
Зеркальное копирование данных в облачное хранилище данных
Задачи зеркального копирования позволяют запрашивать данные, хранящиеся в Открытое озеро данных Qlik, из ваших облачных хранилищ данных. Данные отражаются в вашем хранилище без дублирования. Зеркальные таблицы обеспечивают минимальные затраты на хранение и проектирование, а также поддерживают единый источник истины.
После переноса данных в Открытое озеро данных Qlik вы можете зеркально скопировать свои данные в облачное хранилище данных с помощью зеркальных таблиц. Данные в Iceberg можно запрашивать с помощью механизма запросов, который изначально поддерживает Iceberg, например Amazon Athena. Однако зеркальные таблицы идеально подходят, если вы хотите внедрить открытую архитектуру lakehouse Iceberg и продолжать использовать механизм запросов вашего хранилища данных. Задача «Зеркальное копирование данных» автоматизирует процесс предоставления доступа к таблицам Iceberg, объявляя их внешними таблицами и представлениями в вашем хранилище данных. Хранилище данных ссылается на таблицу Iceberg как на внешнее представление, поскольку оно не управляет таблицей, а только считывает из нее данные. Внешние таблицы и представления позволяют запрашивать данные Iceberg в хранилище данных без миграции данных или переноса управления таблицами в хранилище данных.
Задача зеркального копирования выполняет необходимые инструкции DDL для создания внешних таблиц и представлений. Таблица (схема) отображается в хранилище данных вместе с таблицами изменений и истории, но если вы посмотрите на определение таблицы, оно отображается как представление, созданное поверх внешней таблицы. Потребители данных могут запрашивать представления так, как если бы данные хранились в среде их хранилища данных. Зеркальные данные обеспечивают высокую производительность, поскольку Qlik продолжает управлять данными и оптимизировать их.
Поддерживаются следующие хранилища данных:
-
Amazon Redshift
-
Databricks
-
Snowflake
Зеркальное копирование в несколько хранилищ данных
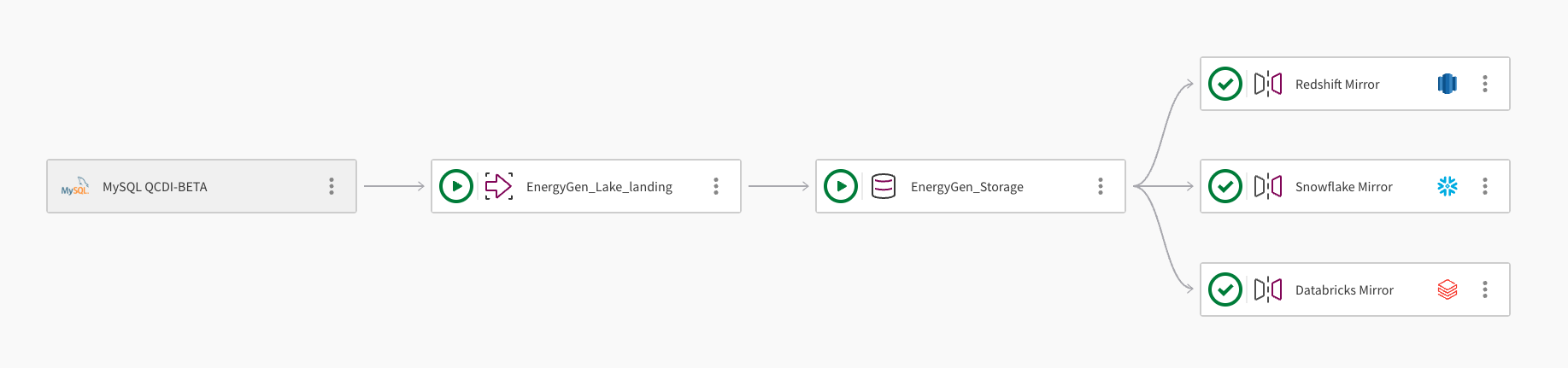
Один набор данных можно зеркально скопировать в несколько облачных хранилищ данных. На следующем рисунке показано, как проект конвейера Открытое озеро данных Qlik может использоваться для зеркального копирования данных в Amazon Redshift, Snowflake и Databricks:
-
Конвейер получает данные из базы данных MySQL с помощью подключения MySQL QCDI-BETA.
-
Задача промежуточного хранения в озере данных EnergyGen_Lake_landing загружает необработанные данные в блок Amazon S3.
-
Затем задача хранения EnergyGen_Storage копирует данные в Местоположение S3 для хранения данных в формате Apache Iceberg.
-
Задача «Зеркальное копирование данных» Redshift Mirror создает необходимые представления, позволяющие запрашивать данные из Amazon Redshift, и автоматически обновляет данные.
-
Добавляется вторая задача «Зеркальное копирование данных» Snowflake Mirror для создания необходимых представлений, позволяющих запрашивать данные из Snowflake. Задача зеркального копирования использует механизм обновления Qlik-managed, который позволяет выполнять последующие преобразования.
-
Добавляется третья задача «Зеркальное копирование данных» Databricks Mirror, позволяющая запрашивать данные из Databricks через внешний каталог в Databricks Unity Catalog.
Механизм обновления
Доступный вам механизм обновления зависит от поставщика вашего облачного хранилища данных, как подробно описано ниже.
Amazon Redshift
Данные, зеркально скопированные в Amazon Redshift, обновляются автоматически, и нет необходимости планировать или запускать задачу. Все имена таблиц и представлений преобразуются в нижний регистр в Amazon Redshift, поскольку Открытое озеро данных Qlik не поддерживает имена объектов, чувствительные к регистру (база данных, схема, таблица или столбец).
Snowflake
Snowflake указывает на метаданные, которые отражают последний снимок доступных данных в Iceberg. Существует два способа обновления метаданных:
-
управляемый Qlik: для этого варианта требуется активное хранилище Snowflake, и он включает мониторинг и предварительный просмотр данных. Выберите этот вариант, если вы хотите создавать последующие преобразования, а также отслеживать и планировать задачу. Qlik владеет операцией обновления метаданных, поэтому вы можете настроить ее вручную, например, для запуска каждые 30 минут. Этот вариант особенно актуален для многотабличных преобразований, поскольку метаданные для всех таблиц обновляются одновременно. Хотя вы можете потерять часть преимуществ работы в реальном времени, которые предлагает обновление под управлением Snowflake, вы сохраняете согласованность между таблицами. Для многотабличных преобразований вы можете запускать обновление так часто, как это необходимо. Qlik рекомендует настроить запуск на основе событий для последующих задач преобразования, которые следуют за запланированной задачей зеркального копирования.
-
Snowflake-managed: бессерверная операция, использующая инфраструктуру Snowpipe без необходимости наличия или активации вычислительного хранилища. Этот вариант рекомендуется, если вам не требуются последующие преобразования. Интервал обновления настраивается при создании интеграции каталога Snowflake. Чтобы отслеживать статус автоматического обновления, выполните запрос к SYSTEM$AUTO_REFRESH_STATUS в Snowflake. Qlik теряет право собственности на процесс и не может отслеживать задачи этого типа.
The parquet file 'tg_open_lakehouse/bronze/sales/tables/tg_sales_ingestion_bronze__internal.order_details__internal/data/hdr__scd_partition=asset_state/2025_09_12_00_37_asset_state_apply-4bcbb2eb-4ad3-4d88-bea6-ea611576624e.parquet' for table 'OPENLAKEHOUSE."snowflake_mirror__internal"."ext__order_details"' was inaccessible.
Databricks
Внешний каталог Databricks считывает метаданные Iceberg непосредственно из AWS Glue. После запуска задачи зеркального копирования последний снимок данных становится доступен для запроса в Databricks без дополнительных шагов по обновлению.
Предварительные требования
Следующие требования применяются ко всем поддерживаемым целевым хранилищам данных:
-
Задача «Зеркальное копирование данных» может быть добавлена только после создания задачи хранения в проекте Открытое озеро данных Qlik.
-
Задача хранения может иметь несколько задач «Зеркальное копирование данных», каждая из которых нацелена на отдельное хранилище данных.
-
Задача «Зеркальное копирование данных» может быть связана только с одной задачей хранения.
-
Для выполнения преобразований создайте проект хранилища данных и используйте задачу «Зеркальное копирование данных» в качестве источника. Проект и задача зеркального копирования должны использовать одну и ту же платформу хранилища данных, например Redshift.
Чтобы выполнить зеркальное копирование данных, настройте параметры для целевого хранилища данных.
Amazon Redshift
-
Подключение к базе данных хранилища данных, в которую вы хотите зеркально скопировать свои данные. При необходимости вы можете создать новое подключение во время создания задачи зеркального копирования. Для получения дополнительной информации см. Amazon Redshift.
-
Роль IAM, принимаемая Redshift, с разрешениями на чтение Glue Data Catalog. Следующий скрипт предоставляет необходимые разрешения для доступа к вашему каталогу. Обязательно замените <ICEBERG_BUCKET_NAME> именем вашего блока:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "glue:GetDatabase", "glue:GetDatabases", "glue:GetTable", "glue:GetTables", "glue:GetPartition", "glue:GetPartitions" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "s3:GetObject", "s3:ListBucket" ], "Resource": [ "arn:aws:s3:::<ICEBERG_BUCKET_NAME>", "arn:aws:s3:::<ICEBERG_BUCKET_NAME>/*" ] } }Для этой роли требуются следующие доверительные отношения:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "redshift-serverless.amazonaws.com" }, "Action": "sts:AssumeRole" }, { "Effect": "Allow", "Principal": { "Service": "redshift.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }Примечание к информацииДля получения дополнительной информации см. Политики IAM для Amazon Redshift Spectrum. -
Внешняя схема в Redshift, которая указывает на базу данных задачи хранения. Вы должны создать внешнюю схему Redshift, выполнив команду CREATE EXTERNAL SCHEMA и указав на внутреннюю базу данных исходной задачи хранения Iceberg. Внешние потребители должны использовать представления потребления схемы задачи зеркального копирования. Чтобы создать внешнюю схему, используйте следующий синтаксис, убедившись, что свойство DATABASE указывает на базу данных, созданную задачей хранения:
CREATE EXTERNAL SCHEMA <local_schema_name>
FROM DATA CATALOG
DATABASE '<database_name>'
IAM_ROLE 'arn:aws:iam::<AWS account-id>:role/<role-name>'
REGION '<aws-region>'
Snowflake
-
Подключение к базе данных хранилища данных, в которую вы хотите зеркально скопировать свои данные. При необходимости вы можете создать новое подключение во время создания задачи зеркального копирования. Для получения дополнительной информации см. Snowflake.
-
Внешний том Snowflake. Это предоставляет Snowflake ограниченный доступ к вашему Местоположению S3. Чтобы настроить том, см. раздел Настройка внешнего тома для Amazon S3.
-
Интеграция AWS Glue Data Catalog. Это позволяет Snowflake подключаться к данным, хранящимся в открытом формате таблиц Iceberg в вашем объектном хранилище. Чтобы настроить интеграцию каталога, см. раздел Настройка интеграции каталога для AWS Glue.
Databricks
-
Подключение к рабочей области Databricks, в которую вы хотите зеркально скопировать свои данные. При необходимости вы можете создать новое подключение во время создания задачи зеркального копирования. Для получения дополнительной информации см. Databricks.
-
Перед созданием задачи зеркального копирования в AWS и Databricks необходимо настроить следующие объекты:
-
Подключение Glue в AWS. Это позволяет Databricks объединять запросы метаданных через AWS Glue Data Catalog. Для получения дополнительной информации см. AWS Glue > Подключение к данным.
-
Учетные данные службы, связанные с AWS, в Databricks Unity Catalog. Это предоставляет Databricks разрешения, необходимые для доступа к службам AWS. Для получения дополнительной информации см. Databricks > Создание учетных данных службы.
-
Внешнее Местоположение в Databricks Unity Catalog, которое указывает на ваш блок S3. Это дает Databricks право читать данные Iceberg по пути S3, управляемому задачей хранения. Для получения дополнительной информации см. Databricks > Внешние местоположения.
-
Внешний каталог в Databricks Unity Catalog. Это делает таблицы Iceberg, зарегистрированные в AWS Glue, доступными в виде таблиц для запросов в Databricks. Для получения дополнительной информации см. Databricks > Внешние каталоги.
-
Создание задачи зеркального копирования данных
Чтобы выполнить зеркальное копирование данных в хранилище данных, выполните следующие действия:
-
Откройте проект, содержащий задачу хранения для данных, которые вы хотите зеркально скопировать.
-
Нажмите
 Другие действия на задаче хранения. Выберите Зеркальное копирование данных и настройте его:
Другие действия на задаче хранения. Выберите Зеркальное копирование данных и настройте его: -
Имя: введите имя для вашей задачи зеркального копирования.
-
Описание: при необходимости опишите назначение задачи.
-
Хранилище данных: выберите целевое хранилище данных.
-
Подключение:
-
Чтобы использовать существующее подключение, нажмите Выбрать, чтобы открыть диалоговое окно Безопасное подключение к источнику. Выберите Пространство, в котором находится ваше подключение, а затем выберите подключение. Нажмите Изменить, чтобы изменить свойства подключения.
-
Чтобы создать новое подключение, нажмите Создать подключение, чтобы открыть диалоговое окно Создать подключение, и следуйте инструкциям.
-
-
База данных: введите имя базы данных, в которую вы хотите зеркально скопировать данные.
-
Для зеркального копирования в Amazon Redshift:
-
Внешняя схема: введите имя схемы, в которой будут созданы представления.
Примечание к информацииВсе имена таблиц и представлений преобразуются в нижний регистр в Amazon Redshift.
-
-
Для зеркального копирования в Snowflake:
-
Внешний том Snowflake: введите имя внешнего тома, созданного в Snowflake.
-
Интеграция каталога Snowflake: введите имя интеграции каталога, созданной в Snowflake.
-
Выберите способ обновления данных в Snowflake:
-
Qlik-managed: выберите этот вариант, если вы хотите создавать последующие преобразования. Для этого требуется активное хранилище Snowflake, и оно отслеживается Qlik.
-
Snowflake-managed: выберите этот вариант, если вы не хотите выполнять последующие преобразования. Хранилище Snowflake не требуется и, следовательно, не отслеживается Qlik. Это администрируется и отслеживается в Snowflake.
-
-
-
Для зеркального копирования в Databricks:
-
Каталог Databricks: введите имя Databricks Unity Catalog. Это обычно hive_metastore.
-
Внешний каталог Databricks: введите имя внешнего каталога Databricks, подключенного к AWS Glue.
-
-
Нажмите ОК чтобы создать задачу зеркального копирования и добавить ее к задаче хранения в вашем конвейере.
-
Нажмите
Другие действия на задаче зеркального копирования и выберите Открыть. Убедитесь, что отображается представление Проектирование. -
Чтобы выбрать подмножество доступных наборов данных, нажмите Выбрать исходные данные и удалите все ненужные наборы данных.
-
Нажмите Подготовить, чтобы создать внешние объекты и выполнить зеркальное копирование данных.
Выполнение преобразований
Если вам нужно преобразовать данные, вы можете создать проект Redshift, Snowflake или Databricks и использовать задачу «Зеркальное копирование данных» в рамках вашего проекта Открытое озеро данных Qlik в качестве источника. Источник задачи зеркального копирования должен использовать ту же платформу облачного хранилища данных, что и проект. Например, при создании проекта Amazon Redshift для выполнения преобразований в качестве источника необходимо использовать задачу «Зеркальное копирование данных» Amazon Redshift.
Просмотр информации о задаче
Нажмите ![]() на панели меню, чтобы просмотреть информацию о задаче, например:
на панели меню, чтобы просмотреть информацию о задаче, например:
-
Владелец
-
Пространство
-
Платформа данных
-
Идентификатор проекта
-
Идентификатор выполнения задачи данных
Удаление задачи зеркального копирования данных
При удалении задачи зеркального копирования внутренние схемы и представления, созданные этой задачей, удаляются. Внешние схемы и таблицы в Redshift не удаляются. Если таблица удаляется из AWS Glue, например, когда пользователь удаляет набор данных в хранилище или удаляет всю задачу хранения, изменение автоматически отражается во внешней схеме Redshift. Таблица удаляется, и ее не нужно удалять отдельно. В качестве наилучшей практики полностью удалите внешнюю схему, если она больше не используется.
Чтобы удалить задачу зеркального копирования данных, выполните следующие действия:
-
В задаче зеркального копирования данных, которую вы хотите удалить, нажмите меню
 Другие действия на задаче и выберите Удалить.
Другие действия на задаче и выберите Удалить. -
В диалоговом окне подтверждения нажмите Удалить.