
Espelhamento de dados em um armazém de dados na nuvem
As tarefas de espelhamento permitem que você consulte os dados armazenados no seu Qlik Open Lakehouse a partir de seus armazéns de dados na nuvem. Os dados são refletidos em seu armazém sem duplicação. As tabelas espelhadas garantem que os custos de armazenamento e engenharia sejam mínimos e mantêm uma única fonte de verdade.
Depois de integrar seus dados a um Qlik Open Lakehouse, você pode espelhar seus dados em seu armazém de dados na nuvem usando tabelas de espelhamento. Os dados no Iceberg podem ser consultados usando um mecanismo de consulta compatível nativamente com o Iceberg, como o Amazon Athena. No entanto, tabelas de espelhaento são ideais quando você deseja implementar a arquitetura aberta do Iceberg Lakehouse e continuar usando o mecanismo de consulta do seu armazém de dados. A tarefa de espelhamento de dados automatiza o processo de tornar as tabelas do Iceberg acessíveis, declarando-as como tabelas e exibições externas no seu armazém de dados. O armazém de dados se refere à tabela do Iceberg como uma exibição externa porque não gerencia a tabela, apenas lê a partir dela. Tabelas e exibições externas permitem que você consulte seus dados do Iceberg em seu armazém de dados sem precisar migrar os dados ou gerenciar suas tabelas para o armazém de dados.
A tarefa de espelhamento executa as instruções DDL necessárias para criar as tabelas e exibições externas. A tabela (esquema) é exibida no armazém de dados, juntamente com as tabelas de alterações e histórico, mas, se você observar a definição da tabela, ela será exibida como uma exibição criada sobre a tabela externa. Os consumidores de dados podem consultar as exibições como se os dados estivessem armazenados em seu ambiente de armazém de dados. Os dados espelhados oferecem alto desempenho, pois o Qlik continua gerenciando e otimizando os dados.
Os seguintes armazéns de dados são compatíveis:
-
Amazon Redshift
-
Databricks
-
Snowflake
Espelhar para vários armazéns de dados
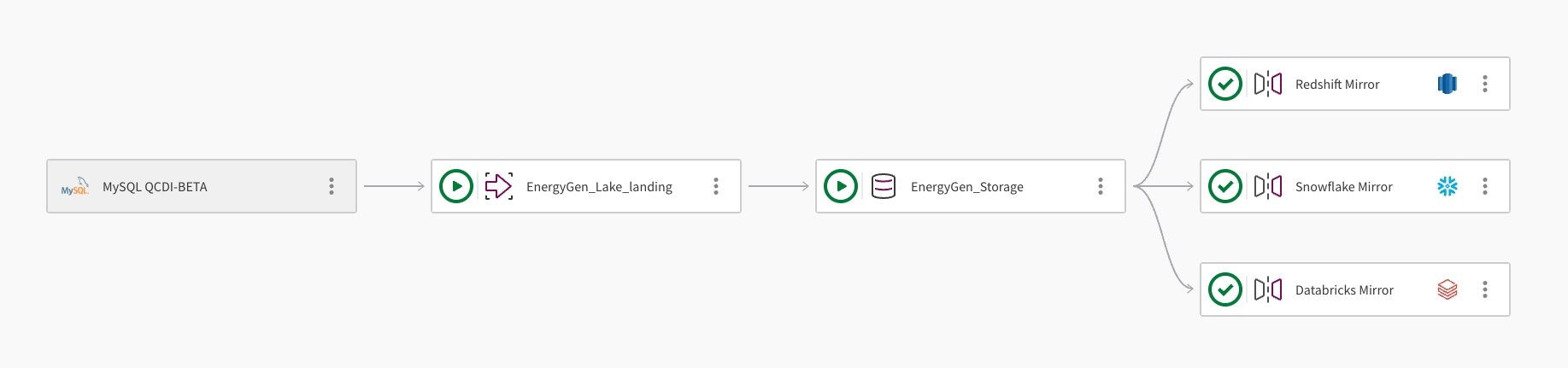
Um único conjunto de dados pode ser espelhado para vários armazéns de dados na nuvem. A imagem a seguir demonstra como um projeto de pipeline do Qlik Open Lakehouse pode ser usado para espelhar dados para o Amazon Redshift, o Snowflake e o Databricks:
-
O pipeline ingere dados de um banco de dados MySQL usando a conexão, MySQL QCDI-BETA.
-
A tarefa de aterrisagem do Lake, EnergyGen_Lake_landing ingere os dados brutos para um compartimento do Amazon S3.
-
Em seguida, a tarefa de armazenamento, EnergyGen_Storage copia os dados para um local no S3 para armazená-los no formato Apache Iceberg.
-
A tarefa de espelhamento de dados, Espelhamento do Redshift, cria as exibições necessárias para permitir que os dados sejam consultados no Amazon Redshift e atualiza os dados automaticamente.
-
Uma segunda tarefa de espelhamento de dados, Espelhamento do Snowflake, é adicionada para criar as exibições necessárias para permitir que os dados sejam consultados no Snowflake. A tarefa de espelhamento utiliza o mecanismo de atualização gerenciado pelo Qlik, que permite transformações subsequentes.
-
Uma terceira tarefa de espelhamento de dados, Espelhamento do Databricks, é adicionada para permitir que os dados sejam consultados do Databricks por meio de um catálogo externo no Databricks Unity Catalog.
Mecanismo de atualização
O mecanismo de atualização disponível para você depende do seu provedor de armazém de dados na nuvem, conforme detalhado abaixo.
Amazon Redshift
Os dados espelhados para o Amazon Redshift são atualizados automaticamente e não há necessidade de agendar ou executar a tarefa. Todos os nomes de tabelas e exibições são convertidos para minúsculas no Amazon Redshift, pois o Qlik Open Lakehouse não oferece suporte a nomes de objetos que diferenciam maiúsculas de minúsculas (banco de dados, esquema, tabela ou coluna).
Snowflake
O Snowflake aponta para os metadados que refletem o último snapshot dos dados disponíveis no Iceberg. Há duas maneiras de atualizar os metadados:
-
Qlik-managed: esta opção requer um depósito ativo do Snowflake e inclui monitoramento e visualização de dados. Selecione essa opção quando quiser criar transformações downstream e monitorar e agendar a tarefa. O Qlik é o proprietário da operação de atualização de metadados, de modo que você pode configurá-la manualmente, por exemplo, para ser executada a cada 30 minutos. Essa opção é particularmente relevante para transformações de várias tabelas, pois os metadados de todas as tabelas são atualizados simultaneamente. Embora possa perder parte do ganho em tempo real que a atualização gerenciada pelo Snowflake oferece, você mantém a consistência entre as tabelas. Para transformações de várias tabelas, você pode acionar a atualização quantas vezes forem necessárias. O Qlik recomenda que você defina o acionamento baseado em eventos nas tarefas de transformação downstream que seguem a tarefa de espelhamento programada.
-
Gerenciado pelo Snowflake: uma operação sem servidor que aproveita a infraestrutura do Snowpipe sem exigir ou ativar um armazém de computação. Essa opção é recomendada quando você não precisa de transformações downstream. O intervalo de atualização é configurado quando você cria a integração do catálogo do Snowflake. Para monitorar o status da atualização automática, consulte o SYSTEM$AUTO_REFRESH_STATUS no Snowflake. O Qlik perde a propriedade do processo e não consegue monitorar tarefas desse tipo.
The parquet file 'tg_open_lakehouse/bronze/sales/tables/tg_sales_ingestion_bronze__internal.order_details__internal/data/hdr__scd_partition=asset_state/2025_09_12_00_37_asset_state_apply-4bcbb2eb-4ad3-4d88-bea6-ea611576624e.parquet' for table 'OPENLAKEHOUSE."snowflake_mirror__internal"."ext__order_details"' was inaccessible.
Databricks
O catálogo externo do Databricks lê metadados do Iceberg diretamente do AWS Glue. Depois de executar a tarefa de espelhamento, o snapshot de dados mais recente estará disponível para consulta no Databricks sem etapas de atualização adicionais.
Pré-requisitos
Os seguintes requisitos se aplicam a todos os destinos de armazém de dados compatíveis:
-
Uma tarefa de espelhamento de dados só pode ser adicionada depois que uma tarefa de armazenamento tiver sido criada em um projeto do Qlik Open Lakehouse.
-
Uma tarefa de armazenamento pode ter várias tarefas de espelhamento de dados, cada uma visando a um armazém de dados diferente.
-
Uma tarefa de espelhamento de dados só pode ser associada a uma tarefa de armazenamento.
-
Para realizar transformações, crie um projeto de armazém de dados e use a tarefa de espelhamento de dados como a origem. O projeto e a tarefa de espelhamento devem usar a mesma plataforma de armazém de dados, por exemplo, Redshift.
Para espelhar seus dados, configure as definições para seu armazém de dados de destino.
Amazon Redshift
-
Uma conexão com o armazém de dados onde você deseja espelhar seus dados. Opcionalmente, você pode criar uma nova conexão durante a criação da tarefa de espelhamento. Para obter mais informações, consulte Amazon Redshift.
-
Uma função IAM assumida pelo Redshift com permissões de leitura do Glue Data Catalog. O script a seguir fornece as permissões necessárias para acessar seu catálogo. Certifique-se de substituir <ICEBERG_BUCKET_NAME> pelo nome do seu compartimento:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "glue:GetDatabase", "glue:GetDatabases", "glue:GetTable", "glue:GetTables", "glue:GetPartition", "glue:GetPartitions" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "s3:GetObject", "s3:ListBucket" ], "Resource": [ "arn:aws:s3:::<ICEBERG_BUCKET_NAME>", "arn:aws:s3:::<ICEBERG_BUCKET_NAME>/*" ] } }Esta função requer a seguinte relação de confiança:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "redshift-serverless.amazonaws.com" }, "Action": "sts:AssumeRole" }, { "Effect": "Allow", "Principal": { "Service": "redshift.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }Nota informativaPara obter mais informações, consulte Políticas do IAM para Amazon Redshift Spectrum. -
Um esquema externo no Redshift que aponta para o banco de dados da tarefa de armazenamento. Você deve criar um esquema externo do Redshift, executando o comando CREATE EXTERNAL SCHEMA e apontando para o banco de dados interno da tarefa de armazenamento do Iceberg de origem. Consumidores externos devem consumir das exibições de consumo do esquema da tarefa de espelhamento. Para criar seu esquema externo, use a seguinte sintaxe, garantindo que a propriedade DATABASE seja o banco de dados criado pela tarefa de armazenamento:
CREATE EXTERNAL SCHEMA <local_schema_name>
FROM DATA CATALOG
DATABASE '<database_name>'
IAM_ROLE 'arn:aws:iam::<AWS account-id>:role/<role-name>'
REGION '<aws-region>'
Snowflake
-
Uma conexão com o armazém de dados onde você deseja espelhar seus dados. Opcionalmente, você pode criar uma nova conexão durante a criação da tarefa de espelhamento. Para obter mais informações, consulte Snowflake.
-
Um volume externo do Snowflake. Isso concede à Snowflake acesso restrito à sua localização no S3. Para configurar o volume, consulte Configurar um volume externo para o Amazon S3.
-
Uma integração do AWS Glue Data Catalog. Isso permite que o Snowflake se conecte aos dados mantidos no formato de tabela aberta do Iceberg no seu armazenamento de objetos. Para configurar uma integração de catálogo, consulte Configurar uma integração de catálogo para o AWS Glue.
Databricks
-
Uma conexão com o espaço de trabalho do Databricks onde você deseja espelhar seus dados. Opcionalmente, você pode criar uma nova conexão durante a criação da tarefa de espelhamento. Para obter mais informações, consulte Databricks.
-
Os seguintes objetos devem ser configurados no AWS e no Databricks antes de criar a tarefa de espelhamento:
-
Uma conexão do Glue no AWS. Isso permite que o Databricks federe consultas de metadados através do AWS Glue Data Catalog. Para obter mais informações, consulte AWS Glue > Conectando-se aos dados.
-
Uma credencial de serviço vinculada ao AWS no Databricks Unity Catalog. Isso concede ao Databricks as permissões necessárias para acessar os serviços do AWS. Para obter mais informações, consulte Databricks > Criar credenciais de serviço.
-
Uma localização externa no Databricks Unity Catalog que aponta para o seu compartimento S3. Isso autoriza o Databricks a ler dados do Iceberg no caminho S3 gerenciado pela tarefa de armazenamento. Para obter mais informações, consulte Databricks > Localizações externas.
-
Um catálogo externo no Databricks Unity Catalog. Isso expõe as tabelas do Iceberg registradas no AWS Glue como tabelas consultáveis no Databricks. Para obter mais informações, consulte Databricks > Catálogos externos.
-
Criando uma tarefa de espelhamento de dados
Para espelhar dados para seu armazém de dados, faça o seguinte:
-
Abra o projeto que contém a tarefa de armazenamento para os dados que você deseja espelhar.
-
Clique em
 Mais ações na tarefa de armazenamento. Selecione Espelhar dados e configure-as:
Mais ações na tarefa de armazenamento. Selecione Espelhar dados e configure-as: -
Nome: digite um nome para sua tarefa de espelhamento.
-
Descrição: opcionalmente, descreva o objetivo da tarefa.
-
Armazém de dados: selecione seu armazém de dados de destino.
-
Conexão:
-
Para usar uma conexão existente, clique em Selecionar para abrir a caixa de diálogo Conexão de fonte segura. Escolha o Espaço onde a conexão está localizada e, em seguida, selecione a conexão. Clique em Editar para alterar as propriedades da conexão.
-
Para criar uma nova conexão, clique em Criar conexão para abrir o diálogo Criar conexão e siga as instruções.
-
-
Banco de dados: digite o nome do banco de dados em que você deseja espelhar os dados.
-
Para espelhar para o Amazon Redshift:
-
Esquema externo: digite o nome do esquema em que as exibições serão criadas.
Nota informativaTodos os nomes de tabelas e exibições são convertidos para minúsculas no Amazon Redshift.
-
-
Para espelhar para o Snowflake:
-
Volume externo do Snowflake: digite o nome do volume externo criado no Snowflake.
-
Integração do catálogo do Snowflake: digite o nome da integração de catálogo criada no Snowflake.
-
Selecione como você deseja que seus dados sejam atualizados no Snowflake:
-
Gerenciado pelo Qlik: selecione essa opção se você quiser criar transformações downstream. Isso requer um depósito ativo no Snowflake e é monitorado pelo Qlik.
-
Gerenciado pelo Snowflake: selecione esta opção quando não quiser executar transformações posteriores. Um armazém do Snowflake não é necessário e, portanto, não é monitorado pelo Qlik. Isso é administrado e monitorado no Snowflake.
-
-
-
Para espelhar para o Databricks:
-
Catálogo do Databricks: insira o nome do Databricks Unity Catalog. Geralmente é hive_metastore.
-
Catálogo externo do Databricks: insira o nome do catálogo externo do Databricks que está conectado ao AWS Glue.
-
-
Clique em OK para criar a tarefa de espelhamento e adicioná-la à tarefa de armazenamento em seu pipeline.
-
Clique em
Mais ações na tarefa de espelhamento e selecione Abrir. Certifique-se de que esteja exibindo a exibição Design. -
Para selecionar um subconjunto dos conjuntos de dados disponíveis, clique em Selecionar fonte de dados e remova os conjuntos de dados indesejados.
-
Clique em Preparar para criar os objetos externos e espelhar os dados.
Executando transformações
Se precisar transformar seus dados, você pode criar um projeto do Redshift, Snowflake ou Databricks e usar uma tarefa de espelhamento de dados dentro do seu projeto do Qlik Open Lakehouse como fonte. A origem da tarefa de espelhamento deve ser a mesma plataforma de armazém de dados na nuvem que a do projeto. Por exemplo, ao criar um projeto do Amazon Redshift para realizar transformações, você deve usar uma tarefa de espelhamento de dados no Amazon Redshift como fonte.
Exibindo informações da tarefa
Clique em ![]() na barra de menu para visualizar informações da tarefa, como:
na barra de menu para visualizar informações da tarefa, como:
-
Proprietário
-
Espaço
-
Plataforma de dados
-
ID do projeto
-
ID de tempo de execução da tarefa de dados
Excluindo uma tarefa de espelhamento de dados
Ao excluir uma tarefa de espelhamento, os esquemas internos e as exibições criadas pela tarefa de espelhamento são descartados. Esquemas externos e tabelas no Redshift não são descartados. Se uma tabela for excluída do AWS Glue, por exemplo, quando um usuário descarta o conjunto de dados no armazenamento ou exclui toda a tarefa de armazenamento, a alteração é automaticamente refletida no esquema externo do Redshift. A tabela é removida e não precisa ser descartada separadamente. É recomendável excluir o esquema externo inteiramente se não estiver mais em uso.
Para excluir uma tarefa de espelhamento de dados, faça o seguinte
-
Na tarefa de espelhamento de dados que você deseja excluir, clique no menu
 Mais ações na tarefa e selecione Excluir.
Mais ações na tarefa e selecione Excluir. -
Na caixa de diálogo de confirmação, clique em Excluir.