
データ パイプライン プロジェクトの作成と管理
データ パイプラインを作成して、データ タスクを使用してプロジェクト内ですべてのデータ統合を実行できます。オンボーディングでは、オンプレミスまたはクラウドのデータ ソースからプロジェクトにデータを移動し、すぐに使用できるデータ セットにデータを保存します。データウェアハウスや Qlik Open Lakehouse にデータを搭載することができます。
データをデータ ウェアハウスにオンボードする際、変換を実行してデータ マートを作成し、生成および変換されたデータ セットを活用することもできます。データ パイプラインはシンプルで線形にすることも、複数のデータ ソースを使用して多くの出力を生成する複雑なパイプラインにすることもできます。
すべてのデータ タスクは、それらが属するプロジェクトと同じスペースに作成されます。
また、系列を表示してデータとデータ変換を元のソースまで遡って追跡することや、データ タスク、データセット、項目の依存関係の将来を見据えたダウンストリーム ビューを示す影響分析を実行することもできます。詳細については、「データ統合 での系列および影響分析の操作」を参照してください。
データ ウェアハウスへのデータのオンボーディング
これには、ステージング エリアへのデータのランディングと、クラウド データ ウェアハウスへのデータセットの格納が含まれます。ランディングおよびストレージ データ タスクは、1 つのステップで作成されます。必要に応じて、ランディングとストレージを別々のタスクで実行することもできます。
Qlik Open Lakehouse へのデータのオンボーディング
Qlik Open Lakehouse パイプライン プロジェクトを作成し、サポートされているあらゆるデータ ソースから Iceberg オープン テーブル形式にデータをコピーします。テーブルは、ミラー データ タスクを使用することで、データを複製することなく、クラウド データ ウェアハウスの分析エンジンからアクセスしたり、クエリを実行したりできます。
データ プラットフォームに既存のデータを登録する
データ プラットフォームに既存のデータを登録し、データをキュレーションして変換し、データ マートを作成します。これにより、Qlik Talend Data Integration 以外のツール (Qlik Replicate または Stitch など) を使ってオンボーディングされたデータを使用できます。
データの変換
ルールとカスタム SQL に基づいて、オンボード データに再利用可能な行レベルの変換を作成します。これにより変換データ タスクが作成されます。
データ マートの作成と管理
データ マートを作成して、データ セットを活用します。これによりデータ マート データ タスクが作成されます。
ナレッジ マートの作成
ナレッジマートを作成し、構造化データと非構造化データをベクター データベースに埋め込んで保存します。この操作により、ナレッジ マート データ タスクが作成されます。
ターゲットとなるデータ プラットフォーム
プロジェクトは、すべての出力のターゲットとして使用されるデータ プラットフォームに関連付けられています。
サポートされているデータ プラットフォーム詳細については、「ターゲットへの接続の設定」を参照してください
プロジェクトの紹介ビデオ
プロジェクトの作成例
次の例では、オンボーディング データを実行し、データを変換してデータ マートを作成します。これにより、より多くのデータ ソースをオンボードし、より多くの変換を作成し、生成されたデータ タスクをデータ マートに追加することで拡張できるシンプルな線形データ パイプラインが作成されます。
プロジェクトの線形データ パイプラインの例

-
新しいプロジェクトを作成します。
[データ統合] > [パイプライン プロジェクト] で、 [新規作成] > [プロジェクト] をクリックします。
-
プロジェクトの名前と説明を入力します。
情報メモ後でプロジェクトのバージョン管理を有効にした場合、バージョン管理下にある間はプロジェクト名を変更できません。 -
プロジェクトを作成するスペースを選択します。すべてのデータ タスクは、それらが属するプロジェクトのスペースに作成されます。
- [ユース ケース] で [データ パイプライン] を選択します。
-
プロジェクトで使用するデータ プラットフォームを選択します。
-
プロジェクトで使用するクラウド データ ウェアハウスへの接続を選択します。これは、データ ファイルを配置し、データセットとビューを保存するために使用されます。接続をまだ準備していない場合は、 [新規作成] で作成します。
-
Google BigQuery、Databricks、または Microsoft Azure Synapse Analytics をデータ プラットフォームとして選択した場合は、ステージング エリアにも接続する必要があります。
-
Snowflake をデータ プラットフォームとして選択した場合は、クラウド ストレージへのデータ ランディングを選択できます。「レイクハウスへのデータのランディング」を参照してください。
-
データ プラットフォームとして Qlik Cloud を選択した場合:
データは、Qlik が管理するストレージまたは自身が管理する Amazon S3 バケットに保存できます。自身の Amazon S3 バケットを使用する場合は、そのバケットへの接続を選択する必要があります。
どちらの場合も、Amazon S3 ステージング エリアへの接続も選択する必要があります。前のステップで定義したものと同じバケットを使用する場合は、バケット内の別のフォルダーをステージングに使用していることを確認してください。
-
-
[作成] をクリックします。
プロジェクトが作成され、データ タスクを追加してデータ パイプラインを作成できます。
-
-
データをオンボードします
プロジェクトで、 [作成] をクリックし、 [データのオンボード] をクリックします。
詳細については、「データ ウェアハウスへのデータのオンボーディング」を参照してください。
これにより、ランディング データ タスクとストレージ データ タスクが作成されます。データのレプリケーションを開始するには、次のことが必要です。
-
ランディング データ タスクを準備して実行します。
詳細については、「データ ソースからのランディング データ」を参照してください。
-
ストレージ データ タスクを準備して実行します。
詳細については、「データセットの保管」を参照してください。
-
-
データの変換
ストレージ データ タスクが作成されたら、プロジェクトに戻ります。作成されたデータセットに対して変換を実行できるようになりました。
ストレージ データ タスクで [...] をクリックし、[データの変換] を選択して、このストレージ データ タスクに基づいて変換データ タスクを作成します。変換の手順については、「データの変換」 を参照してください。
-
データ マートの作成
ストレージ データ タスクまたは変換データ タスクに基づいてデータ マートを作成できます。
データ タスクの [...] をクリックし、[データ マートの作成] を選択して、データ マート データ タスクを作成します。データ マートの作成手順については、次を参照してください。
保存および変換されたデータセットとデータ マートの最初のフル ロードを実行したら、それらを分析アプリケーションなどで使用できます。分析アプリケーション作成の詳細については、「Data Integration で生成されたデータセットを使用して分析アプリケーションを作成する」 を参照してください。
また、より多くのデータ ソースをオンボードすることでデータ パイプラインを拡張し、それらを変換またはデータ マートで結合することもできます。
クロスプロジェクト パイプラインの構築
タスクが別のプロジェクトのタスクを消費できるような、クロスプロジェクト パイプラインを構築できます。構築することにより、複数の方法でセグメンテーションを実現できます。
-
組織単位ごとに個別のデータ移動パイプラインを作成し、単一のデータ マート パイプラインで出力を消費できます。
-
単一のデータ移動パイプラインを作成し、その出力を複数の変換パイプラインで消費できます。
変換タスクとデータ マート タスクは、別のプロジェクトにあるストレージ タスクと変換タスクを消費できます。
-
消費されるプロジェクトのスペースでは、少なくとも [消費可能] ロールを持っている必要があります。
-
両方のプロジェクトが同じデータ プラットフォーム上にある必要があります。
タスクのすべてのデータセットはダウンストリームのプロジェクトと共有されます。つまり、データセットの分離を実現するには、変換タスクを作成して、使用されるプロジェクト内のデータセットをフィルター処理する必要があります。
プロジェクト ビューでは、別のプロジェクトで消費されるタスクと、現在のプロジェクトで消費される他のプロジェクトのタスクを表示できます。現在のプロジェクト外のすべてのタスクはグレーで表示されます。依存関係は名前ではなく参照に応じて決まるため、参照を壊すことなくタスクの名前を変更できます。これは、消費されたタスクを削除し、同じ名前で新しいタスクを作成した場合でも、参照が壊れるという意味でもあります。
既存のデータを再利用するには、次のような方法があります。
-
新しいプロジェクトの作成
プロジェクトを作成したら、 [Use data from another project] (別のプロジェクトのデータを使用する) オプションを選択します。
別のパイプラインからオンボードされたデータを消費する変換またはデータ マートを作成できます。
-
変換タスクまたはデータ マート タスクでは、 [ソース データを選択] で別のプロジェクトからデータを選択できます。
ソース データを選択する際は、 [プロジェクト] を選択します。選択したプロジェクトがバージョン管理下にある場合は、 [ブランチ] を選択します。既定のブランチは main です。データ タスク リストが更新され、選択したブランチが反映されます。次に、 [データ タスク] を選択して、利用可能なデータセットを確認します。
このプロジェクトのタスクを消費する他のプロジェクトのタスクを表示するかどうかを選択できます。
-
[レイヤー] をクリックし、 [クロスプロジェクト出力] をオンまたはオフにします。
現在のプロジェクト外のすべてのタスクはグレーで表示されます。
バージョン管理の制限
クロスプロジェクト パイプラインは複数のプロジェクトに分割されるため、バージョン管理を使用する際に複雑さが増します。これらの例では、Project1 は Project2 によって消費されます。
クロス プロジェクト パイプラインの例

-
Project2 は、Project1 の特定のブランチを使用できます。変換タスクまたはデータ マート タスクで、 [ソースデータを選択] 内のブランチを選択します。既定のブランチは main です。参照されているプロジェクトがバージョン管理下にない場合、ブランチ セレクターは表示されず、Project2 はプロジェクトをそのまま使用します。
-
Project1 のブランチを作成することはできますが、ブランチされたバージョンには Project2 で消費されていることが表示されません。
-
Project2 をメインにマージすることはできますが、依存関係は残ります。
Project1 で選択されたブランチが後で削除された場合、参照先のタスクが削除された場合と同様に、参照が切断されます。参照されているタスクが選択されたブランチで異なる出力を持つ場合、その参照は、参照先のタスクの出力が変更された場合と同じように動作します。
ベスト プラクティス
-
消費されたプロジェクト内のタスクが少なくとも準備されていることを確認して、それらが有効であることを確認します。
-
テナント間でプロジェクトをエクスポートおよびインポートする予定の場合は、テナント内のスペースとプロジェクトの名前を同じにしておくと簡単です。名前が異なる場合は、プロジェクトをインポートするときにプロジェクトとタスクをマッピングする必要があります。
-
エクスポートとインポートを使用してデータ プラットフォームを変更する場合、依存関係を持つすべてのプロジェクトが同じプラットフォーム上にある必要があります。
安全かつ簡単にプラットフォームを変更するには、次の手順に従ってください。この例では、消費されるプロジェクトは Consumed と呼ばれ、Consumed から読み取るプロジェクトは Consumer と呼ばれます。
-
Consumed と Consumer をエクスポートします。
-
Consumed を Consumed_New にインポートし、新しいデータ プラットフォームに変更します。
-
Consumer を Consumer_New にインポートし、Consumed_New と同じデータ プラットフォームに変更し、ソース プロジェクト (Consumed) を Consumed_New に置き換えます。
-
データ パイプライン プロジェクトでの操作
プロジェクトでは、データ タスクで使用できるのと同じ操作を実行できます。同じ操作を実行できることにより、データ パイプラインで操作を調整できます。
-
スケジュールのオンとオフを切り替える
-
設計操作を実行する
-
データ タスクの実行を開始および停止する
-
データ タスクを削除する
[操作] をクリックして、進行中の操作のステータス、または最後に実行された操作を表示します。
[操作を停止] をクリックすると、進行中の操作を停止できます。進行中のデータ タスクは停止されませんが、開始していないタスクはキャンセルされます。
スケジュールのオンとオフを切り替える
プロジェクト レベルでデータ タスクのスケジュールをコントロールできます。
-
[...]、[スケジュール] の順番でクリックします。
すべてのデータ タスクまたは選択したタスクのスケジュールをオンまたはオフにできます。スケジュールが定義されているタスクのみが表示されます。
情報メモこのオプションは、Qlik Cloud をデータ プラットフォームとするプロジェクトでは使用できません。
個別のデータ タスクのスケジューリングの詳細については、次を参照してください。
設計操作を実行する
プロジェクト内のすべてのデータ タスク、または選択したタスクに対して、設計操作を実行できます。これにより、各タスクで個別に設計操作を実行する代わりに、プロジェクトでデータセット タスクをコントロールしやすくなります。
-
[Validate] (検証)
[検証] をクリックして、すべてのタスクまたは選択したタスクを検証します。最後の検証操作以降に変更されたデータ タスクが事前に選択されています。
データ タスクは、パイプライン順に検証されます。
-
準備
[準備] をクリックして、すべてのタスクまたは選択したタスクを準備します。最後の準備操作以降に変更されたデータ タスクが事前に選択されています。
データ プラットフォームでサポートされていない構造変更が必要なデータセットの再作成を選択できます。これによりデータを損失する恐れがあります。
-
再作成
[...]、 [テーブルを再作成] の順番でクリックして、すべてのタスクまたは選択したタスクのソースからデータセットを再作成します。
情報メモ個々のテーブルに問題がある場合は、最初にテーブルを再作成するのではなく、リロードしてみることをお勧めします。テーブルを再作成すると、過去のデータが失われる可能性があります。重大な変更があった場合は、データをリロードできるよう、再作成されたデータ タスクを使用するダウンストリームのデータ タスクを準備することも必要です。
データ タスクを実行する
タスクを個別に実行する代わりに、プロジェクト内のすべてのデータ タスクまたは選択したタスクに対して実行を開始できます。たとえば、すべてのタスクを時間ベースのスケジュールで実行できます。これにより、イベントベースのスケジュールでダウンストリームのタスクが開始されます。
-
実行
[実行] をクリックして、すべてのタスクまたは選択したタスクの実行を開始します。これにより、選択したすべてのタスクの実行が開始され、実行が開始されるとすぐに完了します。
実行の準備ができているすべてのタスクから選択できます。時間ベースのスケジュールを持つタスクと CDC を使用するタスクが事前に選択されています。イベントベースのスケジュールを持つタスクは、処理するデータがある場合に実行されるため、事前に選択されていません。
Qlik Cloud をデータ プラットフォームとするプロジェクトでは、すべてのランディング タスクとストレージ タスクが事前に選択されています。
情報メモすべてのデータ タスクは並行して実行されます。つまり、依存関係のチェックによって、一部のタスクの実行が妨げられる可能性があります。 -
停止
[停止] をクリックして、すべてのタスクまたは選択したタスクを停止します。
実行中のタスクから選択できます。
タスクを削除する
-
[削除] をクリックして、プロジェクト内のすべてのデータ タスク、または選択したタスクを削除します。
実行中のタスク、または他のタスクで使用されているタスクは削除できません。
プロジェクトのビューの変更
プロジェクトには 2 種類のビューがあります。[パイプライン ビュー] をクリックすると、ビューが切り替わります。
-
パイプライン ビューは、データ タスクのデータ フローを表示します。
[レイヤー] をクリックすると、表示されるデータ タスクの情報量を選択できます。次の情報をオンまたはオフに切り替えます。
-
状態
-
データの鮮度
-
[スケジュール]
-
クロスプロジェクト出力
この操作により、このプロジェクトのタスクを消費する他のプロジェクトのタスクが表示されます。現在のプロジェクト外のすべてのタスクはグレーで表示されます。
-
-
カード ビューには、データタスクに関する情報を含むカード ビューが表示されます。
アセットの種類と所有者をフィルタリングできます。
プロジェクトの削除
-
[パイプライン プロジェクト] ビューで、プロジェクト上の
 をクリックし、 [削除] を選択します。
をクリックし、 [削除] を選択します。
[このプロジェクトのタスクによって作成されたテーブルおよびビューを保持する] を選択すると、プロジェクトが削除された後に通常削除されるテーブルとビューが保持されます。次のタスク タイプでは、このオプションが選択されていない場合でも、テーブルとビューは常に保持されます。
-
ランディング タスク
-
レイク ランディング タスク
-
レプリケーション タスク
データの表示
データのサンプルを表示して、データ パイプラインを設計しながらデータの形状を表示して検証することができます。
次の権限が必要です。
-
管理 のテナント レベルでデータの表示が有効になっている。
[設定] > [機能コントロール] > [データ統合 でのデータ表示] を有効にします。
-
接続が常駐するスペースで [データ表示可能] のロールが割り当てられている。
-
プロジェクトが常駐するスペースで [表示可能] のロールが割り当てられている。
データ パイプライン ビューでサンプル データを表示するには:
-
パイプライン ビューの下部にあるプレビュー バナーの
 をクリックします。
をクリックします。 -
データをプレビューするデータ タスクを選択します。
データのサンプルが表示されます。[列の数] でサンプルに含めるデータ列の数を設定できます。
プロジェクトのエクスポートとインポート
プロジェクトを再構築するために必要なものがすべて含まれた JSON ファイルにプロジェクトをエクスポートできます。エクスポートされた JSON ファイルは、同じテナントにも別のテナントにもインポート可能です。例えば、これを使って、プロジェクトを別のテナントに移動することや、プロジェクトのバックアップ コピーを作成することができます。
詳細については、「データ パイプラインのエクスポートとインポート」を参照してください。
プロジェクトの所有者を変更する
データ タスクは、所属するプロジェクトの所有者のコンテキストで動作します。プロジェクトの所有者を変更して、データ プロジェクト内のすべてのタスクの制御を別のユーザーに譲渡できます。これは、削除されたユーザーが所有するプロジェクトがある場合などに便利です。
-
プロジェクト ビューで ... をクリックし、 [所有者を変更] をクリックします。
所有権の変更は、プロジェクト内のすべてのタスクに適用されます。プロジェクト内のタスクによって作成されたすべてのカタログ化されたデータセットの所有者も変更されます。
データ プラットフォーム接続の変更
プロジェクトの [データ プラットフォーム] 接続を変更する場合は、次の操作を実行する必要があります。
-
すべてのランディング タスクでテーブルを再作成します。
-
プロジェクト内の他のすべてのタスクを準備します。
プロジェクト情報の表示
メニュー バーで ![]() をクリックして、次のようなプロジェクト情報を表示します。
をクリックして、次のようなプロジェクト情報を表示します。
-
所有者
-
スペース
-
データ プラットフォーム
-
プロジェクトID
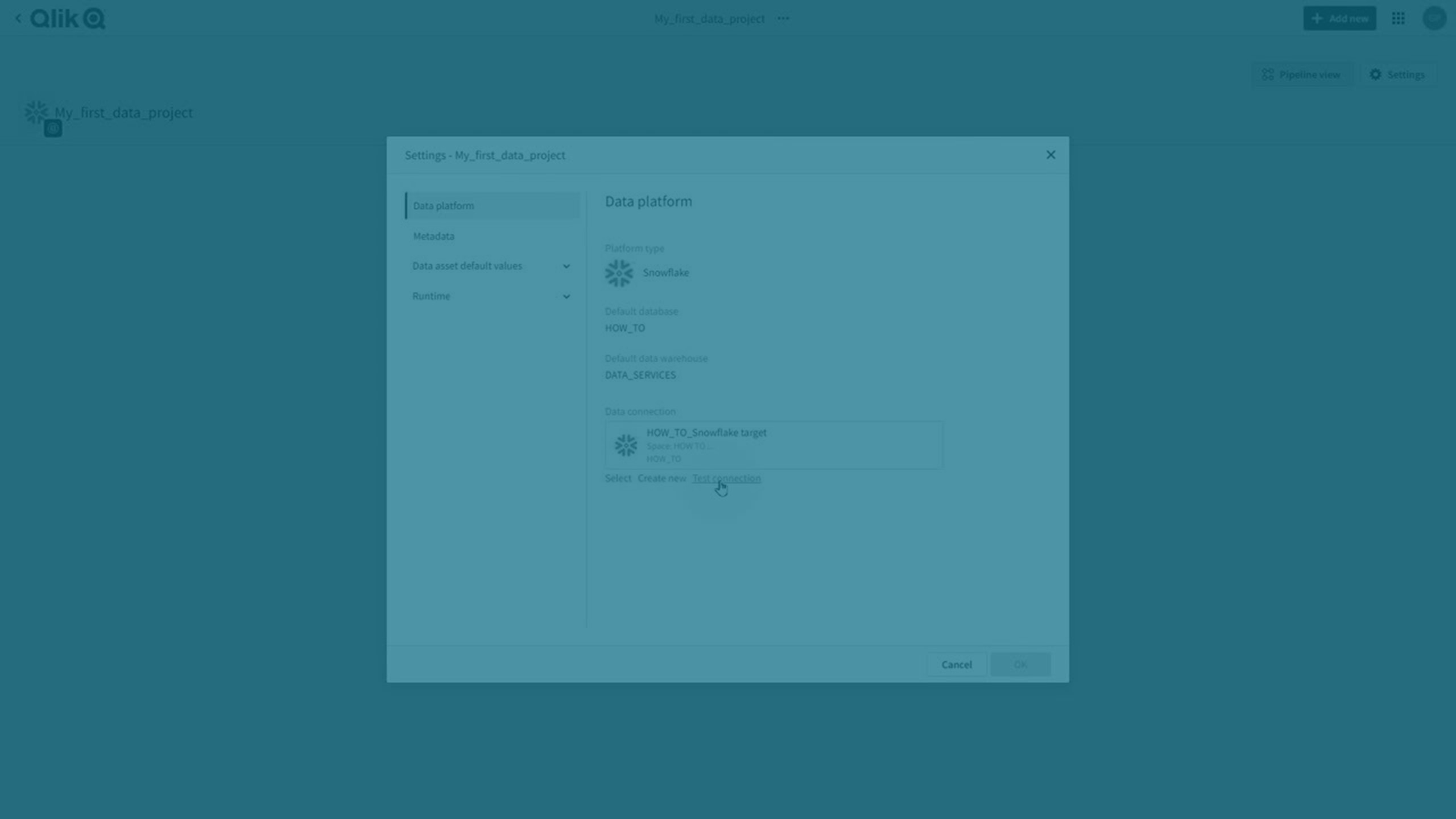
プロジェクトの設定
プロジェクトおよび含まれるすべてのデータ タスクに共通のプロパティを設定できます。
-
[設定] をクリックします。
詳細については、「データ パイプライン プロジェクトの設定」を参照してください。