
Verileri bir bulut veri deposuna yansıtma
Yansıtma görevleri, Qlik Açık Göl Evi içinde depolanan verileri bulut veri depolarınızdan sorgulamanıza olanak tanır. Veriler, yinelenmeden veri deponuza yansıtılır. Yansıtılan tablolar, depolama ve mühendislik maliyetlerinin minimum düzeyde olmasını sağlar ve tek bir doğru kaynak sürdürür.
Verilerinizi bir Qlik Açık Göl Evi ortamına aktardıktan sonra, yansıtma tablolarını kullanarak verilerinizi bulut veri deponuza yansıtabilirsiniz. Iceberg'deki veriler, Amazon Athena gibi Iceberg'i yerel olarak destekleyen bir sorgu motoru kullanılarak sorgulanabilir. Ancak yansıtma tabloları, açık Iceberg lakehouse mimarisini uygulamak ve veri deposu sorgu motorunuzu kullanmaya devam etmek istediğinizde idealdir. Yansıtma veri görevi, Iceberg tablolarını veri deponuzda harici tablolar ve görünümler olarak bildirerek erişilebilir hale getirme sürecini otomatikleştirir. Veri deposu, Iceberg tablosunu harici bir görünüm olarak adlandırır çünkü tabloyu yönetmez, yalnızca tablodan okuma yapar. Harici tablolar ve görünümler, verileri veya tablolarınızın yönetimini veri deponuza taşımadan veri deponuzdaki Iceberg verilerinizi sorgulamanıza olanak tanır.
Yansıtma görevi, harici tabloları ve görünümleri oluşturmak için gerekli DDL ifadelerini yürütür. Tablo (şema), değişiklikler ve geçmiş tablolarıyla birlikte veri deponuzda görüntülenir, ancak tablo tanımına bakarsanız harici tablonun üzerinde oluşturulmuş bir görünüm olarak görüntülenir. Veri tüketicileri, veriler kendi veri deposu ortamlarında depolanıyormuş gibi görünümleri sorgulayabilir. Yansıtılan veriler yüksek performans sunar, çünkü Qlik verileri yönetmeye ve optimize etmeye devam eder.
Aşağıdaki veri depoları desteklenir:
-
Amazon Redshift
-
Databricks
-
Snowflake
Birden çok veri deposuna yansıtma
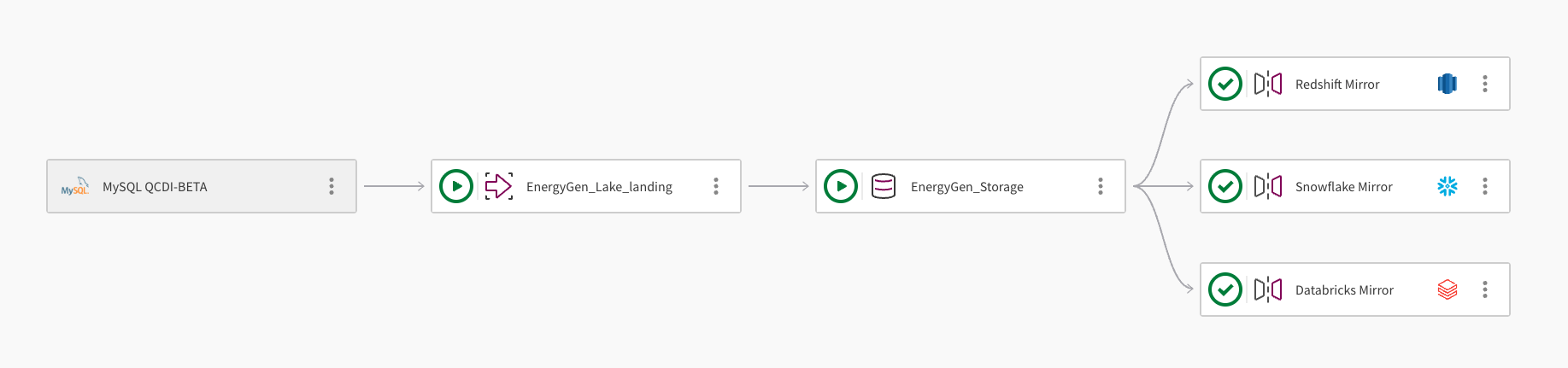
Tek bir veri kümesi birden çok bulut veri deposuna yansıtılabilir. Aşağıdaki görsel, Amazon Redshift, Snowflake ve Databricks'e veri yansıtmak için bir Qlik Açık Göl Evi işlem hattı projesinin nasıl kullanılabileceğini göstermektedir:
-
İşlem hattı, MySQL QCDI-BETA bağlantısını kullanarak bir MySQL veritabanından veri alır.
-
Göl yerleştirme görevi, EnergyGen_Lake_landing ham verileri bir Amazon S3 demetine alır.
-
Ardından, depolama görevi EnergyGen_Storage, verileri Apache Iceberg biçiminde depolamak için bir S3 konumuna kopyalar.
-
Yansıtma veri görevi, Redshift Mirror, verilerin Amazon Redshift'ten sorgulanabilmesini sağlamak için gerekli görünümleri oluşturur ve verileri otomatik olarak yeniler.
-
Verilerin Snowflake'ten sorgulanabilmesini sağlamak amacıyla gerekli görünümleri oluşturmak için ikinci bir yansıtma veri görevi, Snowflake Mirror eklenir. Yansıtma görevi, akış yönündeki dönüşümlere izin veren Qlik-managed yenileme mekanizmasını kullanır.
-
Verilerin Databricks Unity Catalog'daki bir harici katalog aracılığıyla Databricks'ten sorgulanabilmesini sağlamak için üçüncü bir yansıtma veri görevi, Databricks Mirror eklenir.
Yenileme mekanizması
Kullanabileceğiniz yenileme mekanizması, aşağıda ayrıntıları verildiği gibi bulut veri deposu sağlayıcınıza bağlıdır.
Amazon Redshift
Amazon Redshift'e yansıtılan veriler otomatik olarak yenilenir ve görevi zamanlamaya veya çalıştırmaya gerek yoktur. Amazon Redshift'te tüm tablo ve görünüm adları küçük harfe dönüştürülür, çünkü Qlik Açık Göl Evi büyük/küçük harfe duyarlı nesne adlarını (veritabanı, şema, tablo veya sütun) desteklemez.
Snowflake
Snowflake, Iceberg içindeki mevcut verilerin en son anlık görüntüsünü yansıtan meta verilere işaret eder. Meta verileri yenilemenin iki yolu vardır:
-
Qlik-managed: Bu seçenek etkin bir Snowflake ambarı gerektirir ve izleme ile veri önizlemeyi içerir. Akış yönünde dönüşümler oluşturmak ve görevi izleyip zamanlamak istediğinizde bu seçeneği belirleyin. Meta veri yenileme işleminin sahibi Qlik olduğundan, bunu örneğin her 30 dakikada bir çalışacak şekilde manuel olarak yapılandırabilirsiniz. Tüm tabloların meta verileri eş zamanlı olarak güncellendiğinden, bu seçenek özellikle çoklu tablo dönüşümleri için geçerlidir. Snowflake tarafından yönetilen yenilemenin sunduğu gerçek zamanlı kazancın bir kısmını kaybetseniz de, tablolar arasındaki tutarlılığı korursunuz. Çoklu tablo dönüşümleri için yenilemeyi gerektiği sıklıkta tetikleyebilirsiniz. Qlik, zamanlanmış yansıtma görevini takip eden akış yönündeki dönüşüm görevlerinde olay tabanlı tetikleme ayarlamanızı önerir.
-
Snowflake-managed: Bir bilgi işlem ambarı gerektirmeden veya etkinleştirmeden Snowpipe altyapısından yararlanan sunucusuz bir işlemdir. Akış yönünde dönüşümlere ihtiyaç duymadığınızda bu seçenek önerilir. Yenileme aralığı, Snowflake katalog entegrasyonunu oluşturduğunuzda yapılandırılır. Otomatik yenilemenin durumunu izlemek için Snowflake'te SYSTEM$AUTO_REFRESH_STATUS sorgusunu çalıştırın. Qlik sürecin sahipliğini kaybeder ve bu türdeki görevleri izleyemez.
The parquet file 'tg_open_lakehouse/bronze/sales/tables/tg_sales_ingestion_bronze__internal.order_details__internal/data/hdr__scd_partition=asset_state/2025_09_12_00_37_asset_state_apply-4bcbb2eb-4ad3-4d88-bea6-ea611576624e.parquet' for table 'OPENLAKEHOUSE."snowflake_mirror__internal"."ext__order_details"' was inaccessible.
Databricks
Databricks harici kataloğu, Iceberg meta verilerini doğrudan AWS Glue'dan okur. Yansıtma görevini çalıştırdıktan sonra, en son veri anlık görüntüsü ek yenileme adımları olmadan Databricks'te sorgulanabilir hale gelir.
Önkoşullar
Aşağıdaki gereksinimler desteklenen tüm veri deposu hedefleri için geçerlidir:
-
Bir yansıtma veri görevi, yalnızca bir Qlik Açık Göl Evi projesinde depolama görevi oluşturulduktan sonra eklenebilir.
-
Bir depolama görevi, her biri farklı bir veri deposunu hedefleyen birden çok yansıtma veri görevine sahip olabilir.
-
Bir yansıtma veri görevi yalnızca bir depolama göreviyle ilişkilendirilebilir.
-
Dönüşümleri gerçekleştirmek için bir veri deposu projesi oluşturun ve kaynak olarak yansıtma veri görevini kullanın. Proje ve yansıtma görevi aynı veri deposu platformunu kullanmalıdır, örneğin Redshift.
Verilerinizi yansıtmak için hedef veri deponuzun ayarlarını yapılandırın.
Amazon Redshift
-
Verilerinizi yansıtmak istediğiniz veri deposu veritabanına bir bağlantı. İsteğe bağlı olarak, yansıtma görevi oluşturma sırasında yeni bir bağlantı oluşturabilirsiniz. Daha fazla bilgi için bkz. Amazon Redshift.
-
Glue Data Catalog okuma izinlerine sahip, Redshift tarafından üstlenilen bir IAM rolü. Aşağıdaki komut dosyası, kataloğunuza erişmek için gerekli izinleri sağlar. <ICEBERG_BUCKET_NAME> kısmını kendi demet adınızla değiştirdiğinizden emin olun:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "glue:GetDatabase", "glue:GetDatabases", "glue:GetTable", "glue:GetTables", "glue:GetPartition", "glue:GetPartitions" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "s3:GetObject", "s3:ListBucket" ], "Resource": [ "arn:aws:s3:::<ICEBERG_BUCKET_NAME>", "arn:aws:s3:::<ICEBERG_BUCKET_NAME>/*" ] } }Bu rol aşağıdaki güven ilişkisini gerektirir:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "redshift-serverless.amazonaws.com" }, "Action": "sts:AssumeRole" }, { "Effect": "Allow", "Principal": { "Service": "redshift.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }Bilgi notuDaha fazla bilgi için bkz. Amazon Redshift Spectrum için IAM politikaları. -
Redshift'te depolama görevi veritabanını işaret eden harici bir şema. CREATE EXTERNAL SCHEMA komutunu yürüterek ve kaynak Iceberg depolama görevi dahili veritabanını işaret ederek harici bir Redshift şeması oluşturmalısınız. Harici tüketiciler, yansıtma görevi şeması tüketim görünümlerinden tüketmelidir. Harici şemanızı oluşturmak için, DATABASE özelliğinin depolama görevi tarafından oluşturulan veritabanı olduğundan emin olarak aşağıdaki söz dizimini kullanın:
CREATE EXTERNAL SCHEMA <local_schema_name>
FROM DATA CATALOG
DATABASE '<database_name>'
IAM_ROLE 'arn:aws:iam::<AWS account-id>:role/<role-name>'
REGION '<aws-region>'
Snowflake
-
Verilerinizi yansıtmak istediğiniz veri deposu veritabanına bir bağlantı. İsteğe bağlı olarak, yansıtma görevi oluşturma sırasında yeni bir bağlantı oluşturabilirsiniz. Daha fazla bilgi için bkz. Snowflake.
-
Bir Snowflake harici birimi. Bu, Snowflake'e S3 konumunuza kısıtlı erişim hakkı verir. Birimi yapılandırmak için bkz. Amazon S3 için harici birim yapılandırma.
-
Bir AWS Glue Data Catalog entegrasyonu. Bu, Snowflake'in nesne deponuzda Iceberg açık tablo biçiminde tutulan verilere bağlanmasını sağlar. Katalog entegrasyonunu yapılandırmak için bkz. AWS Glue için katalog entegrasyonu yapılandırma.
Databricks
-
Verilerinizi yansıtmak istediğiniz Databricks çalışma alanına bir bağlantı. İsteğe bağlı olarak, yansıtma görevi oluşturma sırasında yeni bir bağlantı oluşturabilirsiniz. Daha fazla bilgi için bkz. Databricks.
-
Yansıtma görevi oluşturulmadan önce AWS ve Databricks'te aşağıdaki nesnelerin yapılandırılması gerekir:
-
AWS'de bir Glue bağlantısı. Bu, Databricks'in AWS Glue Data Catalog aracılığıyla meta veri sorgularını birleştirmesini sağlar. Daha fazla bilgi için bkz. AWS Glue > Verilere bağlanma.
-
Databricks Unity Catalog'da AWS bağlantılı bir hizmet kimlik bilgisi. Bu, Databricks'e AWS hizmetlerine erişmek için gerekli izinleri verir. Daha fazla bilgi için bkz. Databricks > Hizmet kimlik bilgileri oluşturma.
-
Databricks Unity Catalog'da S3 demetinizi işaret eden harici bir konum. Bu, Databricks'e depolama görevi tarafından yönetilen S3 yolundaki Iceberg verilerini okuma yetkisi verir. Daha fazla bilgi için bkz. Databricks > Harici konumlar.
-
Databricks Unity Catalog'da bir harici katalog. Bu, AWS Glue'da kayıtlı Iceberg tablolarını Databricks'te sorgulanabilir tablolar olarak sunar. Daha fazla bilgi için bkz. the Databricks > Harici kataloglar.
-
Yansıtma veri görevi oluşturma
Verileri veri deponuza yansıtmak için aşağıdakileri yapın:
-
Yansıtmak istediğiniz verilere ait depolama görevini içeren projeyi açın.
-
Depolama görevinde
 Diğer eylemler seçeneğine tıklayın. Verileri yansıt seçeneğini belirleyin ve yapılandırın:
Diğer eylemler seçeneğine tıklayın. Verileri yansıt seçeneğini belirleyin ve yapılandırın: -
Ad: Yansıtma göreviniz için bir ad girin.
-
Açıklama: İsteğe bağlı olarak, görevin amacını açıklayın.
-
Veri deposu: Hedef veri deponuzu seçin.
-
Bağlantı:
-
Mevcut bir bağlantıyı kullanmak için Seç seçeneğine tıklayarak Güvenli kaynak bağlantısı iletişim kutusunu açın. Bağlantınızın bulunduğu Alan seçimini yapın, ardından bağlantıyı seçin. Bağlantı özelliklerini değiştirmek için Düzenle seçeneğine tıklayın.
-
Yeni bir bağlantı oluşturmak için Bağlantı oluştur seçeneğine tıklayarak Bağlantı oluştur iletişim kutusunu açın ve talimatları izleyin.
-
-
Veritabanı: Verileri yansıtmak istediğiniz veritabanının adını girin.
-
Amazon Redshift'e yansıtmak için:
-
Harici şema: Görünümlerin oluşturulacağı şemanın adını girin.
Bilgi notuAmazon Redshift'te tüm tablo ve görünüm adları küçük harfe dönüştürülür.
-
-
Snowflake'e yansıtmak için:
-
Snowflake harici birimi: Snowflake'te oluşturulan harici birimin adını girin.
-
Snowflake katalog entegrasyonu: Snowflake'te oluşturulan katalog entegrasyonunun adını girin.
-
Verilerinizin Snowflake'te nasıl yenilenmesini istediğinizi seçin:
-
Qlik tarafından yönetilen: Akış yönünde dönüşümler oluşturmak istiyorsanız bu seçeneği belirleyin. Bu seçenek etkin bir Snowflake ambarı gerektirir ve Qlik tarafından izlenir.
-
Snowflake tarafından yönetilen: Akış yönünde dönüşümler gerçekleştirmek istemediğinizde bu seçeneği belirleyin. Bir Snowflake ambarı gerekli değildir ve bu nedenle Qlik tarafından izlenmez. Bu işlem Snowflake'te yönetilir ve izlenir.
-
-
-
Databricks'e yansıtmak için:
-
Databricks kataloğu: Databricks Unity Catalog adını girin. Bu genellikle hive_metastore şeklindedir.
-
Databricks harici kataloğu: AWS Glue'a bağlı olan Databricks harici kataloğunun adını girin.
-
-
Yansıtma görevini oluşturmak ve işlem hattınızdaki depolama görevine eklemek için Tamam seçeneğine tıklayın.
-
Yansıtma görevinde
Diğer eylemler seçeneğine tıklayın ve Aç seçeneğini belirleyin. Tasarım görünümünü görüntülediğinizden emin olun. -
Mevcut veri kümelerinin bir alt kümesini seçmek için Kaynak verileri seç seçeneğine tıklayın ve istenmeyen veri kümelerini kaldırın.
-
Harici nesneleri oluşturmak ve verileri yansıtmak için Hazırla seçeneğine tıklayın.
Dönüşümleri gerçekleştirme
Verilerinizi dönüştürmeniz gerekiyorsa, bir Redshift, Snowflake, of Databricks projesi oluşturabilir ve kaynak olarak Qlik Açık Göl Evi projenizdeki bir Yansıtma veri görevini kullanabilirsiniz. Yansıtma görevi kaynağı, projeyle aynı bulut veri deposu platformu olmalıdır. Örneğin, dönüşümleri gerçekleştirmek için bir Amazon Redshift projesi oluşturduğunuzda, kaynak olarak bir Amazon Redshift Yansıtma veri görevi kullanmalısınız.
Görev bilgilerini görüntüleme
Görev bilgilerini görüntülemek için menü çubuğundaki ![]() öğesine tıklayın, örneğin:
öğesine tıklayın, örneğin:
-
Sahip
-
Kullanılabilir alan
-
Veri platformu
-
Proje Kimliği
-
Veri görevi çalışma zamanı kimliği
Yansıtma veri görevini silme
Bir yansıtma görevini sildiğinizde, yansıtma görevi tarafından oluşturulan dahili şemalar ve görünümler kaldırılır. Redshift'teki harici şemalar ve tablolar kaldırılmaz. Örneğin bir kullanıcı depolamadaki veri kümesini kaldırdığında veya depolama görevinin tamamını sildiğinde AWS Glue'dan bir tablo silinirse, değişiklik Redshift harici şemasına otomatik olarak yansıtılır. Tablo kaldırılır ve ayrıca silinmesi gerekmez. En iyi uygulama olarak, artık kullanılmıyorsa harici şemayı tamamen kaldırın.
Bir yansıtma veri görevini silmek için aşağıdakileri yapın:
-
Silmek istediğiniz yansıtma veri görevinde, görev üzerindeki
 Diğer eylemler menüsüne tıklayın ve Sil seçeneğini belirleyin.
Diğer eylemler menüsüne tıklayın ve Sil seçeneğini belirleyin. -
Onay iletişim kutusunda Sil seçeneğine tıklayın.