
Verwalten von Datensätzen
Sie können die Datensätze verwalten, die in Bereitstellungs-, Speicher-, Umwandlungs-, Data Mart-, Streaming-Bereitstellungs-, Streaming-Umwandlungs- und Replikations-Datenaufgaben enthalten sind, um Umwandlungen zu erstellen, Daten zu filtern und Spalten hinzuzufügen.
Die eingeschlossenen Datensätze sind unter Datensätze in der Ansicht Design aufgeführt. Sie können mit der Spaltenauswahl (![]() ) auswählen, welche Spalten angezeigt werden.
) auswählen, welche Spalten angezeigt werden.
Datensätze in der Ansicht Design einer Datenaufgabe

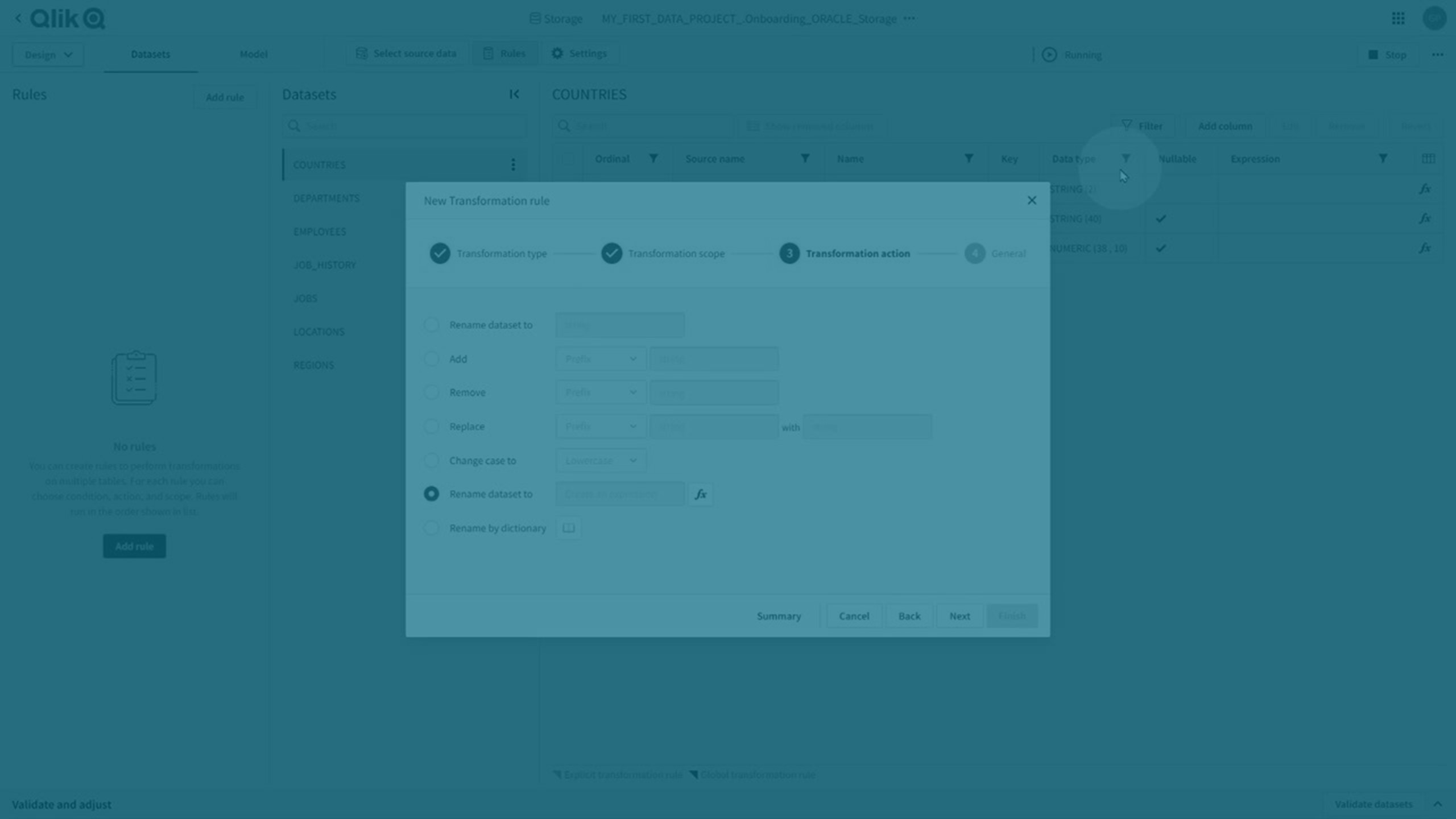
Umwandlungsregeln und explizite Umwandlungen
Sie können sowohl globale als auch explizite Umwandlungen durchführen.
Umwandlungsregeln
Sie können globale Umwandlungen durchführen, indem Sie eine Umwandlungsregel erstellen, die % als Platzhalter im Umfang verwendet, um auf alle übereinstimmenden Datensätze angewendet zu werden.
-
Klicken Sie auf Regeln und dann auf Regel hinzufügen, um eine neue Umwandlungsregel zu erstellen.
Weitere Informationen finden Sie unter Erstellen von Regeln zur Umwandlung von Datensätzen.
Umwandlungsregeln werden durch eine dunkel-lilafarbene Ecke am betroffenen Attribut gekennzeichnet.
Explizite Umwandlungen
Explizite Umwandlung werden erstellt:
-
wenn Sie Bearbeiten zum Ändern eines Spaltenattributs verwenden
-
wenn Sie Umbenennen für einen Datensatz verwenden
-
wenn Sie eine Spalte hinzufügen.
Explizite Umwandlungen werden durch eine hell-lilafarbene Ecke am betroffenen Attribut gekennzeichnet.
Datensatzmodelle
Datensätze können entweder quell- oder zielbasiert sein, je nach Aufgabentyp und den Vorgängen in der Aufgabe. Das verwendete Datensatzmodell wirkt sich auf das Verhalten der Pipeline bei Quelländerungen aus und bestimmt, welche Vorgänge Sie durchführen können.
-
Quellbasierte Datensätze
Der Datensatz basiert auf Quelldatensätzen und enthält nur Änderungen in den Metadaten. Eine Änderung der Quelldaten wird automatisch übernommen, was zu Änderungen in allen nachgelagerten Aufgaben führen kann. Es ist nicht möglich, die Reihenfolge der Spalten oder den Quelldatensatz zu ändern.
Die folgenden Aufgabentypen verwenden immer ein quellbasiertes Datensatzmodell: Bereitstellung, Speicherung, registrierte Daten, Replikation und Bereitstellung in einem Data Lake.
-
Zielbasierte Datensätze
Der Datensatz basiert auf den Zielmetadaten. Falls eine Spalte aus der Quelle hinzugefügt oder entfernt wird, wird sie nicht automatisch zur nächsten nachgelagerten Aufgabe propagiert. Sie können auch die Spaltenreihenfolge und den Quelldatensatz ändern. Das bedeutet, dass die Aufgabe eigenständiger ist und Sie die Auswirkungen von Änderungen an der Quelle kontrollieren können.
Die folgenden Aufgabentypen können ein zielbasiertes Datensatzmodell verwenden: Umwandeln, Data Mart. Es gibt einige Fälle, in denen ein quellbasiertes Modell für Umwandlungsaufgaben auf der Grundlage des Vorgangs verwendet wird.
-
Wenn eine SQL-Umwandlung oder ein Umwandlungsfluss eine Spaltenauswahl durchführt, ist der Datensatz zielbasiert. Dies gilt beispielsweise, wenn Sie SELECT A, B, C from XYZ in einer SQL-Umwandlung verwenden oder den Prozessor Spalten auswählen in einem Umwandlungsfluss verwenden.
-
Wenn die Standardspalten beibehalten werden, ist der Datensatz quellbasiert. Dies gilt zum Beispiel, wenn Sie SELECT * from XYZ in einer SQL-Umwandlung verwenden.
-
Aktualisieren von Projekten von einem quellbasierten Modell zu einem zielbasierten Modell
Sofern zutreffend, werden vorhandene Projekt auf das zielbasierte Datensatzmodell aktualisiert. Wenn Sie ein Projekt erstmals öffnen, werden Sie durch den Aktualisierungsvorgang geführt. Es gibt einige Überlegungen beim Importieren und Exportieren von Projekten mit unterschiedlichen Datensatzmodellen.
-
Es ist nicht möglich, ein Projekt mit einem quellbasierten Modell in ein Projekt mit einem zielbasierten Modell zu importieren.
Importieren Sie das Projekt mit einem quellbasierten Modell in ein neues Projekt, aktualisieren Sie das neue Projekt und exportieren Sie dann das resultierende Projekt. Sie können dieses Projekt jetzt wieder in das Projekt mit einem zielbasierten Modell importieren.
-
Es ist nicht möglich, ein Projekt mit einem zielbasierten Modell in ein Projekt mit einem quellbasierten Modell zu importieren.
Aktualisieren Sie das Projekt auf ein zielbasiertes Modell, bevor Sie ein Projekt mit einem zielbasierten Modell importieren.
Filtern eines Datensatzes
Sie können Daten filtern, um bei Bedarf einen Teilsatz der Zeilen zu erstellen.
-
Klicken Sie auf Filter.
Weitere Informationen finden Sie unter Filtern eines Datensatzes.
Umbenennen eines Datensatzes
Sie können einen Datensatz umbenennen.
-
Klicken Sie auf
 in einem Datensatz und dann auf Bearbeiten.
in einem Datensatz und dann auf Bearbeiten.
Hinzufügen von Spalten
Sie können bei Bedarf Spalten mit Umwandlungen auf Zeilenebene hinzufügen.
-
Klicken Sie auf Spalten hinzufügen.
Weitere Informationen finden Sie unter Hinzufügen von Spalten zu einem Dataset.
Bearbeiten einer Spalte
Sie können Spalteneigenschaften bearbeiten, indem Sie eine Spalte auswählen und auf Bearbeiten klicken.
-
Name
-
Schlüssel
Legen Sie eine Spalte als Primärschlüssel fest. Sie können auch Schlüssel festlegen, indem Sie sie in der Spalte Schlüssel aktivieren oder deaktivieren.
-
Nullwertfähig
-
Datentyp
Legen Sie den Datentyp der Spalte fest. Für einige Datentypen können Sie eine zusätzliche Eigenschaft festlegen, z. B. Länge.
InformationshinweisWenn Sie den Datentyp oder die Datentypgröße einer Spalte ändern, kann dies Auswirkungen auf die Aufgaben haben, die den Datensatz verwenden. Weitere Informationen finden Sie unter Verwalten von Datentypen.
Entfernen von Spalten
Sie können eine oder mehrere Spalten aus einem Datensatz entfernen.
-
Wählen Sie die zu entfernenden Spalten aus und klicken Sie auf Entfernen.
Wenn Sie die entfernten Spalten anzeigen möchten, klicken Sie auf Entfernte Spalten anzeigen. Entfernte Spalten werden mit durchgestrichenem Text dargestellt. Sie können eine entfernte Spalte wiederherstellen, indem Sie sie auswählen und auf Zurücksetzen klicken.
Zurücksetzen expliziter Änderungen an Spalten
Sie können alle expliziten Änderungen an einer oder mehreren Spalten zurücksetzen.
-
Wählen Sie die Spalten aus, für die Änderungen zurückgesetzt werden sollen, und klicken Sie auf Zurücksetzen.
Änderungen durch globale Umwandlungsregeln werden nicht zurückgesetzt.
Wenn Sie eine hinzugefügte Spalte zurücksetzen, wird sie entfernt.
Dataset-Einstellungen
Sie können die Einstellungen für den Datensatz ändern. Die Standardeinstellung besteht darin, die Einstellungen der Datenaufgabe zu übernehmen. Sie können eine Einstellung aber auch explizit als „Aktiviert“ oder „Deaktiviert“ festlegen.
-
Klicken Sie in einem Datensatz auf
 und dann auf Einstellungen.
und dann auf Einstellungen.
Anzeigen von Daten
Sie können Beispieldaten anzeigen, um die Form Ihrer Daten zu sehen und zu validieren, während Sie die Daten-Pipeline entwerfen.
Die folgenden Anforderungen müssen erfüllt sein:
-
Das Anzeigen der Daten auf Mandantenebene wird im Aktivitätscenter Administration aktiviert.
Navigieren Sie zum Aktivieren der Funktion zur Seite Einstellungen, wählen Sie die Registerkarte Funktionssteuerung aus und aktivieren Sie Daten in Datenintegration anzeigen.
-
Ihnen wird die Rolle Kann Daten anzeigen in dem Bereich zugewiesen, in dem sich die Verbindung befindet.
-
Ihnen wird die Rolle Kann anzeigen in dem Bereich zugewiesen, in dem sich das Projekt befindet.
Anzeigen von Beispieldaten
So zeigen Sie Beispieldaten auf der Registerkarte Datensätze in der Ansicht Design an:
-
Klicken Sie in Physische Objekte auf Daten anzeigen.
Ein Beispiel der Daten wird angezeigt. Mit Zeilenanzahl können Sie festlegen, wie viele Datenzeilen in das Beispiel eingeschlossen werden sollen.
Wechseln zwischen Datensätzen und Tabellen
So wechseln Sie zwischen Datensätzen und Tabellen:
-
Wählen Sie Datensätze aus, um die logische Darstellung der Daten anzuzeigen.
-
Wählen Sie Physische Objekte aus, um die physische Darstellung in der Datenbank als Tabellen und Ansichten anzuzeigen.
Hinweis zu NeuigkeitenDiese Option ist nicht verfügbar, wenn die physische Darstellung noch nicht erstellt ist.
Filterung
Sie können die Beispieldaten auf zwei Arten filtern:
-
Verwenden Sie
 , um zu filtern, welche Beispieldaten abgerufen werden.
, um zu filtern, welche Beispieldaten abgerufen werden.Wenn Sie beispielsweise den Filter ${OrderYear}>2023 verwenden und Zeilenanzahl auf 10 festlegen, erhalten Sie beispielhaft 10 Bestellungen des Jahres 2024.
-
Filtern Sie die Beispieldaten nach einer bestimmten Spalte.
Dies betrifft nur die vorhandenen Beispieldaten. Wenn Sie
verwendet haben, um nur Bestellungen aus 2024 einzuschließen, und den Spaltenfilter auf de Anzeige von Bestellungen aus 2022 festlegen, ist das Ergebnis ein leeres Beispiel.
Sortierung
Sie können die Beispieldaten auch nach einer bestimmten Spalte filtern. Die Sortierung betrifft nur die vorhandenen Beispieldaten. Wenn Sie ![]() verwendet haben, um nur Bestellungen aus 2024 einzuschließen, und die Sortierreihenfolge umkehren, enthalten die Beispieldaten immer noch nur Bestellungen aus 2024.
verwendet haben, um nur Bestellungen aus 2024 einzuschließen, und die Sortierreihenfolge umkehren, enthalten die Beispieldaten immer noch nur Bestellungen aus 2024.
Ausblenden von Spalten
Sie können Spalten in der Datenansicht ausblenden:
-
Blenden Sie eine Spalte aus, indem Sie in der Spalte auf
klicken und dann Spalte ausblenden auswählen. -
Blenden Sie mehrere Spalten aus, indem Sie in einer beliebigen Spalte auf
klicken und dann Spalten anzeigen auswählen. Damit können Sie die Sicherheit für alle Spalten in der Ansicht steuern.
Herunterladen der Beispieldaten
Sie können die angezeigten Beispieldaten herunterladen:
-
Klicken Sie auf
 , um den Inhalt der Beispieldatenansicht herunterzuladen.
, um den Inhalt der Beispieldatenansicht herunterzuladen.
Die Beispieldaten werden als CSV-Datei in den Downloads-Abschnitt Ihres Browsers heruntergeladen.
Validieren und Anpassen der Datensätze
Sie können alle in der Datenaufgabe enthaltenen Datensätze validieren.
Erweitern Sie Validieren und anpassen, um alle Validierungsfehler und Designänderungen anzuzeigen.
Validieren der Datensätze
-
Klicken Sie auf Datensätze validieren, um die Datensätze zu validieren.
Bei der Validierung wird Folgendes geprüft:
-
Alle Tabellen haben einen Primärschlüssel.
-
Es fehlen keine Attribute.
-
Es sind keine duplizierten Tabellen- oder Spaltennamen vorhanden.
Zudem erhalten Sie eine Liste der Designänderungen im Vergleich zur Quelle:
-
Hinzugefügte Tabellen und Spalten
-
Entfernte Tabellen und Spalten
-
Umbenannte Tabellen und Spalten
-
Geänderte Primärschlüssel und Datentypen
Erweitern Sie Validieren und anpassen, um alle Validierungsfehler und Designänderungen anzuzeigen.
-
Beheben Sie die Validierungsfehler und validieren Sie die Datensätze dann erneut.
-
Die meisten Designänderungen können automatisch angepasst werden, mit Ausnahme von geänderten Primärschlüsseln oder Datentypen. In diesem Fall müssen Sie die Datensätze synchronisieren.
Vorbereiten der Datensätze
Sie können Datensätze vorbereiten, um Designänderungen falls möglich ohne Datenverlust vorzunehmen. Wenn Designänderungen vorhanden sind, die nicht ohne Datenverlust angepasst werden können, wird Ihnen die Option zum Neuerstellen der Tabellen aus der Quelle mit Datenverlust angezeigt.
Dafür muss die Aufgabe angehalten werden.
-
Klicken Sie auf
 und dann auf Vorbereiten.
und dann auf Vorbereiten.
Nachdem die Datensätze vorbereitet sind, validieren Sie sie, bevor Sie die Speicheraufgabe neu starten.
Neuerstellen von Datensätzen
Sie können die Datensätze aus der Quelle neu erstellen. Wenn Sie einen Datensatz neu erstellen, tritt Datenverlust auf. Solange Sie über die Quelldaten verfügen, können Sie sie aus der Quelle neu laden.
Dafür muss die Aufgabe angehalten werden.
-
Klicken Sie auf
und dann auf Tabellen neu erstellen.
Herunterladen von Validierungsdaten
Sie können die Daten aus Validierungsfehlern, Designänderungen und Vorbereitungsfortschritt herunterladen:
-
Klicken Sie zum Herunterladen auf
.
Die Daten werden als CSV-Datei in den Downloads-Abschnitt Ihres Browsers heruntergeladen.
Beschränkungen
-
Wenn Sie in Google BigQuery eine Spalte löschen oder umbenennen, wird die Tabelle neu erstellt, was zu Datenverlust führt.