
Mise en miroir des données dans un entrepôt de données cloud
Les tâches de mise en miroir vous permettent d'interroger des données stockées dans votre Qlik Open Lakehouse à partir de vos entrepôts de données cloud. Les données sont reflétées (mises en miroir) dans votre entrepôt sans être dupliquées. Les tables mises en miroir permettent de minimiser les coûts de stockage et d'ingénierie et de conserver une seule source de vérité.
Après avoir intégré vos données à un Qlik Open Lakehouse, vous pouvez les mettre en miroir dans votre entrepôt de données cloud à l'aide de tables en miroir. Les données figurant dans Iceberg peuvent être interrogées à l'aide d'un moteur de requête qui supporte nativement Iceberg, comme Amazon Athena. Cependant, les tables en miroir sont idéales lorsque vous souhaitez mettre en œuvre l'architecture de lakehouse Iceberg ouverte et continuer à utiliser votre entrepôt de données comme moteur de requête. La tâche Refléter les données automatise le processus consistant à rendre les tables Iceberg accessibles en les déclarant comme des tables et des vues externes dans votre entrepôt de données. L'entrepôt de données traite la table Iceberg comme une vue externe, car il ne gère pas la table, il se contente de la lire. Les tables et les vues externes vous permettent d'interroger vos données Iceberg dans votre entrepôt de données sans avoir à migrer les données ni à gérer vos tables dans votre entrepôt de données.
La tâche de mise en miroir exécute les instructions DDL nécessaires pour créer les tables et les vues externes. La table (le schéma) est affichée dans l'entrepôt de données, avec les tables de modifications et d'historique, mais, si vous regardez la définition de la table, elle s'affiche comme une vue créée en plus de la table externe. Les consommateurs de données peuvent interroger les vues comme si les données étaient stockées dans l'environnement de leur entrepôt de données. Les données en miroir offrent des performances élevées, car Qlik continue de gérer et d'optimiser les données.
Les entrepôts de données suivants sont supportés :
-
Amazon Redshift
-
Databricks
-
Snowflake
Mise en miroir dans plusieurs entrepôts de données
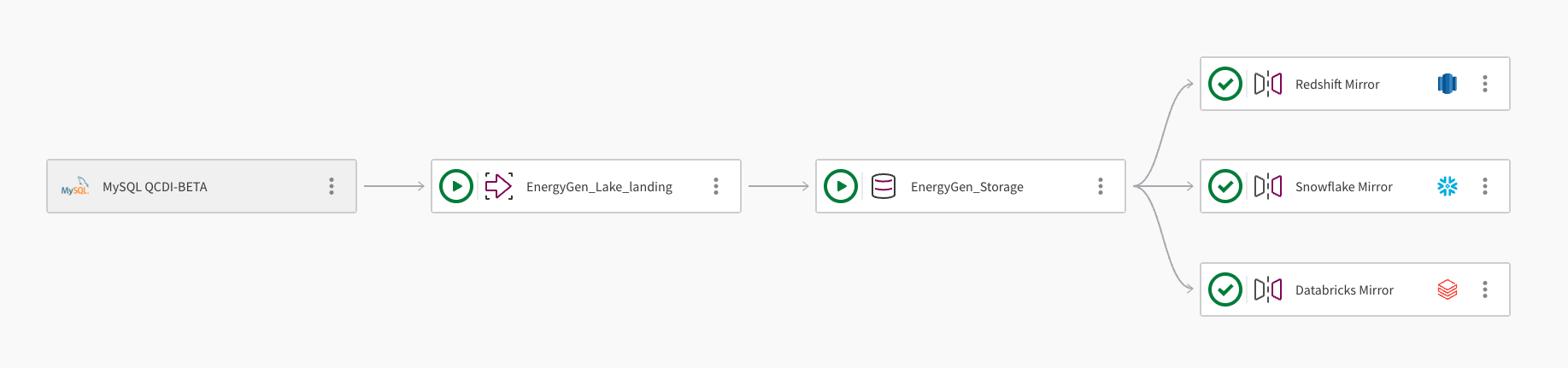
Un seul jeu de données peut être mis en miroir dans plusieurs entrepôts de données cloud. L'image suivante montre comment un projet de pipeline Qlik Open Lakehouse peut être utilisé pour mettre des données en miroir dans Amazon Redshift, Snowflake et Databricks :
-
Le pipeline ingère des données d'une base de données MySQL à l'aide de la connexion, MySQL QCDI-BETA.
-
La tâche de dépôt temporaire dans un lac, EnergyGen_Lake_landing, ingère les données brutes dans un compartiment Amazon S3.
-
Ensuite, la tâche de stockage, EnergyGen_Storage, copie les données à un emplacement S3 pour stocker les données au format Apache Iceberg.
-
La tâche Refléter les données, Redshift Mirror, crée les vues nécessaires pour permettre l'interrogation des données depuis Amazon Redshift et actualise automatiquement les données.
-
Une deuxième tâche Refléter les données, Snowflake Mirror, est ajoutée pour créer les vues nécessaires afin de permettre l'interrogation des données depuis Snowflake. La tâche de mise en miroir utilise le mécanisme d'actualisation géré par Qlik, ce qui permet des transformations en aval.
-
Une troisième tâche Refléter les données, Databricks Mirror, est ajoutée pour permettre l'interrogation des données depuis Databricks via un catalogue externe dans Databricks Unity Catalog.
Mécanisme d'actualisation
Le mécanisme d'actualisation disponible dépend de votre fournisseur d'entrepôt de données cloud, comme détaillé ci-dessous.
Amazon Redshift
Les données mises en miroir dans Amazon Redshift sont automatiquement actualisées et il n'est pas nécessaire de planifier ou d'exécuter la tâche. Tous les noms de table et de vue sont convertis en minuscules dans Amazon Redshift, car Qlik Open Lakehouse ne supporte pas les noms d'objet sensibles à la casse (base de données, schéma, table ou colonne).
Snowflake
Snowflake pointe vers les métadonnées qui reflètent le dernier instantané des données disponibles dans Iceberg. Il existe deux méthodes d'actualisation des métadonnées :
-
Gestion par Qlik : cette option nécessite un entrepôt Snowflake actif et inclut la surveillance et la prévisualisation des données. Sélectionnez cette option lorsque vous souhaitez créer des transformations en aval et surveiller et planifier la tâche. Qlik possède l'opération d'actualisation des métadonnées, si bien que vous pouvez la configurer manuellement, par exemple pour qu'elle s'exécute toutes les 30 minutes. Cette option est particulièrement utile pour les transformations multi-tables, car les métadonnées de toutes les tables sont mises à jour simultanément. Bien que vous risquiez de perdre une partie du gain en temps réel qu'offre l'actualisation Gestion par Snowflake, vous maintenez la cohérence entre les tables. Pour les transformations multi-tables, vous pouvez déclencher l'actualisation aussi souvent que nécessaire. Qlik recommande de définir un déclenchement basé sur les événements pour les tâches de transformation en aval qui suivent la tâche de mise en miroir planifiée.
-
Gestion par Snowflake : opération sans serveur qui tire parti de l'infrastructure Snowpipe sans nécessiter ni activer d'entrepôt de calcul. Cette option est recommandée lorsque vous n'avez pas besoin de transformations en aval. L'intervalle d'actualisation est configuré lorsque vous créez l'intégration de catalogue Snowflake. Pour surveiller le statut de l'actualisation automatique, interrogez SYSTEM$AUTO_REFRESH_STATUS dans Snowflake. Qlik perd la titularité du processus et n'est pas en mesure de surveiller les tâches de ce type.
The parquet file 'tg_open_lakehouse/bronze/sales/tables/tg_sales_ingestion_bronze__internal.order_details__internal/data/hdr__scd_partition=asset_state/2025_09_12_00_37_asset_state_apply-4bcbb2eb-4ad3-4d88-bea6-ea611576624e.parquet' for table 'OPENLAKEHOUSE."snowflake_mirror__internal"."ext__order_details"' was inaccessible.
Databricks
Le catalogue externe Databricks lit les métadonnées Iceberg directement depuis AWS Glue. Après l'exécution de la tâche miroir, le dernier instantané de données est disponible à des fins d'interrogation dans Databricks sans étapes d'actualisation supplémentaires.
Conditions préalables requises
Les conditions suivantes s'appliquent à toutes les cibles d'entrepôt de données supportées :
-
Une tâche Refléter les données ne peut être ajoutée qu'après la création d'une tâche de stockage dans un projet Qlik Open Lakehouse.
-
Une tâche de stockage peut avoir plusieurs tâches Refléter les données, chacune ciblant un entrepôt de données différent.
-
Une tâche Refléter les données ne peut être associée qu'à une seule tâche de stockage.
-
Pour effectuer des transformations, créez un projet d'entrepôt de données et utilisez la tâche Refléter les données comme source. Le projet et la tâche de mise en miroir doivent utiliser la même plateforme d'entrepôt de données, par exemple, Redshift.
Pour mettre vos données en miroir, configurez les paramètres de votre entrepôt de données cible.
Amazon Redshift
-
Connexion à la base de données d'entrepôt de données dans laquelle vous souhaitez mettre vos données en miroir. Vous pouvez éventuellement créer une nouvelle connexion lors de la création de la tâche de mise en miroir. Pour plus d'informations, consultez Amazon Redshift.
-
Rôle IAM assumé par Redshift avec des autorisations de lecture sur Glue Data Catalog. Le script suivant fournit les autorisations nécessaires pour pouvoir accéder à votre catalogue. Assurez-vous de remplacer <ICEBERG_BUCKET_NAME> par le nom de votre compartiment :
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "glue:GetDatabase", "glue:GetDatabases", "glue:GetTable", "glue:GetTables", "glue:GetPartition", "glue:GetPartitions" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "s3:GetObject", "s3:ListBucket" ], "Resource": [ "arn:aws:s3:::<ICEBERG_BUCKET_NAME>", "arn:aws:s3:::<ICEBERG_BUCKET_NAME>/*" ] } }Ce rôle nécessite la relation de confiance suivante :
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "redshift-serverless.amazonaws.com" }, "Action": "sts:AssumeRole" }, { "Effect": "Allow", "Principal": { "Service": "redshift.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }Note InformationsPour plus d'informations, consultez Politiques IAM pour Amazon Redshift Spectrum. -
Schéma externe dans Redshift qui pointe vers la base de données de la tâche de stockage. Vous devez créer un schéma Redshift externe en exécutant la commande CREATE EXTERNAL SCHEMA et en pointant vers la base de données interne de la tâche de stockage Iceberg source. Les consommateurs externes doivent consommer à partir des vues de consommation du schéma de la tâche de mise en miroir. Pour créer votre schéma externe, utilisez la syntaxe suivante, en vous assurant que la propriété DATABASE est la base de données créée par la tâche de stockage :
CREATE EXTERNAL SCHEMA <local_schema_name>
FROM DATA CATALOG
DATABASE '<database_name>'
IAM_ROLE 'arn:aws:iam::<AWS account-id>:role/<role-name>'
REGION '<aws-region>'
Snowflake
-
Connexion à la base de données d'entrepôt de données dans laquelle vous souhaitez mettre vos données en miroir. Vous pouvez éventuellement créer une nouvelle connexion lors de la création de la tâche de mise en miroir. Pour plus d'informations, consultez Snowflake.
-
Un volume externe Snowflake. Cela permet à Snowflake d'avoir un accès restreint à votre emplacement S3. Pour configurer le volume, consultez Configuration d'un volume externe pour Amazon S3.
-
Une intégration AWS Glue Data Catalog. Cela permet à Snowflake de se connecter aux données détenues au format de table ouverte Iceberg dans votre magasin d'objets. Pour configurer une intégration de catalogue, consultez Configuration d'une intégration de catalogue pour AWS Glue.
Databricks
-
Une connexion à l'espace de travail Databricks dans lequel vous souhaitez mettre vos données en miroir. Vous pouvez éventuellement créer une nouvelle connexion lors de la création de la tâche de mise en miroir. Pour plus d'informations, consultez Databricks.
-
Les objets suivants doivent être configurés dans AWS et Databricks avant de créer la tâche miroir :
-
Une connexion Glue dans AWS. Cela permet à Databricks de fédérer les requêtes de métadonnées via le catalogue de données AWS Glue. Pour plus d'informations, consultez AWS Glue > Connexion aux données.
-
Un identifiant de service lié à AWS dans Databricks Unity Catalog. Cela accorde à Databricks les autorisations nécessaires pour accéder aux services AWS. Pour plus d'informations, consultez Databricks > Créer des identifiants de service.
-
Un emplacement externe dans Databricks Unity Catalog qui pointe vers votre compartiment S3. Cela autorise Databricks à lire les données Iceberg au niveau du chemin d'accès à S3 géré par la tâche de stockage. Pour plus d'informations, consultez Databricks > Emplacements externes.
-
Un catalogue externe dans Databricks Unity Catalog. Cela expose les tables Iceberg enregistrées dans AWS Glue comme des tables interrogeables dans Databricks. Pour plus d'informations, consultez Databricks > Catalogues externes.
-
Création d'une tâche Refléter les données
Pour mettre des données en miroir dans votre entrepôt de données, procédez comme suit :
-
Ouvrez le projet qui contient la tâche de stockage des données que vous souhaitez mettre en miroir.
-
Cliquez sur
 Autres actions sur la tâche de stockage. Sélectionnez l'action Refléter les données et configurez-la :
Autres actions sur la tâche de stockage. Sélectionnez l'action Refléter les données et configurez-la : -
Nom : saisissez un nom pour votre tâche de mise en miroir.
-
Description : si vous le souhaitez, décrivez l'objectif de la tâche.
-
Entrepôt de données : sélectionnez votre entrepôt de données cible.
-
Connexion :
-
pour pouvoir utiliser une connexion existante, cliquez sur Sélectionner pour ouvrir la boîte de dialogue Connexion source sécurisée. Sélectionnez l'Espace dans lequel se trouve votre connexion, puis sélectionnez la connexion. Cliquez sur Modifier pour modifier les propriétés de la connexion.
-
Pour créer une nouvelle connexion, cliquez sur Créer une connexion pour ouvrir la boîte de dialogue Créer une connexion et suivez les instructions.
-
-
Base de données : saisissez le nom de la base de données dans laquelle vous souhaitez mettre les données en miroir.
-
Pour la mise en miroir dans Amazon Redshift :
-
Schéma externe : saisissez le nom du schéma dans lequel les vues seront créées.
Note InformationsTous les noms de table et de vue sont convertis en minuscules dans Amazon Redshift.
-
-
Pour la mise en miroir dans Snowflake :
-
Volume externe Snowflake : saisissez le nom du volume externe créé dans Snowflake.
-
Intégration de catalogue Snowflake : saisissez le nom de l'intégration de catalogue créée dans Snowflake.
-
Sélectionnez la manière dont vous souhaitez que vos données soient actualisées dans Snowflake :
-
Gestion par Qlik : sélectionnez cette option si vous souhaitez créer des transformations en aval. Cela nécessite un entrepôt Snowflake actif et est surveillé par Qlik.
-
Gestion par Snowflake : sélectionnez cette option si vous ne souhaitez pas effectuer de transformations en aval. Un entrepôt Snowflake n'est pas nécessaire et n'est donc pas surveillé par Qlik. Cela est administré et surveillé dans Snowflake.
-
-
-
Pour la mise en miroir dans Databricks :
-
Catalogue Databricks : saisissez le nom du Databricks Unity Catalog. Il s'agit généralement de hive_metastore.
-
Catalogue externe Databricks : saisissez le nom du catalogue externe Databricks qui est connecté à AWS Glue.
-
-
Cliquez sur OK pour créer la tâche de mise en miroir et pour l'ajouter à la tâche de stockage dans votre pipeline.
-
Cliquez sur
Autres actions sur la tâche de mise en miroir et sélectionnez Ouvrir. Assurez-vous d'afficher la vue Conception. -
Pour sélectionner un sous-jeu des jeux de données disponibles, cliquez sur Sélectionner des données sources et supprimez les jeux de données indésirables.
-
Cliquez sur Préparer pour créer les objets externes et mettre les données en miroir.
Réalisation de transformations
Si vous devez transformer vos données, vous pouvez créer un projet Redshift, Snowflake ou Databricks et utiliser une tâche Refléter les données dans votre projet Qlik Open Lakehouse comme source. La source de la tâche de mise en miroir doit être la même plateforme d'entrepôt de données cloud que le projet. Par exemple, lorsque vous créez un projet Amazon Redshift pour effectuer des transformations, vous devez utiliser une tâche Refléter les données Amazon Redshift comme source.
Affichage des informations sur les tâches
Cliquez sur ![]() dans la barre de menus pour afficher les informations sur les tâches telles que :
dans la barre de menus pour afficher les informations sur les tâches telles que :
-
Propriétaire
-
Espace
-
Plateforme de données
-
ID de projet
-
ID d'exécution de la tâche de données
Suppression d'une tâche Refléter les données
Lorsque vous supprimez une tâche de mise en miroir, les schémas et les vues internes créés par la tâche de mise en miroir sont abandonnés. Les schémas externes et la table dans Redshift ne sont pas abandonnés. Si une table est supprimée d'AWS Glue, par exemple, lorsqu'un utilisateur abandonne le jeu de données en stockage ou supprime l'intégralité de la tâche de stockage, la modification est automatiquement reflétée dans le schéma externe Redshift. La table est retirée et n'a pas besoin d'être abandonnée séparément. Il est vivement conseillé d'abandonner entièrement le schéma externe s'il n'est plus utilisé.
Pour supprimer une tâche Refléter les données, procédez comme suit :
-
Sur la tâche Refléter les données à supprimer, cliquez sur le menu
 Autres actions de la tâche et sélectionnez Supprimer.
Autres actions de la tâche et sélectionnez Supprimer. -
Dans la boîte de dialogue de confirmation, cliquez sur Supprimer.