
將資料鏡像到雲端資料倉庫
鏡像工作可讓您從雲端資料倉庫查詢儲存在 Qlik 開放湖倉庫 中的資料。資料會反映在您的資料倉庫中,而不會重複。鏡像表可確保儲存和工程成本降至最低,並維持單一真實來源。
將資料上線到 Qlik 開放湖倉庫 後,您可以使用鏡像表將資料鏡像到您的雲端資料倉庫。可以使用原生支援 Iceberg 的查詢引擎 (例如 Amazon Athena) 來查詢 Iceberg 中的資料。然而,當您想要實作開放式 Iceberg 湖倉架構並繼續使用您的資料倉庫查詢引擎時,鏡像表是理想的選擇。「鏡像資料」工作會自動執行使 Iceberg 表可供存取的程序,將其在您的資料倉庫中宣告為外部表和檢視。資料倉庫將 Iceberg 表視為外部檢視,因為它不管理該表,而僅從中讀取。外部表 and 檢視可讓您在資料倉庫中查詢 Iceberg 資料,而無需將資料或表的管理遷移到您的資料倉庫。
鏡像工作會執行必要的 DDL 陳述式以建立外部表和檢視。 該表 (架構) 會與變更和歷程記錄表一起顯示在資料倉庫中,但如果您查看表定義,它會顯示為在外部表之上建立的檢視。資料取用者可以查詢這些檢視,就像資料儲存在其資料倉庫環境中一樣。鏡像資料提供高效能,因為 Qlik 會繼續管理和最佳化資料。
支援以下資料倉庫:
-
Amazon Redshift
-
Databricks
-
Snowflake
鏡像到多個資料倉庫
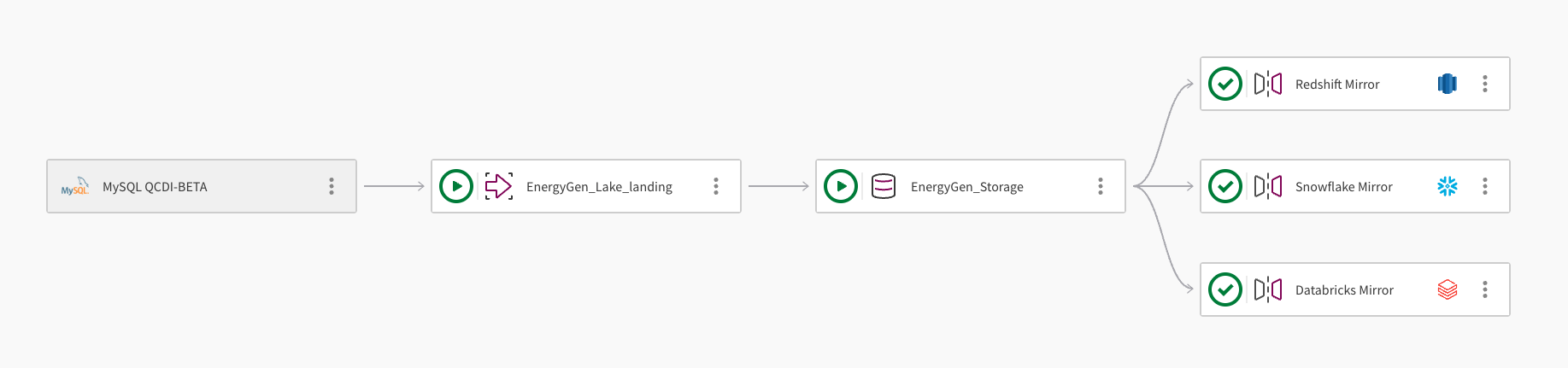
單一資料集可以鏡像到多個雲端資料倉庫。下圖說明如何使用 Qlik 開放湖倉庫 管道專案將資料鏡像到 Amazon Redshift、Snowflake 和 Databricks:
-
該管道使用連線 MySQL QCDI-BETA 從 MySQL 資料庫內嵌資料。
-
湖泊登陸工作 EnergyGen_Lake_landing 將原始資料內嵌到 Amazon S3 值區。
-
接下來,儲存工作 EnergyGen_Storage 將資料複製到 S3 位置,以 Apache Iceberg 格式儲存資料。
-
鏡像資料工作 Redshift Mirror 會建立必要的檢視,以便從 Amazon Redshift 查詢資料,並自動重新整理資料。
-
新增第二個鏡像資料工作 Snowflake Mirror,以建立必要的檢視,以便從 Snowflake 查詢資料。該鏡像工作使用 Qlik-managed 重新整理機制,這允許下游轉換。
-
新增第三個鏡像資料工作 Databricks Mirror,以便透過 Databricks Unity Catalog 中的外部目錄從 Databricks 查詢資料。
重新整理機制
您可以使用的重新整理機制取決於您的雲端資料倉庫提供者,詳情如下。
Amazon Redshift
鏡像到 Amazon Redshift 的資料會自動重新整理,無需排程或執行工作。Amazon Redshift 中的所有表和檢視名稱都會轉換為小寫,因為 Qlik 開放湖倉庫 不支援區分大小寫的物件名稱 (資料庫、架構、表或資料行)。
Snowflake
Snowflake 指向反映 Iceberg 內可用資料之最新快照的詮釋資料。有兩種方法可以重新整理詮釋資料:
-
Qlik-managed:此選項需要作用中的 Snowflake 倉庫,並包括監控和資料預覽。當您想要建立下游轉換,以及監控和排程工作時,請選擇此選項。Qlik 擁有詮釋資料重新整理作業,因此您可以手動設定此項,例如每 30 分鐘執行一次。此選項對於多表轉換特別重要,因為所有表的詮釋資料會同時更新。雖然您可能會失去 Snowflake-managed 重新整理提供的一些即時優勢,但您可以維持表之間的一致性。對於多表轉換,您可以根據需要隨時觸發重新整理。Qlik 建議您在追蹤排程鏡像工作的下游轉換工作上設定基於事件的觸發。
-
Snowflake-managed:一種無伺服器作業,利用 Snowpipe 基礎架構,而不需要或啟用運算倉庫。當您不需要下游轉換時,建議使用此選項。重新整理間隔是在您建立 Snowflake 目錄整合時設定的。若要監控自動重新整理的狀態,請在 Snowflake 中查詢 SYSTEM$AUTO_REFRESH_STATUS。Qlik 會失去該程序的擁有權,且無法監控此類型的工作。
The parquet file 'tg_open_lakehouse/bronze/sales/tables/tg_sales_ingestion_bronze__internal.order_details__internal/data/hdr__scd_partition=asset_state/2025_09_12_00_37_asset_state_apply-4bcbb2eb-4ad3-4d88-bea6-ea611576624e.parquet' for table 'OPENLAKEHOUSE."snowflake_mirror__internal"."ext__order_details"' was inaccessible.
Databricks
Databricks 外部目錄直接從 AWS Glue 讀取 Iceberg 詮釋資料。執行鏡像工作後,即可在 Databricks 中查詢最新的資料快照,而無需額外的重新整理步驟。
先決條件
以下需求適用於所有支援的資料倉庫目標:
-
只有在 Qlik 開放湖倉庫 專案中建立儲存工作後,才能新增鏡像資料工作。
-
一個儲存工作可以有多個鏡像資料工作,每個工作都針對不同的資料倉庫。
-
一個鏡像資料工作只能與一個儲存工作相關聯。
-
若要執行轉換,請建立資料倉庫專案並使用鏡像資料工作做為來源。專案和鏡像工作必須使用相同的資料倉庫平台,例如 Redshift。
若要鏡像您的資料,請設定目標資料倉庫的設定。
Amazon Redshift
-
與您要鏡像資料的資料倉庫資料庫的連線。或者,您可以在建立鏡像工作期間建立新連線。如需詳細資訊,請參閱 Amazon Redshift。
-
Redshift 擔任的具有 Glue Data Catalog 讀取權限的 IAM 角色。以下指令碼提供存取您目錄所需的權限。請確保將 <ICEBERG_BUCKET_NAME> 取代為您的值區名稱:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "glue:GetDatabase", "glue:GetDatabases", "glue:GetTable", "glue:GetTables", "glue:GetPartition", "glue:GetPartitions" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "s3:GetObject", "s3:ListBucket" ], "Resource": [ "arn:aws:s3:::<ICEBERG_BUCKET_NAME>", "arn:aws:s3:::<ICEBERG_BUCKET_NAME>/*" ] } }此角色需要以下信任關係:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "redshift-serverless.amazonaws.com" }, "Action": "sts:AssumeRole" }, { "Effect": "Allow", "Principal": { "Service": "redshift.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }資訊備註如需詳細資訊,請參閱 Amazon Redshift Spectrum 的 IAM 政策。 -
Redshift 中指向儲存工作資料庫的外部架構。您必須藉由執行 CREATE EXTERNAL SCHEMA 命令並指向來源 Iceberg 儲存工作內部資料庫,來建立外部 Redshift 架構。外部取用者應從鏡像工作架構取用檢視進行取用。若要建立您的外部架構,請使用以下語法,並確保 DATABASE 屬性是儲存工作建立的資料庫:
CREATE EXTERNAL SCHEMA <local_schema_name>
FROM DATA CATALOG
DATABASE '<database_name>'
IAM_ROLE 'arn:aws:iam::<AWS account-id>:role/<role-name>'
REGION '<aws-region>'
Snowflake
-
與您要鏡像資料的資料倉庫資料庫的連線。或者,您可以在建立鏡像工作期間建立新連線。如需詳細資訊,請參閱 Snowflake。
-
Snowflake 外部磁碟區。這會授予 Snowflake 對您 S3 位置的受限存取權。若要設定磁碟區,請參閱 設定 Amazon S3 的外部磁碟區。
-
AWS Glue Data Catalog 整合。這可讓 Snowflake 連線到物件儲存中以 Iceberg 開放表格式保存的資料。若要設定目錄整合,請參閱 設定 AWS Glue 的目錄整合。
Databricks
-
與您要鏡像資料的 Databricks 工作區的連線。或者,您可以在建立鏡像工作期間建立新連線。如需詳細資訊,請參閱 Databricks。
-
在建立鏡像工作之前,必須在 AWS 和 Databricks 中設定以下物件:
-
AWS 中的 Glue 連線。這可讓 Databricks 透過 AWS Glue Data Catalog 聯合詮釋資料查詢。如需詳細資訊,請參閱 AWS Glue > 連線到資料。
-
Databricks Unity Catalog 中與 AWS 連結的服務認證。這會授予 Databricks 存取 AWS 服務所需的權限。如需詳細資訊,請參閱 Databricks > 建立服務認證。
-
Databricks Unity Catalog 中指向您 S3 值區的外部位置。這會授權 Databricks 讀取由儲存工作管理的 S3 路徑上的 Iceberg 資料。如需詳細資訊,請參閱 Databricks > 外部位置。
-
Databricks Unity Catalog 中的外部目錄。這會將在 AWS Glue 中註冊的 Iceberg 表公開為 Databricks 中的可查詢表。如需詳細資訊,請參閱 Databricks > 外部目錄。
-
建立鏡像資料工作
若要將資料鏡像到您的資料倉庫,請執行以下操作:
-
開啟包含您要鏡像之資料的儲存工作的專案。
-
按一下儲存工作上的
 更多動作。選取 鏡像資料,然後進行設定:
更多動作。選取 鏡像資料,然後進行設定: -
名稱:輸入鏡像工作的名稱。
-
說明:(選填) 描述工作的目的。
-
資料倉庫:選取您的目標資料倉庫。
-
連線:
-
若要使用現有連線,請按一下 選取 以開啟 安全來源連線 對話方塊。選擇您連線所在的 空間,然後選取該連線。按一下 編輯 以修改連線屬性。
-
若要建立新連線,請按一下 建立連線 以開啟 建立連線 對話方塊,然後按照說明進行操作。
-
-
資料庫:輸入您要鏡像資料的資料庫名稱。
-
若要鏡像到 Amazon Redshift:
-
外部架構:輸入將在其中建立檢視的架構名稱。
資訊備註Amazon Redshift 中的所有表和檢視名稱都會轉換為小寫。
-
-
若要鏡像到 Snowflake:
-
Snowflake 外部磁碟區:輸入在 Snowflake 中建立的外部磁碟區名稱。
-
Snowflake 目錄整合:輸入在 Snowflake 中建立的目錄整合名稱。
-
選取您希望如何在 Snowflake 中重新整理資料:
-
Qlik-managed:如果您想要建立下游轉換,請選取此選項。這需要作用中的 Snowflake 倉庫,並由 Qlik 進行監控。
-
Snowflake-managed:當您不想執行下游轉換時,請選取此選項。不需要 Snowflake 倉庫,因此不受 Qlik 監控。這在 Snowflake 中進行管理和監控。
-
-
-
To mirror to Databricks:
-
Databricks 目錄:輸入 Databricks Unity Catalog 的名稱。這通常是 hive_metastore。
-
Databricks 外部目錄:輸入連線到 AWS Glue 的 Databricks 外部目錄名稱。
-
-
按一下 確定 以建立鏡像工作,並將其新增至您管道中的儲存工作。
-
按一下鏡像工作上的
更多動作,然後選取 開啟。確保您顯示的是 設計 檢視。 -
若要選取可用資料集的子集,請按一下 選取來源資料 並移除任何不需要的資料集。
-
按一下 準備 以建立外部物件並鏡像資料。
執行轉換
如果您需要轉換資料,可以建立 Redshift、Snowflake 或 Databricks 專案,並使用 Qlik 開放湖倉庫 專案中的鏡像資料工作做為來源。鏡像工作來源必須與專案使用相同的雲端資料倉庫平台。例如,當您建立 Amazon Redshift 專案以執行轉換時,您必須使用 Amazon Redshift 鏡像資料工作做為來源。
檢視任務資訊
按一下功能表長條上的 ![]() 以檢視任務資訊,例如:
以檢視任務資訊,例如:
-
擁有者
-
空間
-
資料平台
-
專案 ID
-
資料任務執行階段 ID
刪除鏡像資料工作
當您刪除鏡像工作時,會捨棄由該鏡像工作建立的內部架構和檢視。Redshift 中的外部架構和表不會被捨棄。如果從 AWS Glue 中刪除了某個表 (例如,當使用者在儲存中捨棄資料集或刪除整個儲存工作時),該變更會自動反映在 Redshift 外部架構中。該表會被移除,不需要單獨捨棄。最佳做法是,如果外部架構不再使用,請將其完全捨棄。
若要刪除鏡像資料工作,請執行以下操作:
-
在您要刪除的鏡像資料工作上,按一下該工作上的
 更多動作 功能表,然後選取 刪除。
更多動作 功能表,然後選取 刪除。 -
在確認對話方塊中,按一下 刪除。