
Учебное пособие ― Работа с потоком данных для начинающих
В этом учебном пособии описывается базовый сценарий подготовки данных и объясняются различные шаги, необходимые для построения потока данных, и предоставляемые возможности. С помощью прилагаемого пакета, содержащего несколько наборов данных, можно воспроизвести все действия, описанные в данном руководстве.
В этом сценарии используется выборка данных о продажах клиентам во всем мире с информацией об их именах, датах и состоянии заказов, стране происхождения, штатах, адресах, номерах телефонов и т. д. Допустим, требуется подготовить данные таким образом, чтобы сосредоточится на покупателях из США. Вы изолируете все данные о покупателях из США, добавите недостающую информацию о штатах происхождения, внесете небольшие изменения в форматирование и выполните экспорт данных в новый файл, который сможете использовать в качестве источника данных, например, для аналитического приложения.
Необходимые условия
Загрузите этот пакет и распакуйте его на своем рабочем столе:
Руководство «Работа с потоком данных для начинающих»
Пакет содержит следующие файлы данных, которые потребуются для изучения данного учебного пособия.
-
sales_data_sample.xlsx
-
states.xlsx
Добавление исходных файлов в каталог
Прежде чем приступить к созданию потока данных, необходимо сделать доступными два файла из пакета в аналитической платформе. Чтобы добавить источник данных в каталог, выполните следующие действия.
-
В меню средства запуска выберите Аналитика > Каталог.
-
Нажмите кнопку Добавить в правом верхнем углу и выберите Набор данных;
-
В открывшемся окне щелкните Загрузить файл данных.
-
Перетащите файлы учебного пособия с рабочего стола в специальную область окна Добавить файл или нажмите кнопку Обзор, чтобы выбрать их из папки.
-
Нажмите Загрузить.
Создание потока данных и добавление источника
Теперь, когда все подготовлено, можно приступать к созданию потока данных, начиная с источника.
-
В меню средства запуска выберите Аналитика > Подготовка данных.
-
Щелкните плитку Поток данных или выберите Создать > Поток данных.
-
В окне Создание нового потока данных настройте следующую информацию о потоке данных и нажмите кнопку Создать:
-
Учебное пособие по потоку данных в поле Имя.
-
Личное в поле Пространство.
-
Поток данных для подготовки данных о продажах покупателям из США в поле Описание.
-
Учебное пособие в поле Тег.
Открывается пустой поток данных.

-
-
Щелкните Найти в каталоге на пустом холсте, чтобы начать просматривать наборы данных, добавленные в каталог.
-
Выполните поиск с применением фильтра, чтобы найти ранее загруженные наборы данных sales_data_sample.xlsx и states.xlsx, и установите флажки перед их именами.
-
Нажмите Далее.
-
Просмотрите наборы данных и их поля в сводке, затем нажмите Загрузить в поток данных.
Оба исходных набора данных добавлены на холст, и можно приступать к подготовке данных с помощью процессоров. sales_data_sample.xlsx ― это основной набор данных, с которым мы будем работать, а states.xlsx будет использоваться в качестве дополнительных данных.

Фильтрация данных по клиентам из США
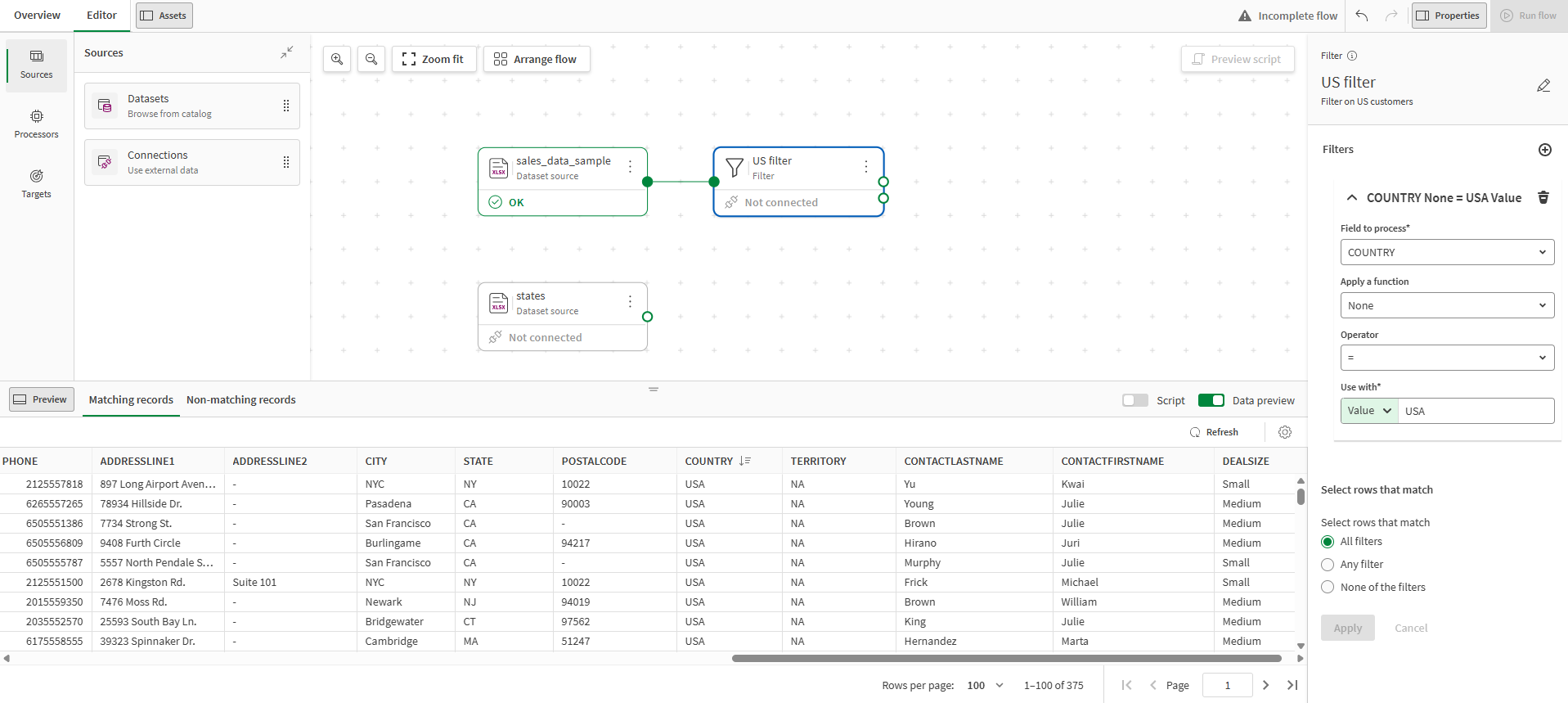
Теперь можно начинать подготовку данных путем последовательного изменения с помощью процессоров. Первый шаг ― уменьшить область набора данных и сосредоточиться только на покупателях из США. Для этого используйте процессор Filter (Фильтр), чтобы выбрать только те строки, которые содержат значение USA (США) в поле COUNTRY (СТРАНА).
-
Щелкните меню действий (
 ) источника sales_data_sample на холсте.
) источника sales_data_sample на холсте. -
В открывшемся меню выберите Добавить процессор > Фильтр.
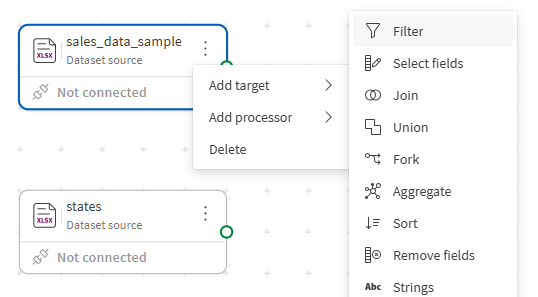
Процессор Filter (Фильтр) помещается на холст и автоматически подключается к источнику.
Примечание к информацииТакже можно вручную перетащить процессоры с левой панели Процессоры и вручную подключить узлы. -
Если панель свойств процессора еще не открыта, щелкните Свойства в правом верхнем углу холста, чтобы настроить процессоры и взглянуть на предварительный просмотр данных и скрипт.
-
На панели свойств щелкните значок Изменить (
 ) рядом с именем процессора, чтобы дать ему более информативное имя, например Фильтр США, и добавить краткое описание, например Фильтрация по клиентам из США.
) рядом с именем процессора, чтобы дать ему более информативное имя, например Фильтр США, и добавить краткое описание, например Фильтрация по клиентам из США. -
В раскрывающемся списке Поле для обработки выберите COUNTRY (Страна).
-
В раскрывающемся списке Оператор выберите =.
-
В поле Использовать с выберите Значение и введите USA (США).
-
В списке Выберите строки, которые соответствуют, выберите Все фильтры.
Эти параметры более полезны при комбинировании нескольких фильтров.
-
Нажмите Применить.
Конфигурация процессора настроена правильно, но все еще отображается сообщение Не подключено, потому что у процессора пока нет выходного потока.
-
Щелкните Предварительный просмотр данных на нижней панели.
Взглянув на предварительный просмотр, можно увидеть, что на этом этапе остались только строки со страной USA (США) и они будут переданы в выходной поток. На данный момент поток данных должен выглядеть следующим образом:
Добавление названий штатов из другого набора данных
В случае с оставшимися клиентами из США поле STATE (ШТАТ) содержит штат происхождения, но в виде двухбуквенного кода. Лучше сделать эту информацию более удобной для чтения, в идеале ― с полным названием штата.
Набор данных states.xlsx, ранее импортированный в качестве источника, содержит список всех штатов США с двухбуквенными кодами, а также соответствующими полными названиями. Необходимо выполнить соединение этих двух наборов данных, чтобы извлечь названия штатов и дополнить основной поток.

Для соединения выполните следующие действия.
-
Щелкните меню действий (
) процессора Filter (Фильтр) и выберите Добавить процессор в соответствующую ветку > Соединить. -
Присвойте процессору новое имя Полные названия штатов, щелкнув значок Изменить (
) на панели свойств. -
Подключите источник states к нижней точке привязки процессора Join (Соединить). Чтобы создать ссылку, щелкните точку справа от узла источника и, удерживая, перетащите ссылку на нижнюю точку слева от узла процессора.

-
В раскрывающемся списке Тип соединения выберите Левое внешнее соединение.
-
В раскрывающемся списке Левый ключ выберите поле STATE (ШТАТ).
-
В раскрывающемся списке Правый ключ выберите поле Abbreviation (Сокращение).
Два выделенных столбца содержат общую информацию и позволяют установить связь между двумя входными потоками. При левом внешнем соединении в основной поток добавляются только дополнительные поля из второго набора данных.
-
Нажмите Применить.

В конец набора данных добавлено новое поле State (Штат), содержащее полное название штата для каждого покупателя.
Переименование и перемещение полей
Сейчас существует несколько проблем с именованием и форматированием столбцов. Имена STATE (ШТАТ) и State (Штат) слишком похожи и сбивают с толку, и два поля находятся слишком далеко друг от друга. Чтобы улучшить согласованность и единообразие данных, можно использовать процессор Select fields (Выбрать поля) для переименования и перемещения полей.
-
Щелкните меню действий (
) процессора Join (Соединить) и выберите Добавить процессор > Выбрать поля. -
Подключите процессор Join (Соединить) к процессору Select fields (Выбрать поля).

-
Присвойте процессору новое имя Реорганизовать поля штатов, нажав значок Изменить (
) на панели свойств. -
Отметьте Выбрать все, чтобы сохранить в потоке все поля.
-
Наведите курсор на поля, которые нужно переименовать, и щелкните значок
Изменить, чтобы отредактировать имена названия двух полей следующим образом:-
STATE (ШТАТ) как STATECODE (КОД_ШТАТА)
-
State (Штат) как STATENAME (НАЗВАНИЕ_ШТАТА)
-
-
Используйте значок =, чтобы перетащить новый столбец STATENAME (НАЗВАНИЕ_ШТАТА) и расположить его рядом со столбцом STATECODE (КОД_ШТАТА).
-
Нажмите Применить.
Поля переупорядочены, и поток данных выглядит следующим образом:

Преобразование имен клиентов в верхний регистр
Чтобы выделить фамилии клиентов и легче отличать их от имен, мы воспользуемся простой функцией форматирования процессора Strings (Строки), чтобы преобразовать фамилии в верхний регистр.
-
Щелкните меню действий (
) процессора Select fields (Выбрать поля) и выберите Добавить процессор > Strings (Строки). -
Подключите процессор Select fields (Выбрать поля) к процессору Strings (Строки).

-
Присвойте процессору новое имя Верхний регистр, щелкнув значок Изменить (
) на панели свойств. -
В раскрывающемся списке Имя функции выберите Изменить на верхний регистр.
-
В раскрывающемся списке Поля для обработки выберите CONTACTLASTNAME (ФАМИЛИЯ_КОНТАКТА).
-
Нажмите Применить.

Добавление цели и запуск потока данных
Основные этапы подготовки выполнены, и теперь можно завершить работу над потоком данных, настроив способ экспорта полученных данных. В этом сценарии вы выполните экспорт подготовленных данных в виде файла .qvd, сохраненного непосредственно в вашем каталоге, что позволит впоследствии удобно работать с ним, например, в аналитическом приложении.
-
Щелкните меню действий (
) процессора Strings (Строки) и выберите Добавить цель > Файлы данных. -
Подключите процессор Strings (Строки) к Цели файлов данных.

-
Присвойте процессору новое имя Цель QVD, щелкнув значок Изменить (
) на панели свойств. -
В раскрывающемся списке Пространство выберите Личное.
-
В поле Имя файла введите tutorial_output (выходные_данные_учебного_пособия).
-
В раскрывающемся списке Расширение выберите .qvd.
-
Нажмите Применить.
Теперь поток данных завершен и действителен, о чем свидетельствует состояние в полосе заголовка и зеленые галочки под каждым источником, процессором и целевым узлом.

-
Нажмите кнопку Запустить поток в правом верхнем углу окна.
Откроется модальное окно, в котором отображается ход выполнения.

Через некоторое время окно закроется, и появится уведомление о результате выполнения: успешно или нет. Выходные данные потока данных теперь можно найти в каталоге или в разделе Выходные данные на панели Обзор потока данных.
Дальнейшие действия
Вы научились импортировать исходные данные в каталог, строить простой поток данных для фильтрации и улучшения данных, а также экспортировать результат подготовки данных в виде готового к использованию файла.
Чтобы узнать о многочисленных способах использования потока данных в конкретных сценариях, ознакомьтесь с полным списком Процессоры потоков данных, где описаны предлагаемые функции.
Чтобы узнать, как использовать подготовленные данные в аналитических приложениях, см. раздел Создание аналитики и визуализация данных.