glue のカタログ統合を構成する」を参照してください。
Databricks
-
データをミラーリングする Databricks ワークスペースへの接続です。オプションで、ミラー タスクの作成中に新しい接続を作成することもできます。詳細については、「Databricks」を参照してください。
-
ミラータスクを作成する前に、AWS と Databricks で次のオブジェクトを構成する必要があります。
-
AWS の Glue 接続。これにより、Databricks は AWS Glue Data Catalog を介してメタデータ クエリをフェデレートできます。詳細については、AWS Glue > データへの接続を参照してください。
-
Databricks Unity Catalog の AWS リンク サービス認証情報。これにより、Databricks が AWS サービスへアクセスするために必要な権限が付与されます。詳細については、Databricks > サービス認証情報の作成を参照してください。
-
S3 バケットを指す Databricks Unity Catalog における外部ロケーション。これにより、ストレージ タスクによって管理される S3 パス上の Iceberg データを Databricks が読み取れるようになります。詳細については、Databricks > 外部ロケーションを参照してください。
-
Databricks Unity Catalog 内の外部カタログ。これにより、AWS Glue に登録されている Iceberg テーブルが Databricks でクエリ可能なテーブルとして公開されます。詳細については、Databricks > 外部カタログを参照してください。
-
ミラー データ タスクの作成
データをデータ ウェアハウスにミラーリングするには、以下を行います。
-
ミラーリングしたいデータのストレージ タスクを含むプロジェクションを開きます。
-
ストレージ タスクの [
 その他のアクション] をクリックします。[ミラー データ] を選択し、設定します。
その他のアクション] をクリックします。[ミラー データ] を選択し、設定します。 -
名前: ミラー タスクの名前を入力します。
-
説明: オプションで、タスクの目的を記述します。
-
データ ウェアハウス: ターゲット データ ウェアハウスを選択します。
-
接続:
-
既存の接続を使用するには、[選択] をクリックして、[安全なソース接続] ダイアログを開きます。接続場所の [スペース] を選択し、接続を選択します。接続プロパティを変更するには、 [編集] をクリックします。
-
新しい接続を作成するには、 [接続の作成] をクリックして [接続の作成] ダイアログを開き、指示に従ってください。
-
-
データベース: データをミラーリングするデータベース名を入力します。
-
Amazon Redshift にミラーリングするには:
-
外部スキーマ: ビューが作成されるスキーマの名前を入力します。
情報メモAmazon Redshift では、すべてのテーブル名とビュー名は小文字に変換されます。
-
-
Snowflake にミラーリングするには:
-
Snowflake 外部ボリューム: Snowflake で作成した外部ボリュームの名前を入力します。
-
Snowflake カタログ統合: Snowflake で作成したカタログ統合の名前を入力します。
-
Snowflake でデータをリフレッシュする方法を選択します。
-
Qlik 管理: ダウンストリーム変換を作成する場合は、このオプションを選択します。これにはアクティブな Snowflake ウェアハウスが必要で、Qlik によって監視されます。
-
Snowflake 管理: ダウンストリームの変換を行わない場合は、このオプションを選択します。Snowflake ウェアハウスは必要ないため、Qlik によって監視されません。これは Snowflake で管理・監視されています。
-
-
-
Databricks にミラーリングするには:
-
Databricks カタログ: Databricks Unity Catalog の名前を入力します。通常は hive_metastore です。
-
Databricks 外部カタログ: AWS Glue に接続されている Databricks 外部カタログの名前を入力します。
-
-
[OK] をクリックしてミラー タスクを作成し、パイプラインのストレージ タスクに追加します。
-
ミラー タスクの [
その他のアクション] をクリックし、[開く] を選択します。[デザイン] ビューが表示されていることを確認します。 -
利用可能なデータセットのサブセットを選択するには、[ソース データの選択] をクリックし、不要なデータセットを削除します。
-
[準備] をクリックして、外部オブジェクトを作成し、データのミラーリングを行います。
変換の実行
データの変換が必要な場合は、Redshift、Snowflake、または Databricks プロジェクトを作成し、Qlik Open Lakehouse プロジェクト内のミラー データ タスクをソースとして使用できます。ミラー タスク ソースは、プロジェクトと同じクラウド データ ウェアハウス プラットフォームである必要があります。たとえば、変換を実行するために Amazon Redshift プロジェクトを作成する場合は、ソースとして Amazon Redshift ミラー データ タスクを使用する必要があります。
タスク情報の表示
メニュー バーで ![]() をクリックして、次のようなタスク情報を表示します。
をクリックして、次のようなタスク情報を表示します。
-
所有者
-
スペース
-
データ プラットフォーム
-
プロジェクトID
-
データ タスク実行 ID
ミラー データ タスクの削除
ミラー タスクを削除すると、ミラー タスクによって作成された内部スキーマとビューが削除されます。Redshift 内の外部スキーマとテーブルは削除されません。たとえば、ユーザーがストレージ内のデータセットを削除したり、ストレージタスク全体を削除したりして AWS Glue からテーブルが削除されると、その変更は Redshift 外部スキーマに自動的に反映されます。テーブルは削除され、個別に削除する必要はありません。ベストプラクティスとして、使用されなくなった外部スキーマは完全に削除してください。
ミラー データ タスクを削除するには、以下を行います。
-
削除したいミラー データ タスクで、タスクの [
 その他のアクション] メニューをクリックし、[削除] を選択します。
その他のアクション] メニューをクリックし、[削除] を選択します。 -
確認ダイアログで、[削除] をクリックします。