
Administrar conjuntos de datos
Puede administrar o gestionar los conjuntos de datos incluidos en las tareas de datos de Aterrizaje, Almacenamiento, Transformación, Data mart, Aterrizaje de streaming, Transformación de streaming y Replicación para crear transformaciones, filtrar los datos y añadir columnas.
Los conjuntos de datos incluidos se muestran en Conjuntos de datos en la vista Diseño. Puede seleccionar qué columnas mostrar con el selector de columnas (![]() ).
).
Conjuntos de datos en la vista Diseño de una tarea de datos

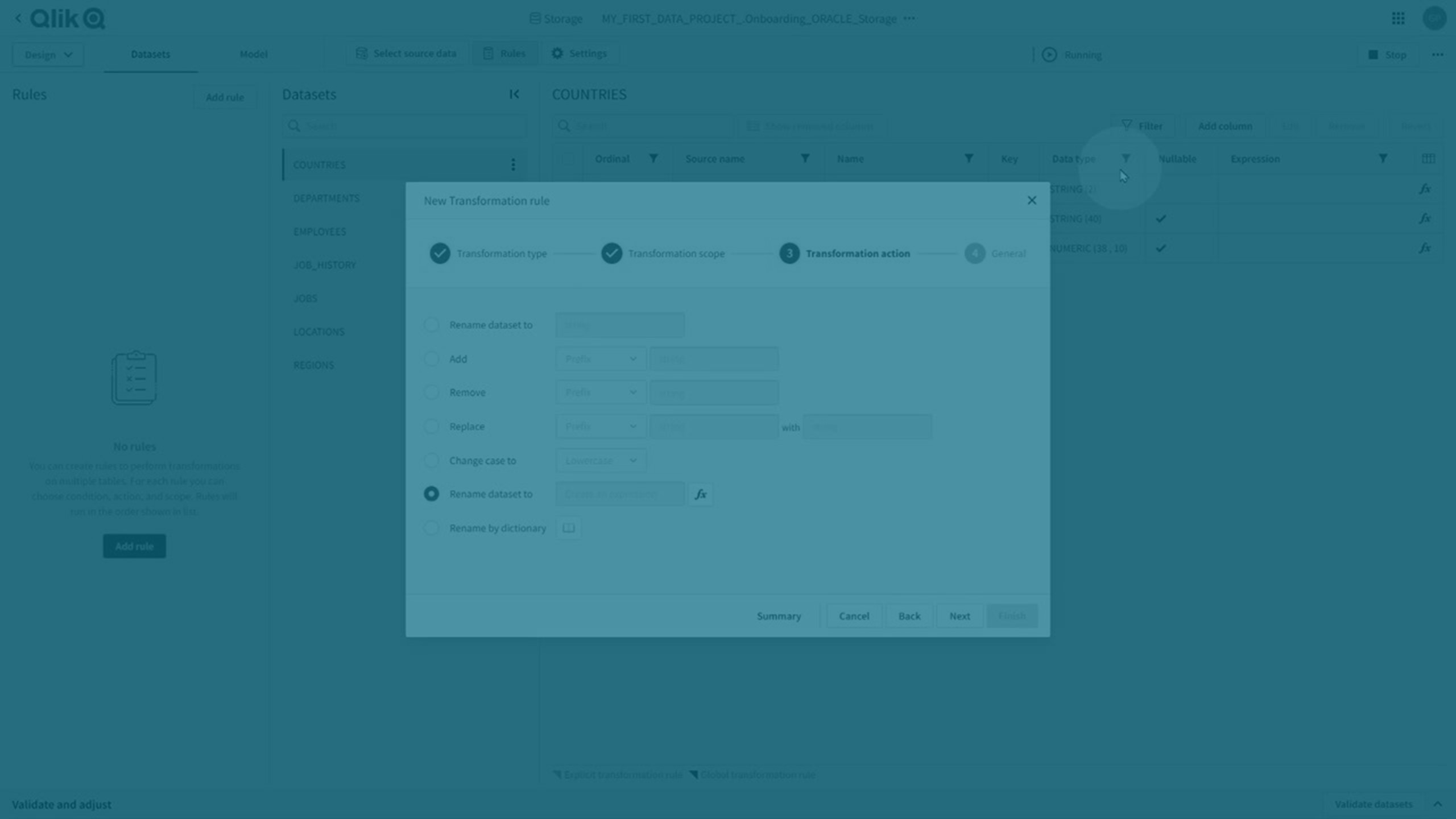
Reglas de transformación y transformaciones explícitas
Puede realizar transformaciones tanto globales como explícitas.
Reglas de transformación
Puede realizar transformaciones globales creando una regla de transformación que utilice % como comodín en el ámbito para aplicarlo a todos los conjuntos de datos coincidentes.
-
Haga clic en Reglas y luego en Añadir regla para crear una nueva regla de transformación.
Para más información, vea Crear reglas para transformar conjuntos de datos.
Las reglas de transformación se indican mediante una esquina de color púrpura oscuro en el atributo afectado.
Transformaciones explícitas
Las transformaciones explícitas se crean:
-
Cuando utiliza Editar para cambiar un atributo de columna.
-
Cuando utiliza Renombrar en un conjunto de datos.
-
Cuando agrega una columna.
Las transformaciones explícitas anulan las transformaciones globales y se indican mediante una esquina de color violeta claro en el atributo afectado.
Modelos de conjuntos de datos
Los conjuntos de datos pueden estar basados en el origen o en el destino, dependiendo del tipo de tarea y de las operaciones de la tarea. El modelo de conjunto de datos utilizado afecta al comportamiento de la canalización en los cambios de origen, y a las operaciones que puede realizar.
-
Conjuntos de datos basados en el origen
El conjunto de datos se basa en los conjuntos de datos fuente y solo contendrá cambios en los metadatos. Se aplica automáticamente un cambio en los datos de origen que puede provocar cambios en todas las tareas posteriores. No es posible cambiar el orden de las columnas, o cambiar el conjunto de datos de origen.
Los siguientes tipos de tarea utilizan siempre un modelo de conjunto de datos de origen: Destino, Almacenamiento, Datos registrados, Replicación y Aterrizaje en un lago de datos.
-
Conjuntos de datos basados en el destino
El conjunto de datos se basa en los metadatos del destino. Si se añade o elimina una columna desde el origen, no se aplicará automáticamente a la siguiente tarea descendente. Puede cambiar el orden de las columnas y cambiar el conjunto de datos de origen. Esto significa que la tarea es más autónoma y le permite controlar el efecto de los cambios de origen.
Los siguientes tipos de tareas pueden utilizar un modelo de conjuntos de datos basado en el destino: Transformación, Data mart. Hay algunos casos en los que se utiliza un modelo basado en el origen para tareas de transformación basadas en la operación.
-
Si una transformación SQL o un flujo de transformación realiza una selección de columnas, el conjunto de datos se basará en el destino. Por ejemplo, si utiliza SELECT A, B, C from XYZ en una transformación SQL o utiliza el procesador Seleccionar columnas en un flujo de transformación.
-
Si se mantienen las columnas predeterminadas, el conjunto de datos está basado en el origen. Por ejemplo, si utiliza SELECT * from XYZ en una transformación SQL.
-
Actualizar proyectos desde un modelo basado en el origen a un modelo basado en el destino
Los proyectos existentes se actualizan al modelo de conjunto de datos basado en el destino cuando procede. Se le guiará a través del proceso de actualización cuando abra un proyecto por primera vez. Existen algunas consideraciones a la hora de importar y exportar proyectos con diferentes modelos de conjuntos de datos.
-
No es posible importar un proyecto con un modelo basado en origen a un proyecto con un modelo basado en destino.
Importar el proyecto con un modelo basado en fuentes a un nuevo proyecto, actualizar el nuevo proyecto y, a continuación, exportar el proyecto resultante. Ahora puede volver a importar este proyecto al proyecto con un modelo basado en destino.
-
No es posible importar un proyecto con un modelo basado en destino a un proyecto con un modelo basado en origen.
Actualice el proyecto a un modelo basado en destino antes de importar un proyecto con un modelo basado en origen.
Filtrar un conjunto de datos
Puede filtrar datos para crear un subconjunto de filas, si es necesario.
-
Haga clic en Filtrar
Para más información, vea Filtrar un conjunto de datos.
Cambiar el nombre de un conjunto de datos
Puede cambiar el nombre de un conjunto de datos.
-
Haga clic en
 en un conjunto de datos y, a continuación, en Editar.
en un conjunto de datos y, a continuación, en Editar.
Añadir columnas
Puede agregar columnas con transformaciones de nivel de fila, si es necesario.
-
Haga clic en Añadir columna
Para más información, vea Agregar columnas a un conjunto de datos.
Editar una columna
Puede editar las propiedades de la columna seleccionando una columna y haciendo clic en Editar.
-
Nombre
-
Clave
Establezca una columna para que sea una clave principal. También puede establecer claves seleccionando o anulando la selección en la columna Clave.
-
Anulable
-
Tipo de datos
Establezca el tipo de datos de la columna. Para algunos tipos de datos, puede establecer una propiedad adicional, por ejemplo, Longitud.
Nota informativaCuando cambie el tipo de datos o el tamaño del tipo de datos de una columna, esto puede tener implicaciones en las tareas que utilicen ese conjunto de datos. Para más información, vea Administrar los tipos de datos.
Eliminar columnas
Puede eliminar una o más columnas de un conjunto de datos.
-
Seleccione las columnas que desee eliminar y haga clic en Eliminar.
Si desea ver las columnas eliminadas, haga clic en Mostrar columnas eliminadas. Las columnas eliminadas se indican mediante un texto tachado. Puede recuperar una columna eliminada seleccionándola y haciendo clic en Revertir.
Revertir cambios explícitos en las columnas
Puede revertir todos los cambios explícitos realizados en una o más columnas.
-
Seleccione las columnas en las que desee revertir los cambios y haga clic en Revertir.
Los cambios de las reglas de transformación global no se revertirán.
Si revierte una columna agregada, esta se eliminará.
Configuración del conjunto de datos
Puede cambiar la configuración del conjunto de datos. La configuración predeterminada hereda la configuración de la tarea de datos, pero también puede cambiar una configuración para que esté explícitamente activada o desactivada.
-
Haga clic en
 , en un conjunto de datos y luego en Configuración.
, en un conjunto de datos y luego en Configuración.
Mostrar columnas de encabezado en las vistas
Para las tareas de aterrizaje de streaming y de transformación de Qlik Open Lakehouse, puede controlar si desea mostrar u ocultar las columnas de encabezado. Las opciones varían según el tipo de tarea.
Tarea de aterrizaje de streaming
Para mostrar las columnas de encabezado, active Mostrar columnas de encabezado a la derecha del cuadro de búsqueda.
Tarea de transformación de streaming
A la derecha del cuadro de búsqueda hay disponible una lista desplegable con las siguientes opciones.
-
Ocultar columnas de cabecera:El valor predeterminado.
-
Mostrar columnas de cabecera
-
Estándar:selecciónelo para mostrar las columnas de cabecera en las vistas estándar.
-
Historial: selecciónelo para mostrar las columnas de encabezado para las vistas de historial. Tenga en cuenta que esta opción solo estará disponible si Crear un almacén de datos históricos (Tipo 2) está habilitado en la configuración de la tarea o del conjunto de datos.
-
Para una descripción de las columnas de encabezado disponibles, vea Tablas de destino y Vistas.
Ver datos
Puede ver una muestra de los datos, para ver y validar la forma de sus datos mientras diseña su canalización de datos.
Deben cumplirse los siguientes requisitos:
-
La visualización de los datos debe estar habilitada a nivel del espacio empresarial inquilino en el centro de actividades Administración.
Para activarla, vaya a la página Configuración, seleccione la pestaña Control de funciones y active Visualización de datos en Integración de datos.
-
Se le asigna el rol Puede ver datos en el espacio donde reside la conexión.
-
Se le asigna el rol Puede ver en el espacio donde reside el proyecto.
Visualización de datos de muestra
Para ver datos de muestra en la pestaña Conjuntos de datos de la vista Diseño:
-
Haga clic en Ver datos.
Se visualiza una muestra de los datos. Puede establecer cuántas filas de datos incluir en la muestra con Número de filas.
Comprender la estructura de los datos
La vista previa de datos muestra tanto las columnas de negocio como las columnas generadas por el sistema. Al visualizar datos de conjuntos de datos de streaming, las columnas de encabezado (con el prefijo hdr__) proporcionan metadatos sobre la fuente de datos y las transformaciones. Los ejemplos incluyen hdr__from_timestamp (cuándo se cargaron los datos) y hdr__operation (tipo de operación aplicada).
Las columnas de encabezado son de solo lectura y no se pueden modificar ni eliminar de la vista previa. Para controlar qué encabezados se muestran de forma predeterminada, configure los encabezados de vista estándar a nivel de proyecto o de conjunto de datos.
Cambiar entre conjuntos de datos y tablas
Para cambiar entre conjuntos de datos y tablas:
-
Seleccione Conjuntos de datos para ver la representación lógica de los datos.
-
Seleccione Objetos físicos para ver la representación física en la base de datos como tablas y vistas.
Nota de prensaEsta opción no está disponible si aún no se ha creado la representación física.
Filtrado
Puede filtrar los datos de muestra de dos maneras:
-
Usar
 para filtrar qué datos de muestra recuperar.
para filtrar qué datos de muestra recuperar.Por ejemplo, si utiliza el filtro ${OrderYear}>2023 y Número de filas se establece en 10, obtendrá una muestra de 10 pedidos de 2024.
-
Filtrar los datos de la muestra por una columna específica.
Esto solo afectará a los datos de muestra existentes. Si usó
para incluir únicamente pedidos de 2024 y establece el filtro de columna para mostrar pedidos a partir de 2022, el resultado es una muestra vacía.
Ordenación
También puede ordenar la muestra de datos por una columna específica. La ordenación solo afectará a los datos de muestra existentes. Si utilizó ![]() para incluir únicamente pedidos de 2024 e invierte el orden de clasificación, los datos de muestra seguirán conteniendo solo pedidos de 2024.
para incluir únicamente pedidos de 2024 e invierte el orden de clasificación, los datos de muestra seguirán conteniendo solo pedidos de 2024.
Ocultar columnas
Puede ocultar columnas en la vista de datos:
-
Para ocultar una columna, haga clic en
en la columna, y después en Ocultar columna. -
Oculte varias columnas haciendo clic en
en cualquier columna y después en Mostrar columnas. Esto permite controlar la visibilidad de todas las columnas de la vista.
Descargar los datos de muestra
Puede descargar los datos de muestra visualizados:
-
Haga clic en
 para descargar el contenido de la vista de datos de muestra.
para descargar el contenido de la vista de datos de muestra.
Los datos de muestra se descargan como un archivo CSV en las descargas de su navegador.
Validar y ajustar los conjuntos de datos
Puede validar todos los conjuntos de datos que se incluyen en la tarea de datos.
Amplíe Validar y ajustar para ver todos los errores de validación y cambios en el diseño.
Validar los conjuntos de datos
-
Haga clic en Validar conjuntos de datos para validarlos.
La validación incluye comprobar que:
-
Todas las tablas tienen una clave principal.
-
No faltan atributos.
-
No hay nombres de tablas o columnas duplicados.
También obtendrá una lista de cambios de diseño en comparación con la fuente:
-
Tablas y columnas añadidas
-
Tablas y columnas eliminadas
-
Tablas y columnas renombradas
-
Claves principales y tipos de datos cambiados.
Amplíe Validar y ajustar para ver todos los errores de validación y cambios en el diseño.
-
Corrija los errores de validación y luego vuelva a validar los conjuntos de datos.
-
La mayoría de los cambios en el diseño se pueden ajustar automáticamente, excepto las claves principales o los tipos de datos modificados. En ese caso, debe sincronizar los conjuntos de datos.
Preparar los conjuntos de datos
Puede preparar conjuntos de datos para ajustar los cambios de diseño sin pérdida de datos si es posible. Si hay cambios de diseño que no se pueden ajustar sin pérdida de datos, tendrá la opción de volver a crear las tablas desde el origen con pérdida de datos.
Esto requiere detener la tarea.
-
Haga clic en
 y después en Preparar.
y después en Preparar.
Cuando los conjuntos de datos estén preparados, valide los conjuntos de datos antes de reiniciar la tarea de almacenamiento.
Volver a crear conjuntos de datos
Puede volver a crear los conjuntos de datos desde el origen. Cuando vuelva a crear un conjunto de datos, se producirá pérdida de datos. Siempre que tenga los datos de origen, puede volver a cargarlos desde el origen.
Esto requiere detener la tarea.
-
Haga clic en
, luego en Volver a crear las tablas.
Descargar los datos de validación
Puede descargar los datos de Errores de validación, Cambios de diseño y Progreso de la preparación:
-
Haga clic en
para descargar.
Los datos se descargan como un archivo CSV en las descargas de su navegador.
Limitaciones
-
En Google BigQuery, si elimina o cambia el nombre de una columna, esto volverá a crear la tabla y provocará la pérdida de datos.