
Gegevens spiegelen naar een clouddatawarehouse
Met spiegelingstaken kunt u gegevens die zijn opgeslagen in uw Qlik Open Lakehouse opvragen vanuit uw clouddatawarehouses. Gegevens worden zonder duplicatie in uw warehouse weergegeven. Gespiegelde tabellen zorgen ervoor dat opslag- en engineeringkosten minimaal blijven en behouden één 'single source of truth'.
Na het onboarden van uw gegevens naar een Qlik Open Lakehouse, kunt u uw gegevens spiegelen naar uw clouddatawarehouse met behulp van gespiegelde tabellen. Gegevens in Iceberg kunnen worden opgevraagd met een query-engine die Iceberg systeemeigen ondersteunt, zoals Amazon Athena. Gespiegelde tabellen zijn echter ideaal wanneer u de open Iceberg-lakehouse-architectuur wilt implementeren en de query-engine van uw datawarehouse wilt blijven gebruiken. De taak Gegevens spiegelen automatiseert het proces om Iceberg-tabellen toegankelijk te maken door ze te declareren als externe tabellen en weergaven in uw datawarehouse. Het datawarehouse verwijst naar de Iceberg-tabel als een externe weergave omdat het de tabel niet beheert, maar er alleen uit leest. Met externe tabellen en weergaven kunt u uw Iceberg-gegevens in uw datawarehouse opvragen zonder dat u gegevens of het beheer van uw tabellen naar uw datawarehouse hoeft te migreren.
De spiegelingstaak voert de benodigde DDL-instructies uit om de externe tabellen en weergaven te maken. De tabel (schema) wordt weergegeven in het datawarehouse, samen met de wijzigings- en geschiedenistabellen, maar als u naar de tabeldefinitie kijkt, wordt deze weergegeven als een weergave die boven op de externe tabel is gemaakt. Gegevensconsumenten kunnen de weergaven opvragen alsof de gegevens zijn opgeslagen in hun datawarehouse-omgeving. Gespiegelde gegevens bieden hoge prestaties, aangezien Qlik de gegevens blijft beheren en optimaliseren.
De volgende datawarehouses worden ondersteund:
-
Amazon Redshift
-
Databricks
-
Snowflake
Spiegelen naar meerdere datawarehouses
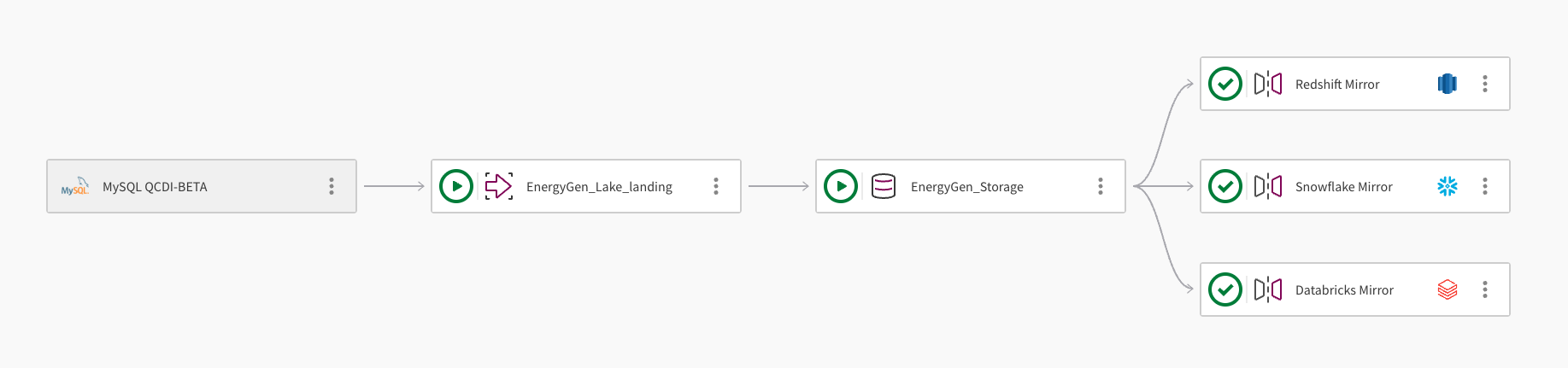
Een enkele dataset kan worden gespiegeld naar meerdere clouddatawarehouses. De volgende afbeelding laat zien hoe een Qlik Open Lakehouse-pijplijnproject kan worden gebruikt om gegevens te spiegelen naar Amazon Redshift, Snowflake en Databricks:
-
De pijplijn haalt gegevens op uit een MySQL-database met behulp van de verbinding MySQL QCDI-BETA.
-
De Lake-tussenopslagtaak, EnergyGen_Lake_landing, haalt de onbewerkte gegevens op naar een Amazon S3-bucket.
-
Vervolgens kopieert de opslagtaak, EnergyGen_Storage, de gegevens naar een S3-locatie om de gegevens op te slaan in Apache Iceberg-indeling.
-
De taak Gegevens spiegelen, Redshift Mirror, maakt de benodigde weergaven om de gegevens op te vragen vanuit Amazon Redshift en vernieuwt de gegevens automatisch.
-
Er wordt een tweede taak Gegevens spiegelen, Snowflake Mirror, toegevoegd om de benodigde weergaven te maken waarmee de gegevens vanuit Snowflake kunnen worden opgevraagd. De spiegelingstaak maakt gebruik van het door Door Qlik beheerd vernieuwingsmechanisme, dat downstream-transformaties mogelijk maakt.
-
Er wordt een derde taak Gegevens spiegelen, Databricks Mirror, toegevoegd om de gegevens op te vragen vanuit Databricks via een externe catalogus in Databricks Unity Catalog.
Vernieuwingsmechanisme
Het vernieuwingsmechanisme dat voor u beschikbaar is, hangt af van uw clouddatawarehouse-provider, zoals hieronder beschreven.
Amazon Redshift
Gegevens die naar Amazon Redshift zijn gespiegeld, worden automatisch vernieuwd en het is niet nodig om de taak te plannen of uit te voeren. Alle tabel- en weergavenamen worden in Amazon Redshift omgezet naar kleine letters, aangezien Qlik Open Lakehouse geen hoofdlettergevoelige objectnamen (database, schema, tabel of kolom) ondersteunt.
Snowflake
Snowflake verwijst naar de metagegevens die de nieuwste snapshot van de beschikbare gegevens binnen Iceberg weerspiegelen. Er zijn twee manieren om de metagegevens te vernieuwen:
-
Door Qlik beheerd: Deze optie vereist een actief Snowflake-warehouse en omvat monitoring en gegevensvoorbeeld. Selecteer deze optie als u downstream-transformaties wilt maken en de taak wilt controleren en plannen. Qlik is eigenaar van de bewerking voor het vernieuwen van metagegevens, dus u kunt dit handmatig configureren, bijvoorbeeld om de 30 minuten. Deze optie is met name relevant voor transformaties van meerdere tabellen, omdat de metagegevens voor alle tabellen tegelijkertijd worden bijgewerkt. Hoewel u mogelijk een deel van de realtime winst verliest die de door Snowflake beheerde vernieuwing biedt, behoudt u de consistentie tussen tabellen. Voor transformaties van meerdere tabellen kunt u de vernieuwing zo vaak als nodig activeren. Qlik raadt aan om gebeurtenisgestuurde activering in te stellen op downstream-transformatietaken die volgen op de geplande spiegelingstaak.
-
Door Snowflake beheerd: Een serverloze bewerking die gebruikmaakt van de Snowpipe-infrastructuur zonder dat een compute-warehouse vereist of geactiveerd hoeft te worden. Deze optie wordt aanbevolen wanneer u geen downstream-transformaties nodig hebt. Het vernieuwingsinterval wordt geconfigureerd wanneer u de Snowflake-catalogusintegratie maakt. Om de status van de automatische vernieuwing te controleren, voert u een query uit op SYSTEM$AUTO_REFRESH_STATUS in Snowflake. Qlik verliest het eigendom van het proces en kan dit type taken niet controleren.
The parquet file 'tg_open_lakehouse/bronze/sales/tables/tg_sales_ingestion_bronze__internal.order_details__internal/data/hdr__scd_partition=asset_state/2025_09_12_00_37_asset_state_apply-4bcbb2eb-4ad3-4d88-bea6-ea611576624e.parquet' for table 'OPENLAKEHOUSE."snowflake_mirror__internal"."ext__order_details"' was inaccessible.
Databricks
De externe catalogus van Databricks leest Iceberg-metagegevens rechtstreeks uit AWS Glue. Nadat u de spiegelingstaak hebt uitgevoerd, is de nieuwste gegevenssnapshot beschikbaar voor query's in Databricks zonder aanvullende vernieuwingsstappen.
Vereisten
De volgende vereisten zijn van toepassing op alle ondersteunde datawarehouse-doelen:
-
Een taak Gegevens spiegelen kan pas worden toegevoegd nadat er een opslagtaak is gemaakt in een Qlik Open Lakehouse-project.
-
Een opslagtaak kan meerdere taken Gegevens spiegelen hebben, elk gericht op een ander datawarehouse.
-
Een taak Gegevens spiegelen kan slechts aan één opslagtaak worden gekoppeld.
-
Als u transformaties wilt uitvoeren, maakt u een datawarehouse-project en gebruikt u de taak Gegevens spiegelen als bron. Het project en de spiegelingstaak moeten hetzelfde datawarehouse-platform gebruiken, bijvoorbeeld Redshift.
Configureer de instellingen voor uw doeldatawarehouse om uw gegevens te spiegelen.
Amazon Redshift
-
Een verbinding met de datawarehouse-database waarnaar u uw gegevens wilt spiegelen. Optioneel kunt u een nieuwe verbinding maken tijdens het maken van de spiegelingstaak. Raadpleeg voor meer informatie Amazon Redshift.
-
Een IAM-rol aangenomen door Redshift met leesrechten voor de Glue Data Catalog. Het volgende script biedt de benodigde machtigingen om toegang te krijgen tot uw catalogus. Zorg ervoor dat u <ICEBERG_BUCKET_NAME> vervangt door uw bucketnaam:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "glue:GetDatabase", "glue:GetDatabases", "glue:GetTable", "glue:GetTables", "glue:GetPartition", "glue:GetPartitions" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "s3:GetObject", "s3:ListBucket" ], "Resource": [ "arn:aws:s3:::<ICEBERG_BUCKET_NAME>", "arn:aws:s3:::<ICEBERG_BUCKET_NAME>/*" ] } }Deze rol vereist de volgende vertrouwensrelatie:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "redshift-serverless.amazonaws.com" }, "Action": "sts:AssumeRole" }, { "Effect": "Allow", "Principal": { "Service": "redshift.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }InformatieRaadpleeg voor meer informatie IAM-beleid voor Amazon Redshift Spectrum. -
Een extern schema in Redshift dat naar de database van de opslagtaak verwijst. U moet een extern Redshift-schema maken door de opdracht CREATE EXTERNAL SCHEMA uit te voeren en te verwijzen naar de interne database van de bron-Iceberg-opslagtaak. Externe consumenten moeten consumeren uit de consumptieweergaven van het spiegelingstaakschema. Gebruik de volgende syntaxis om uw externe schema te maken, waarbij u ervoor zorgt dat de eigenschap DATABASE de database is die door de opslagtaak is gemaakt:
CREATE EXTERNAL SCHEMA <local_schema_name>
FROM DATA CATALOG
DATABASE '<database_name>'
IAM_ROLE 'arn:aws:iam::<AWS account-id>:role/<role-name>'
REGION '<aws-region>'
Snowflake
-
Een verbinding met de datawarehouse-database waarnaar u uw gegevens wilt spiegelen. Optioneel kunt u een nieuwe verbinding maken tijdens het maken van de spiegelingstaak. Raadpleeg voor meer informatie Snowflake.
-
Een extern Snowflake-volume. Dit verleent Snowflake beperkte toegang tot uw S3-locatie. Raadpleeg Een extern volume configureren voor Amazon S3 om het volume te configureren.
-
Een AWS Glue Data Catalog-integratie. Hiermee kan Snowflake verbinding maken met gegevens die in de open tabelindeling van Iceberg in uw objectopslag worden bewaard. Raadpleeg Een catalogusintegratie configureren voor AWS Glue om een catalogusintegratie te configureren.
Databricks
-
Een verbinding met de Databricks-werkruimte waarnaar u uw gegevens wilt spiegelen. Optioneel kunt u een nieuwe verbinding maken tijdens het maken van de spiegelingstaak. Raadpleeg voor meer informatie Databricks.
-
De volgende objecten moeten in AWS en Databricks worden geconfigureerd voordat u de spiegelingstaak maakt:
-
Een Glue-verbinding in AWS. Hiermee kan Databricks metagegevensquery's federeren via de AWS Glue Data Catalog. Raadpleeg voor meer informatie AWS Glue > Verbinding maken met gegevens.
-
Een aan AWS gekoppelde servicereferentie in Databricks Unity Catalog. Dit verleent Databricks de vereiste machtigingen om toegang te krijgen tot AWS-services. Raadpleeg voor meer informatie Databricks > Servicereferenties maken.
-
Een externe locatie in Databricks Unity Catalog die naar uw S3-bucket verwijst. Dit machtigt Databricks om Iceberg-gegevens te lezen op het S3-pad dat door de opslagtaak wordt beheerd. Raadpleeg voor meer informatie Databricks > Externe locaties.
-
A externe catalogus in Databricks Unity Catalog. Hiermee worden de in AWS Glue geregistreerde Iceberg-tabellen weergegeven als opvraagbare tabellen in Databricks. Raadpleeg voor meer informatie de Databricks > Externe catalogi.
-
Een taak Gegevens spiegelen maken
Doe het volgende om gegevens naar uw datawarehouse te spiegelen:
-
Open het project dat de opslagtaak bevat voor de gegevens die u wilt spiegelen.
-
Klik op
 Meer acties op de opslagtaak. Selecteer Gegevens spiegelen en configureer deze:
Meer acties op de opslagtaak. Selecteer Gegevens spiegelen en configureer deze: -
Naam: Voer een naam in voor uw spiegelingstaak.
-
Beschrijving: Beschrijf optioneel het doel van de taak.
-
Datawarehouse: Selecteer uw doeldatawarehouse.
-
Verbinding:
-
Als u een bestaande verbinding wilt gebruiken, klikt u op Selecteren om het dialoogvenster Veilige bronverbinding te openen. Kies de Ruimte waar uw verbinding zich bevindt en selecteer vervolgens de verbinding. Klik op Bewerken om de verbindingseigenschappen te wijzigen.
-
Als u een nieuwe verbinding wilt maken, klikt u op Verbinding maken om het dialoogvenster Verbinding maken te openen en volgt u de instructies.
-
-
Database: Voer de naam in van de database waarnaar u de gegevens wilt spiegelen.
-
Om te spiegelen naar Amazon Redshift:
-
Extern schema: Voer de naam in van het schema waarin de weergaven worden gemaakt.
InformatieAlle tabel- en weergavenamen worden in Amazon Redshift omgezet naar kleine letters.
-
-
Om te spiegelen naar Snowflake:
-
Extern Snowflake-volume: Voer de naam in van het externe volume dat in Snowflake is gemaakt.
-
Snowflake-catalogusintegratie: Voer de naam in van de catalogusintegratie die in Snowflake is gemaakt.
-
Selecteer hoe u uw gegevens wilt vernieuwen in Snowflake:
-
Door Qlik beheerd: Selecteer deze optie als u downstream-transformaties wilt maken. Dit vereist een actief Snowflake-warehouse en wordt gecontroleerd door Qlik.
-
Door Snowflake beheerd: Selecteer deze optie wanneer u geen downstream-transformaties wilt uitvoeren. Een Snowflake-warehouse is niet vereist en wordt daarom niet gecontroleerd door Qlik. Dit wordt beheerd en gecontroleerd in Snowflake.
-
-
-
Om te spiegelen naar Databricks:
-
Databricks-catalogus: Voer de naam in van de Databricks Unity Catalog. Dit is meestal hive_metastore.
-
Externe Databricks-catalogus: Voer de naam in van de externe Databricks-catalogus die is verbonden met AWS Glue.
-
-
Klik op OK om de spiegelingstaak te maken en toe te voegen aan de opslagtaak in uw pijplijn.
-
Klik op
Meer acties op de spiegelingstaak en selecteer Openen. Zorg ervoor dat u de weergave Ontwerp weergeeft. -
Als u een subset van de beschikbare datasets wilt selecteren, klikt u op Brongegevens selecteren en verwijdert u eventuele ongewenste datasets.
-
Klik op Voorbereiden om de externe objecten te maken en de gegevens te spiegelen.
Transformaties uitvoeren
Als u uw gegevens moet transformeren, kunt u een Redshift-, Snowflake- of Databricks-project maken en een taak Gegevens spiegelen binnen uw Qlik Open Lakehouse-project als bron gebruiken. De bron van de spiegelingstaak moet hetzelfde clouddatawarehouse-platform zijn als het project. Als u bijvoorbeeld een Amazon Redshift-project maakt om transformaties uit te voeren, moet u een Amazon Redshift-taak Gegevens spiegelen als bron gebruiken.
Taakinformatie weergeven
Klik op ![]() in de menubalk om taakinformatie weer te geven, zoals:
in de menubalk om taakinformatie weer te geven, zoals:
-
Eigenaar
-
Ruimte
-
Gegevensplatform
-
Project-id
-
Runtime-id gegevenstaak
Een taak Gegevens spiegelen verwijderen
Wanneer u een spiegelingstaak verwijdert, worden de interne schema's en weergaven die door de spiegelingstaak zijn gemaakt, verwijderd. Externe schema's en tabellen in Redshift worden niet verwijderd. Als een tabel wordt verwijderd uit AWS Glue, bijvoorbeeld wanneer een gebruiker de dataset in de opslag verwijdert of de hele opslagtaak verwijdert, wordt de wijziging automatisch weerspiegeld in het externe Redshift-schema. De tabel wordt verwijderd en hoeft niet afzonderlijk te worden verwijderd. Als best practice kunt u het externe schema volledig verwijderen als het niet meer in gebruik is.
Doe het volgende om een taak Gegevens spiegelen te verwijderen:
-
Klik bij de taak Gegevens spiegelen die u wilt verwijderen op het menu
 Meer acties op de taak en selecteer Verwijderen.
Meer acties op de taak en selecteer Verwijderen. -
Klik in het bevestigingsvenster op Verwijderen.