
チュートリアル - データ フロー初級者向け
このチュートリアルでは、データ フローの構築に必要なさまざまな手順と、提供されるさまざまな可能性をよりよく理解できるように、基本的なデータ準備のユース ケースを紹介します。いくつかのデータセットを含む添付パッケージを使用すると、このチュートリアルのすべてのステップを再現できます。
このシナリオでは、世界中の顧客に関する販売データ サンプルと、顧客の名前、注文日とステータス、出身国、州、住所、電話番号などの情報に焦点を当てます。たとえば、米国の顧客に焦点を当てたデータを準備するとします。米国の顧客に関するすべてのデータを分離し、原産国に関する不足情報を追加し、わずかな書式変更を行い、たとえば分析アプリケーションのソースとして使用できる新しいファイルにデータをエクスポートします。
前提条件
このパッケージをダウンロードしてデスクトップに解凍します。
パッケージには、チュートリアルを完了するために必要な次のデータ ファイルが含まれています。
-
sales_data_sample.xlsx
-
states.xlsx
ソース ファイルをカタログに追加する
データ フローの作成を開始する前に、パッケージの 2 つのファイルが分析プラットフォームで使用可能になっている必要があります。ソース データをカタログに追加するには、次を実行します。
-
Launcher メニューから、 [分析] > [カタログ] を選択します。
-
右上の [新規作成] をクリックし、 [データセット] を選択します。
-
開いたウィンドウで、 [データ ファイルをアップロード] をクリックします。
-
チュートリアル ファイルをデスクトップから [ファイルを追加] ウィンドウの専用領域にドラッグ アンド ドロップするか、 [参照] をクリックして保存場所から選択します。
-
[Upload] (アップロード)をクリックします。
データ フローの作成とソースの追加
すべての準備が整ったので、ソースからデータ フローの作成を開始できます。
-
Launcher メニューから、 [分析] > [データの準備] を選択します。
-
[データ フロー] タイルをクリックするか、 [新規作成] > [データ フロー] をクリックします。
-
[新しいデータ フローを作成] ウィンドウで、データ フローの情報を次のように設定し、 [作成] をクリックします。
-
[名前] は データ フローのチュートリアル。
-
[スペース] は 個人。
-
[説明] は 米国の顧客に焦点を当てた販売データを準備するためのデータ フロー。
-
[タグ] は チュートリアル。
空のデータ フローが開きます。

-
-
空のキャンバスで [カタログを参照] をクリックして、カタログに追加されたデータセットの確認を開始します。
-
フィルター検索を使用して、以前にアップロードした sales_data_sample.xlsx および states.xlsx データセットを見つけ、名前の前のチェックボックスを選択します。
-
[Next] (次へ)をクリックします。
-
概要内のデータセットとそのフィールドを確認し、 [データ フローにロード] をクリックします。
両方のソース データセットがキャンバスに追加され、プロセッサーを使用したデータの準備を開始できます。sales_data_sample.xlsx は作業するメイン データセットであり、states.xlsx は追加データとして使用されます。

米国顧客に関するデータのフィルタリング
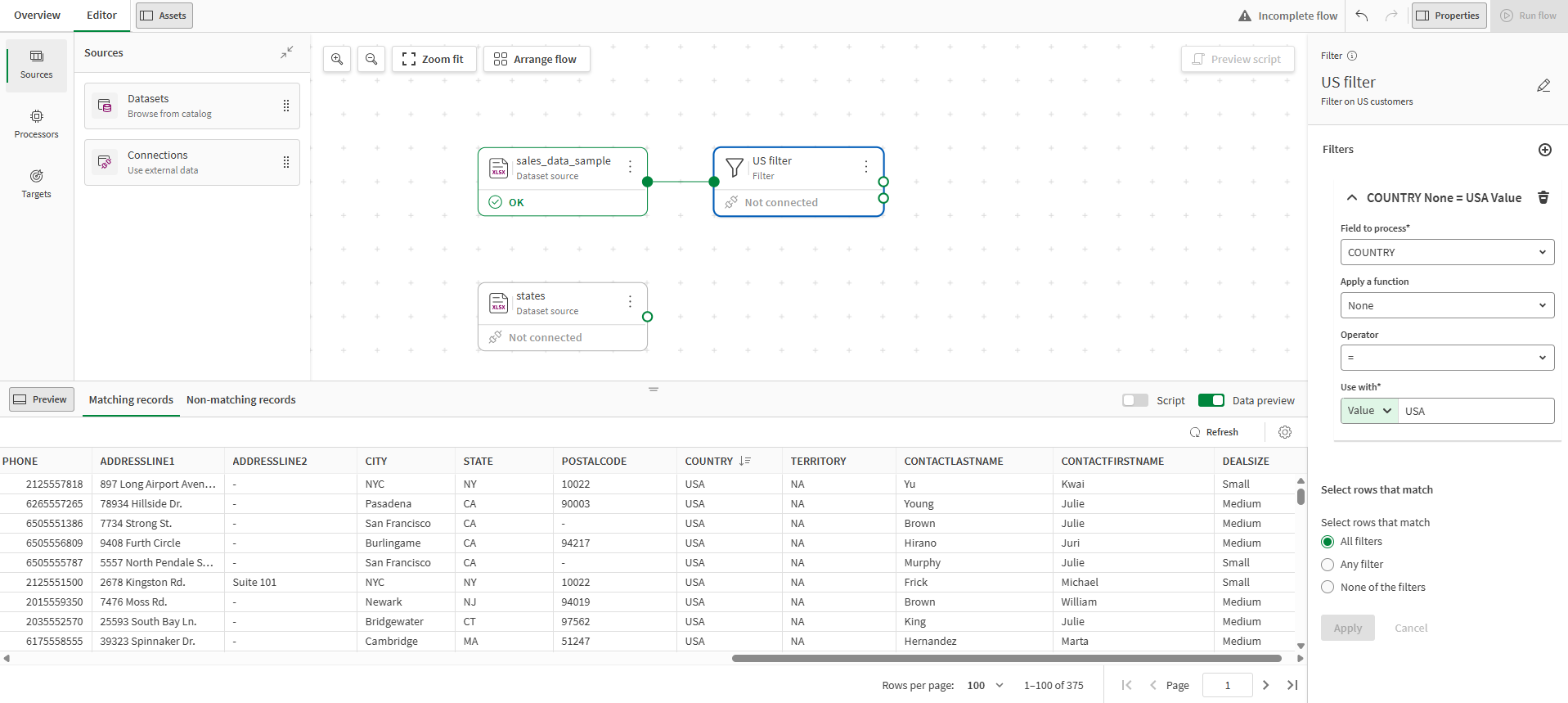
プロセッサを使用して、連続的な変更を伴うデータの準備を開始できるようになりました。最初のステップは、データセットの範囲を縮小し、米国を拠点とする顧客のみに焦点を当てることです。実行するには、Filter プロセッサーを使用して、COUNTRY フィールドに USA 値を持つ行のみを選択します。
-
キャンバス上の sales_data_sample ソースのアクション メニュー (
 ) をクリックします。
) をクリックします。 -
開いたメニューから、 [プロセッサーを追加] > [Filter] を選択します。
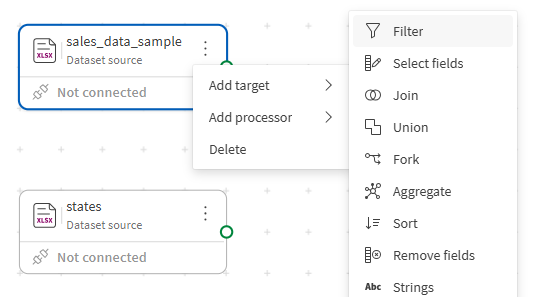
Filter プロセッサーはキャンバス上に配置され、ソース ノードにすでに接続されています。
情報メモ[プロセッサー] の左パネルから手動でプロセッサーを手動でドラッグ アンド ドロップし、ノードを手動で接続することもできます。 -
まだ開いていない場合は、キャンバスの右上にある [プロパティ] をクリックしてプロセッサー プロパティ パネルを開き、プロセッサーを構成したり、データのプレビューやスクリプトを確認したりできます。
-
プロパティ パネルで、プロセッサー名の横にある [編集] アイコン (
 ) をクリックして、プロセッサーに「米国フィルター」などの意味のある名前を付け、「米国顧客のフィルター」などの短い説明を付けます。
) をクリックして、プロセッサーに「米国フィルター」などの意味のある名前を付け、「米国顧客のフィルター」などの短い説明を付けます。 -
[処理するフィールド] ドロップ ダウン リストで、 [COUNTRY] を選択します。
-
[Operator] (オペレーター)ドロップ ダウン リストから==をクリックします。
-
[Use with] (一緒に使用) フィールドで [値] を選択し、「USA」と入力します。
-
[一致する行を選択] リストから、 [すべてのフィルター] を選択します。
これらのパラメーターは、複数のフィルターを組み合わせる場合に便利です。
-
[適用] をクリックします。
プロセッサーの構成は有効ですが、プロセッサーにまだ出力フローがないため、「接続されていません」というメッセージが表示されます。
-
下部パネルの [データのプレビュー] をクリックします。
プレビューを見ると、国が USA である行のみがこの段階で保持され、出力フローに伝播されることがわかります。これまでのデータ フローは次のようになります。
別のデータセットから州名を追加する
米国を拠点とする顧客の場合、「STATE」フィールドには 2 文字のコードとして州の情報が含まれます。州の正式名称を使用して、この情報を読みやすくしたいと考えています。
先ほどソースとしてインポートした states.xlsx データセットには、2 文字のコードに対応する正式名称を持つ米国のすべての州の参照が含まれています。これら 2 つのデータセット間の結合を実行して州名を取得し、メイン フローを補完します。

結合するには、次を実行します。
-
Filter プロセッサーのアクション メニュー (
) をクリックし、 [一致するブランチにプロセッサーを追加] > [Join] を選択します。 -
プロパティ パネルの [編集] アイコン (
) を使用して、プロセッサーの名前を「Full state names (州の正式名称)」に変更します。 -
州のソースを Join プロセッサー下部のアンカー ポイントに接続します。リンクを作成するには、ソース ノードの右側にあるドットをクリックし、クリックしたままリンクをプロセッサー ノードの左側にある下のドットまでドラッグします。

-
[結合タイプ] ドロップ ダウン リストで、 [左外部結合] を選択します。
-
[左キー] ドロップ ダウン リストで、 [STATE (州)] フィールドを選択します。
-
[右キー] ドロップ ダウン リストで、 [Abbreviation (略称)] フィールドを選択します。
選択された 2 つの列には共通の情報が含まれており、2 つの入力フロー間のリンクが可能になります。左外部結合では、2 番目のデータセットからの追加フィールドのみがメインフローに追加されます。
-
[適用] をクリックします。

データセットの最後に新しいフィールド「State (州)」が追加され、各顧客の州の正式名称が表示されます。
フィールドの名前変更と移動
現在、列の名前付けと書式設定にはいくつかの問題があります。STATE と State は酷似しているため混乱を招き、2 つのフィールドは離れすぎています。Select fields プロセッサーを使用してフィールドの名前を変更したり、フィールドを移動したりすることで、フィールドの一貫性と統一性を向上できます。
-
Join プロセッサーのアクション メニュー (
) をクリックし、 [プロセッサーを追加] > [Select fields] を選択します。 -
Join プロセッサーを Select fields プロセッサーに接続します。

-
プロパティ パネルの [編集] アイコン (
) を使用して、プロセッサーの名前を「Reorganize states fields (州フィールドの再編成)」に変更します。 -
フロー内のすべての項目を保持するには、 [すべて選択]チェックボックスをクリックします。
-
名前を変更するフィールドにマウスを合わせ、
[編集] アイコンをクリックして、 2 つのフィールド名を次のように編集します。-
STATE を STATECODE に
-
State を STATENAME に
-
-
= アイコンを使用して、新しい STATENAME 列を STATECODE の横にドラッグ アンド ドロップします。
-
[適用] をクリックします。
フィールドを再編成すると、データ フローは次のようになります。

顧客名を大文字表記にする
顧客の姓を強調表示し、名と区別しやすくするために、Strings プロセッサーのシンプルな書式設定関数を使用して、姓を大文字にします。
-
Select fields プロセッサーのアクション メニュー (
) をクリックし、 [プロセッサーを追加] > [Strings] を選択します。 -
Select fields プロセッサーを Strings プロセッサーに接続します。

-
プロパティ パネルの [編集] アイコン (
) を使用して、プロセッサーの名前を「Upper case (大文字)」に変更します。 -
[Function name] (関数名) ドロップ ダウン リストで [Change to upper case] (大文字に変換) を選択します。
-
[処理するフィールド] ドロップ ダウン リストで、 [CONTACTLASTNAME] を選択します。
-
[適用] をクリックします。

ターゲットを追加してデータ フローを実行する
主な準備ステップは完了ました。結果のデータをエクスポートする方法を構成して、データ フローを最終決定できます。このシナリオでは、準備したデータを .qvd ファイルとしてエクスポートし、カタログに直接保存します。こうすることで、後で分析アプリケーションなどで使用しやすくなります。
-
Strings プロセッサーのアクション メニュー (
) をクリックし、 [ターゲットを追加] > [データ ファイル] を選択します。 -
Strings プロセッサーを [データ ファイル ターゲット] に接続します。

-
プロパティ パネルの [編集] アイコン (
) を使用して、プロセッサーの名前を「QVD ターゲット」に変更します。 -
[スペース] ドロップダウン リストで、 [個人] を選択します。
-
[ファイル名] フィールドに「tutorial_output」と入力します。
-
[拡張] ドロップダウンリストで、 [.qvd] を選択します。
-
[適用] をクリックします。
ヘッダー バーのステータスと、各ソース、プロセッサー、ターゲット ノードの下の緑色のチェック マークで示されるように、データ フローが完了して有効になりました。

-
ウィンドウの右上にある [フローを実行] ボタンをクリックします。
実行の進行状況を示すモーダルが開きます。

しばらくするとウィンドウが閉じ、実行が成功したかどうかを知らせる通知が表示されます。データ フローの出力は、カタログまたはデータ フローの [概要] パネルの [出力] セクションで確認できます。
次のステップ
ソース データをカタログにインポートし、データをフィルター処理して改善するためのシンプルなデータ フローを構築し、準備の結果をすぐに使用できるファイルとしてエクスポートする方法を学習しました。
独自のユース ケースにデータ フローを使用するさまざまな方法については、データ フロー プロセッサー の完全なリストと、提供される関数を参照してください。
準備したデータを分析アプリケーションで使用する方法については、「分析の作成とデータの視覚化」を参照してください。