
教程 - 初学者的数据流
本教程将介绍一个基本的数据准备用例,让你更加熟悉构建数据流所需的不同步骤,以及所提供的不同可能性。使用所附的包含几个数据集的软件包,您就可以重现本教程的所有步骤。
本方案将重点关注一个销售数据样本,其中包含来自世界各地的客户,以及他们的姓名、订单日期和状态、原籍国、州、地址、电话号码等信息。比方说,您想准备数据,以便重点关注来自美国的客户。您将把美国客户的所有数据分离出来,添加缺失的原籍国信息,对格式稍作修改,然后把数据导出到一个新文件中,以便用作分析应用程序等的数据源。
先决条件
下载该程序包并将其在您的桌面上解压:
该包内含完成本教程所需的以下数据文件:
-
sales_data_sample.xlsx
-
states.xlsx
将源文件添加到目录中
在开始创建数据流之前,需要在分析平台中提供软件包中的两个文件。将数据源添加到目录中:
-
从启动器菜单中选择分析 > 目录。
-
单击右上角的新建按钮,然后选择数据集。
-
在打开的窗口中,单击上传数据文件。
-
将桌面上的教程文件拖放至添加文件窗口的专用区域,或单击浏览从其位置选择文件。
-
单击上传。
创建数据流并添加源
现在各部分都已设置完毕,可以开始创建数据流,首先从源开始。
-
从启动器菜单开始,选择分析 > 准备数据。
-
单击数据流磁贴或单击新建 > 数据流。
-
在新建数据流窗口中,设置数据流的信息如下,然后单击创建:
-
数据流教程作为名称。
-
个人作为空间。
-
数据流,准备以美国客户为重点的销售数据,作为描述。
-
教程作为标签。
您的空数据流会打开。

-
-
单击空白画布上的浏览目录,开始查看已添加到目录中的数据集。
-
使用过滤搜索查找之前上传的 sales_data_sample.xlsx 和 states.xlsx 数据集,并选择其名称前的复选框。
-
单击下一步。
-
查看摘要中的数据集及其字段,然后单击加载到数据流中。
两个源数据集都添加到画布中,您可以使用处理器开始准备数据。sales_data_sample.xlsx 是您要使用的主要数据集,而 states.xlsx 将用作附加数据。

筛选美国客户数据
现在,您可以开始准备数据,通过使用处理器进行连续更改。第一步是缩小数据集的范围,只关注美国客户。为此,请使用筛选器处理器,只选择 COUNTRY 字段中包含 USA 值的记录。
-
单击画布上 sales_data_sample 源的操作菜单 (
 )。
)。 -
在打开的菜单中选择添加处理器 > 筛选器。
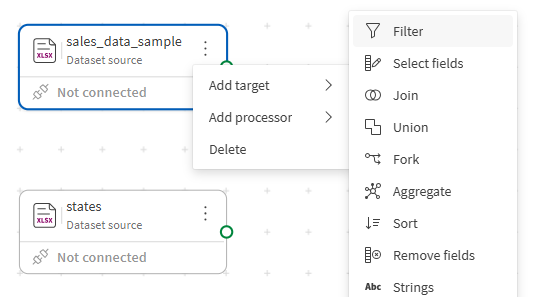
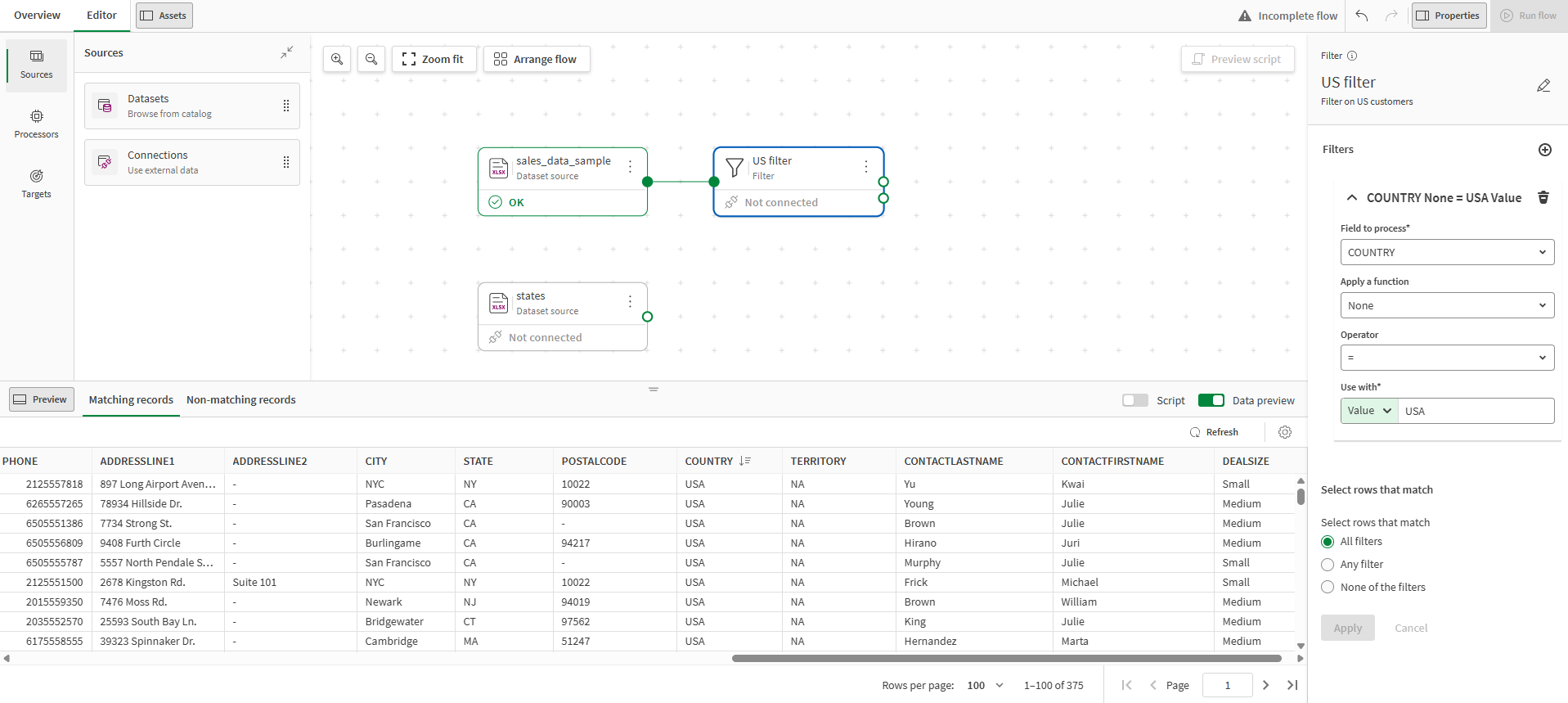
筛选器处理器被放置在画布上,并已自动与源连接。
信息注释也可以从处理器左侧面板手动拖放处理器,并手动连接节点。 -
如果尚未打开,请单击画布右上方的属性,打开处理器属性面板,在这里可以配置处理器,查看数据预览和脚本。
-
在自定义属性面板中,单击处理器名称旁边的编辑图标 (
 ),给处理器起一个更有意义的名称,如美国筛选器,以及一个简短的描述,如筛选美国客户。
),给处理器起一个更有意义的名称,如美国筛选器,以及一个简短的描述,如筛选美国客户。 -
从要处理的字段下拉列表中选择国家。
-
从运算符下拉列表中选择 =。
-
在使用字段中,选择值并输入美国。
-
从选择匹配的行列表中,选择所有筛选器。
这些参数在组合多个筛选器时更为有用。
-
单击应用。
处理器配置有效,但仍显示未连接消息,是因为处理器还没有输出流。
-
单击底部面板中的预览数据。
从预览中可以看到,在此阶段只保留了以美国为国家的行,并将在输出流中传播。到目前为止,您的数据流应该如下所示:
从另一个数据集添加州名
对于其余的美国客户,州字段包含原籍州,但为双字母代码。要想让这些信息更容易阅读,最好能提供州的全称。
您之前作为源代码导入的 states.xlsx 数据集恰好包含了美国所有州的双字母代码参考以及相应的全称。您将在这两个数据集之间执行联接,以检索州名并补充您的主要流。

执行联接:
-
单击筛选器处理器的操作菜单 (
) 并选择添加处理器到匹配分支 > 联接。 -
使用属性面板中的编辑图标 (
) 重新命名处理器为全状态名称。 -
将状态源连接到联接处理器的底部锚点。要创建链接,请单击源节点右侧的圆点,按住不放,然后将链接拖动到处理器节点左侧底部的圆点。

-
在联接类型下拉列表中,选择左外部联接。
-
在左键下拉列表中,选择状态关键字段。
-
在右键下拉列表中,选择缩略词字段。
所选的两列包含共同信息,可在两个输入流之间建立联系。通过左外联接,只有第二个数据集的附加字段才会被添加到主要流中。
-
单击应用。

在数据集末尾添加了一个新字段州,其中包含每个客户所在州的全称。
重命名并移动字段
现在,您的列的命名和格式有几个问题。STATE 和 State 太相似,容易混淆,两个领域相差太远。为提高字段的一致性和统一性,您可以使用选择字段处理器来重新命名和移动字段。
-
单击联接处理程序的操作菜单 (
) ,选择添加处理器 > 选择字段。 -
连接联接处理器和选择字段处理器。

-
使用属性面板中的编辑图标 (
) 将处理器重命名为重新分类状态字段。 -
单击全选复选框,在流程中保留所有字段。
-
将鼠标指向要重新命名的字段,然后单击
编辑图标,编辑两个字段的名称,如下所示:-
STATECODE 为 STATE
-
STATENAME 为 State
-
-
使用 = 图标将新的 STATENAME 列拖放至 STATECODE 旁边。
-
单击应用。
您重新组织了字段,数据流看起来是这样的:

客户名称大写
为了突出客户的姓氏,并使其更容易与名字区分开来,您将使用字符串处理器的简单格式函数,将姓氏大写。
-
单击选择字段处理器的操作菜单 (
),选择添加处理器 > 字符串。 -
连接选择字段处理器到字符串处理器。

-
使用属性面板中的编辑图标 (
) 重新命名处理器为大写。 -
在函数名称下拉列表中,选择改为大写。
-
在要处理的字段下拉列表中,选择 CONTACTLASTNAME。
-
单击应用。

添加目标并运行数据流
主要的准备步骤已经完成,现在可以通过配置如何导出生成的数据来最终确定数据流。在这种情况下,您将把准备好的数据导出为直接存储在目录中的 .qvd 文件,方便以后在分析应用程序等中使用。
-
点击字符串处理器的操作菜单 (
),选择添加目标 > 无断点空格。 -
将字符串处理器连接到数据文件目标。

-
使用属性面板中的编辑图标 (
) 重新命名处理器为 QVD 目标。 -
在空间下拉列表中,选择个人。
-
在文件名字段中输入 tutorial_output。
-
在扩展下拉列表中,选择 .qvd。
-
单击应用。
从标题栏中的状态,以及每个数据源、处理器和目标节点下的绿色勾号可以看出,您的数据流现在已经完成并有效。

-
单击窗口右上方的运行流程按钮。
打开一个模态窗口,显示运行进度。

一段时间后,窗口关闭,并打开一个通知,告诉你运行是否成功。现在可以在目录中或数据流概览面板的输出部分找到数据流的输出。
下一步
您已经学会了如何将数据源导入目录,建立简单的数据流来筛选和改进数据,并将准备数据的结果导出为即用文件。
要了解在自己的用例中使用数据流的多种方法,可以查看 数据流处理器 的完整列表及其提供的功能。
要了解如何在分析应用程序中使用准备好的数据,请参阅创建分析和数据可视化。