
チュートリアル - 初心者向けのテーブル レシピ
このチュートリアルでは、テーブル レシピを作成する際に必要となる手順や、利用できるさまざまな機能に慣れるための、基本的なデータ準備のユースケースについて紹介します。付属のデータセットを使用すると、このチュートリアルのすべてのステップを再現できます。
このシナリオでは、ペットフードのオンライン ストアの販売データを見ていると想定します。データ サンプルには、世界中の顧客に関する情報 (名前、注文日、出身国、年齢層など) が含まれています。ここでは、フランスの顧客に焦点を当てたデータを準備するとします。具体的には、わずかな書式変更を行い、注文日を調整し、特定の年齢層に属するフランスの顧客データを分離し、最終的には分析アプリケーションのソースとして使用できる新しいファイルにデータをエクスポートします。
前提条件
このアーカイブをダウンロードしてデスクトップに解凍します。
アーカイブには、チュートリアルを完了するために必要な orders_pet_food.csv データ ファイルが含まれています。
ソース ファイルをカタログに追加する
テーブル レシピの作成を開始する前に、パッケージのファイルが分析プラットフォームで使用可能になっている必要があります。ソース データをカタログに追加するには、次を実行します。
-
Launcher メニューから、 [分析] > [カタログ] を選択します。
-
右上の [新規作成] をクリックし、 [データセット] を選択します。
-
開いたウィンドウで、 [データ ファイルをアップロード] をクリックします。
-
チュートリアル ファイルをデスクトップから [ファイルを追加] ウィンドウの専用領域にドラッグ アンド ドロップするか、 [参照] をクリックして保存場所から選択します。
-
[Upload] (アップロード)をクリックします。
テーブル レシピを作成してソースを選択する
ソースが設定されたので、テーブル レシピの作成を開始できます。
-
Launcher メニューから、 [分析] > [データの準備] を選択します。
-
[テーブル レシピ] タイルをクリックするか、 [新規作成] > [テーブル レシピ] をクリックします。
-
[新しいテーブル レシピを作成] ウィンドウで、テーブル レシピの情報を次のように設定し、 [作成] をクリックします。
-
[名前]: テーブル レシピのチュートリアル。
-
[スペース] は 個人。
-
[説明]: フランスの顧客に焦点を当てた販売データを準備するためのテーブル レシピ。
-
[タグ] は チュートリアル。
空のテーブル レシピが開きますが、何かを実行する前に、 [データ カタログ] からソース ファイルを選択するように求められます。
-
-
フィルター検索を使用して、以前にアップロードした order_pet_food.csv データセットを見つけ、その名前の前のチェックボックスをオンにします。
-
[Next] (次へ)をクリックします。
-
概要内のデータセットとその項目を確認し、 [テーブル レシピにロード] をクリックします。
データセットのデータがテーブルとして表示され、項目が列として表示されます。データセットの内容を簡単に参照し、関数を使用してデータの準備を開始できます。
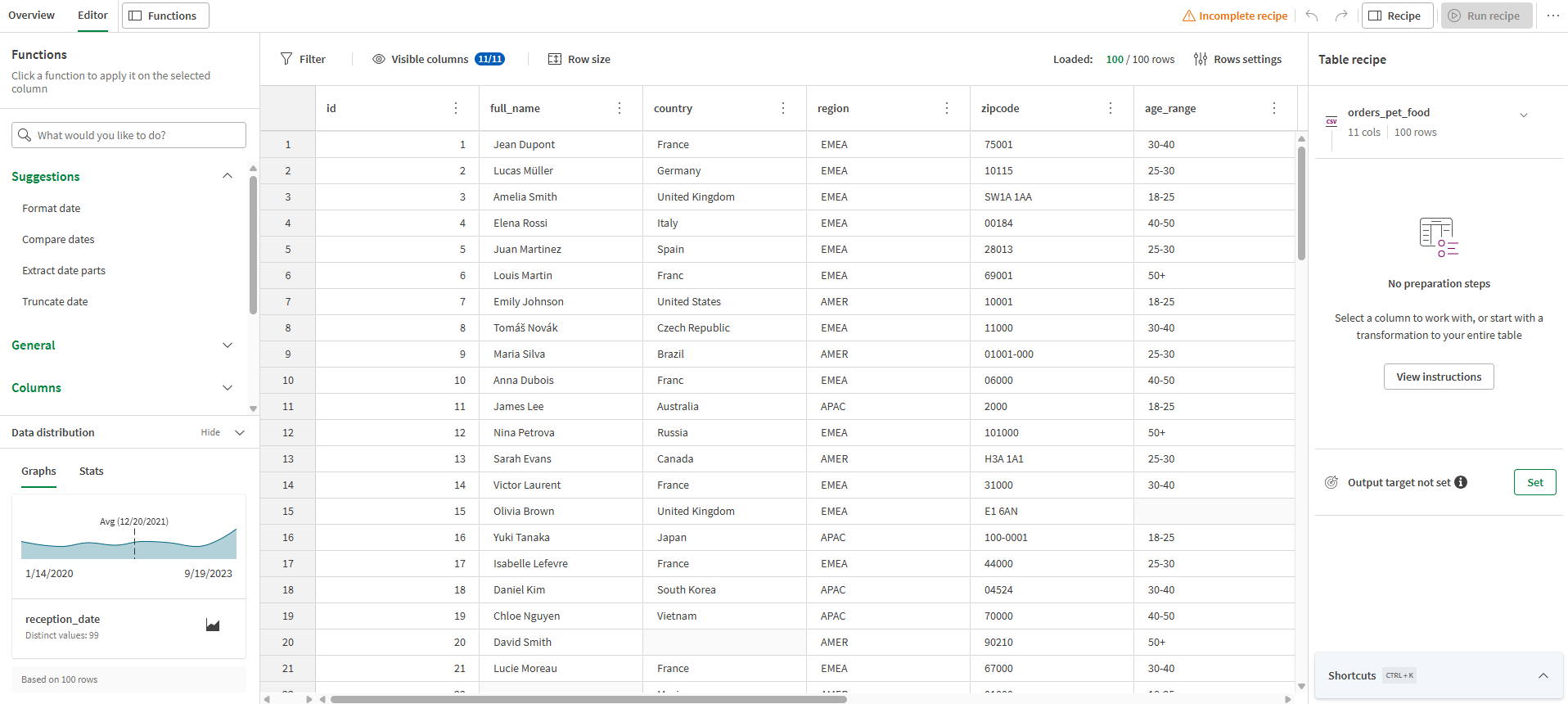
注文タイプのクリーニング
サンプルを見ると、注文したペットフードの種類をリストする [order] (注文) 列で「food」という単語が重複しており、不要であることに気付くでしょう。簡潔でわかりやすくするために、 [テキストの一部を削除] 関数を使用して、「food」という単語を削除します。

-
[order] 列のヘッダーをクリックしてその内容を選択します。
-
左側パネルの関数リストから、 [文字列] カテゴリの [テキストの一部を削除] 関数を選択します。
関数の構成フォームが右側のパネルに開き、 [処理する列] 項目がすでに選択されています。
-
[演算子] ドロップ ダウン リストから [Contains] (含む) をクリックします。
-
[値] 項目に「Food」と入力します。
-
[適用] をクリックします。
列内のすべての場所から「Food」という単語が削除され、注文タイプが見やすくなりました。

この操作を完了すると、右側のパネルのレシピにステップがリストされていることがわかります。テーブル レシピとは、料理のレシピの手順のように、データに適用される準備手順の一覧を意味します。ステップをクリックすると、適用された構成を確認したり、編集したりすることもできます。

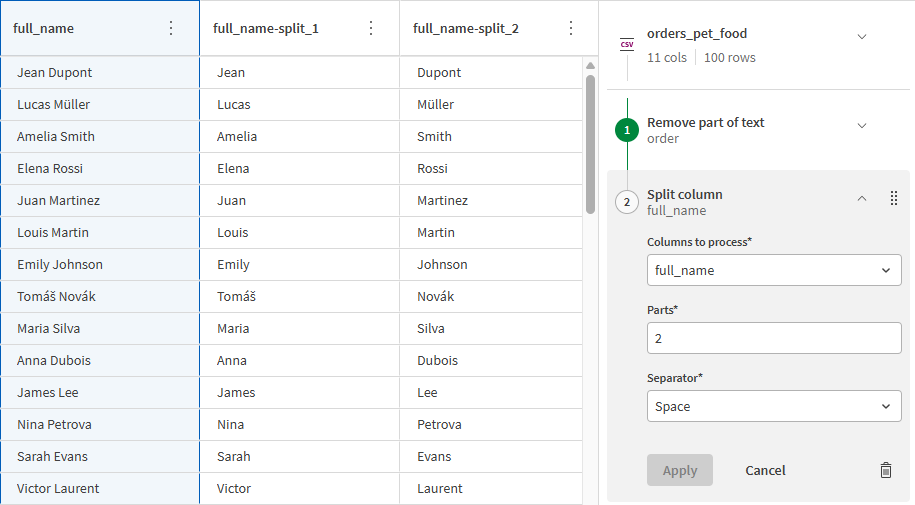
顧客名を 2 つの列に分割する
現在、顧客の名と姓は 1 つの列に含まれています。情報をより適切に分けるために、レシピの次のステップとして、 [列を分割] 関数を使用して名前を 2 つの列に分割します。

-
full_name 列のヘッダーをクリックしてその内容を選択します。
-
左側パネルの関数リストから、 [文字列] カテゴリの [列を分割] 関数を選択します。
-
[部分] 項目に「2」と入力し、 [区切り] ドロップダウン リストから [スペース] を選択します。
-
[適用] をクリックします。
2 つの新しい列が作成され、各列にはフル ネームの一部のみが含まれます。2 つの新しい列には自動的に生成された名前がありますが、わかりやすさと一貫性のために名前を変更します。
-
full_name-split_1 列を選択し、関数リストから [列名を変更] 関数を選択します。
-
[新しい列名] 項目に 「first_name」と入力し、 [適用] をクリックします。
別の方法を使用して、列メニューから直接 2 番目の列の名前を変更することもできます。どちらの場合も、レシピのステップが作成されます。
-
full_name-split_2 列のヘッダーで、
 をクリックして列メニューを表示し、 [列名を変更] を選択します。
をクリックして列メニューを表示し、 [列名を変更] を選択します。
-
[新しい列名] 項目に 「last_name」と入力し、 [適用] をクリックします。
これで、名と姓を含む 2 つの見やすい列が作成されました。最初の full_name 列は不要になったので、削除できます。
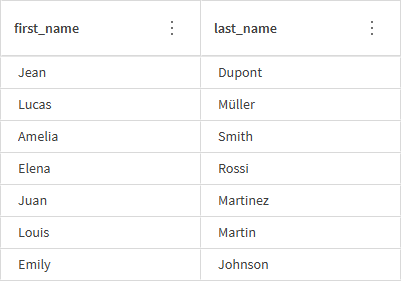
-
full_name 列のヘッダーで、
 をクリックして列メニューを表示し、 [列を削除] を選択して [適用] をクリックします。
をクリックして列メニューを表示し、 [列を削除] を選択して [適用] をクリックします。
日付をフォーマットする
テーブル レシピには、日付を操作するための関数も多数用意されています。データセットには、顧客が注文した日付、注文が発送された日付、顧客が注文を受け取った日付を追跡するための日付を含む 3 つの列があります。このデータをさらに活用する前に、最初にデータを変換してフォーマットし、使用できるようにする必要があります。このチュートリアルの目的はフランスの顧客に焦点を当てることなので、現在 YYYY-MM-DD 形式になっている日付にフランスの日付形式を適用します。
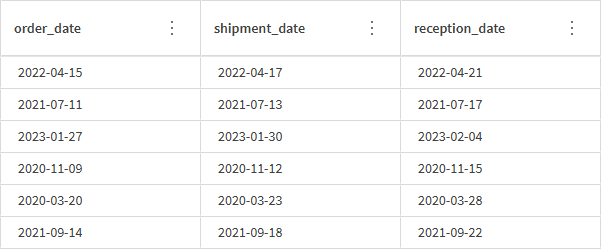
-
order_date 列を選択し、Shift キーを押しながら、reception_date 列のヘッダーをクリックします。
shipment_date 列を含む 3 つの列が選択されます。Ctrl + クリックのショートカットを使用して複数の列を選択することもできます。
-
関数リストから、 [日付] カテゴリの [日付に変換] 関数を選択します。
-
[入力形式] ドロップ ダウン リストで [自動] を選択し、 [適用] をクリックします。
この関数の目的は、テーブルのデータをシステム内で date として適切に解釈されるように変換することです。これにより、日付に基づいてさらに多くの操作を実行できるようになります。この場合、これら 3 つの列の日付形式を安全に変更できます。
-
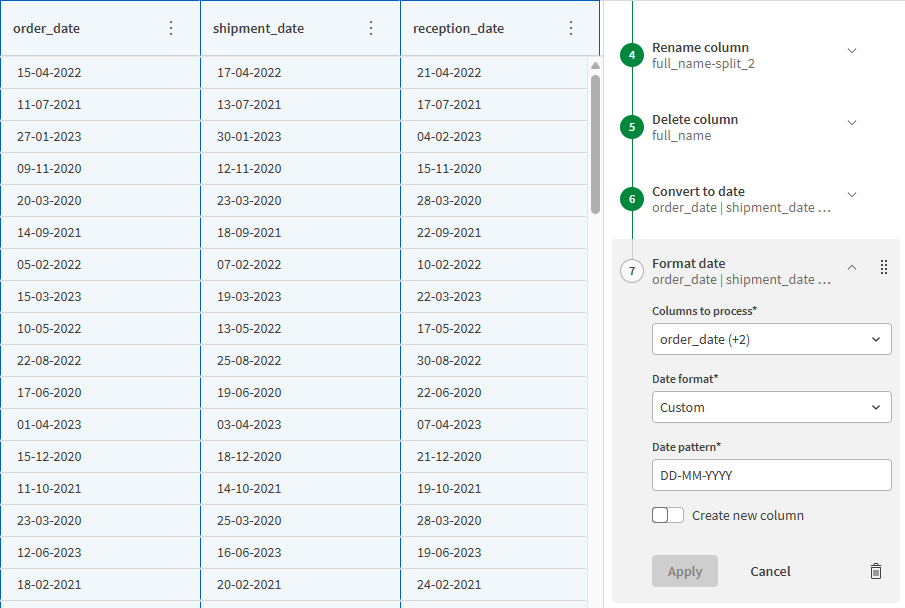
order_date 列を選択し、関数リストの [提案] から [日付の書式設定] 関数を選択します。
現在選択されている列のタイプに応じて、関連する関数が関数リストに動的に提案されます。検索フィールドを使用して、関数の名前または関連キーワードで関数を検索することもできます。
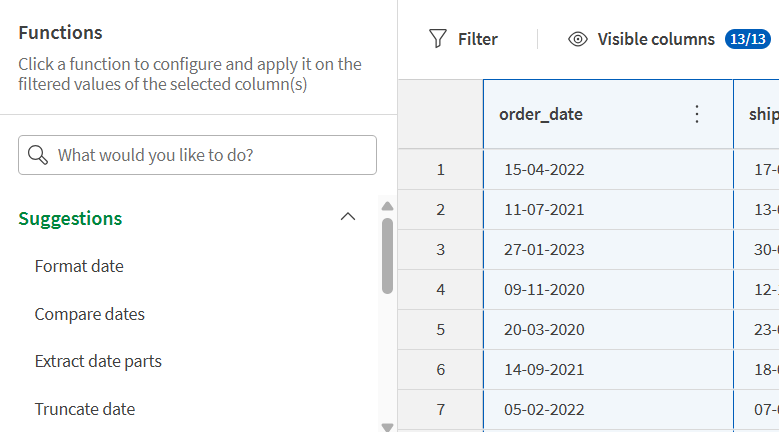
これまで関数を構成する際、 [処理する列] 項目は現在選択されている列に基づいてすでに入力されていました。次のステップでは、複数の列に関数を適用する別の方法を紹介します。
-
[処理する列] のドロップダウン リストを開き、order_date、shipment_date、reception_date のチェックボックスをオンにします。
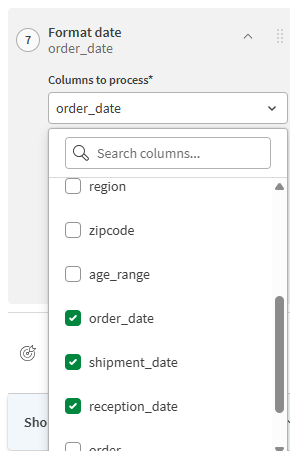
-
[日付の書式設定] ドロップ ダウン リストで [カスタム] を選択します。
-
[日付パターン] 項目には、フランスの公式書式である DD-MM-YYYY を入力します。
-
[適用] をクリックします。
3 つの列すべてが適切な形式になり、対象のユーザーにとって読みやすくなりました。
注文処理時間を計算する
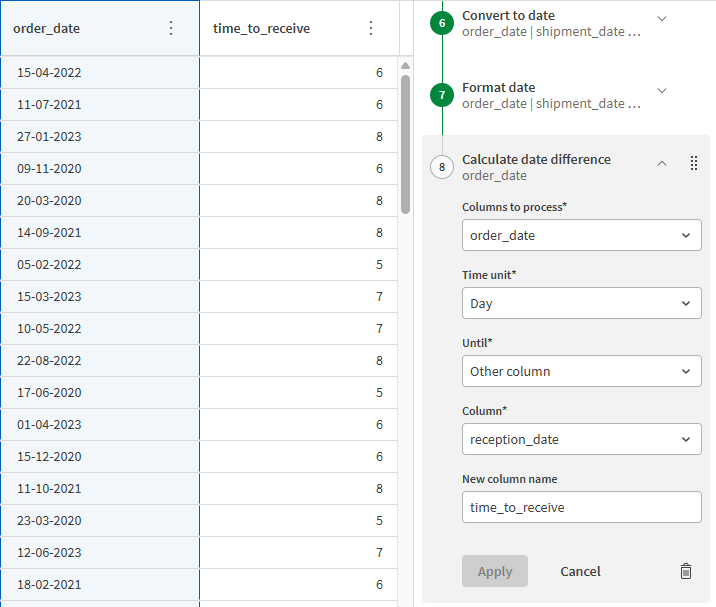
日付列が適切にフォーマットされたので、 [日付の差を計算] 関数を使用して、顧客が注文してから商品を受け取るまでに必要な日数を計算します。
-
[order_date] 列を選択します。
-
左側のパネルの関数リストから、 [日付] カテゴリの [日付の差を計算] 関数を選択します。
-
時間単位のドロップ ダウン リストから [日] を選択します。
-
[Until] (期限) ドロップ ダウン リストから [他の列] を選択します。
この関数を使用して特定の日付との時間差を計算することもできますが、この場合は 2 つの列を比較します。
-
[列] のドロップ ダウン リストから、reception_date を選択します。
-
[新しい列名] 項目に「time_to_receive」と入力します。
-
[適用] をクリックします。
order_date 列の右側に新しい列が作成され、そこには注文日から受取日までの日数が含まれます。データセットをすっきりと見やすく保つために、新しい time_to_receive 列を 3 つの日付列の右側に移動します。
-
列のヘッダーを reception_date 列の右側にドラッグ アンド ドロップして、time_to_receive 列を移動します。

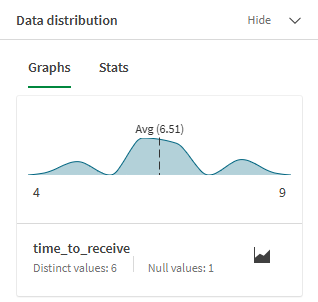
テーブル レシピでは、プロファイリング機能を利用して、現在のデータに関する情報を得ることもできます。たとえば、time_to_receive 列が選択されているときに、左下の [データ分布] パネルに役立つ情報が表示されます。列の数値のグラフが表示され、顧客が注文を受け取るまでの平均日数は 6 ~ 7 日であることがわかります。
国のクイック フィルターを追加する
フランスの場合のみ、国名を大文字にするとします。まず、country 列にクイック フィルターを適用し、次に一致する行にのみ関数を適用します。
-
country 列で、値 France の出現箇所の 1 つを右クリックし、開いたメニューから [この値の行をフィルタリング] を選択します。

上記のデータを見ると、is equal to 演算子を使用してフィルターが正しく適用され、値 France を含む行のみが表示されていることを確認できます。

-
左側パネルの関数リストから、 [文字列] カテゴリの [大文字に変換] 関数を選択し、 [適用] をクリックします。
ステップの概要に示されているように、関数はフィルターされた行にのみ適用されました。値が大文字になったため、元の大文字と小文字に基づくフィルターに一致しなくなり、この時点でグリッドが空になっているのは正常です。

次に進む前に、フィルターをクリアします。
-
フィルターを削除するには、フィルター内の十字を直接クリックするか、 [すべてクリア] オプションを使用します。
すべての行が再び表示されますが、France のみが大文字で表示されます。
レシピのステップを並び替える
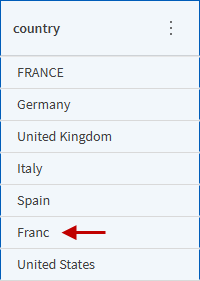
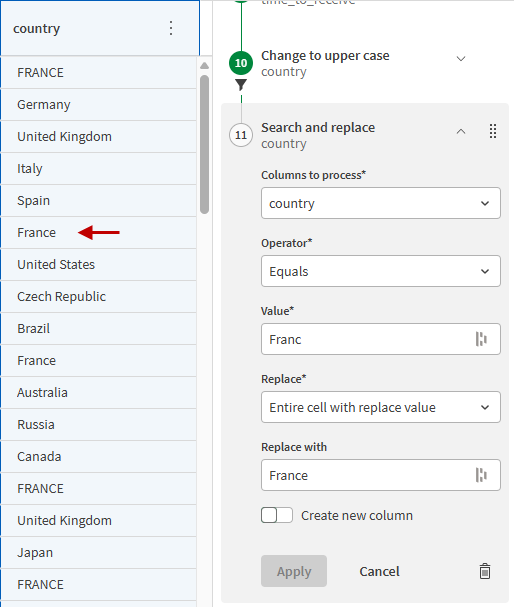
country 列をもう一度見てみると、France の出現箇所がすべて大文字に変更されたわけではないことがわかります。先ほど作成したフィルターは正確な France の値に基づいていたため、以下に示す Franc などの入力ミスは関数のスコープに含まれませんでした。
準備の次のステップとして、入力ミスを修正し、テーブル レシピのステップ並べ替え機能を使用して、新しいレシピのステップを大文字変換の前に移動します。テーブル レシピでは、ステップが後続のすべてのステップに影響するため、これを実行すると、すべての固定値にも [大文字に変換] 関数が自動的に再適用されます。
-
country 列を選択します。
-
左側パネルの関数リストから、 [文字列] カテゴリの [検索と置換] 関数を選択します。
-
[演算子] ドロップ ダウン リストから [Equals] (等しい) をクリックします。
-
[値] 項目に「Franc」と入力します。
-
[置換] ドロップ ダウン リストから、 [セル全体を置換値に] を選択します。
-
[置換] 項目に「France」と入力します。
-
[適用] をクリックします。
入力ミスは修正されましたが、大文字にはなっていません。以前と同じ関数を再度適用する代わりに、レシピ内のステップを並べ替えます。
-
右側のレシピパネルで、 [検索と置換] ステップを [大文字に変換] ステップの前にドラッグ アンド ドロップして移動します。
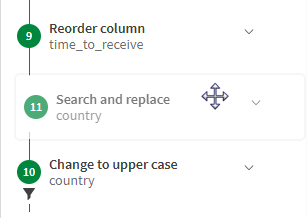
11 番目だった検索と置換の手順が 10 番目になり、今度は入力ミスを含むすべての France の出現が大文字で表示されます。

特定の顧客範囲を絞り込む
レシピはもう少しで完成します。データセットをクリーニングして改善した後、特定の年齢層のフランスの顧客に関連するデータのみを抽出します。そのためには、もう一度フィルターを作成しますが、今回は 2 つの条件を組み合わせて少し複雑にします。
-
テーブルの左上にある [フィルター] ボタンをクリックします。
-
最初のフィルター行で、列のドロップダウン リストから country を選択し、演算子として [is equal to] (等しい) を選択し、値として大文字で「FRANCE」と入力します。
-
[フィルターを追加] をクリックします。
2 行目が使用可能になります。
-
2 つ目のフィルター行で、列のドロップダウン リストから age_range を選択し、演算子として [is equal to] (等しい) を選択し、値として「18-25」と入力します。
フィルターを組み合わせる場合、フィルター間の演算子は AND です。
-
[適用] をクリックします。

テーブルの上には、現在 2 つのフィルターが適用されており、一致する行のみがテーブルに表示されていることがわかります。レシピの最後のステップでは、データセットから一致しない行をすべて削除し、18 歳から 25 歳までのフランス人の顧客に関するデータのみを保持します。

-
左パネルの関数リストから、 [一般] カテゴリの [フィルタリング済みの行を保持] 関数を選択し、 [適用] をクリックします。
これで、テーブル レシピが完了しました。データの範囲とサイズは縮小されますが、見やすくなり、特定のユーザーが対象とされています。さらに、顧客が注文を受け取るまでに必要な時間に関する情報も得られました。

ターゲットの設定とレシピの実行
これでデータの準備が整い、アプリケーションなどで使用する準備が整いました。あとは、結果のデータをどのように実行し、エクスポートするかを構成するだけです。テーブル レシピの結果は、さまざまなファイル形式でカタログに直接出力できるため、Qlik Cloud エコシステムで簡単に再利用できます。このシナリオでは、準備したデータを実行し、.qvd ファイルとしてエクスポートします。
-
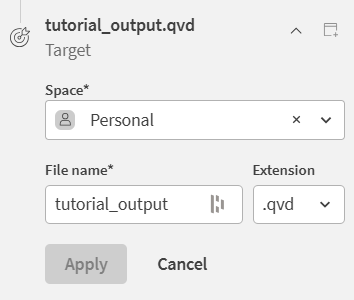
テーブル レシピ パネルのターゲット セクションで、レシピのステップの下にある、 [設定] をクリックします。
-
[スペース] ドロップダウン リストで、 [個人] を選択します。
-
[ファイル名] フィールドに「tutorial_output」と入力します。
-
[拡張] ドロップダウンリストで、 [.qvd] を選択します。
-
[適用] をクリックします。
ヘッダー バーのステータスに示されているように、テーブル レシピが完了し、有効になりました。
-
ウィンドウの右上にある [レシピを実行] ボタンをクリックします。
実行の進行状況を示すモーダルが開きます。
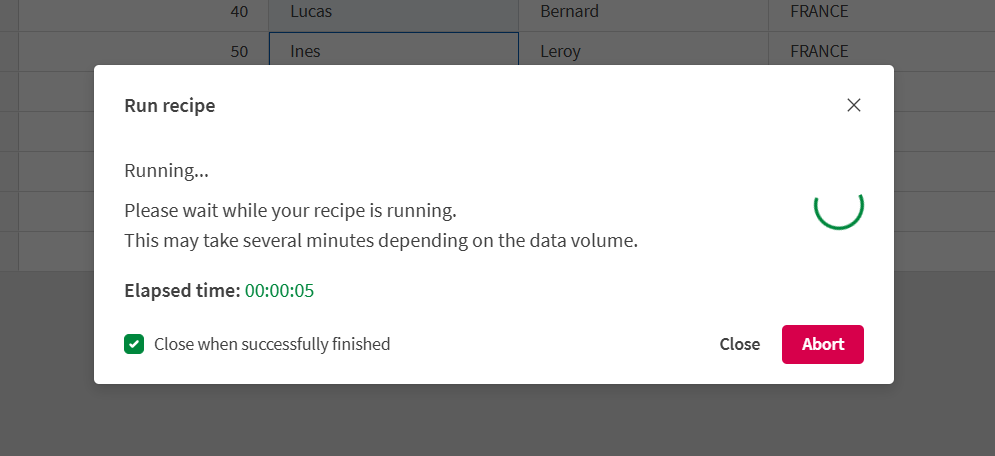
しばらくするとウィンドウが閉じ、実行が成功したかどうかを知らせる通知が表示されます。テーブル レシピの出力は、カタログまたはテーブル レシピの [概要] パネルの [出力] セクションで確認できます。
すべての実行のステータスは、 [実行履歴] セクションにも表示されます。
次のステップ
ソース データをカタログにインポートし、データをフィルター処理して改善するためのシンプルなテーブル レシピを構築し、準備の結果をすぐに使用できるファイルとしてエクスポートする方法を学習しました。
独自のユース ケースにテーブル レシピを使用するさまざまな方法については、テーブル レシピの関数 の完全なリストを参照してください。
準備したデータを分析アプリケーションで使用する方法については、「分析の作成とデータの視覚化」を参照してください。