
Reflejar datos en un almacén de datos en la nube
Las tareas de reflejo de datos le permiten consultar los datos almacenados en su Qlik Open Lakehouse desde sus almacenes de datos en la nube. Los datos se reflejan en su almacén de datos sin duplicación. El reflejo de tablas garantiza que los costes de almacenamiento e ingeniería sean mínimos y que se mantenga una única fuente de verdad.
Tras incorporar sus datos a Qlik Open Lakehouse, puede reflejar sus datos en su almacén de datos en la nube utilizando tablas espejo. Los datos en Iceberg pueden consultarse utilizando un motor de consulta que admita Iceberg de forma nativa, como Amazon Athena. Sin embargo, las tablas espejo son ideales cuando se desea implementar la arquitectura abierta de lakehouse Iceberg y seguir utilizando el motor de consulta de su almacén de datos. La tarea de reflejo de datos automatiza el proceso de hacer que las tablas Iceberg sean accesibles al declararlas como tablas y vistas externas en su almacén de datos. El almacén de datos se refiere a la tabla Iceberg como una vista externa porque no gestiona la tabla, solo lee de ella. Las tablas y vistas externas le permiten consultar sus datos Iceberg en su almacén de datos sin migrar los datos o la gestión de sus tablas a su almacén de datos.
La tarea de reflejo ejecuta las sentencias DDL necesarias para crear las tablas y vistas externas. La tabla (esquema) se muestra en el almacén de datos, junto con las tablas de cambios e historial, pero si se observa la definición de la tabla, se muestra como una vista creada sobre la tabla externa. Los consumidores de datos pueden consultar las vistas como si los datos estuvieran almacenados en su entorno de almacén de datos. Los datos reflejados ofrecen un alto rendimiento, ya que Qlik sigue gestionando y optimizando los datos.
Se admiten los siguientes almacenes de datos:
-
Amazon Redshift
-
Databricks
-
Snowflake
Duplicar en varios almacenes de datos
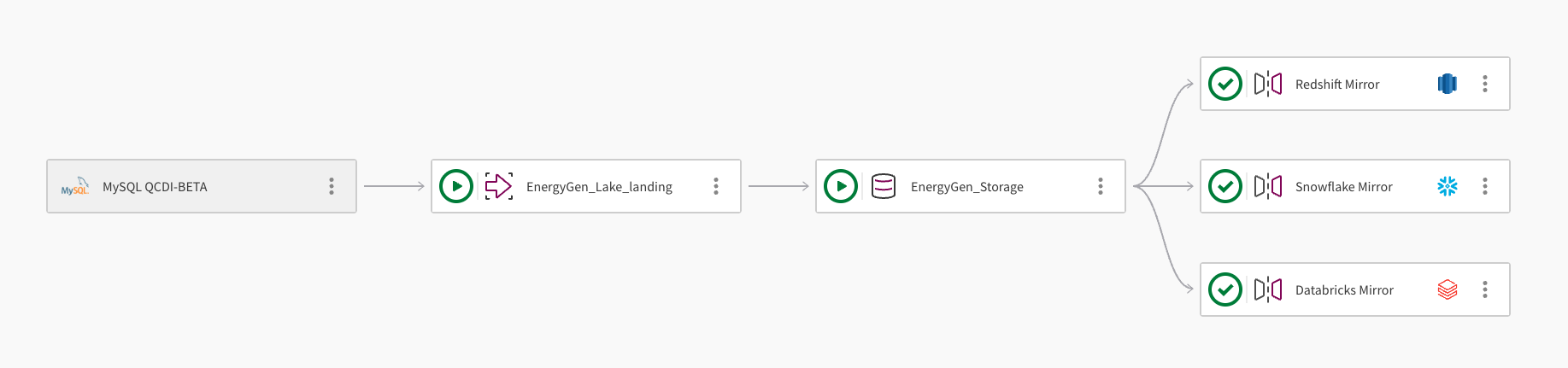
Un único conjunto de datos se puede duplicar en varios almacenes de datos en la nube. La siguiente imagen demuestra cómo un proyecto de canalización de Qlik Open Lakehouse se puede utilizar para duplicar datos en Amazon Redshift, Snowflake y Databricks:
-
La canalización ingiere datos de una base de datos MySQL utilizando la conexión, MySQL QCDI-BETA.
-
La tarea de aterrizaje en un lago de datos, EnergyGen_Lake_landing ingiere los datos sin procesar en un depóstito (bucket) de Amazon S3.
-
A continuación, la tarea de almacenamiento, EnergyGen_Storage copia los datos a una ubicación de S3 para almacenar los datos en formato de Apache Iceberg.
-
La tarea de reflejo de datos, Redshift Mirror, crea las vistas necesarias para permitir que los datos se consulten desde Amazon Redshift y actualiza automáticamente los datos.
-
Una segunda tarea de reflejo de datos, Snowflake Mirror, se añade para crear las vistas necesarias para permitir que los datos se consulten desde Snowflake.La tarea reflejada utiliza el mecanismo de actualización administrado por Qlik, lo que permite transformaciones posteriores.
-
Una tercera tarea de reflejo de datos, Databricks Mirror, se añade para permitir que los datos se consulten desde Databricks a través de un catálogo externo en Databricks Unity Catalog.
Mecanismo de actualización
El mecanismo de actualización disponible para usted dependerá de su proveedor de almacenamiento de datos en la nube, tal como se detalla a continuación.
Amazon Redshift
Los datos reflejados en Amazon Redshift se actualizan automáticamente y no es necesario programar ni ejecutar la tarea. Todos los nombres de tablas y vistas se convierten a minúsculas en Amazon Redshift, ya que Qlik Open Lakehouse no admite nombres de objetos que distingan entre mayúsculas y minúsculas (base de datos, esquema, tabla o columna).
Snowflake
Snowflake apunta a los metadatos que reflejan la última captura de los datos disponibles dentro de Iceberg. Hay dos formas de actualizar los metadatos:
-
Administrado por Qlik: esta opción requiere un almacén de Snowflake activo e incluye la supervisión y la vista previa de los datos. Seleccione esta opción cuando desee crear transformaciones posteriores, descendentes, y supervisar y programar la tarea. Qlik posee la operación de actualización de los metadatos, por lo que puede configurarlo manualmente, por ejemplo, para que se ejecute cada 30 minutos. Esta opción es especialmente útil para las transformaciones de varias tablas, ya que los metadatos de todas las tablas se actualizan simultáneamente. Aunque puede perder parte de la ganancia en tiempo real que ofrece la actualización gestionada por Snowflake, mantendrá la coherencia entre las tablas. Para las transformaciones de varias tablas, puede activar la actualización tantas veces como sea necesario. Qlik le recomienda que establezca la activación basada en eventos en las tareas de transformación posteriores que siguen a la tarea de reflejo programada.
-
Administrado por Snowflake: una operación sin servidor que aprovecha la infraestructura Snowpipe sin requerir ni activar un almacén de computación. Esta opción se recomienda cuando no necesite transformaciones posteriores. El intervalo de actualización se configura al crear la integración del catálogo Snowflake. Para supervisar el estado de la actualización automática, consulte el SYSTEM$AUTO_REFRESH_STATUS en Snowflake. Qlik pierde la propiedad del proceso y es incapaz de supervisar tareas de este tipo.
The parquet file 'tg_open_lakehouse/bronze/sales/tables/tg_sales_ingestion_bronze__internal.order_details__internal/data/hdr__scd_partition=asset_state/2025_09_12_00_37_asset_state_apply-4bcbb2eb-4ad3-4d88-bea6-ea611576624e.parquet' for table 'OPENLAKEHOUSE."snowflake_mirror__internal"."ext__order_details"' was inaccessible.
Databricks
El catálogo externo de Databricks lee los metadatos de Iceberg directamente de AWS Glue. Después de ejecutar la tarea de duplicación, la última captura de datos está disponible para consulta en Databricks sin pasos de actualización adicionales.
Requisitos previos
Los siguientes requisitos se aplican a todos los destinos de almacén de datos compatibles:
-
Una tarea de reflejo de datos solo puede añadirse después de que se haya creado una tarea de almacenamiento en un proyecto de Qlik Open Lakehouse.
-
Una tarea de almacenamiento puede tener varias tareas de reflejo de datos, cada una dirigida a un almacén de datos diferente.
-
Una tarea de reflejo de datos solo puede asociarse a una tarea de almacenamiento.
-
Para realizar transformaciones, cree un proyecto de almacenamiento de datos y utilice la tarea de reflejo de datos como origen. El proyecto y la tarea de reflejo de datos deben usar la misma plataforma de data warehouse, por ejemplo, Redshift.
Para reflejar sus datos, configure los ajustes para su almacén de datos de destino.
Amazon Redshift
-
Una conexión a la base de datos del almacén de datos en la que desea reflejar sus datos. Opcionalmente, puede crear una nueva conexión durante la creación de la tarea de reflejo. Para más información, vea Amazon Redshift.
-
Un rol de IAM asumido por Redshift con permisos de lectura de Glue Data Catalog.El siguiente script proporciona los permisos necesarios para acceder a su catálogo. Asegúrese de reemplazar <ICEBERG_BUCKET_NAME> por el nombre de su depósito (bucket):
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "glue:GetDatabase", "glue:GetDatabases", "glue:GetTable", "glue:GetTables", "glue:GetPartition", "glue:GetPartitions" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "s3:GetObject", "s3:ListBucket" ], "Resource": [ "arn:aws:s3:::<ICEBERG_BUCKET_NAME>", "arn:aws:s3:::<ICEBERG_BUCKET_NAME>/*" ] } }Este rol requiere la siguiente relación de confianza:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "redshift-serverless.amazonaws.com" }, "Action": "sts:AssumeRole" }, { "Effect": "Allow", "Principal": { "Service": "redshift.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }Nota informativaPara más información, consulte Políticas de IAM para Amazon Redshift Spectrum. -
Un esquema externo en Redshift que apunta a la base de datos de la tarea de almacenamiento. Debe crear un esquema externo de Redshift, ejecutando el comando CREATE EXTERNAL SCHEMA y apuntando a la base de datos interna de la tarea de almacenamiento de Iceberg de origen. Los consumidores externos deben consumir desde las vistas de consumo del esquema de la tarea de reflejo. Para crear su esquema externo, utilice la siguiente sintaxis, asegurándose de que la propiedad DATABASE sea la base de datos creada por la tarea de almacenamiento:
CREATE EXTERNAL SCHEMA <local_schema_name>
FROM DATA CATALOG
DATABASE '<database_name>'
IAM_ROLE 'arn:aws:iam::<AWS account-id>:role/<role-name>'
REGION '<aws-region>'
Snowflake
-
Una conexión a la base de datos del almacén de datos en la que desea reflejar sus datos. Opcionalmente, puede crear una nueva conexión durante la creación de la tarea de reflejo. Para más información, vea Snowflake.
-
Un volumen externo de Snowflake. Esto concede a Snowflake un acceso restringido a su ubicación de S3. Para configurar el volumen, consulte Configurar un volumen externo para Amazon S3.
-
Una integración de catálogo de datos de AWS Glue. Esto permite a Snowflake conectarse a los datos mantenidos en formato de tabla abierta Iceberg en su almacén de objetos. Para configurar una integración en el catálogo, consulte Configurar una integración en el catálogo para AWS Glue.
Databricks
-
Una conexión al espacio de trabajo de Databricks donde desea reflejar sus datos. Opcionalmente, puede crear una nueva conexión durante la creación de la tarea de reflejo. Para más información, vea Databricks.
-
Los siguientes objetos deben configurarse en AWS y Databricks antes de crear la tarea de duplicación:
-
Una conexión de Glue en AWS. Esto permite a Databricks federar consultas de metadatos a través del Catálogo de datos de AWS Glue. Para más información, vea AWS Glue > Conexión a datos.
-
Una credencial de servicio vinculada a AWS en Databricks Unity Catalog. Esto otorga a Databricks los permisos necesarios para acceder a los servicios de AWS. Para más información, vea Databricks > Crear credenciales de servicio.
-
Una ubicación externa en Databricks Unity Catalog que apunta a su depósito de S3. Esto autoriza a Databricks a leer datos de Iceberg en la ruta de S3 gestionada por la tarea de almacenamiento. Para más información, consulte Databricks > Ubicaciones externas.
-
Un catálogo externo en Databricks Unity Catalog. Esto expone las tablas de Iceberg registradas en AWS Glue como tablas consultables en Databricks. Para obtener más información, consulte Databricks > Catálogos externos.
-
Crear una tarea de reflejo de datos
Para reflejar datos en su almacén de datos, haga lo siguiente:
-
Abra el proyecto que contiene la tarea de almacenamiento de los datos que desea reflejar.
-
Haga clic en
 Más acciones en la tarea de almacenamiento. Seleccione Reflejar datos y configúrelos:
Más acciones en la tarea de almacenamiento. Seleccione Reflejar datos y configúrelos: -
Nombre: escriba un nombre para su tarea de reflejo de datos.
-
Descripción: opcionalmente, describa el propósito de la tarea.
-
Almacén de datos: seleccione el data warehouse de destino.
-
Conexión:
-
Para utilizar una conexión existente, haga clic en Seleccionar para abrir el cuadro de diálogo Conexión de fuente segura. Elija el Espacio en el que se encuentra su conexión y, a continuación, seleccione la conexión. Haga clic en Editar para modificar las propiedades de la conexión.
-
Para crear una nueva conexión, haga clic en Crear conexión para abrir el cuadro de diálogo Crear conexión y siga las instrucciones.
-
-
Base de datos: indique el nombre de la base de datos en la que desea reflejar los datos.
-
Para replicar en Amazon Redshift:
-
Esquema externo: indique el nombre del esquema donde se crearán las vistas.
Nota informativaTodos los nombres de tablas y vistas se convierten a minúsculas en Amazon Redshift.
-
-
Para replicar en Snowflake:
-
Volumen externo de Snowflake: escriba el nombre del volumen externo creado en Snowflake.
-
Integración en el catálogo de Snowflake: indique el nombre de la integración de catálogo creada en Snowflake.
-
Seleccione cómo desea que se actualicen sus datos en Snowflake:
-
Administrado por Qlik: seleccione esta opción si desea crear transformaciones descendentes. Esto requiere un almacén Snowflake activo y está supervisado por Qlik.
-
Administrado por Snowflake: seleccione esta opción cuando no desee realizar transformaciones posteriores.Un almacén de Snowflake no es necesario y, por tanto, no está supervisado por Qlik. Esto se administra y supervisa en Snowflake.
-
-
-
Para replicar en Databricks:
-
Catálogo de Databricks: agregue el nombre del Databricks Unity Catalog. Este suele ser hive_metastore.
-
Catálogo externo de Databricks: agregue el nombre del catálogo externo de Databricks que está conectado a AWS Glue.
-
-
Haga clic en Aceptar para crear la tarea de reflejo y añadirla a la tarea de almacenamiento en su canalización de datos.
-
Haga clic en
Más acciones en la tarea de reflejo y seleccione Abrir. Asegúrese de que está visualizando la vista Diseño. -
Para seleccionar un subconjunto de los conjuntos de datos disponibles, haga clic en Seleccionar datos de origen y elimine los conjuntos de datos no deseados.
-
Haga clic en Preparar para crear los objetos externos y reflejar los datos.
Realizar transformaciones
Si necesita transformar sus datos, puede crear un proyecto de Redshift, Snowflake o Databricks y usar una tarea de datos de Mirror dentro de su proyecto de Qlik Open Lakehouse como origen.La fuente de la tarea de reflejo debe ser la misma plataforma de almacén de datos en la nube que el proyecto.Por ejemplo, cuando crea un proyecto de Amazon Redshift para realizar transformaciones, debe usar una tarea de datos de Mirror de Amazon Redshift como origen.
Ver la información de la tarea
Haga clic en ![]() en la barra de menú para ver la información de la tarea, como:
en la barra de menú para ver la información de la tarea, como:
-
Propietario
-
Espacio
-
Plataforma de datos
-
ID de proyecto
-
ID del tiempo de ejecución de la tarea de datos
Eliminar una tarea de reflejo de datos
Cuando se elimina una tarea de reflejo de datos, los esquemas internos y las vistas creadas por la tarea de reflejo también se eliminan. Los esquemas externos y las tablas en Redshift no se eliminan. Si se elimina una tabla de AWS Glue, por ejemplo, cuando un usuario elimina el conjunto de datos del almacenamiento o elimina toda la tarea de almacenamiento, el cambio se refleja automáticamente en el esquema externo de Redshift. La tabla se elimina y no es necesario eliminarla por separado. Como práctica recomendada, elimine el esquema externo por completo si ya no está en uso.
Para eliminar una tarea de reflejo de datos, haga lo siguiente:
-
En la tarea de reflejo de datos que desee eliminar, haga clic en el menú
 Más acciones de la tarea y seleccione Eliminar.
Más acciones de la tarea y seleccione Eliminar. -
En el diálogo de confirmación, haga clic en Eliminar.