
Gestion des jeux de données
Vous pouvez gérer les jeux de données inclus dans les tâches de données Dépôt temporaire, Stockage, Transformation, Datamart Dépôt temporaire de flux, Transformation de flux et Réplication pour créer des transformations, filtrer les données et ajouter des colonnes.
Les jeux de données inclus sont répertoriés sous Jeux de données dans la vue Conception. Vous pouvez sélectionner les colonnes à afficher grâce au sélecteur de colonnes (![]() ).
).
Jeux de données dans la vue Conception d'une tâche de données

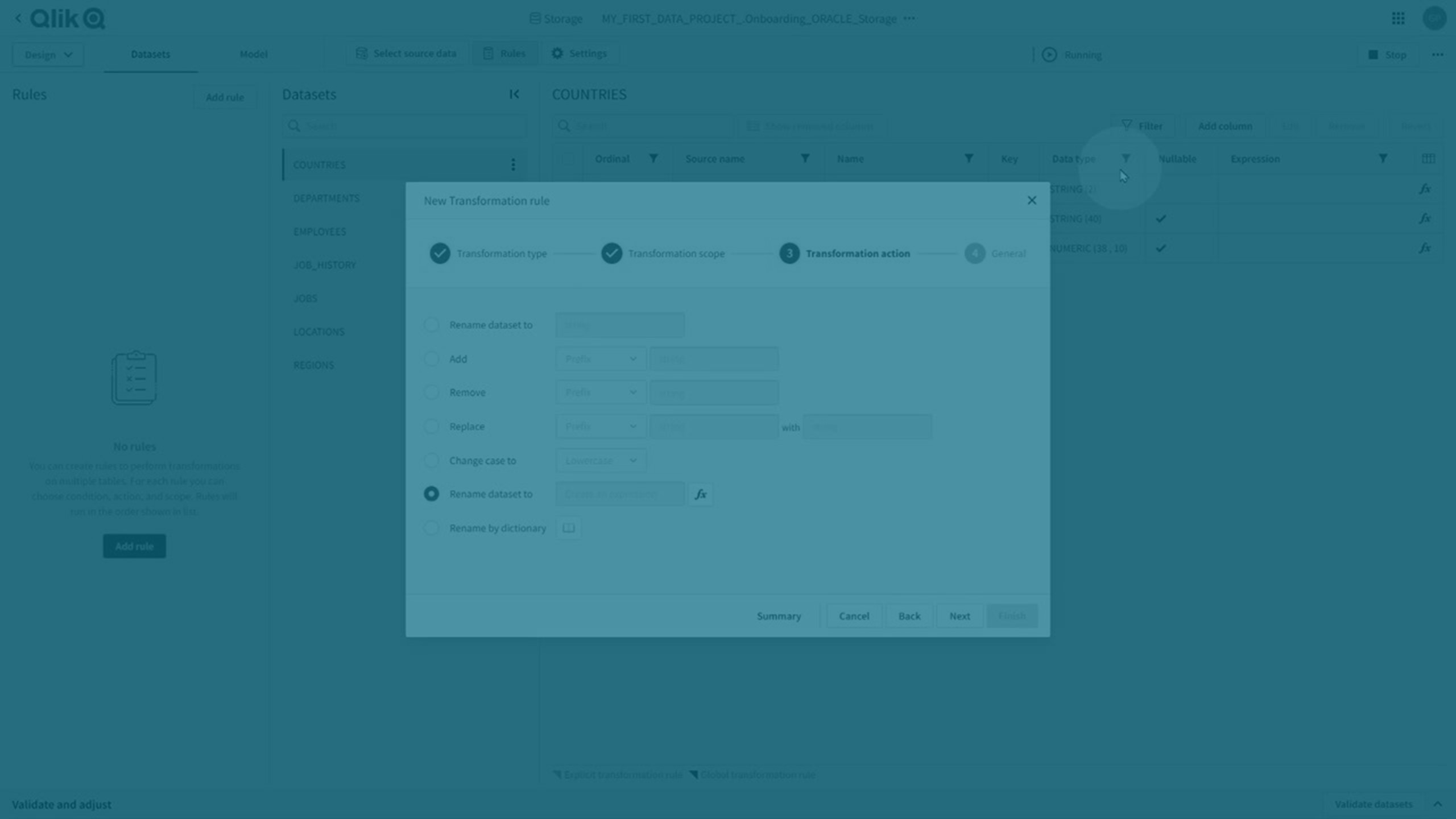
Règles de transformation et transformations explicites
Vous pouvez effectuer des transformations globales et explicites.
Règles de transformation
Vous pouvez effectuer des transformations globales en créant une règle de transformation qui utilise % comme caractère générique dans l'étendue pour permettre son application dans tous les jeux de données correspondants.
-
Cliquez sur Règles puis sur Ajouter une règle pour créer une règle de transformation.
Pour plus d'informations, consultez Création de règles pour transformer des jeux de données.
Les règles de transformation sont indiquées par un coin violet foncé sur l'attribut affecté.
Transformations explicites
Des transformations explicites sont créées :
-
lorsque vous utilisez Modifier pour changer un attribut de colonne ;
-
lorsque vous utilisez Renommer dans un jeu de données ;
-
lorsque vous ajoutez une colonne.
Les transformations explicites remplacement les transformations globales et elles sont indiquées par un coin violet clair au niveau de l'attribut affecté.
Modèles de jeu de données
Les jeux de données peuvent être basés sur la source ou sur la cible, suivant le type de tâche et les opérations de la tâche. Le modèle de jeu de données utilisé affecte le comportement du pipeline lors des modifications de la source et les opérations que vous pouvez effectuer.
-
Jeux de données basés sur la source
Le jeu de données est basé sur des jeux de données sources et ne contiendra que les modifications apportées aux métadonnées. Une modification des données sources est automatiquement appliquée, ce qui peut entraîner des modifications dans toutes les tâches en aval. Il n'est pas possible de modifier l'ordre des colonnes ni de modifier le jeu de données source.
Les types de tâche suivants utilisent toujours un modèle de jeu de données basé sur la source : Dépôt temporaire, Stockage, Données enregistrées, Réplication et Dépôt temporaire dans un lac de données.
-
Jeux de données basés sur la cible
Le jeu de données est basé sur les métadonnées cibles. Si une colonne est ajoutée depuis la source, ou si elle est retirée, cette modification n'est pas automatiquement appliquée à la tâche en aval suivante. Vous pouvez modifier l'ordre des colonnes et le jeu de données source. Cela signifie que la tâche est plus autonome et qu'elle vous permet de contrôler l'effet des modifications apportées à la source.
Les types de tâche suivants peuvent utiliser un modèle de jeu de données basé sur la cible : Transformer, Datamart. Dans certains cas, un modèle basé sur la source est utilisé pour les tâches Transformer en fonction de l'opération.
-
Si un flux de transformation ou une transformation SQL effectue une sélection de colonne, le jeu de données sera basé sur la cible. Par exemple, si vous utilisez SELECT A, B, C from XYZ dans une transformation SQL, ou si vous utilisez le processeur Sélectionner des colonnes dans un flux de transformation.
-
Si les colonnes par défaut sont conservées, le jeu de données est basé sur la source. Par exemple, si vous utilisez SELECT * from XYZ dans une transformation SQL.
-
Mise à jour des projets d'un modèle basé sur la source vers un modèle basé sur la cible
Les projets existants sont mis à jour en fonction du modèle de jeu de données basé sur la cible, le cas échéant. Nous vous guiderons tout au long du processus de mise à jour lors de la première ouverture d'un projet. Certaines considérations doivent être prises en compte lors de l'import et de l'export de projets avec des modèles de jeu de données différents.
-
Il n'est pas possible d'importer un projet dont le modèle est basé sur la source dans un projet dont le modèle est basé sur la cible.
Importez le projet avec un modèle basé sur la source dans un nouveau projet, mettez le nouveau projet à jour, puis exportez le projet obtenu. Vous pouvez ensuite réimporter ce projet dans le projet avec un modèle basé sur la cible.
-
Il n'est pas possible d'importer un projet dont le modèle est basé sur la cible dans un projet dont le modèle est basé sur la source.
Mettez le projet à jour vers un modèle basé sur la cible avant d'importer un projet avec un modèle basé sur la cible.
Filtrage d'un jeu de données
Vous pouvez filtrer des données pour créer un sous-ensemble de lignes, si nécessaire.
-
Cliquez sur Filtrer.
Pour plus d'informations, consultez Filtrage d'un jeu de données.
Renommer un jeu de données
Vous pouvez renommer un jeu de données.
-
Cliquez sur
 sur un jeu de données, puis sur Modifier.
sur un jeu de données, puis sur Modifier.
Ajouter des colonnes
Vous pouvez ajouter des colonnes avec des transformations au niveau de la ligne, si nécessaire.
-
Cliquez sur Ajouter une colonne.
Pour plus d'informations, consultez Ajout de colonnes à un jeu de données.
Modifier une colonne
Vous pouvez modifier les propriétés de colonne en sélectionannt une colonne et en cliquant sur Modifier.
-
Nom
-
Clé
Définissez une colonne comme clé primaire. Vous pouvez également définir des clés en sélectionnant ou désélectionnant la colonne Clé.
-
Peut être nul
-
Data type (Type de données)
Définissez le type de données de la colonne. Pour certains types de données, vous pouvez définir une propriété supplémentaire, par exemple Longueur.
Note InformationsLorsque vous modifiez le type de données ou la taille de type de données d'une colonne, cela peut avoir des conséquences sur les tâches qui utilisent le jeu de données. Pour plus d'informations, consultez Gestion des types de données.
Suppression de colonnes
Vous pouvez supprimer une ou plusieurs colonnes d'un jeu de données.
-
Sélectionnez les colonnes à supprimer et cliquez sur Supprimer.
Si vous voulez voir les colonnes supprimées, cliquez sur Afficher les colonnes supprimées. Les colonnes supprimées sont indiquées par un texte barré. Pour récupérer une colonne supprimée, sélectionnez-la et cliquez sur Rétablir.
Rétablissement des changements explicites dans les colonnes
Vous pouvez rétablir tous les changements explicites dans une ou plusieurs colonnes.
-
Sélectionnez les colonnes dans lesquelles vous voulez rétablir les changements et cliquez sur Rétablir.
Les changements provenant de règles de transformation globales ne sont pas rétablies.
Si vous annulez une colonne ajoutée, elle est supprimée.
Paramètres du jeu de données
Vous pouvez modifier les paramètres du jeu de données. Le paramètre par défaut consiste à reprendre le paramètre de la tâche de données. Toutefois, vous pouvez également modifier un paramètre pour qu'il ait explicitement la valeur Activé ou Désactivé.
-
Cliquez sur
 au niveau d'un jeu de données puis sur Paramètres.
au niveau d'un jeu de données puis sur Paramètres.
Affichage des colonnes d'en-tête dans les vues
Pour les tâches de dépôt temporaire et de transformation de flux Qlik Open Lakehouse, vous pouvez choisir d'afficher ou de masquer les colonnes d'en-tête. Les options varient en fonction du type de tâche.
Tâche de dépôt temporaire de flux
Pour afficher les colonnes d'en-tête, activez Afficher les colonnes d'en-tête à droite de la zone de recherche.
Tâche de transformation de flux
Une liste déroulante contenant les options suivantes est disponible à droite de la zone de recherche.
-
Masquer les colonnes d'en-tête : valeur par défaut.
-
Afficher les colonnes d'en-tête
-
Standard : sélectionnez cette option pour afficher les colonnes d'en-tête des vues standards.
-
Historique : sélectionnez cette option pour afficher les colonnes d'en-tête des vues Historique. Notez que cette option ne sera disponible que si Créer un data store historique (Type 2) est activé dans les paramètres de la tâche ou du jeu de données.
-
Pour une description des colonnes d'en-tête disponibles, consultez Les tables de dépôt temporaire. et Vues.
Visualisation des données
Vous pouvez afficher un échantillon des données pour voir et valider la forme de vos données à mesure que vous concevez votre pipeline de données.
Les conditions suivantes doivent être remplies :
-
L'affichage des données est activé au niveau du client dans le centre d'activités Administration.
Pour l'activer, accédez à la page Paramètres, sélectionnez l'onglet Contrôle de fonction et activez l'option Affichage des données dans Intégration de données.
-
Vous êtes titulaire du rôle Peut afficher des données dans l'espace dans lequel réside la connexion.
-
Vous êtes titulaire du rôle Accès en lecture dans l'espace dans lequel réside le projet.
Affichage de l'échantillon de données
Pour afficher un échantillon de données dans l'onglet Jeux de données de la vue Conception :
-
Cliquez sur Afficher les données.
Un échantillon des données apparaît. Vous pouvez définir le nombre de lignes de données à inclure dans l'échantillon dans Nombre de lignes.
Comprendre la structure des données
L'aperçu des données affiche à la fois les colonnes métier et les colonnes générées par le système. Lors de la visualisation de données provenant de jeux de données de flux, les colonnes d'en-tête (préfixées de hdr__) fournissent des métadonnées sur la source de données et les transformations. Les exemples incluent hdr__from_timestamp (lorsque les données ont été chargées) et hdr__operation (type d'opération appliqué).
Les colonnes d'en-tête sont en lecture seule et ne peuvent pas être modifiées ni supprimées de l'aperçu. Pour contrôler les en-têtes qui s'affichent par défaut, configurez les en-têtes de vue standard au niveau du projet ou du jeu de données.
Passage des jeux de données à des tables
Pour passer des jeux de données à des tables :
-
Sélectionnez Jeux de données pour afficher la représentation logique des données.
-
Sélectionnez Objets physiques pour afficher la représentation physique dans la base de données sous forme de tables et de vues.
Note ActualitésCette option n'est pas disponible si la représentation physique n'a pas encore été créée.
Filtrage
Vous pouvez filtrer l'échantillon de données de deux manières différentes :
-
Utilisez
 pour filtrer l'échantillon de données à récupérer.
pour filtrer l'échantillon de données à récupérer.Par exemple, si vous appliquez le filtre ${OrderYear}>2023 et si Nombre de lignes est défini sur 10, vous obtiendrez un échantillon de 10 commandes en 2024.
-
Filtrez l'échantillon de données en fonction d'une colonne spécifique.
Cela affectera uniquement l'échantillon de données existant. Si vous avez utilisé
pour inclure uniquement des commandes de 2024 et si vous avez défini le filtre de colonne pour afficher des commandes de 2022, vous obtiendrez un échantillon vide.
Tri
Vous pouvez également trier l'échantillon de données en fonction d'une colonne spécifique. Le tri affectera uniquement l'échantillon de données existant. Si vous avez utilisé ![]() pour inclure uniquement des commandes de 2024 et si vous inversez l'ordre de tri, l'échantillon de données continuera à ne contenir que des commandes de 2024.
pour inclure uniquement des commandes de 2024 et si vous inversez l'ordre de tri, l'échantillon de données continuera à ne contenir que des commandes de 2024.
Masquage des colonnes
Vous pouvez masquer des colonnes dans la vue des données :
-
Masquez une seule colonne en cliquant sur
sur la colonne, puis sur Masquer colonne. -
Masquez plusieurs colonnes en cliquant sur
sur n'importe quelle colonne, puis sur Afficher les colonnes. Cela vous permet de contrôler la visibilité de l'ensemble des colonnes de la vue.
Téléchargement de l'échantillon de données
Vous pouvez télécharger l'échantillon de données affiché :
-
Cliquez sur
 pour télécharger le contenu de la vue de l'échantillon de données.
pour télécharger le contenu de la vue de l'échantillon de données.
L'échantillon de données est téléchargé sous forme de fichier CSV dans les téléchargements de votre navigateur.
Validation et ajustement des jeux de données
Vous pouvez valider tous les jeux de données inclus dans la tâche de données.
Développez Valider et ajuster pour voir toutes les erreurs de validation et les changements de conception.
Validation des jeux de données
-
Cliquez sur Valider les jeux de données pour valider les jeux de données.
La validation implique de vérifier que :
-
Toutes les tables ont une clé primaire.
-
Il ne manque pas d'attributs.
-
Il n'y a pas de doublons de nom de table ou de colonne.
Vous obtenez également une liste des modifications apportées à la conception par rapport à la source :
-
Tables et colonnes ajoutées
-
Tables et colonnes abandonnées
-
Tables et colonnes renommées
-
Clés primaires et types de données modifiés
Développez Valider et ajuster pour voir toutes les erreurs de validation et les changements de conception.
-
Corrigez les erreurs de validation puis validez à nouveau les jeux de données.
-
L’adaptation de la plupart des changements de conception peut s'effectuer automatiquement, sauf pour les clés primaires et les types de données modifiés. Dans ce cas, vous devez synchroniser les jeux de données.
Préparation des jeux de données
Vous pouvez préparer les ensembles données pour ajuster les changements de conception sans perte de données, si possible. En cas de changements de conception impossibles à ajuster sans perte de données, vous aurez la possibilité de recréer les tables à partir de la source avec perte de données.
Cette opération implique l'arrêt de la tâche.
-
Cliquez sur
 , puis sur Préparer.
, puis sur Préparer.
Une fois les jeux de données préparés, validez-les avant de redémarrer la tâche de stockage.
Recréation des jeux de données
Vous pouvez recréer les jeux de données depuis la source. Lorsque vous recréez un jeu de données, cela entraînera une perte de données. Si vous avez les données source, vous pouvez les charger depuis la source.
Cette opération implique l'arrêt de la tâche.
-
Cliquez sur
, puis sur Recréer les tables.
Téléchargement des données de validation
Vous pouvez télécharger les données à partir de Erreurs de validation, de Modifications apportées à la conception et de Progression de la préparation :
-
Cliquez sur
pour télécharger.
Les données sont téléchargées sous forme de fichier CSV dans les téléchargements de votre navigateur.
Limitations
-
Dans Google BigQuery, la suppression ou l'attribution d'un nouveau nom à une colonne implique la recréation de la table et entraîne la perte des données.