
Zelfstudie - Gegevensstroom voor beginners
Deze zelfstudie introduceert een basisgebruikssituatie voor gegevensvoorbereiding om u meer vertrouwd te maken met de verschillende stappen die nodig zijn voor het bouwen van een gegevensstroom, en de verschillende mogelijkheden die geboden worden. Met het bijgevoegde pakket met een paar gegevensverzamelingen kunt u alle stappen van deze zelfstudie reproduceren.
Dit scenario richt zich op een voorbeeld van verkoopgegevens met klanten van over de hele wereld, en informatie over hun namen, besteldata en -status, land van herkomst, staten, adressen, telefoonnummers, enz. Laten we zeggen dat u de gegevens zo wilt voorbereiden dat ze zich richten op de klanten uit de Verenigde Staten. U zult alle gegevens over klanten in de VS isoleren, ontbrekende informatie over landen van herkomst toevoegen, een kleine wijziging in de opmaak aanbrengen en de gegevens exporteren naar een nieuw bestand dat u kunt gebruiken als gegevensbron voor bijvoorbeeld een analyse-applicatie.
Vereisten
Download dit pakket en pak het uit op uw bureaublad:
Zelfstudie Gegevensstroom voor beginners
Het pakket bevat de volgende gegevensbestanden die u nodig hebt om de zelfstudie af te ronden:
-
sales_data_sample.xlsx
-
states.xlsx
De bronbestanden aan uw catalogus toevoegen
Voordat u begint met het maken van de gegevensstroom, moeten de twee bestanden uit het pakket beschikbaar zijn in het analyseplatform. Om de gegevensbron aan uw catalogus toe te voegen:
-
Selecteer Analyses > Catalogus in het startmenu.
-
Klik op de Nieuwe maken in de rechterbovenhoek en selecteer Gegevensverzameling.
-
Klik op Gegevenbestand uploaden in het venster dat wordt geopend.
-
Sleep de zelfstudiebestanden van uw bureaublad naar het daarvoor bestemde gebied in het venster Bestand toevoegen of klik op Bladeren om ze vanuit hun locatie te selecteren.
-
Klik op Uploaden.
De gegevensstroom maken en een bron toevoegen
Nu alle onderdelen klaar zijn, kunt u beginnen met het maken van de gegevensstroom, te beginnen bij de bron.
-
Selecteer Analyses > Gegevens voorbereiden in het startmenu.
-
Klik op de tegel Gegevensstroom of klik op Nieuwe maken > Gegevensstroom.
-
Stel in het venster Een nieuwe gegevensstroom maken de informatie van uw gegevensstroom als volgt in en klik op Maken:
-
Zelfstudie Gegevensstroom als Naam.
-
Persoonlijk als Ruimte.
-
Gegevensstroom voor het voorbereiden van verkoopgegevens gericht op klanten in de VS als Beschrijving.
-
Zelfstudie als Label.
Uw lege gegevensstroom wordt geopend.

-
-
Klik op Catalogus doorzoeken op het lege canvas om gegevensverzamelingen te bekijken die aan uw catalogus zijn toegevoegd.
-
Gebruik de gefilterde zoekfunctie om de eerder geüploade gegevensverzamelingen sales_data_sample.xlsx en states.xlsx te vinden en schakel de selectievakjes voor hun namen in.
-
Klik op Volgende.
-
Bekijk de gegevensverzamelingen en hun velden in het overzicht en klik op Laden in gegevensstroom.
Beide brongegevensverzamelingen worden toegevoegd aan het canvas en u kunt beginnen met het voorbereiden van de gegevens met behulp van processoren. sales_data_sample.xlsx is de belangrijkste gegevensverzameling waarmee u zult werken, terwijl states.xlsx gebruikt zal worden als aanvullende gegevens.

De gegevens filteren op klanten uit de VS
U kunt nu beginnen met het voorbereiden van de gegevens met opeenvolgende wijzigingen door middel van processoren. De eerste stap is om het bereik van de gegevensverzameling te verkleinen en ons alleen te richten op klanten in de VS. Om dit te doen, gebruikt u de Filter-processor om alleen de rijen te selecteren die de waarde VS in het veld LAND hebben.
-
Klik op het actiemenu (
 ) van de bron sales_data_sample op het canvas.
) van de bron sales_data_sample op het canvas. -
Selecteer in het menu dat verschijnt Processor toevoegen > Filter.
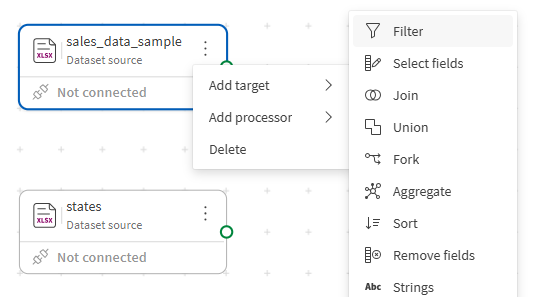
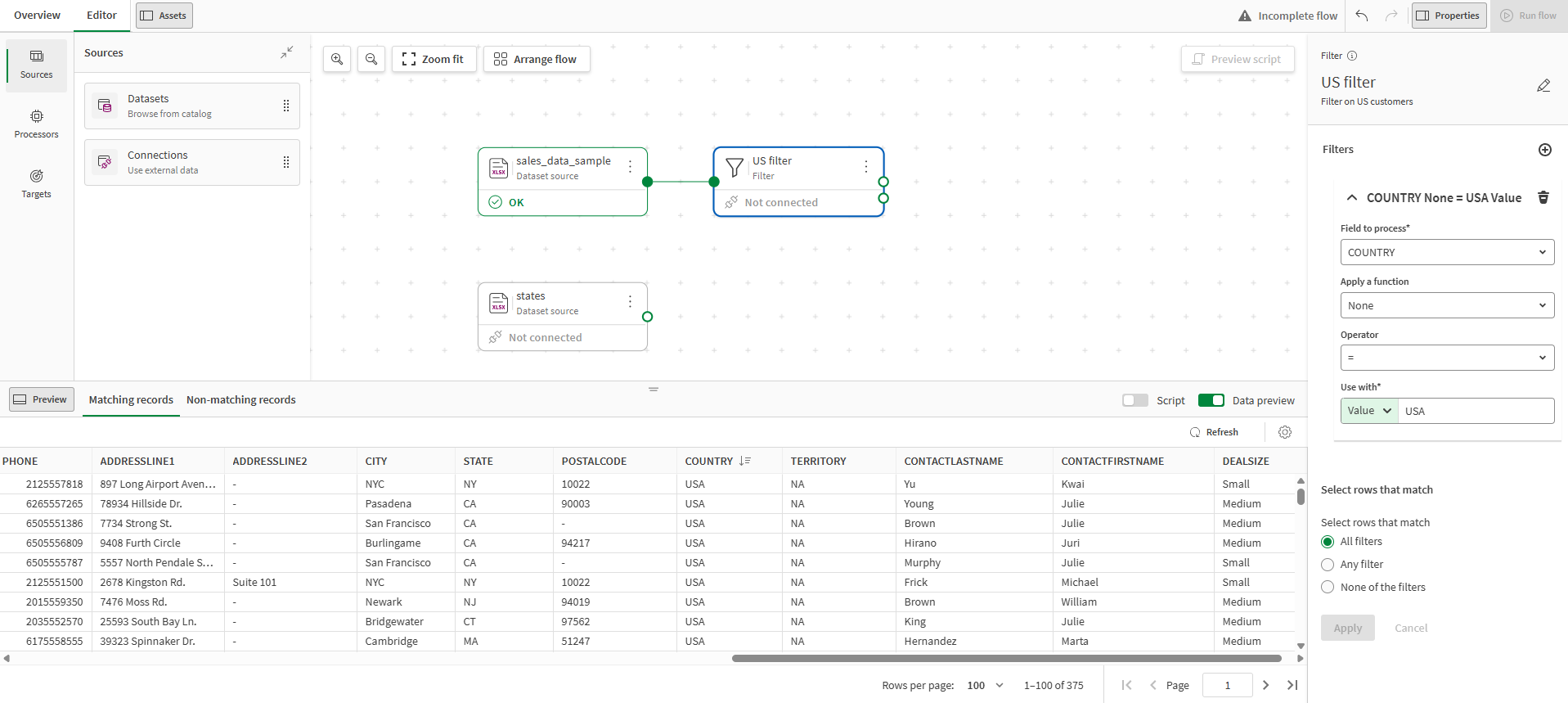
De Filter-processor wordt op het canvas geplaatst en automatisch verbonden met de bron.
InformatieU kunt ook handmatig processoren slepen en neerzetten vanuit het linkervenster Processoren en knooppunten handmatig verbinden. -
Als het nog niet geopend is, klikt u op Eigenschappen rechtsboven op het canvas om het Venster Processoreigenschappen te openen, waar u uw processoren kunt configureren en het gegevensvoorbeeld en script kunt bekijken.
-
Klik in het venster Eigenschappen op het pictogram Bewerken (
 ) naast de naam van de processor om de processor een betekenisvollere naam te geven, zoals VS filter, en een korte beschrijving zoals Filter op Amerikaanse klanten bijvoorbeeld.
) naast de naam van de processor om de processor een betekenisvollere naam te geven, zoals VS filter, en een korte beschrijving zoals Filter op Amerikaanse klanten bijvoorbeeld. -
Selecteer LAND in de vervolgkeuzelijst Te verwerken veld.
-
Selecteer = in de vervolgkeuzelijst Operator.
-
In het veld Gebruiken met selecteert uWaarde en voert u VS in.
-
Selecteer Alle filters in de lijst Selecteer rijen die overeenkomen.
Deze parameters zijn nuttiger bij het combineren van meer dan één filter.
-
Klik op Toepassen.
De processorconfiguratie is geldig, maar er wordt nog steeds het bericht Niet verbonden weergegeven omdat de processor nog geen uitvoerstroom heeft.
-
Klik op Gegevens weergeven in het onderste venster.
Als u naar het voorbeeld kijkt, kunt u zien dat alleen de rijen met VS als land in dit stadium zijn bewaard en in de uitvoerstroom zullen worden doorgegeven. Uw gegevensstroom zou er tot nu toe als volgt uit moeten zien:
Namen van staten uit een andere gegevensverzameling toevoegen
In het geval van de resterende in de VS gevestigde klanten bevat het veld STAAT de staat van herkomst, maar als een tweelettercode. U wilt deze informatie gemakkelijker leesbaar maken, met idealiter de volledige naam van de staat.
De gegevensverzameling states.xlsx die u eerder als bron hebt geïmporteerd, bevat een verwijzing naar alle Amerikaanse staten met de tweelettercodes en de bijbehorende volledige namen. U zult een join uitvoeren tussen deze twee gegevensverzamelingen om de namen van de staten op te halen en uw hoofdstroom aan te vullen.

Om de samenvoeging uit te voeren:
-
Klik op het actiemenu (
) van de Filter-processor en selecteer Processor toevoegen aan overeenkomende vertakking > Samenvoegen. -
Hernoem de processor als Volledige staatnamen met het pictogram Bewerken (
) in het eigenschappenvenster. -
Verbind de Staten-bron met het onderste ankerpunt van de Join-processor. Maak een koppeling door op de punt rechts van het bronknooppunt te klikken, deze vast te houden en de koppeling naar de onderste punt links van het processorknooppunt te slepen.

-
Selecteer in de vervolgkeuzelijst Type samenvoeging de optie Left outer join.
-
Selecteer het veld STATE in de vervolgkeuzelijst Linker sleutel.
-
Selecteer het veld Afkorting in de vervolgkeuzelijst Rechter sleutel.
De twee geselecteerde kolommen bevatten de gemeenschappelijke informatie en maken een koppeling tussen de twee invoerstromen mogelijk. Met een left outer join worden alleen de extra velden uit de tweede gegevensverzameling toegevoegd aan de hoofdstroom.
-
Klik op Toepassen.

Er is een nieuw veld State toegevoegd aan het einde van de gegevensverzameling, met de volledige naam van de staat voor elke klant.
Velden hernoemen en verplaatsen
Er zijn nu verschillende problemen met de naamgeving en opmaak van uw kolommen. STATE en State lijken te veel op elkaar en zijn verwarrend, en de twee velden liggen te ver uit elkaar. U kunt de Select fields-processor gebruiken om uw velden te reorganiseren en hernoemen om de consistentie en uniformiteit van uw gegevens te verbeteren.
-
Klik op het actiemenu (
) van de Join-processor en selecteer Processor toevoegen > Velden selecteren. -
Verbind de Join-processor met de Select fields-processor.

-
Hernoem de processor als Staatvelden opnieuw rangschikken met het pictogram Bewerken (
) in het eigenschappenvenster. -
Klik op het selectievakje Alles selecteren om alle velden in uw stroom te behouden.
-
Plaats uw muis op de velden die u wilt hernoemen en klik op het pictogram
Bewerken om de twee veldnamen als volgt te bewerken:-
STATE als STATECODE
-
State als STATENAME
-
-
Gebruik het = pictogram om de nieuwe STATENAME kolom naast STATECODE te slepen en neer te zetten.
-
Klik op Toepassen.
U hebt uw velden opnieuw ingedeeld en de gegevensstroom ziet er als volgt uit:

Namen van klanten in hoofdletters zetten
Om de achternamen van de klanten te benadrukken en ze gemakkelijker te kunnen onderscheiden van de voornamen, gebruikt u een eenvoudige opmaakfunctie van de Strings-processor om achternamen in hoofdletters te zetten.
-
Klik op het actiemenu (
) van de Select Fields-processor en selecteer Processor toevoegen > Tekenreeksen. -
Verbind de Select Fields-processor met de Strings-processor.

-
Hernoem de processor als Hoofdletters met het pictogram Bewerken (
) in het eigenschappenvenster. -
In de vervolgkeuzelijst Functienaamselecteert u Wijzigen in hoofdletters.
-
Selecteer CONTACTLASTNAME in de vervolgkeuzelijst Te verwerken velden.
-
Klik op Toepassen.

Een doel toevoegen en de gegevensstroom uitvoeren
De belangrijkste gegevensvoorbereidingsstappen zijn uitgevoerd en u kunt nu de gegevensstroom afronden door te configureren hoe de resulterende gegevens moeten worden geëxporteerd. In dit scenario exporteert u de voorbereide gegevens als een .qvd-bestand dat direct in uw catalogus is opgeslagen, waardoor het handig is om later bijvoorbeeld in een analyse-applicatie te gebruiken.
-
Klik op het actiemenu (
) van de Strings-processor en selecteer Doel toevoegen > Gegevensbestanden. -
Verbind de Strings-processor met Doel Gegevensbestanden.

-
Hernoem de processor als QVD-‑doel met het pictogram Bewerken (
) in het eigenschappenvenster. -
Selecteer Persoonlijk in de vervolgkeuzelijst Ruimte.
-
Voer in het veld Bestandsnaamtutorial_output in.
-
Selecteer .qvd in de vervolgkeuzelijst Uitbreiding.
-
Klik op Toepassen.
Uw gegevensstroom is nu voltooid en geldig, zoals te zien is aan de status in de kopbalk en de groene vinkjes onder elk bron, processor en het doelknooppunt.

-
Klik op de knop Stroom uitvoeren rechtsboven in het venster.
Er wordt een venster geopend om de voortgang van de uitvoering weer te geven.

Na enige tijd sluit het venster en wordt er een melding geopend om u te vertellen of de uitvoering geslaagd is of niet. De uitvoer van de gegevensstroom is nu te vinden in uw catalogus, of in de sectie Uitvoer van het venster Overzicht gegevensstroom.
Wat is de volgende stap
U hebt geleerd hoe u gegevensbronnen in uw catalogus importeert, een eenvoudige gegevensstroom opbouwt om uw gegevens te filteren en te verbeteren, en het resultaat van uw gegevensvoorbereiding exporteert als een gebruiksklaar bestand.
Om meer te weten te komen over de verschillende manieren waarop u een gegevensstroom voor uw eigen gebruiksscenario's kunt gebruiken, kunt u de volledige lijst van Processoren voor gegevensstroom en de functies die ze bieden bekijken.
Zie Analyses maken en gegevens visualiseren om te leren hoe u uw voorbereide gegevens in analytische toepassingen kunt gebruiken.