-
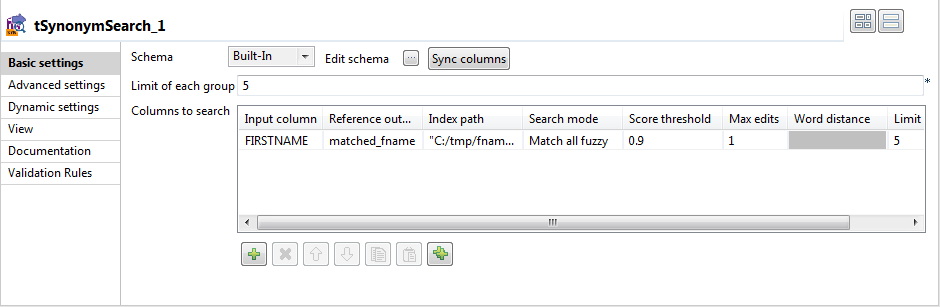
Dans la colonne Input column, sélectionnez FIRSTNAME dans la liste des colonnes d'entrée.
-
Dans la colonne Reference output column, sélectionnez matched_fname dans la liste des colonnes de sortie.
-
Dans la colonne Index path, saisissez entre guillemets doubles le chemin d'accès à l'index de synonymes à utiliser.
Lorsque vous utilisez le mode Spark
Local, utilisez un chemin vers un dossier local :
- Apache Spark 3.1 et versions précédentes : prefix://file path ou file:///file path.
- Apache Spark 3.2 et supérieures : file:///file path.
-
Dans la colonne Search mode, sélectionnez Match all fuzzy. Cela va mettre en correspondance chaque mot de la chaîne de caractères d'entrée par rapport au mot similaire de la chaîne de caractères de l'index.
-
Dans la colonne Score threshold, saisissez 0.9 pour filtrer les résultats et lister uniquement les termes ayant une haute similarité.
-
Dans la colonne Max edits, sélectionnez 1 comme distance de modification autorisée à utiliser.
Avec une distance maximale de modification de 1, vous pouvez effectuer une seule insertion, suppression ou substitution. Tout terme à l'intérieur de cette distance depuis les données d'entrée est mis en correspondance.
-
Laissez la colonne Word distance telle qu'elle est pour le mode Match partial.
-
Dans la colonne Limit, laissez la valeur par défaut, 5.