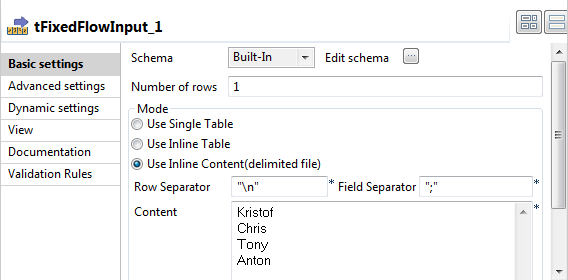
-
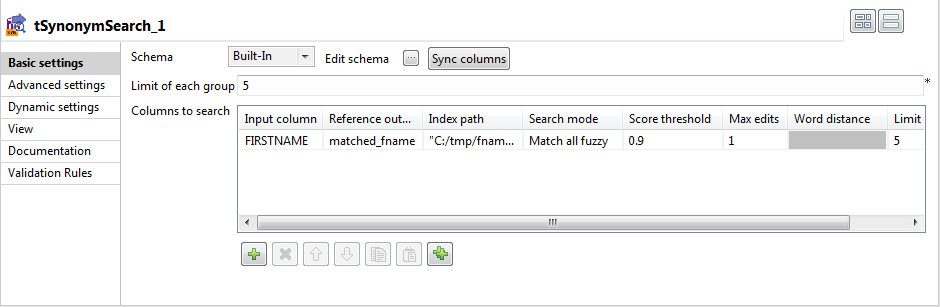
[Input column] (入力カラム)カラムで、入力カラムのリストからFIRSTNAMEを選択します。
-
[Reference output column] (出力カラムの参照)カラムで、出力カラムのリストからmatched_fnameを選択します。
-
[Index path] (インデックスパス)カラムに、使用するシノニムインデックスへのパスを二重引用符で囲んで入力します。
Sparkの
[Local] (ローカル)モードを使う場合は、次のようにローカルフォルダーへのパスを使用します。
- Apache Spark 3.1以前のバージョンでは、prefix://file pathまたはfile:///file pathとなります。
- Apache Spark 3.2以降のバージョンでは、file:///file pathとなります。
-
[Search mode] (検索モード)カラムで[Match all fuzzy] (すべてのファジーを一致)を選択します。これにより、入力文字列の各語がインデックス文字列の類似する語と一致します。
-
[Score threshold] (スコアしきい値)カラムに0.9と入力し、結果をフィルタリングして、類似性の高い用語のみをリスト表示します。
-
[Max edits] (最大編集)カラムで、使用が許可される編集距離に1を選択します。
最大編集距離を1にすると、挿入、削除、置換を1回だけ行うことができます。入力データからその編集距離内にあるすべての用語が一致します。
-
[Word distance] (単語距離)カラムは、Match partialモードの場合のみそのままにしておきます。
-
[Limit] (制限)カラムで、デフォルト値5をそのままにしておきます。