Bienvenue dans Qlik Cloud
Qlik Cloud rapproche étroitement les données, les informations analytiques et les actions grâce à l'intelligence active fournie par la seule solution complète pour l'intégration et l'analyse des données.
Présentation de Qlik Cloud
Qlik Cloud est une plateforme cloud d'analyse et d'intégration de données conçue pour l'intelligence active. Elle propose des services d'analyse et d'intégration de données pouvant être utilisés de manière conjointe ou indépendante.

Démarrage et options d'apprentissage
La documentation technique Qlik contient des exemples, des didacticiels et des solutions de dépannage pour tous les niveaux de compétences et pour toutes les étapes de votre parcours.

Présentation de l'interface
Lorsque vous vous connectez à Qlik Cloud pour la première fois, vous trouverez des didacticiels et des démos qui vous aideront à démarrer.

Qlik Cloud Government
Qlik Cloud Government est différent de l'offre Qlik Cloud commerciale de Qlik. Il inclut les protocoles de sécurité nécessaires pour la compatibilité avec le secteur public américain, et il est agréé aux niveaux FedRAMP Moderate Impact Level (IL) et Department of Defense (DOD) IL2.
Analyse des données
Qlik Cloud Analytics offre des fonctionnalités d'analyse modernes pour une gamme complète d'utilisateurs et de scénarios d'utilisation, des analyses en libre-service aux tableaux de bord et applications interactifs, en passant par les analyses conversationnelles, la traçabilité et le catalogage de métadonnées, les analyses mobiles, la génération de rapports et le lancement d'alertes.

Utilisation des analyses pour explorer les données
Utilisez des applications et des visualisations pour obtenir une vue d'ensemble de vos données. Vous pouvez prendre des décisions informées et effectuer des découvertes en observant les relations dans vos données.

Création d'analyses et visualisation de données
Créez des analyses et des visualisations de données puissantes. Les applications que vous créez établissent les bases qui permettent aux utilisateurs d'applications de visualiser les données et de faire des découvertes.

Chargement et modélisation des données analytiques
Commencez par ajouter vos sources de données, chargez les données dans votre application et commencez à modéliser votre modèle de données.

Fourniture de données et traçabilité à des fins d'analyse
Options de chargement des données de traçabilité et sur site dans votre client Qlik Cloud.

Apprentissage automatique avec Qlik Predict
L'apprentissage automatique automatisé recherche des modèles dans vos données et les utilise pour prédire des données futures.
Intégration de données
Qlik Talend Cloud permet le déplacement et la transformation de données en temps réel et propose des produits de données avec Qlik Talend Data Integration. De plus, Qlik Talend Cloud inclut les fonctionnalités de Talend pour la coordination des données, la qualité des données, l'intégration d'applications et d'autres fonctionnalités.

Présentation de l'intégration de données
Créez des pipelines de données pour effectuer une variété de tâches d'intégration de données afin de répondre à vos besoins d'architecture de données et d'analyse. Vous pouvez également rationaliser la gestion de vos données à l'aide de produits de données.

Qu'est-ce que Qlik Talend Cloud
Davantage de fonctionnalités d'intégration de données de Talend sont incluses dans les niveaux supérieurs de Qlik Talend Cloud. Cela inclut les fonctionnalités de coordination des données, de qualité des données, d'intégration d'applications et d'autres fonctionnalités.

Vidéos Intégration de données
Pour bien démarrer avec l'intégration de données, regardez quelques brèves vidéos.
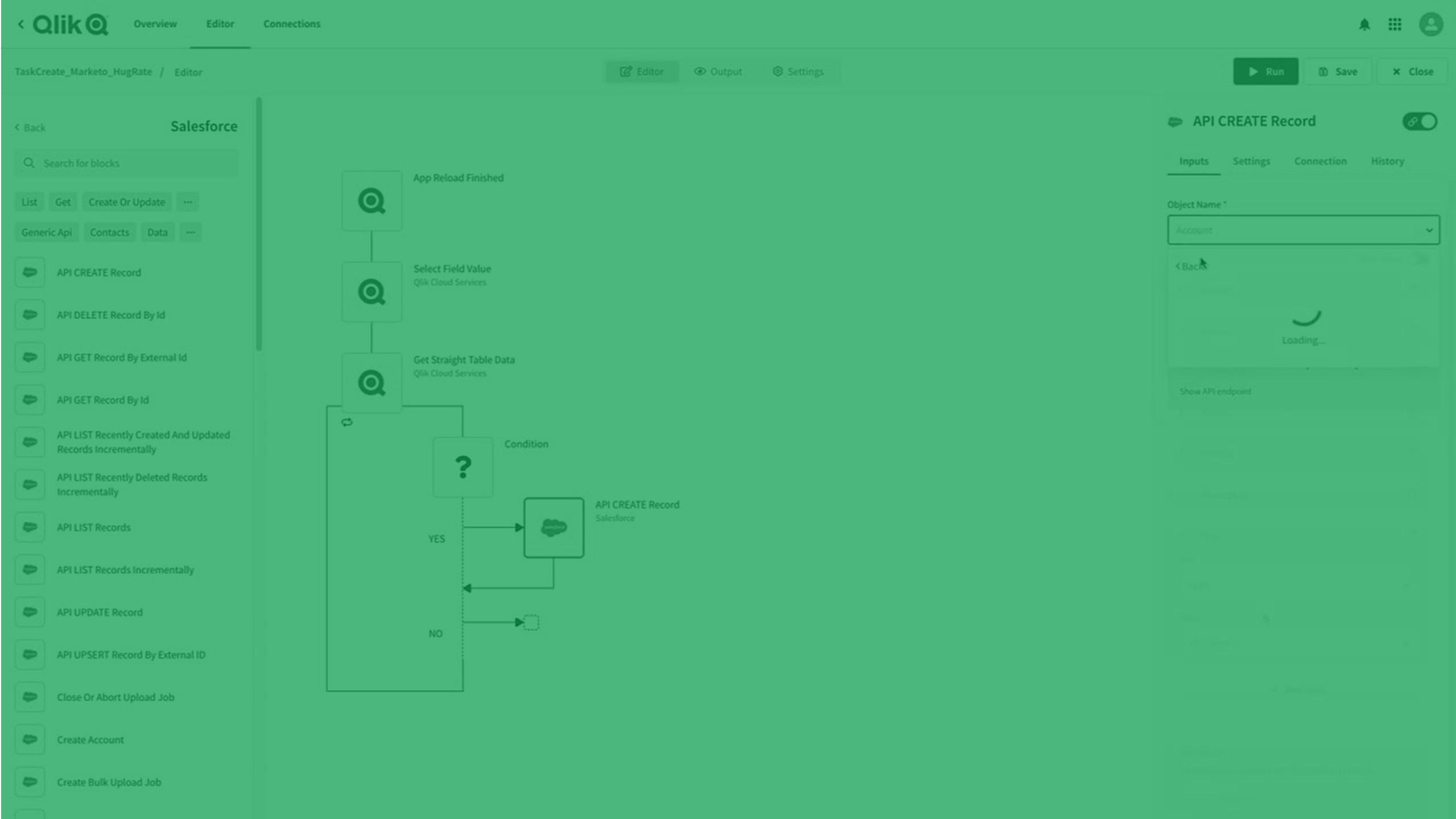
Création d'automatisations
Qlik Automate fournit une interface visuelle sans code qui vous permet de créer facilement des flux de travail analytiques et de données automatisés.
Une automatisation est une séquence d'actions et de déclencheurs qui s'exécute comme un programme. Elles peuvent se composer d'un workflow simple collectant des informations d'une application et les passant à une autre, ou d'un pipeline de bout en bout prenant des données brutes et les transférant à une intelligence active. Qlik Automate vous permet d'automatiser votre environnement analytique, de créer des flux de travail orientés données et d'inclure des données et des analyses dans vos processus métier.
Administration
Les administrateurs sont chargés de déployer, de configurer et de gérer l'abonnement et l'environnement Qlik Cloud. L'environnement Qlik Cloud offre une gestion et une gouvernance centralisées et permet de garantir l'adoption par les utilisateurs, l'exactitude et la fiabilité du système.

Planification de votre déploiement Qlik Cloud
Pour planifier correctement votre déploiement Qlik Cloud, vous devez tenir compte de facteurs tels que la répartition géographique de votre entreprise, les déploiements existants, la sécurité, la capacité et la manière dont vous souhaitez gérer votre environnement et votre abonnement Qlik Sense.

Déploiement Qlik Cloud
Pour déployer Qlik Cloud, suivez un ensemble standard d'étapes de haut niveau, notamment l'enregistrement, la configuration du système, l'ajout d'utilisateurs et la configuration des processus de gestion.

Gestion de Qlik Cloud
L'environnement Qlik Cloud offre une gestion et une gouvernance centralisées et permet de garantir l'adoption par les utilisateurs, l'exactitude et la fiabilité du système. L'administration du client implique la gestion des utilisateurs et des ressources, des paramètres de sécurité et de l'administration générale du système.
Développement d'analyses et d'intégrations de données
Utilisez les API et les outils Qlik Cloud pour générer, développer et déployer des applications axées sur les données personnalisées. Vous pouvez également générer des applications Web hybrides, créer des applications et des visualisations à la volée ou encore incorporer des analyses riches et intéressantes dans des applications.
Migration vers Qlik Cloud
Consultez le Centre de migration pour permettre aux utilisateurs et aux administrateurs de se familiariser rapidement avec Qlik Cloud. Que vous passiez de QlikView ou de Qlik Sense Enterprise Client-Managed à Qlik Cloud Analytics ou de Stitch à Qlik Talend Cloud, le Centre de migration fournit des conseils sur le processus et les meilleures pratiques lors de la transition vers le nouvel environnement.
Autres solutions Qlik
Si vous recherchez de l'aide avec les solutions Qlik Client-Managed (sur site), voici quelques liens directs vers d'autres systèmes d'aide Qlik.
- QlikView
- Qlik Sense Enterprise on Windows (utilisateurs)
- Qlik Sense Enterprise on Windows (administrateurs) (uniquement en anglais)
- Qlik Sense Enterprise on Windows (Développeurs) (uniquement en anglais)
- Qlik NPrinting
- Qlik Replicate (uniquement en anglais)
- Qlik Compose (uniquement en anglais)
Pour consulter la documentation sur les solutions Qlik Client-Managed, accédez à la page d'accueil Aide de Qlik.