
Kopiowanie lustrzane danych do hurtowni danych w chmurze
Zadania kopiowania lustrzanego umożliwiają wysyłanie zapytań do danych przechowywanych w Qlik Open Lakehouse z poziomu hurtowni danych w chmurze. Dane są odzwierciedlane w hurtowni bez duplikacji. Tabele lustrzane zapewniają minimalne koszty przechowywania i inżynierii oraz utrzymują jedno źródło prawdy.
Po wdrożeniu danych do Qlik Open Lakehouse można wykonać kopiowanie lustrzane danych do hurtowni danych w chmurze za pomocą tabel lustrzanych. Zapytania do danych w formacie Iceberg można wysyłać za pomocą silnika zapytań, który natywnie obsługuje format Iceberg, takiego jak Amazon Athena. Jednak tabele lustrzane są idealne, gdy chcesz wdrożyć otwartą architekturę lakehouse Iceberg i nadal korzystać z silnika zapytań hurtowni danych. Zadanie kopiowania lustrzanego danych automatyzuje proces udostępniania tabel Iceberg, deklarując je jako tabele zewnętrzne i widoki w hurtowni danych. Hurtownia danych odnosi się do tabeli Iceberg jako widoku zewnętrznego, ponieważ nie zarządza tabelą, a jedynie z niej odczytuje. Zewnętrzne tabele i widoki umożliwiają wysyłanie zapytań do danych Iceberg w hurtowni danych bez migracji danych ani zarządzania tabelami do hurtowni danych.
Zadanie kopiowania lustrzanego wykonuje niezbędne instrukcje DDL w celu utworzenia zewnętrznych tabel i widoków. Tabela (schemat) jest wyświetlana w hurtowni danych wraz z tabelami zmian i historii, ale jeśli spojrzysz na definicję tabeli, jest ona wyświetlana jako widok utworzony na wierzchu tabeli zewnętrznej. Odbiorcy danych mogą wysyłać zapytania do widoków tak, jakby dane były przechowywane w ich środowisku hurtowni danych. Skopiowane lustrzanie dane oferują wysoką wydajność, ponieważ Qlik nadal zarządza danymi i je optymalizuje.
Obsługiwane są następujące hurtownie danych:
-
Amazon Redshift
-
Databricks
-
Snowflake
Kopiowanie lustrzane do wielu hurtowni danych
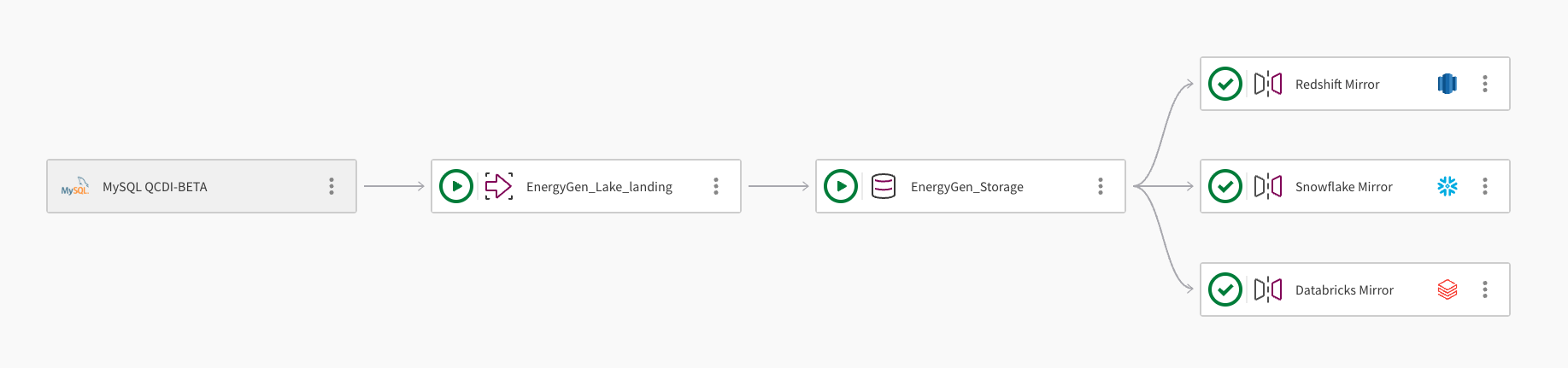
Pojedynczy zestaw danych może być kopiowany lustrzanie do wielu hurtowni danych w chmurze. Poniższy obraz przedstawia, jak projekt potoku Qlik Open Lakehouse może być użyty do kopiowania lustrzanego danych do Amazon Redshift, Snowflake i Databricks:
-
Potok pobiera dane z bazy danych MySQL przy użyciu połączenia MySQL QCDI-BETA.
-
Zadanie umieszczania w jeziorze (Lake landing), EnergyGen_Lake_landing, pobiera surowe dane do zasobnika Amazon S3.
-
Następnie zadanie przechowywania, EnergyGen_Storage, kopiuje dane do lokalizacji S3 w celu przechowywania danych w formacie Apache Iceberg.
-
Zadanie kopiowania lustrzanego danych, Redshift Mirror, tworzy niezbędne widoki, aby umożliwić wysyłanie zapytań do danych z Amazon Redshift, i automatycznie odświeża dane.
-
Drugie zadanie kopiowania lustrzanego danych, Snowflake Mirror, jest dodawane w celu utworzenia niezbędnych widoków umożliwiających wysyłanie zapytań do danych z Snowflake. Zadanie kopiowania lustrzanego wykorzystuje mechanizm odświeżania Zarządzane przez Qlik (Qlik-managed), który umożliwia transformacje na dalszych etapach.
-
Trzecie zadanie kopiowania lustrzanego danych, Databricks Mirror, jest dodawane, aby umożliwić wysyłanie zapytań do danych z Databricks za pośrednictwem katalogu obcego w Databricks Unity Catalog.
Mechanizm odświeżania
Dostępny mechanizm odświeżania zależy od dostawcy hurtowni danych w chmurze, jak opisano poniżej.
Amazon Redshift
Dane skopiowane lustrzanie do Amazon Redshift są automatycznie odświeżane i nie ma potrzeby planowania ani uruchamiania zadania. Wszystkie nazwy tabel i widoków są konwertowane na małe litery w Amazon Redshift, ponieważ Qlik Open Lakehouse nie obsługuje nazw obiektów uwzględniających wielkość liter (baza danych, schemat, tabela lub kolumna).
Snowflake
Snowflake wskazuje na metadane, które odzwierciedlają najnowszą migawkę dostępnych danych w Iceberg. Istnieją dwa sposoby odświeżania metadanych:
-
Zarządzane przez Qlik: Ta opcja wymaga aktywnej hurtowni Snowflake i obejmuje monitorowanie oraz podgląd danych. Wybierz tę opcję, jeśli chcesz tworzyć transformacje na dalszych etapach oraz monitorować i planować zadanie. Qlik jest właścicielem operacji odświeżania metadanych, więc możesz skonfigurować to ręcznie, na przykład tak, aby uruchamiało się co 30 minut. Ta opcja jest szczególnie istotna w przypadku transformacji obejmujących wiele tabel, ponieważ metadane dla wszystkich tabel są aktualizowane jednocześnie. Chociaż możesz stracić część korzyści w czasie rzeczywistym, jakie oferuje odświeżanie zarządzane przez Snowflake, zachowujesz spójność między tabelami. W przypadku transformacji obejmujących wiele tabel można wyzwalać odświeżanie tak często, jak to konieczne. Qlik zaleca ustawienie wyzwalania opartego na zdarzeniach w zadaniach transformacji na dalszych etapach, które następują po zaplanowanym zadaniu kopiowania lustrzanego.
-
Zarządzane przez Snowflake: Operacja bezserwerowa, która wykorzystuje infrastrukturę Snowpipe bez wymagania lub aktywowania hurtowni obliczeniowej. Ta opcja jest zalecana, gdy nie są wymagane transformacje na dalszych etapach. Interwał odświeżania jest konfigurowany podczas tworzenia integracji katalogu Snowflake. Aby monitorować stan automatycznego odświeżania, wyślij zapytanie do SYSTEM$AUTO_REFRESH_STATUS w Snowflake. Qlik traci własność procesu i nie jest w stanie monitorować zadań tego typu.
The parquet file 'tg_open_lakehouse/bronze/sales/tables/tg_sales_ingestion_bronze__internal.order_details__internal/data/hdr__scd_partition=asset_state/2025_09_12_00_37_asset_state_apply-4bcbb2eb-4ad3-4d88-bea6-ea611576624e.parquet' for table 'OPENLAKEHOUSE."snowflake_mirror__internal"."ext__order_details"' was inaccessible.
Databricks
Katalog obcy Databricks odczytuje metadane Iceberg bezpośrednio z AWS Glue. Po uruchomieniu zadania kopiowania lustrzanego najnowsza migawka danych jest dostępna do zapytań w Databricks bez dodatkowych kroków odświeżania.
Wymagania wstępne
Następujące wymagania dotyczą wszystkich obsługiwanych docelowych hurtowni danych:
-
Zadanie kopiowania lustrzanego danych można dodać dopiero po utworzeniu zadania przechowywania w projekcie Qlik Open Lakehouse.
-
Zadanie przechowywania może mieć wiele zadań kopiowania lustrzanego danych, z których każde jest kierowane do innej hurtowni danych.
-
Zadanie kopiowania lustrzanego danych może być powiązane tylko z jednym zadaniem przechowywania.
-
Aby wykonać transformacje, utwórz projekt hurtowni danych i użyj zadania kopiowania lustrzanego danych jako źródła. Projekt i zadanie kopiowania lustrzanego muszą korzystać z tej samej platformy hurtowni danych, na przykład Redshift.
Aby wykonać kopiowanie lustrzane danych, skonfiguruj ustawienia docelowej hurtowni danych.
Amazon Redshift
-
Połączenie z bazą danych hurtowni danych, do której chcesz skopiować lustrzanie dane. Opcjonalnie możesz utworzyć nowe połączenie podczas tworzenia zadania kopiowania lustrzanego. Więcej informacji zawiera temat Amazon Redshift.
-
Rola IAM przyjmowana przez Redshift z uprawnieniami do odczytu Glue Data Catalog. Poniższy skrypt zapewnia niezbędne uprawnienia dostępu do katalogu. Upewnij się, że zastąpisz <ICEBERG_BUCKET_NAME> nazwą swojego zasobnika:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "glue:GetDatabase", "glue:GetDatabases", "glue:GetTable", "glue:GetTables", "glue:GetPartition", "glue:GetPartitions" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "s3:GetObject", "s3:ListBucket" ], "Resource": [ "arn:aws:s3:::<ICEBERG_BUCKET_NAME>", "arn:aws:s3:::<ICEBERG_BUCKET_NAME>/*" ] } }Ta rola wymaga następującej relacji zaufania:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "redshift-serverless.amazonaws.com" }, "Action": "sts:AssumeRole" }, { "Effect": "Allow", "Principal": { "Service": "redshift.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }InformacjaWięcej informacji zawiera temat Zasady IAM dla Amazon Redshift Spectrum. -
Schemat zewnętrzny w Redshift, który wskazuje na bazę danych zadania przechowywania. Musisz utworzyć zewnętrzny schemat Redshift, wykonując polecenie CREATE EXTERNAL SCHEMA i wskazując na źródłową wewnętrzną bazę danych zadania przechowywania Iceberg. Zewnętrzni konsumenci powinni korzystać z widoków konsumpcji schematu zadania kopiowania lustrzanego. Aby utworzyć schemat zewnętrzny, użyj następującej składni, upewniając się, że właściwość DATABASE to baza danych utworzona przez zadanie przechowywania:
CREATE EXTERNAL SCHEMA <local_schema_name>
FROM DATA CATALOG
DATABASE '<database_name>'
IAM_ROLE 'arn:aws:iam::<AWS account-id>:role/<role-name>'
REGION '<aws-region>'
Snowflake
-
Połączenie z bazą danych hurtowni danych, do której chcesz skopiować lustrzanie dane. Opcjonalnie możesz utworzyć nowe połączenie podczas tworzenia zadania kopiowania lustrzanego. Więcej informacji zawiera temat Snowflake.
-
Wolumin zewnętrzny Snowflake. Zapewnia to Snowflake ograniczony dostęp do lokalizacji S3. Aby skonfigurować wolumin, zobacz Konfigurowanie woluminu zewnętrznego dla Amazon S3.
-
Integracja AWS Glue Data Catalog. Umożliwia to Snowflake łączenie się z danymi przechowywanymi w formacie otwartej tabeli Iceberg w magazynie obiektów. Aby skonfigurować integrację katalogu, zobacz Konfigurowanie integracji katalogu dla AWS Glue.
Databricks
-
Połączenie z obszarem roboczym Databricks, do którego chcesz skopiować lustrzanie dane. Opcjonalnie możesz utworzyć nowe połączenie podczas tworzenia zadania kopiowania lustrzanego. Więcej informacji zawiera temat Databricks.
-
Przed utworzeniem zadania kopiowania lustrzanego należy skonfigurować następujące obiekty w AWS i Databricks:
-
Połączenie Glue w AWS. Umożliwia to Databricks federację zapytań o metadane za pośrednictwem AWS Glue Data Catalog. Więcej informacji zawiera temat AWS Glue > Łączenie z danymi.
-
Poświadczenie usługi połączonej z AWS w Databricks Unity Catalog. Zapewnia to Databricks uprawnienia wymagane do uzyskania dostępu do usług AWS. Więcej informacji zawiera temat Databricks > Tworzenie poświadczeń usługi.
-
Lokalizacja zewnętrzna w Databricks Unity Catalog, która wskazuje na zasobnik S3. Autoryzuje to Databricks do odczytu danych Iceberg w ścieżce S3 zarządzanej przez zadanie przechowywania. Więcej informacji zawiera temat Databricks > Lokalizacje zewnętrzne.
-
Katalog obcy w Databricks Unity Catalog. Udostępnia to tabele Iceberg zarejestrowane w AWS Glue jako tabele z możliwością zapytań w Databricks. Więcej informacji zawiera temat Databricks > Katalogi obce.
-
Tworzenie zadania kopiowania lustrzanego danych
Aby skopiować lustrzanie dane do hurtowni danych, wykonaj następujące czynności:
-
Otwórz projekt zawierający zadanie przechowywania dla danych, które chcesz skopiować lustrzanie.
-
Kliknij
 Więcej akcji w zadaniu przechowywania. Wybierz Kopiowanie lustrzane danych i skonfiguruj je:
Więcej akcji w zadaniu przechowywania. Wybierz Kopiowanie lustrzane danych i skonfiguruj je: -
Nazwa: Wprowadź nazwę zadania kopiowania lustrzanego.
-
Opis: Opcjonalnie opisz cel zadania.
-
Hurtownia danych: Wybierz docelową hurtownię danych.
-
Połączenie:
-
Aby użyć istniejącego połączenia, kliknij Wybierz, aby otworzyć okno dialogowe Bezpieczne połączenie źródłowe. Wybierz Przestrzeń, w której znajduje się połączenie, a następnie wybierz połączenie. Kliknij Edytuj, aby zmienić właściwości połączenia.
-
Aby utworzyć nowe połączenie, kliknij Utwórz połączenie, aby otworzyć okno dialogowe Utwórz połączenie i postępuj zgodnie z instrukcjami.
-
-
Baza danych: Wprowadź nazwę bazy danych, do której chcesz skopiować lustrzanie dane.
-
Aby skopiować lustrzanie do Amazon Redshift:
-
Schemat zewnętrzny: Wprowadź nazwę schematu, w którym zostaną utworzone widoki.
InformacjaWszystkie nazwy tabel i widoków są konwertowane na małe litery w Amazon Redshift.
-
-
Aby skopiować lustrzanie do Snowflake:
-
Wolumin zewnętrzny Snowflake: Wprowadź nazwę woluminu zewnętrznego utworzonego w Snowflake.
-
Integracja katalogu Snowflake: Wprowadź nazwę integracji katalogu utworzonej w Snowflake.
-
Wybierz sposób odświeżania danych w Snowflake:
-
Zarządzane przez Qlik: Wybierz tę opcję, jeśli chcesz tworzyć transformacje na dalszych etapach. Wymaga to aktywnej hurtowni Snowflake i jest monitorowane przez Qlik.
-
Zarządzane przez Snowflake: Wybierz tę opcję, jeśli nie chcesz wykonywać transformacji na dalszych etapach. Hurtownia Snowflake nie jest wymagana i dlatego nie jest monitorowana przez Qlik. Jest to administrowane i monitorowane w Snowflake.
-
-
-
Aby skopiować lustrzanie do Databricks:
-
Katalog Databricks: Wprowadź nazwę Databricks Unity Catalog. Zazwyczaj jest to hive_metastore.
-
Katalog obcy Databricks: Wprowadź nazwę katalogu obcego Databricks, który jest połączony z AWS Glue.
-
-
Kliknij OK, aby utworzyć zadanie kopiowania lustrzanego i dodać je do zadania przechowywania w potoku.
-
Kliknij
Więcej akcji w zadaniu kopiowania lustrzanego i wybierz Otwórz. Upewnij się, że wyświetlany jest widok Projekt. -
Aby wybrać podzbiór dostępnych zestawów danych, kliknij Wybierz dane źródłowe i usuń niechciane zestawy danych.
-
Kliknij Przygotuj, aby utworzyć obiekty zewnętrzne i skopiować lustrzanie dane.
Wykonywanie transformacji
Jeśli musisz przekształcić dane, możesz utworzyć projekt Redshift, Snowflake lub Databricks i użyć zadania kopiowania lustrzanego danych w projekcie Qlik Open Lakehouse jako źródła. Źródło zadania kopiowania lustrzanego musi być tą samą platformą hurtowni danych w chmurze co projekt. Na przykład podczas tworzenia projektu Amazon Redshift w celu wykonania transformacji należy użyć zadania kopiowania lustrzanego danych Amazon Redshift jako źródła.
Wyświetlanie informacji o zadaniu
Kliknij ![]() na pasku menu, aby wyświetlić informacje o zadaniu, takie jak:
na pasku menu, aby wyświetlić informacje o zadaniu, takie jak:
-
Właściciel
-
Przestrzeń
-
Platforma danych
-
Identyfikator projektu
-
Identyfikator czasu wykonania zadania danych
Usuwanie zadania kopiowania lustrzanego danych
Po usunięciu zadania kopiowania lustrzanego schematy wewnętrzne i widoki utworzone przez zadanie kopiowania lustrzanego są usuwane. Zewnętrzne schematy i tabele w Redshift nie są usuwane. Jeśli tabela zostanie usunięta z AWS Glue, na przykład gdy użytkownik usunie zestaw danych w pamięci masowej lub usunie całe zadanie przechowywania, zmiana zostanie automatycznie odzwierciedlona w schemacie zewnętrznym Redshift. Tabela jest usuwana i nie trzeba jej usuwać osobno. Najlepszą praktyką jest całkowite usunięcie schematu zewnętrznego, jeśli nie jest już używany.
Aby usunąć zadanie kopiowania lustrzanego danych, wykonaj następujące czynności:
-
W zadaniu kopiowania lustrzanego danych, które chcesz usunąć, kliknij menu
 Więcej akcji w zadaniu i wybierz Usuń.
Więcej akcji w zadaniu i wybierz Usuń. -
W oknie dialogowym potwierdzenia kliknij Usuń.