
Replikationseinstellungen
Sie können Einstellungen für die Datenreplikationsaufgabe konfigurieren.
-
Öffnen Sie die Replikationsaufgabe und klicken Sie in der Symbolleiste auf Einstellungen.
Das Dialogfeld Einstellungen: <Aufgaben-Name> wird geöffnet. Die verfügbaren Einstellungen werden unten beschrieben.
Allgemein
Auf dieser Registerkarte können Sie den Replikationsmodus, die Bereitstellungseinstellungen (falls verfügbar), den Modus für das Anwenden der Änderungen auf das Ziel und die Veröffentlichungseinstellungen ändern.
Replikationsmodus
Die folgenden Replikationsmodi sind verfügbar:
-
Vollständiger Ladevorgang: Lädt die Daten aus den ausgewählten Quelltabellen in die Zielplattform und erstellt bei Bedarf die Zieltabellen. Vollständiges Laden findet automatisch statt, wenn die Aufgabe gestartet wird, kann aber bei Bedarf auch manuell durchgeführt werden. Manuelles vollständiges Laden ist z. B. erforderlich, wenn Sie Aktualisierungen an Ansichten replizieren müssen (die während CDC nicht erfasst werden) oder wenn Sie aus einer Datenquelle replizieren, die CDC nicht unterstützt.
InformationshinweisBei Verwendung eines SaaS-Anwendungs-Konnektors ist diese Option immer aktiviert, da ein vollständiges Laden erforderlich ist. -
Änderungen anwenden: Aktualisiert die Zieltabellen fortlaufend mit allen an den Quelltabellen vorgenommenen Änderungen.
-
Änderungen speichern: Speichert die Änderungen an den Quelltabellen in Änderungstabellen (eine pro Quelltabelle).
Weitere Informationen finden Sie unter Änderungen speichern.
Bei der Arbeit mit Data Movement Gateway, außer bei der Verwendung von SaaS-Anwendungsquellen, werden Änderungen von der Quelle nahezu in Echtzeit erfasst. Bei der Arbeit ohne Data Movement Gateway (beispielsweise mit einem Qlik Talend Cloud Starter-Abonnement oder wenn Keine ausgewählt wurde) oder bei der Verwendung von SaaS-Anwendungsquellen werden Änderungen entsprechend den Scheduler-Einstellungen erfasst. Weitere Informationen finden Sie unter Scheduling tasks.
Wenn Sie Änderungen speichern oder Änderungen anwenden auswählen und Ihre Datenquelle:
-
Ist keine SaaS-Anwendung
-
Enthält Datensätze, die CDC unterstützen, und Datensätze, die nur vollständiges Laden unterstützen (wie Ansichten)
Zwei Datenpipelines werden erstellt. Eine pipeline wird für Tabellen erstellt, die CDC unterstützen, und eine weitere für Datasets, die nur vollständiges Laden unterstützen.
Lademethode
Bei der Replikation an Snowflake können Sie eine der folgenden Lademethoden wählen:
-
Massenladen (die Standardmethode)
Wenn Sie Massenladen wählen, können Sie die Details der Ladeparameter auf der Registerkarte Daten hochladen angeben.
-
Snowpipe Streaming
InformationshinweisSnowpipe Streaming kann nur ausgewählt werden, wenn die folgenden Bedingungen erfüllt sind:
- Der Replikationsmodus Änderungen speichern ist ohne Änderungen anwenden aktiviert.
- Der Authentifizierungsmechanismus im Snowflake-Konnektor ist auf Schlüsselpaar festgelegt.
- Wenn Sie Data Movement Gateway verwenden, ist Version 2024.11.45 oder höher erforderlich.
Wenn Sie die Snowpipe Streaming auswählen, müssen Sie sich unbedingt mit den Einschränkungen und Überlegungen für diese Methode vertraut machen. Wenn Sie außerdem Snowpipe Streaming auswählen und dann den Replikationsmodus Änderungen anwenden aktivieren oder Änderungen speichern deaktivieren, wird die Lademethode automatisch wieder auf Massenladen umgestellt.
Die wichtigsten Gründe für eine Auswahl von Snowpipe Streaming anstelle von Massenladen sind:
-
Kostengünstiger: Da Snowpipe Streaming nicht das Snowflake Warehouse verwendet, dürften die Betriebskosten deutlich niedriger ausfallen. Dies hängt jedoch vom jeweiligen Anwendungsfall ab.
-
Geringere Latenz: Da die Daten direkt an die Zieltabellen (und nicht bereitgestellt) werden, sollte die Replikation von der Datenquelle an das Ziel schneller verlaufen.
Verbindung zu einem Bereitstellungsbereich
Wenn die Replikation an die unten aufgelisteten Data Warehouses erfolgt, müssen Sie einen Bereitstellungsbereich einrichten. Die Daten werden im Bereitstellungsbereich verarbeitet und vorbereitet, bevor sie an das Warehouse übertragen werden.
Wählen Sie entweder einen vorhandenen Bereitstellungsbereich aus oder klicken Sie auf Neu erstellen, um einen neuen Bereitstellungsbereich zu definieren, und befolgen Sie die Anleitungen in Verbinden mit Cloud-Speicher.
Um die Verbindungseinstellungen zu bearbeiten, klicken Sie auf Bearbeiten. Um die Verbindung zu testen (empfohlen), klicken Sie auf Verbindung testen.
Weitere Informationen dazu, welche Bereitstellungsbereiche für welche Data Warehouses unterstützt werden, finden Sie in der Spalte Als Bereitstellungsbereich unterstützt in Zielplattform-Anwendungsfälle und unterstützte Versionen.
Modus „Änderungen anwenden“
Änderungen werden mit einer der folgenden Methoden auf die Zieltabellen angewendet:
- Stapeloptimiert: Dies ist die Standardeinstellung. Wenn diese Option ausgewählt ist, werden Änderungen in Stapeln angewendet. Es wird eine Vorverarbeitung ausgeführt, um die Transaktionen auf die effizienteste Weise in Stapeln zu gruppieren.
- Transaktional: Wählen Sie diese Option aus, um jede Transaktion einzeln in der Reihenfolge des Commit anzuwenden. In diesem Fall ist strikte referenzielle Integrität für alle Tabellen gewährleistet.
Veröffentlichungseinstellungen
-
In Katalog veröffentlichen
Wählen Sie diese Option aus, um diese Version der Daten als Datensatz im Katalog zu veröffentlichen. Der Kataloginhalt wird aktualisiert, wenn Sie diese Aufgabe zum nächsten Mal vorbereiten.
Weitere Informationen zu Katalog finden Sie unter Verstehen Ihrer Daten mit Katalogwerkzeugen.
Proxy-Einstellungen bei Verwendung von Data Movement Gateway
-
Bei Verwendung des Data Movement Gateway eine Verbindung über den Proxy herstellen mit
Bei Verwendung von Data Movement Gateway können Sie über einen Proxy eine Verbindung zur Zielplattform und zur Staging-Plattform (Bereich) herstellen.
Weitere Informationen zum Konfigurieren von Data Movement Gateway für die Verwendung eines Proxy-Servers finden Sie unter Festlegen des Qlik Cloud Mandanten und eines Proxy-Servers.
-
Zielplattform
InformationshinweisVerfügbar bei Verwendung von Snowflake und Databricks. -
Bereitstellungsplattform
InformationshinweisVerfügbar bei Verwendung von Google BigQuery, Amazon Redshift, Microsoft Fabric und Databricks.
-
Daten hochladen
Diese Registerkarte wird nur angezeigt, wenn an ein Data Warehouse oder ein Kafka-Ziel repliziert wird. Zusätzlich unterscheiden sich die Einstellungen in dieser Registerkarte je nach dem ausgewählten Ziel.
Relevant für alle Data Warehouse-Ziele
Maximale Dateigröße
Die maximale Größe, die eine Datei erreichen kann, bevor sie geschlossen wird. Kleinere Dateien könnten (abhängig vom Netzwerk) schneller hochgeladen werden und die Leistung verbessern, wenn diese Möglichkeit zusammen mit der parallelen Ausführungsoption verwendet wird. Generell wird aber davon abgeraten, die Datenbank mit kleinen Dateien zu überfüllen.
Nur für Snowflake-Ziel relevant
Auf der Registerkarte Allgemein können Sie wählen, ob Sie die Daten über Massenladen oder Snowpipe Streaming in Snowflake laden möchten. Wenn Snowpipe Streaming ausgewählt ist, wird die Registerkarte Daten hochladen nicht angezeigt. Wenn Sie Massenladen wählen, stehen Ihnen die folgenden Einstellungen zur Verfügung:
-
Maximale Dateigröße (MB): Relevant für die anfängliche Full Load und CDC. Die maximale Größe, die eine Datei erreichen kann, bevor sie ins Ziel geladen wird. Wenn Sie Leistungsprobleme feststellen, kann die Anpassung dieses Parameters Abhilfe schaffen.
-
Anzahl der Dateien, die in einem Stapel geladen werden sollen: Relevant nur für den initialen vollständigen Ladevorgang. Die Anzahl der Dateien, die in einem einzigen Stapel geladen werden sollen. Wenn Sie Leistungsprobleme feststellen, kann die Anpassung dieses Parameters Abhilfe schaffen.
Eine Beschreibung der Lademethoden Massenladen und Snowpipe Streaming finden Sie unter Allgemein.
Nur für Kafka-Ziel relevant
Nachrichteneigenschaften
Komprimierung
Wählen Sie optional eine der verfügbaren Komprimierungsmethoden (Snappy oder Gzip) aus. Standard ist Keine.
Veröffentlichung von Datennachrichten
Wählen Sie eine der folgenden Optionen für Daten veröffentlichen in aus:
- Spezifisches Thema: Veröffentlicht die Daten in einem einzelnen Thema. Geben Sie entweder einen Themennamen ein oder verwenden Sie die Schaltfläche „Durchsuchen“, um das gewünschte Thema auszuwählen.
-
Separates Thema für jede Tabelle: Veröffentlicht die Daten in mehreren Themen, die den Namen der Quelltabellen entsprechen.
Der topic-Zielname besteht aus dem Quellschemanamen und dem Quelltabellennamen, getrennt durch einen Punkt (zum Beispiel dbo.Employees). Das Format des topic-Zielnamens ist wichtig, da Sie diese topics im Voraus vorbereiten müssen.
Wenn die Themen nicht existieren, konfigurieren Sie die Broker mit auto.create.topics.enable=true, damit die Datenaufgabe die Themen zur Laufzeit erstellen kann. Andernfalls schlägt die Aufgabe fehl.
Informationen zum Überschreiben dieser Einstellung auf Datensatzebene finden Sie unter Überschreiben von Aufgabeneinstellungen für einzelne Datensätze beim Veröffentlichen in Kafka
Nachrichtenschlüssel
Wählen Sie eine der verfügbaren Optionen aus.
-
Primärschlüsselspalten: Für jede Nachricht enthält der Nachrichtenschlüssel den Wert der Primärschlüsselspalte.
Wenn Nach Nachrichtenschlüssel als Partitionsstrategie ausgewählt ist, werden Nachrichten, die denselben Primärschlüsselwert enthalten, in dieselbe Partition geschrieben.
-
Schema- und Tabellenname: Für jede Nachricht enthält der Nachrichtenschlüssel eine Kombination aus Schema- und Tabellennamen (zum Beispiel dbo+Employees).
Wenn Nach Nachrichtenschlüssel als Partitionsstrategie ausgewählt ist, werden Nachrichten, die denselben Schema- und Tabellenname enthalten, in dieselbe Partition geschrieben.
- Keine: Erstellt Nachrichten ohne Nachrichtenschlüssel.
Informationen zum Überschreiben dieser Einstellung auf Datensatzebene finden Sie unter Überschreiben von Aufgabeneinstellungen für einzelne Datensätze beim Veröffentlichen in Kafka
Partitionsstrategie
Wählen Sie entweder Zufällig oder Nach Nachrichtenschlüssel aus. Wenn Sie Zufällig auswählen, wird jede Nachricht in eine zufällig ausgewählte Partition geschrieben. Wenn Sie Nach Nachrichtenschlüssel auswählen, werden Nachrichten basierend auf dem ausgewählten Nachrichtenschlüssel in Partitionen geschrieben (wie oben beschrieben).
Veröffentlichung von Metadatennachrichten
Benennungsstrategie für Subjects
Die erste Strategie (Schema- und Tabellenname) ist eine proprietäre Qlik Strategie, während die anderen drei Standard-Benennungsstrategien für Confluent-Subjects sind.
Wählen Sie eine der verfügbaren Subject-Benennungsstrategien aus.
- Schema- und Tabellenname (Standard)
- Name des Themas
- Datensatzname
- Themen- und Datensatzname
Weitere Informationen zu den Benennungsstrategien für Confluent-Subjects Benennungsstrategie für Subjects.
Subject-Kompatibiltätsmodus
Wählen Sie einen der folgenden Kompatibilitätsmodi aus der Dropdown-Liste Subject-Kompatibilitätsmodus aus:
-
Standardeinstellungen der Schemaregistrierung verwenden: Ruft die Kompatibilitätsstufe aus der Serverkonfiguration der Schemaregistrierung ab.
-
Abwärts - Nur neuestes Schema: Neue Schemata können nur entsprechende Daten lesen, sowie Daten, die vom zuletzt registrierten Schema generiert wurden.
-
Rückwärts transitiv – Alle vorherigen Schemata: Neue Schemata können Daten lesen, die von allen zuvor registrierten Schemata generiert wurden.
-
Vorwärts - Nur neuestes Schema: Das zuletzt registrierte Schema kann Daten lesen, die vom neuen Schema generiert wurden.
-
Vorwärts transitiv – Alle vorherigen Schemata: Alle zuvor registrierten Schemata können Daten lesen, die vom neuen Schema generiert wurden.
-
Vollständig - Nur neuestes Schema: Das neue Schema ist rückwärts- und vorwärtskompatibel mit dem zuletzt registrierten Schema.
-
Voll transitiv – Alle vorherigen Schemata: Das neue Schema ist rückwärts- und vorwärtskompatibel mit allen zuvor registrierten Schemata.
-
Keine
- Abhängig von der ausgewählten Benennungsstrategie für Subjects sind einige der Kompatibilitätsmodi möglicherweise nicht verfügbar.
-
Beim Veröffentlichen von Nachrichten in einer Schemaregistrierung ist der standardmäßige Subject-Kompatibilitätsmodus für alle neu erstellten Kontrolltabellen-Subjects Keine, unabhängig vom ausgewählten Subject-Kompatibilitätsmodus.
Wenn Sie möchten, dass der ausgewählte Subject-Kompatibilitätsmodus auch für Kontrolltabellen gilt, setzen Sie den internen Parameter setNonCompatibilityForControlTables im Kafka-Zielkonnektor auf false.
Einen Proxy zum Herstellen einer Verbindung zur Confluent Schema Registry verwenden
Diese Option wird nur beim Veröffentlichen in der Confluent-Schemaregistrierung unterstützt.
Aktivieren Sie diese Option, wenn Ihr Data Movement Gateway für die Verwendung eines Proxyservers konfiguriert ist.
Nachrichtenattribute
Sie können benutzerdefinierte Nachrichtenattribute angeben, die die Standard-Nachrichtenattribute überschreiben. Dies ist nützlich, wenn die Nutzeranwendung die Nachricht in einem bestimmten Format verarbeiten muss.
Benutzerdefinierte Nachrichtenattribute können sowohl auf Aufgaben- als auch auf Tabellenebene definiert werden. Wenn die Attribute sowohl auf Aufgaben- als auch auf Tabellenebene definiert sind, haben die für die Tabelle definierten Nachrichtenattribute Vorrang vor den für die Aufgabe definierten.
Informationen zum Überschreiben der Nachrichtenattribute auf Datensatzebene finden Sie unter Überschreiben von Aufgabeneinstellungen für einzelne Datensätze beim Veröffentlichen in Kafka.
Hierarchisch strukturierte Nachrichten werden nicht unterstützt.
Allgemeine Regeln und Nutzungsrichtlinien
Beim Definieren einer benutzerdefinierten Nachricht ist es wichtig, die unten aufgeführten Regeln und Nutzungsrichtlinien zu beachten.
Abschnittsnamen
Die folgenden Benennungsregeln gelten:
- Abschnittsnamen müssen mit den Zeichen a-z, A-Z oder _ (Unterstrich) beginnen. Darauf können beliebige der folgenden Zeichen folgen: a-z, A-Z, 0-9, _
- Mit Ausnahme der Abschnitte Datensatzname und Schlüsselname (die nicht mit einem Schrägstrich enden), wird durch das Entfernen des Schrägstrichs aus Abschnittsnamen die Hierarchie des zugehörigen Abschnitts abgeflacht (siehe Schrägstriche unten).
- Alle Abschnittsnamen außer Datensatzname und Schlüsselname können gelöscht werden (siehe Löschung unten)
-
Die Abschnittsnamen Datenname und Vor-Daten des Datensatzes einbeziehen können nicht beide gelöscht werden.
-
Die Abschnittsnamen Datenname und Vor-Daten des Datensatzes einbeziehen dürfen nicht gleich sein.
Einige der Abschnittsnamen in der Benutzeroberfläche enden mit einem Schrägstrich (z. B. beforeData/beforeData/). Der Zweck des Schrägstrichs ist es, eine Hierarchie der verschiedenen Abschnitte innerhalb der Nachricht aufrechtzuerhalten. Wenn der Schrägstrich entfernt wird, geschieht Folgendes:
- Die hierarchische Struktur dieses Abschnitts wird abgeflacht, wodurch der Abschnittsname aus der Nachricht entfernt wird.
- Der Abschnittsname wird den tatsächlichen Metadaten vorangestellt, entweder direkt oder unter Verwendung eines Trennzeichens (z. B. eines Unterstrichs), das Sie an den Namen angehängt haben.
Beispiel einer Datennachricht, wenn headers/ mit einem Schrägstrich angegeben wird:
"message":{
"data":{
"COL1": "159",
"COL2": "159"
},
"beforeData": null,
"headers": {
"operation": "INSERT",
"changeSequence": "2018100811484900000000233",
Beispiel einer Datennachricht, wenn headers_ mit einem Unterstrich anstelle eines Schrägstrichs angegeben wird:
"message":{
"data":{
"COL1": "159",
"COL2": "159"
},
"beforeData": null,
"headers_operation": "INSERT",
"headers_changeSequence": "2018100811484900000000233",
Durch Löschen eines Abschnittsnamens aus der Nachricht wird die hierarchische Struktur dieses Abschnitts abgeflacht. Dies führt dazu, dass alle Daten dieses Abschnitts unmittelbar unter dem Inhalt des vorhergehenden Abschnitts angezeigt werden.
Beispiel einer Datennachricht mit dem Abschnittsnamen headers :
"message":{
"data":{
"COL1": "159",
"COL2": "159"
},
"headers": {
"operation": "INSERT",
"changeSequence": "2018100811484900000000233",
Beispiel einer Datennachricht ohne den Abschnittsnamen headers :
"message":{
"data":{
"COL1": "159",
"COL2": "159"
},
"beforeData": null,
"operation": "INSERT",
"changeSequence": "2018100811484900000000233",
Variablen
Sie können Variablen zu Namen hinzufügen, indem Sie am Ende der Zeile auf die Schaltfläche ![]() klicken. Die folgenden Variablen sind verfügbar:
klicken. Die folgenden Variablen sind verfügbar:
- SERVER_NAME – Der Hostname des Data Movement Gateway Servers
- TARGET_TABLE_NAME – Der Name der Tabelle
- TARGET_TABLE_OWNER – Der Tabellenbesitzer
- TASK_NAME – Der Name der Datenaufgabe.
Die Variable TARGET_TABLE_OWNER ist für die Optionen Datensatzname und Schlüsselname nicht verfügbar (wie in der folgenden Tabelle beschrieben).
Definieren von benutzerdefinierten Nachrichtenattributen
Um ein benutzerdefiniertes Nachrichtenformat zu definieren, aktivieren Sie Benutzerdefinierte Einstellungen verwenden und konfigurieren Sie die Optionen wie in der folgenden Tabelle beschrieben.
Um zu den Standard-Nachrichtenattributen zurückzukehren, deaktivieren Sie Benutzerdefinierte Einstellungen verwenden.
| Option | Beschreibung |
|---|---|
|
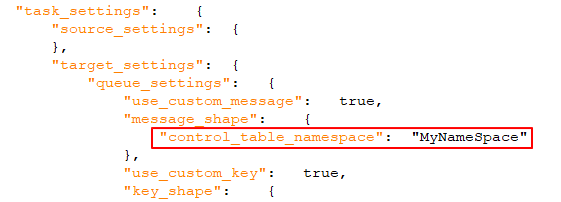
Wenn aktiviert (Standardeinstellung), wird eine eindeutige Kennung in die Nachricht eingeschlossen. Dies sollte ein durch Punkte getrennter String sein. Beachten Sie, dass der Namespace sowohl in die Nachricht als auch in den Nachrichtenschlüssel eingeschlossen wird. Beispiel: mycompany.queue.msg Standardname: com.attunity.queue.msg.{{TASK_NAME}}.{{TARGET_TABLE_OWNER}}.{{TARGET_TABLE_NAME}} Standardname für Kontrolltabellen: com.attunity.queue.msg.{{TARGET_TABLE_NAME}} Informationshinweis
Der Standard-Namespace für Kontrolltabellen kann nicht über die Benutzeroberfläche geändert werden. Sie können den Standard-Namespace für Kontrolltabellen jedoch wie folgt ändern:
|
|
|
Datensatzname |
Der Name des Datensatzes (Nachricht). Standardname: DataRecord |
|
Datenname |
Alle im Datensatz enthaltenen Datenspalten. Standardname: data/ |
|
Kopfzeilen einschließen |
Wenn aktiviert (Standardeinstellung), werden Header-Spalten in die Nachricht eingeschlossen. Header-Spalten liefern zusätzliche Informationen über die Quellvorgänge. Weitere Informationen finden Sie unter „Folgende Header einschließen“ unten. |
|
Namespace der Kopfzeile einbeziehen |
Wenn aktiviert (Standardeinstellung), wird eine eindeutige Kennung für den Header-Spaltenabschnitt in die Nachricht eingeschlossen. Dies sollte ein durch Punkte getrennter String sein. Beispiel: headers.queue.msg Standardname: com.attunity.queue.msg |
|
Kopfzeilenname |
Der Name des Abschnitts, der die Qlik Spalten-Header enthält. Standardname: headers/ |
|
Eine Beschreibung der verfügbaren Header-Spalten finden Sie unter Datennachrichten in der Qlik-Hilfe. Standard: Alle Spalten sind standardmäßig enthalten, mit Ausnahme der Spalte Externe Schema-ID. |
|
|
Vor-Daten des Datensatzes einbeziehen |
Wenn aktiviert (Standardeinstellung), werden sowohl Vor- als auch Nach-UPDATE-Daten in UPDATE-Nachrichten eingeschlossen. Um nur die Nach-UPDATE-Daten in Nachrichten aufzunehmen, deaktivieren Sie die Option. Standardname: beforeData/ |
|
Schlüsselname |
Der Name des Abschnitts, der den Nachrichtenschlüssel enthält. Standardname: keyRecord Diese Option ist nur in folgenden Fällen anwendbar:
|
Zusätzliche Einstellungen
-
Maximale Nachrichtengröße
Geben Sie im Feld Maximale Nachrichtengröße die maximale Größe der Nachrichten an, die Broker empfangen sollen (message.max.bytes). Die Datenaufgabe sendet keine Nachrichten, die größer sind als die maximale Größe.
Metadaten
Standard
-
Zieltabellenschema
Das Schema des Ziels, in das alle Quelltabellen repliziert werden, wenn Sie nicht das Quelltabellenschema verwenden möchten, bzw. wenn die Quelldatenbank kein Schema enthält.
InformationshinweisBeim Replizieren an ein Oracle-Ziel ist das Standard-Zieltabellenschema „system“. Beachten Sie auch Folgendes: Wenn Sie dieses Feld leer lassen (in welchem Fall das Quellschema verwendet wird), müssen Sie sich vergewissern, dass das Quellschema bereits im Ziel vorhanden ist. Andernfalls schlägt die Aufgabe fehl.InformationshinweisDie maximal zulässige Länge des Schemanamens ist 128 Zeichen.
JSON-Spaltenzuordnung
Kompatible JSON-Spalten der Quelle den JSON-Spalten auf dem Ziel zuordnen
-
Wenn Sie Data Movement Gateway für den Zugriff auf Ihre Datenquelle nutzen, benötigen Sie Version 2024.11.70 oder höher.
Wenn diese Option aktiviert ist, werden JSON-Spalten in der Quelle automatisch JSON-Spalten im Ziel zugeordnet.
Der Status und die Anzeige dieser Option wird von folgenden Faktoren bestimmt:
-
Neue Aufgaben: Diese Option ist standardmäßig aktiviert, wenn sowohl die Quelle als auch das Ziel den JSON-Datentyp unterstützen.
-
Bestehende Aufgaben: Diese Option ist standardmäßig deaktiviert, selbst wenn sowohl die Quelle als auch das Ziel den JSON-Datentyp unterstützen. Hierdurch wird die Abwärtskompatibilität mit nachgelagerten Prozessen beibehalten, wie z. B. Transformationen, die erwarten, dass die Zieldaten im STRING-Format vorliegen (dies entspricht dem vorherigen Verhalten). Sie können die Option entweder deaktiviert lassen oder die nachgelagerten Prozesse so bearbeiten, dass sie mit dem JSON-Format kompatibel sind und dann diese Option aktivieren.
-
Neue und bestehende Aufgaben: Wenn der JSON-Datentyp nur von der Quelle unterstützt wird, ist diese Option ausgeblendet. Wenn dem Ziel zu einem späteren Zeitpunkt JSON-Unterstützung hinzugefügt wird, wird die Option zwar angezeigt, bleibt aber deaktiviert. Hierdurch wird die Abwärtskompatibilität mit nachgelagerten Prozessen beibehalten, wie z. B. Transformationen, die erwarten, dass die Zieldaten im STRING-Format vorliegen (dies entspricht dem vorherigen Verhalten).
LOB-Einstellungen
Die verfügbaren LOB-Einstellungen variieren je nach dem ausgewählten Replikationsziel. Da Data Warehouse-Ziele keine unbegrenzte LOB-Spaltengröße unterstützen, ist diese Option nicht verfügbar, wenn an ein Data Warehouse repliziert wird.
LOB-Einstellungen für Ziele, die keine Data Warehouses sind
- LOB-Spalten nicht einschließen: Wählen Sie diese Option, wenn Sie die LOB-Quellspalten nicht replizieren möchten.
-
LOB-Spaltengröße beschränken auf (KB): Dies ist die Standardoption. Wählen Sie diese Option aus, wenn Sie nur kleine LOBs replizieren möchten oder wenn die Zielplattform keine unbegrenzte LOB-Größe unterstützt. Der maximal zulässige Wert für dieses Feld ist 102400 KB (100 MB).
Wenn kleine LOBs repliziert werden, ist diese Option effizienter als die Option LOB-Spaltengröße nicht beschränken, da die LOBs „inline“ repliziert werden, nicht per „lookup“ aus der Quelle. Während der Änderungsverarbeitung werden kleine LOBs in der Regel per „lookup“ aus der Quelle repliziert.
Die Beschränkung gilt für die Anzahl der LOB-Bytes, die vom Quell-Endpunkt gelesen werden. Bei BLOB-Spalten entspricht die Ziel-BLOB-Größe genau der angegebenen Beschränkung. Bei CLOB- und NCLOB-Spalten kann die Ziel-LOB-Größe von der angegebenen Beschränkung abweichen, wenn Quell- und Ziel-LOB nicht den gleichen Zeichensatz haben. In diesem Fall führt die Datenaufgabe eine Zeichensatzkonvertierung durch, was zu einer Diskrepanz zwischen der Größe des Quell- und des Ziel-LOBs führen kann.
Da der Wert der Option „LOB-Größe begrenzen auf“ in Byte angegeben wird, muss die Größe nach den folgenden Formeln berechnet werden:
- BLOB: Die Länge des größten LOB.
- NCLOB: Die Länge des längsten TEXT in Zeichen, multipliziert mit zwei (da Zeichen als Doppel-Byte verarbeitet werden). Wenn die Daten 4-Byte-Zeichen enthalten, multiplizieren Sie mit vier.
- CLOB: Die Länge des längsten TEXT in Zeichen (da Zeichen als UTF8-Zeichen verarbeitet werden). Wenn die Daten 4-Byte-Zeichen enthalten, multiplizieren Sie mit zwei.
Informationshinweis- Alle LOBs, die die angegebenen Größe überschreiten, werden abgeschnitten.
- Während der Änderungsverarbeitung aus einer Oracle-Quelle werden Inline-BLOBs inline repliziert.
- Änderungen an dieser Einstellung betreffen vorhandene Tabellen erst, nachdem diese neu geladen wurden.
-
LOB-Spaltengröße nicht begrenzen: Wenn diese Option ausgewählt ist, werden LOB-Spalten unabhängig von der Größe repliziert.
InformationshinweisDas Replizieren von LOB-Spalten kann die Leistung beeinträchtigen. Das gilt insbesondere für große LOB-Spalten, für die die Replikationsaufgabe ein Lookup in der Quelltabelle durchführen muss, um den LOB-Quellwert abzurufen.-
Optimieren, wenn die LOB-Größe kleiner ist als: Wählen Sie diese Option aus, wenn Sie sowohl kleine als auch große LOBs replizieren müssen und die meisten LOBs klein sind.
InformationshinweisDiese Option wird nur für die folgenden Quellen und Ziele unterstützt:
-
Quellen: Oracle, Microsoft SQL Server, MySQL, PostgreSQL und IBM DB2 for LUW
-
Ziele: Oracle, Microsoft SQL Server, MySQL, PostgreSQL.
Wenn diese Option während des vollständigen Ladens ausgewählt wird, werden die kleinen LOBs „inline“ repliziert (was effizienter ist), und die großen LOBs werden per Lookup in der Quelltabelle repliziert. Während der Änderungsverarbeitung werden jedoch sowohl kleine als auch große LOBs per Lookup in der Quelltabelle repliziert.
InformationshinweisWenn diese Option ausgewählt ist, prüft die Replikationsaufgabe alle LOB-Größen, um zu bestimmen, welche „inline“ übertragen werden. LOBs, die die angegebene Größe überschreiten, werden mit dem vollständigen LOB-Modus repliziert.
Wenn Sie daher wissen, dass die meisten LOBs größer als die angegebene Einstellung sind, sollte stattdessen die Option Replicate unbegrenzte LOB-Spalten verwendet werden.
-
-
Blockgröße (KB): Optional können Sie die Größe der LOB-Blöcke ändern, die beim Replizieren der Daten an das Ziel verwendet werden. Die Standardblockgröße sollte in den meisten Fällen genügen. Wenn jedoch Leistungsprobleme auftreten, kann durch Anpassen der Größe die Leistung verbessert werden.
InformationshinweisIn manchen Datenbanken werden Datentypen validiert, wenn die Daten eingefügt oder aktualisiert werden. In solchen Fällen, Replikation von strukturierten Datentypen (z. B. XML, JSON, GEOGRAPHY usw.) kann fehlschlagen, wenn die Daten größer als die angegebene Blockgröße sind.
-
LOB-Einstellungen für unterstützt Data Warehouse-Ziele
-
LOB-Spalten einbeziehen und Spaltengröße beschränken auf (KB):
Sie können sich entscheiden, LOB-Spalten in die Aufgabe einzuschließen, und die maximale LOB-Größe festlegen. LOBs, die die maximale Größe überschreiten, werden abgeschnitten.
Erweitert
Kontrolltabelleneinstellungen
-
Schema der Kontrolltabellen: Geben Sie das Zielschema für die Kontrolltabellen an, wenn Sie nicht möchten, dass diese im Quellschema (Standardeinstellung) oder im Zielschema erstellt werden.
InformationshinweisDie maximal zulässige Länge des Schemanamens ist 128 Zeichen. - Zielkontrolltabellen im Tablespace erstellen: Wenn das Replikationsziel Oracle ist, geben Sie den Tablespace an, in dem die Zielkontrolltabellen erstellt werden sollen. Wenn Sie in dieses Feld keine Informationen eingeben, werden die Tabellen im Standard-Tablespace in der Zieldatenbank erstellt.
- Indizes für Zielkontrolltabellen im Tablespace erstellen:Wenn das Replikationsziel Oracle ist, geben Sie den Tablespace an, in dem die Kontrolltabellenindizes erstellt werden sollen. Wenn Sie in dieses Feld keine Informationen eingeben, werden die Indizes im gleichen Tablespace wie die Kontrolltabellen erstellt.
- Zeitfenster für Replikationsverlauf (Minuten): Die Länge der einzelnen Zeitfenster in der Kontrolltabelle Replikationsverlauf. Der Standardwert ist 5 Minuten.
Kontrolltabellenauswahl
Wählen Sie die Kontrolltabellen aus, die auf der Zielplattform erstellt werden sollen:
| Logischer Name | Name in Ziel |
|---|---|
| Ausnahmen anwenden | attrep_apply_exceptions |
| Replikationsstatus | attrep_status |
| Ausgesetzte Tabellen | attrep_suspended_tables |
| Replikationsverlauf | attrep_history |
| DDL-Verlauf |
attrep_ddl_history Die Tabelle „DDL-Verlauf“ wird nur von den folgenden Zielplattformen unterstützt:
|
Weitere Informationen zu Kontrolltabellen finden Sie unter Kontrolltabellen.
Vollständiges Laden
Standard
Diese Einstellungen werden während der Vorbereitungsphase der Datenaufgabe und bei jedem Ladevorgang der Tabelle angewendet.
Wenn die Zieltabelle bereits existiert: Wählen Sie eine der folgenden Möglichkeiten, um festzulegen, wie die Daten in die Zieltabellen geladen werden sollen:
Die Option zum Löschen oder Abschneiden der Zieltabellen ist nur relevant, wenn diese Vorgänge vom Quellendpunkt unterstützt werden.
-
Tabelle löschen und erstellen: Die Zieltabelle wird gelöscht, und an ihrer Stelle wird eine neue Tabelle erstellt.
InformationshinweisDie Kontrolltabellen der Replikationsaufgabe werden nicht gelöscht. Alle ausgesetzten Tabellen, die gelöscht werden, werden aber auch aus der Kontrolltabelle attrep_suspended_tables gelöscht, wenn die zugeordnete Aufgabe neu geladen wird.
-
Vor Laden ABSCHNEIDEN: Die Daten werden abgeschnitten, ohne dass sich dies auf die Zieltabellenmetadaten auswirkt. Hinweis: Wenn diese Option ausgewählt wird, hat das Aktivieren der Option Primärschlüssel oder eindeutigen Index nach Abschluss des vollständigen Ladens erstellen keine Auswirkung.
InformationshinweisNicht unterstützt, wenn Microsoft Fabric die Zielplattform ist. - Ignorieren: Vorhandene Daten und Metadaten der Zieltabelle sind nicht betroffen. Neue Daten werden zur Tabelle hinzugefügt.
Erweitert
Leistungsfeinabstimmung
Wenn die Datenreplikation zu langsam verläuft, kann eine Anpassung der folgenden Parameter die Leistung verbessern.
- Maximale Anzahl Tabellen: Geben Sie die maximale Anzahl Tabellen ein, die gleichzeitig in das Ziel geladen werden können. Der Standardwert ist 5.o
-
Zeitüberschreitung für Transaktionseinheitlichkeit (Sekunden): Geben Sie die Anzahl der Sekunden ein, die die Replikationsaufgabe auf den Abschluss von offenen Transaktionen warten soll, bevor mit dem vollständigen Ladevorgang begonnen wird. Der Standardwert ist 600 (10 Minuten). Die Replikationsaufgabe beginnt mit dem vollständigen Laden, nachdem der Zeitüberschreitungswert erreicht ist, auch wenn offene Transaktionen vorhanden sind.
InformationshinweisUm Transaktionen zu replizieren, die beim Starten des vollständigen Ladens geöffnet waren, für die aber erst nach Erreichen des Zeitüberschreitungswerts ein Commit durchgeführt wurde, müssen Sie die Zieltabellen neu laden. - Commit-Rate beim vollständigen Laden: Die maximale Anzahl der Ereignisse, die gleichzeitig übertragen werden können. Der Standardwert ist 10000.
Nach Abschluss des vollständigen Ladens
Sie können festlegen, dass die Aufgabe nach Abschluss des vollständigen Ladens automatisch angehalten wird. Das ist nützlich, wenn Sie DBA-Vorgänge an den Zieltabellen durchführen müssen, bevor die Phase „Änderungen anwenden“ (d.h. CDC) Phase beginnt.
Während des vollständigen Ladens werden alle DML-Vorgänge, die in den Quelltabellen durchgeführt werden, zwischengespeichert. Nach Abschluss des vollständigen Ladens werden die zwischengespeicherten Änderungen automatisch auf die Zieltabellen angewendet (vorausgesetzt, die unten beschriebenen Optionen Vor/Nach Anwenden der zwischengespeicherten Änderungen sind deaktiviert).
-
Primärschlüssel oder eindeutigen Index erstellen: Wählen Sie diese Option aus, wenn Sie die Erstellung des Primärschlüssels oder des eindeutigen Index im Ziel bis nach dem Abschluss des vollständigen Ladens aufschieben möchten.
InformationshinweisDiese Einstellung ist für Aufgaben, die einen Konnektor einer SaaS-Anwendung verwenden, nicht verfügbar. - Aufgabe anhalten:
Informationshinweis
Diese Einstellungen sind nicht verfügbar, wenn an Data Warehouse-Ziele repliziert wird
-
Bevor zwischengespeicherte Änderungen angewendet werden: Wählen Sie diese Option aus, damit die Aufgabe nach Abschluss des vollständigen Ladens angehalten wird.
-
Nachdem zwischengespeicherte Änderungen angewendet wurden: Wählen Sie diese Option aus, damit die Aufgabe angehalten wird, sobald die Daten in allen Tabellen der Aufgabe einheitlich sind.
InformationshinweisWenn Sie konfigurieren, dass die Aufgabe nach Abschluss des vollständigen Ladens angehalten wird, beachten Sie Folgendes:
- Die Aufgabe wird nicht sofort angehalten, wenn das vollständige Laden abgeschlossen ist. Sie wird erst dann angehalten, nachdem der erste Satz Änderungen erfasst wurde (da dies das Anhalten der Aufgabe auslöst). Je nachdem, wie häufig die Quelldatenbank aktualisiert wird, kann dies eine Zeitlang dauern. Nach Anhalten der Aufgabe werden die Änderungen erst dann auf das Ziel angewendet, wenn die Aufgabe fortgesetzt wird.
- Wenn Sie Vor Anwenden der zwischengespeicherten Änderungen auswählen, kann sich dies auf die Leistung auswirken, da die zwischengespeicherten Änderungen erst auf die Tabellen angewendet werden (auch auf diejenigen, deren vollständiges Laden bereits abgeschlossen ist), nachdem das vollständige Laden der letzten Tabelle abgeschlossen ist.
- Wenn diese Option ausgewählt wird und ein DDL während des vollständigen Ladevorgangs in einer der Quelltabellen ausgeführt wird (in einer Aufgabe „Vollständiges Laden und Änderungen anwenden“), lädt die Replikationsaufgabe die Tabelle neu. Das bedeutet in der Praxis, dass alle in den Quelltabellen ausgeführten DML-Vorgänge im Ziel repliziert werden, bevor die Aufgabe angehalten wird.
-
Für den anfänglichen Ladevorgang
| Zwischengespeicherte Daten verwenden |
Mit dieser Option können Sie zwischengespeicherte Daten verwenden, die bei der Erzeugung von Metadaten mit ausgewählter Option Vollständiger Datenscan gelesen wurden. Dadurch ist weniger Aufwand für API-Nutzung und -Kontingente nötig, da die Daten bereits von der Quelle gelesen wurden. Etwaige Änderungen seit dem anfänglichen Datenscan können von Change Data Capture (CDC) festgestellt werden. |
| Daten aus Quelle laden |
Mit dieser Option wird ein neuer Ladevorgang von der Datenquelle durchgeführt. Diese Option ist nützlich, wenn:
|
Änderungen anwenden
Diese Einstellungen sind nur verfügbar, wenn der Replikationsmodus Änderungen anwenden aktiviert ist.
Standard
Typ der DDL-Änderungen auswählen, der auf das Ziel angewendet werden soll
Die folgenden Optionen bestimmen, ob DDL-Vorgange, die in der Quelltabelle ausgeführt werden, auch in der zugehörigen Zieltabelle ausgeführt werden.
-
Tabelle löschen: Wählen Sie die Option, um die Zieltabelle zu löschen, wenn die Quelltabelle gelöscht wird.
InformationshinweisWird nicht unterstützt, wenn Kafka die Zielplattform ist. -
Tabelle kürzen: Wählen Sie die Option, um die Zieltabelle zu kürzen, wenn die Quelltabelle gekürzt wird.
InformationshinweisNicht unterstützt, wenn Microsoft Fabric die Zielplattform ist. -
Tabelle ändern: Wählen Sie die Option, um die Zieltabelle zu verändern, wenn die Quelltabelle verändert wird.
InformationshinweisDas Umbenennen einer Tabelle wird nicht unterstützt, wenn Kafka die Zielplattform ist.
Feinabstimmung der Änderungsverarbeitung
-
Stapeländerungen gleichzeitig auf mehrere Tabellen anwenden: Die Auswahl dieser Option könnte die Leistung verbessern, wenn Änderungen aus mehreren Quelltabellen angewendet werden.
InformationshinweisDiese Option wird nur in folgenden Fällen unterstützt:
- Der Modus „Änderungen anwenden“ ist auf Stapeloptimiert festgelegt. Weitere Informationen finden Sie unter Replikationseinstellungen.
- Die Replikationsziele sind nicht MySQL, PostgreSQL, Oracle und Google BigQuery.
-
Maximale Anzahl von Tabellen: Die maximale Anzahl der Tabellen, auf die Stapeländerungen gleichzeitig angewendet werden. Der Standardwert ist fünf, der Höchstwert 50 und der Mindestwert zwei.
Wenn die Option Stapeländerungen gleichzeitig auf mehrere Tabellen anwenden aktiviert ist, gelten die folgenden Einschränkungen:
-
Die Aufgabenfehlerbehandlungs-Richtlinie bleibt unverändert für Fehler der Kategorien Umgebungsbezogen und Tabelle, aber die Standardwerte für die Fehlerkategorien Daten und Anwendungskonflikte lauten wie folgt:
- Datenfehler:
- Datenabschneidefehler: Datensatz in Ausnahmetabelle protokollieren
- Andere Datenfehler: Tabelle aussetzen
- Anwendungskonfliktfehler:
- Löscht: Datensatz ignorieren
Einfügungen: Vorhandenen Zieldatensatz AKTUALISIEREN
InformationshinweisDies ist für ein Snowflake-Ziel nicht relevant (da Snowflake keine Primärschlüssel unterstützt).- Updates: Datensatz ignorieren
- Eskalierungsaktion:
- Die Eskalierungsaktion sowohl für Daten-Fehler als auch für Anwendungskonflikte wird nicht unterstützt.
- Die Kontrolltabelle attrep_apply_exception wird nicht unterstützt.
- Für Datenfehler:
- Die Option Datensatz in Ausnahmetabelle protokollieren ist nur für Datenabschneidefehler verfügbar.
- Es ist keine Option Ignorieren vorhanden.
- Für Anwendungskonflikte:
- Die Option Datensatz in Ausnahmetabelle protokollieren ist nicht verfügbar.
Die Option Ignorieren ist nur für den Anwendungskonflikt Kein Datensatz für die Anwendung einer AKTUALISIERUNG gefunden verfügbar.
- Datenfehler:
Siehe auch: Fehlerbehandlung.
-
-
Anzahl der pro Änderungsverarbeitungsbefehl angewendeten Änderungen begrenzen auf: Um die Anzahl der pro Änderungsverarbeitungsbefehl angewendeten Änderungen zu begrenzen, aktivieren Sie dieses Kontrollkästchen und ändern Sie dann optional den Standardwert. Der Standardwert ist 10,000.
InformationshinweisDiese Option wird nur mit den folgenden Zielen unterstützt: MySQL, PostgreSQL, Oracle und Google BigQuery.
Erweitert
Siehe Feinabstimmung der Änderungsverarbeitung.
Änderungen speichern
Diese Einstellungen sind nur verfügbar, wenn der Replikationsmodus Änderungen speichern aktiviert ist.
Standard
DDL-Optionen
Wählen Sie eine der folgenden Optionen aus, um zu bestimmen, wie mit DDL-Vorgängen in den Quelltabellen verfahren wird:
- Auf Änderungstabelle anwenden: DDL-Vorgänge an den Quelltabellen (z. B. das Hinzufügen einer Spalte) werden nur auf die entsprechende Änderungstabelle angewendet.
- Ignorieren: Alle DDL-Vorgänge an Quelltabellen werden ignoriert.
Erweitert
Bei Aktualisierung
Wählen Sie Vor und nach Image speichern aus, um sowohl die Daten vor als auch nach dem UPDATE zu speichern. Wenn die Option nicht ausgewählt wird, werden nur die Daten nach dem UPDATE gespeichert.
Änderungstabellenerstellung
Im folgenden Abschnitt werden die verfügbaren Optionen beschrieben, wenn Änderungen in Änderungstabellen gespeichert werden.
- Suffix: Geben Sie einen String an, der als Suffix für alle Änderungstabellen verwendet werden soll. Der Standardwert ist __ct. Die Namen der Änderungstabellen sind der Name der Zieltabelle mit angehängtem Suffix. Wenn Sie beispielsweise den Standardwert verwendet, lautet der Name der Änderungstabelle HR__ct.
- Präfix der Kopfzeilenspalte: Geben Sie einen String an, der als Präfix für alle Kopfzeilenspalten der Änderungstabellen verwendet werden soll. Der Standardwert ist header__. Beispiel: Wenn der Standardwert verwendet wird, lautet der Name der Kopfzeilenspalte stream_position header__stream_position.
Weitere Informationen zu Änderungstabellen finden Sie unter Verwenden von Änderungstabellen.
Wenn Änderungstabelle beim Start des vollständigen Ladens vorhanden ist: Wählen Sie eine der folgenden Optionen aus, um zu bestimmen, wie die Änderungstabellen geladen werden, wenn die Replikation mit vollständigem Laden startet:
- Änderungstabelle löschen und erstellen: Die Tabelle wird gelöscht, und an ihrer Stelle wird eine neue Tabelle erstellt.
-
Alte Änderungen löschen und neue Änderungen in vorhandener Änderungstabelle speichern: Die Daten werden abgeschnitten und hinzugefügt, ohne dass sich dies auf die Tabellenmetadaten auswirkt.
InformationshinweisNicht unterstützt, wenn Microsoft Fabric die Zielplattform ist. - Alte Änderungen beibehalten und neue Änderungen in vorhandener Änderungstabelle speichern: Daten und Metadaten der vorhandenen Änderungstabelle sind nicht betroffen.
Tabellenkopfzeilenspalten
Die Kopfzeilenspalten der Änderungstabelle enthalten Informationen zu Änderungsverarbeitungsvorgängen, wie den Typ des Vorgangs (z. B. INSERT), die Commit-Uhrzeit usw. Wenn Sie diese Informationen nicht alle benötigen, können Sie die verschieben-Aufgabe so konfigurieren, dass die Änderungstabellen mit ausgewählten Kopfzeilenspalten (oder ohne Kopfzeilenspalten) erstellt werden, was ihren Speicherbedarf in der Zieldatenbank reduziert.
Eine Beschreibung der Kopfzeilenspalten finden Sie unter Änderungstabellen.
Fehlerbehandlung
Standard
Anwendungskonflikte
Doppelter Schlüssel beim Anwenden von INSERT: Wählen Sie, welche Aktion durchgeführt werden soll, wenn ein Konflikt bei einem INSERT-Vorgang besteht.
-
Ignorieren: Die Aufgabe wird fortgesetzt und der Fehler wird ignoriert.
-
Vorhandenen Zieldatensatz AKTUALISIEREN: Der Zieldatensatz mit dem gleichen Primärschlüssel wie der EINGEFÜGTE Quelldatensatz wird aktualisiert.
- Datensatz in Ausnahmetabelle protokollieren (Standard): Die Aufgabe wird fortgesetzt und der Fehler wird in die Ausnahmetabelle geschrieben.
-
Tabelle aussetzen: Die Aufgabe wird fortgesetzt, aber die Daten aus der Tabelle mit dem Fehlerdatensatz werden in einen Fehlerzustand verschoben, und ihre Daten werden nicht repliziert.
- Aufgabe anhalten: Die Aufgabe wird angehalten und ein manueller Eingriff ist erforderlich.
Kein Datensatz für die Anwendung eines UPDATE gefunden: Wählen Sie, welche Aktion durchgeführt werden soll, wenn ein Konflikt bei einem UPDATE-Vorgang besteht.
- Ignorieren: Die Aufgabe wird fortgesetzt und der Fehler wird ignoriert.
-
Fehlenden Zieldatensatz EINFÜGEN: Der fehlende Zieldatensatz wird in die Zieltabelle eingefügt. Wenn der Quellendpunkt Oracle ist, muss bei Auswahl dieser Option ergänzende Protokollierung für alle Quelltabellenspalten aktiviert sein.
- Datensatz in Ausnahmetabelle protokollieren (Standard): Die Aufgabe wird fortgesetzt und der Fehler wird in die Ausnahmetabelle geschrieben.
-
Tabelle aussetzen: Die Aufgabe wird fortgesetzt, aber die Daten aus der Tabelle mit dem Fehlerdatensatz werden in einen Fehlerzustand verschoben, und ihre Daten werden nicht repliziert.
- Aufgabe anhalten: Die Aufgabe wird angehalten und ein manueller Eingriff ist erforderlich.
Erweitert
Die Datenfehlerbehandlung wird nur im Replikationsmodus „Änderungen anwenden“ unterstützt (nicht bei vollständigem Laden).
Datenfehler
Für Datenabschneidefehler: Wählen Sie aus, was geschehen soll, wenn ein Abschneiden in einem oder mehreren spezifischen Datensätzen auftritt. Sie können eine der folgenden Optionen aus der Liste auswählen:
- Ignorieren: Die Aufgabe wird fortgesetzt und der Fehler wird ignoriert.
- Datensatz in Ausnahmetabelle protokollieren (Standard): Die Aufgabe wird fortgesetzt und der Fehler wird in die Ausnahmetabelle geschrieben.
- Tabelle aussetzen: Die Aufgabe wird fortgesetzt, aber die Daten aus der Tabelle mit dem Fehlerdatensatz werden in einen Fehlerzustand verschoben, und ihre Daten werden nicht repliziert.
- Aufgabe anhalten: Die Aufgabe wird angehalten, und ein manueller Eingriff ist erforderlich.
Für andere Datenfehler: Wählen Sie aus, was geschehen soll, wenn ein Fehler in einem oder mehreren spezifischen Datensätzen auftritt. Sie können eine der folgenden Optionen aus der Liste auswählen:
- Ignorieren: Die Aufgabe wird fortgesetzt und der Fehler wird ignoriert.
- Datensatz in Ausnahmetabelle protokollieren (Standard): Die Aufgabe wird fortgesetzt und der Fehler wird in die Ausnahmetabelle geschrieben.
- Tabelle aussetzen: Die Aufgabe wird fortgesetzt, aber die Daten aus der Tabelle mit dem Fehlerdatensatz werden in einen Fehlerzustand verschoben, und ihre Daten werden nicht repliziert.
- Aufgabe anhalten: Die Aufgabe wird angehalten, und ein manueller Eingriff ist erforderlich.
Fehlerbearbeitung eskalieren, wenn andere Datenfehler (pro Tabelle) die folgende Anzahl erreichen: Aktivieren Sie dieses Kontrollkästchen, um die Fehlerbearbeitung zu eskalieren, wenn die Anzahl der anderen Datenfehler (keine Datenabschneidung) pro Tabelle die angegebene Anzahl erreicht. Gültige Werte sind 1-10.000.
Eskalierungsaktion: Wählen Sie aus, was geschehen soll, wenn die Fehlerbearbeitung eskaliert wird. Beachten Sie, dass die verfügbaren Aktionen von der Aktion abhängen, die aus der oben beschriebenen Dropdown-Liste Für andere Datenfehler ausgewählt wurde.
-
Tabelle aussetzen (Standard): Die Aufgabe wird fortgesetzt, aber die Daten aus der Tabelle mit dem Fehlerdatensatz werden in einen Fehlerzustand verschoben, und die Daten werden nicht verschoben.
InformationshinweisDas Verhalten ist je nach Änderungsverarbeitungsmodus unterschiedlich:
-
Im Modus Transaktional anwenden werden die letzten Änderungen nicht verschoben.
-
Im Modus Stapeloptimierte Anwendung ist eine Situation möglich, in der die Daten gar nicht verschoben oder nur teilweise verschoben werden.
-
- Aufgabe anhalten: Die Aufgabe wird angehalten, und ein manueller Eingriff ist erforderlich.
- Datensatz in Ausnahmetabelle protokollieren: Die Aufgabe wird fortgesetzt und der Datensatz wird in die Ausnahmetabelle geschrieben.
Tabellenfehler
Bei Auftreten eines Tabellenfehlers: Wählen Sie eine der folgenden Optionen aus der Dropdown-Liste aus:
- Tabelle aussetzen (Standard): Die Aufgabe wird fortgesetzt, aber die Daten aus der Tabelle mit dem Fehlerdatensatz werden in einen Fehlerzustand verschoben, und ihre Daten werden nicht repliziert.
- Aufgabe anhalten: Die Aufgabe wird angehalten und ein manueller Eingriff ist erforderlich.
Fehlerbearbeitung eskalieren, wenn Tabellenfehler (pro Tabelle) die folgende Anzahl erreichen: Aktivieren Sie dieses Kontrollkästchen, um die Fehlerbearbeitung zu eskalieren, wenn die Anzahl der Tabellenfehler (pro Tabelle) die angegebene Anzahl erreicht. Gültige Werte sind 1-10.000.
Eskalierungsaktion: Die Eskalationsrichtlinie für Tabellenfehler ist auf Aufgabe anhalten festgelegt und kann nicht geändert werden.
Anwendungskonflikte
Kein Datensatz für die Anwendung von DELETE gefunden: Wählen Sie, welche Aktion durchgeführt werden soll, wenn ein Konflikt bei einem DELETE-Vorgang besteht.
- Ignorieren: Die Aufgabe wird fortgesetzt und der Fehler wird ignoriert.
- Datensatz in Ausnahmetabelle protokollieren: Die Aufgabe wird fortgesetzt und der Fehler wird in die Ausnahmetabelle geschrieben.
- Tabelle aussetzen: Die Aufgabe wird fortgesetzt, aber die Daten aus der Tabelle mit dem Fehlerdatensatz werden in einen Fehlerzustand verschoben, und ihre Daten werden nicht repliziert.
- Aufgabe anhalten: Die Aufgabe wird angehalten und ein manueller Eingriff ist erforderlich.
Fehlerbearbeitung eskalieren, wenn Anwendungskonflikte (pro Tabelle) die folgende Anzahl erreichen: Aktivieren Sie dieses Kontrollkästchen, um die Fehlerbearbeitung zu eskalieren, wenn die Anzahl der Anwendungskonflikte pro Tabelle die angegebene Anzahl erreicht. Gültige Werte sind 1-10.000.
Eskalierungsaktion: Wählen Sie aus, was geschehen soll, wenn die Fehlerbearbeitung eskaliert wird.
- Datensatz in Ausnahmetabelle protokollieren (Standard): Die Aufgabe wird fortgesetzt und der Fehler wird in die Ausnahmetabelle geschrieben.
-
Tabelle aussetzen: Die Aufgabe wird fortgesetzt, aber die Daten aus der Tabelle mit dem Fehlerdatensatz werden in einen Fehlerzustand verschoben, und ihre Daten werden nicht repliziert.
InformationshinweisDas Verhalten ist je nach Änderungsverarbeitungsmodus unterschiedlich:
-
Im Modus Transaktional anwenden werden die letzten Änderungen nicht repliziert.
-
Im Modus Stapeloptimierte Anwendung ist eine Situation möglich, in der keine Datenreplikation bzw. nur eine teilweise Datenreplikation stattfindet.
-
-
Aufgabe anhalten: Die Aufgabe wird angehalten und ein manueller Eingriff ist erforderlich.
Umgebungsbezogene Fehler
-
Maximale Anzahl Wiederholungsversuche: Wählen Sie diese Option aus und geben Sie dann die maximale Anzahl der Male ein, für die eine Aufgabe wiederholt werden soll, wenn ein wiederherstellbarer umgebungsbezogener Fehler eintritt. Nachdem die angegebene Anzahl Male versucht wurde, die Aufgabe zu wiederholen, wird die Aufgabe angehalten, und ein manueller Eingriff ist erforderlich.
Um eine Aufgabe nie zu wiederholen, deaktivieren Sie das Kontrollkästchen oder geben Sie „0“ an.
Um eine Aufgabe eine unendliche Anzahl von Malen zu wiederholen, geben Sie „-1“ an.
-
Intervall zwischen Wiederholungsversuchen (Sekunden): Verwenden Sie den Zähler zur Auswahl oder geben Sie die Anzahl Sekunden an, für die das System zwischen den Wiederholungsversuchen für eine Aufgabe wartet.
Gültige Werte sind 0-2.000.
-
- Wiederholungsintervall für lange Ausfälle erhöhen: Aktivieren Sie dieses Kontrollkästchen, um das Wiederholungsintervall für lange Ausfälle zu erhöhen. Wenn diese Option aktiviert ist, wird das Intervall zwischen den einzelnen Wiederholungsversuchen verdoppelt, bis das Maximale Wiederholungsintervall erreicht ist (und die Wiederholungsversuche werden entsprechend dem angegebenen maximalen Intervall fortgesetzt).
- Maximales Wiederholungsintervall (Sekunden): Verwenden Sie den Zähler für die Auswahl oder geben Sie die Anzahl der Sekunden ein, die zwischen den Wiederholungsversuchen für eine Aufgabe gewartet werden soll, wenn die Option Wiederholungsintervall für lange Ausfälle erhöhen aktiviert ist. Gültige Werte sind 0-2.000.
Feinabstimmung der Änderungsverarbeitung
Anpassung der Transaktionsauslagerung
-
Laufende Transaktionen an Festplatte auslagern, wenn:
Die Replikationsaufgabe bewahrt Transaktionen in der Regel im Arbeitsspeicher auf, bis der Commit-Vorgang an die Quelle bzw. an das Ziel abgeschlossen ist. Wenn die Transaktionen jedoch umfangreicher sind als der zugewiesene Arbeitsspeicher, oder wenn der Commit-Vorgang nicht innerhalb des angegebenen Zeitlimits abgeschlossen ist, werden sie auf die Festplatte ausgelagert.
- Der Gesamtarbeitsspeicher für Transaktionen überschreitet (MB): Der maximale Platz, den alle Transaktionen im Arbeitsspeicher belegen können, bevor sie an die Festplatte ausgelagert werden. Der Standardwert ist 1024.
- Transaktionsdauer überschreitet (Sekunden): Die maximale Zeit, die alle Transaktionen im Arbeitsspeicher bleiben können, bevor sie an die Festplatte ausgelagert werden. Die Dauer wird ab der Zeit berechnet, zu der die Replikationsaufgabe mit der Erfassung der Transaktion begann. Der Standardwert ist 60.
Stapeloptimierung
Die Einstellungen auf dieser Registerkarte werden durch den Modus Änderungen übernehmen bestimmt.
Einstellungen, die nur verfügbar sind, wenn der „Anwendungsmodus“ auf „Stapeloptimiert“ festgelegt ist.
- Stapeländerungen in Intervallen anwenden:
-
Größer als: Die Mindestwartezeit zwischen den einzelnen Anwendungen von Stapeländerungen. Der Standardwert ist 1.
Wenn Sie den Wert für Länger als erhöhen, reduziert sich die Häufigkeit, mit der Änderungen auf das Ziel angewendet werden, während gleichzeitig die Stapelgröße zunimmt. Dies kann die Leistung verbessern, wenn Änderungen auf Zieldatenbanken angewendet werden, die für die Verarbeitung großer Stapel optimiert sind.
- Kleiner als: Die maximale Wartezeit zwischen den einzelnen Anwendungen von Stapeländerungen (bevor eine Zeitüberschreitung erklärt wird). Dies ist also die maximal akzeptable Latenz. Der Standardwert ist 30. Dieser Wert bestimmt die maximale Wartezeit vor dem Anwenden der Änderungen, nachdem der Wert Länger als erreicht wurde.
-
Anwendung eines Satzes erzwingen, wenn Verarbeitungsspeicher größer ist als (MB):: Die maximale Arbeitsspeichermenge, die zur Vorverarbeitung im stapeloptimierten Anwendungsmodus verwendet werden kann. Der Standardwert ist 500.
Für die maximale Stapelgröße legen Sie diesen Wert auf die höchste Arbeitsspeichermenge fest, die Sie der Replikationsaufgabe zuweisen können. Dies kann die Leistung verbessern, wenn Änderungen auf Zieldatenbanken angewendet werden, die für die Verarbeitung großer Stapel optimiert sind.
Einstellungen, die nur verfügbar sind, wenn der „Anwendungsmodus“ auf „Transaktional“ festgelegt ist
Die folgenden Einstellungen sind nur verfügbar, wenn im Anwendungsmodus „Transaktional“ gearbeitet wird. Beachten Sie, dass bei der Replikation an Snowflake „Transaktional“ der einzige verfügbare Anwendungsmodus ist (und daher nicht ausgewählt werden kann) und dass die Lademethode Snowpipe Streaming ist.
-
Mindestanzahl Änderungen pro Transaktion: Die Mindestanzahl der Änderungen, die in jede Transaktion eingeschlossen werden sollen. Der Standardwert ist 1000.
InformationshinweisDie Änderungen werden auf das Ziel angewendet, wenn entweder die Anzahl der Änderungen größer oder gleich dem Wert für Mindestanzahl Änderungen pro Transaktion ist, ODER wenn der unten beschriebene Wert Maximale Zeit für Stapeltransaktionen vor der Anwendung (Sekunden) erreicht ist, je nachdem, welcher Fall zuerst eintritt. Da die Häufigkeit der Änderungsanwendung auf das Ziel von diesen beiden Parametern gesteuert wird, sind Änderungen an den Quelldatensätzen möglicherweise nicht sofort in den Zieldatensätzen ersichtlich.
- Maximale Zeit für Stapeltransaktionen vor der Anwendung (Sekunden): Die maximale Zeit zum Erfassen von Transaktionen in Stapeln, bevor eine Zeitüberschreitung eintritt. Der Standardwert ist 1.
Interval
-
Änderungen alle (Minuten) lesen
Das Intervall zwischen dem Lesen von Änderungen aus der Quelle in Minuten. Der gültige Bereich ist 1 bis 1440.
InformationshinweisDiese Option ist nur für Aufgaben, die Folgendes verwenden:
- Data Movement Gateway
- Mit der Aktualisierungsmethode Änderungen anwenden oder Änderungen speichern
Nach Änderungen suchen
-
Gemäß dem Delta-Extraktionsintervall: Wenn diese Option ausgewählt ist, prüft die Datenaufgabe auf Änderungen gemäß dem Delta-Extraktionsintervall.
InformationshinweisDas Intervall beginnt nach jeder „Runde“. Eine Runde kann als die Zeit definiert werden, die die Datenaufgabe benötigt, um die Änderungen in den Quelltabellen zu lesen und sie an das Ziel zu senden (in einer einzigen Transaktion). Die Länge einer Runde variiert je nach Anzahl der Tabellen und Änderungen. Wenn Sie also ein Intervall von 10 Minuten angeben und eine Runde 4 Minuten dauert, dann beträgt die tatsächliche Zeit zwischen den Prüfungen auf Änderungen 14 Minuten.-
Delta-Extraktionsintervall: Die Häufigkeit, mit der Deltas aus Ihrem System extrahiert werden. Der Standardwert ist alle 60 Sekunden.
-
-
Wie geplant: Wenn diese Option ausgewählt ist, extrahiert die Datenaufgabe das Delta einmal und stoppt dann. Sie wird dann weiterhin wie geplant ausgeführt.
InformationshinweisDiese Option ist nur relevant, wenn das Intervall zwischen den CDC-Zyklen 24 Stunden oder mehr beträgt.Informationen zur Planung:
-
„Datenaufgaben replizieren“ in einem Replikationsprojekt: siehe Planen von Aufgaben
-
Verschiedene Einstellungen
Anweisungs-Cache-Größe (Anzahl der Anweisungen)
Die maximale Anzahl der vorbereiteten Anweisungen zum Speichern auf dem Server zur späteren Ausführung (wenn Änderungen auf das Ziel angewendet werden). Der Standardwert ist 50. Der Höchstwert ist 200.
DELETE und INSERT beim Aktualisieren einer Primärschlüsselspalte
Diese Option ist nur verfügbar, wenn der Änderungen speichern Replikationsmodus aktiviert ist, und erfordert, dass die vollständige ergänzende Protokollierung in der Quelldatenbank aktiviert ist.
Tombstone beim LÖSCHEN senden
Wenn diese Option ausgewählt ist, wird nur der Nachrichtenschlüssel gefüllt; die Nachricht selbst ist null, was darauf hinweist, dass das Element gelöscht wurde. Dies kann Nutzern helfen zu erkennen, dass ein DELETE-Vorgang durchgeführt wurde.
Aufgabenwiederherstellungsdaten in Zieldatenbank speichern
Wählen Sie diese Option aus, um aufgabenspezifische Wiederherstellungsinformationen in der Zieldatenbank zu speichern. Wenn diese Option ausgewählt ist, erstellt die Replikationsaufgabe eine Tabelle mit dem Namen attrep_txn_state in der Zieldatenbank. Diese Tabelle enthält Transaktionsdaten, die zum Wiederherstellen einer Aufgabe verwendet werden können, wenn die Dateien im Ordner Data Movement Gateway Data beschädigt sind oder wenn das Speichergerät, das den Ordner Data enthält, ausgefallen ist.
Änderungen mit SQL MERGE anwenden
Wenn diese Option nicht ausgewählt ist. führt die Replikationsaufgabe getrennte Massenbefehle INSERT, UPDATE und DELETE für jeden der einzelnen Änderungstypen in der Tabelle der Nettoänderungen aus.
Diese Methode ist zwar hocheffizient, aber das Aktivieren der Option Änderungen mit SQL MERGE anwenden ist noch effizienter, wenn mit Endpunkte gearbeitet wird, die diese Option unterstützen.
Dies hat folgende Gründe:
- Es reduziert die Anzahl der pro Tabelle ausgeführten SQL-Anweisungen von drei auf eine. Bei den meisten UPDATE-Vorgängen in großen, unveränderlichen, dateibasierten Cloud-Datenbanken (wie Google Cloud BigQuery) müssen die betroffenen Dateien neu geschrieben werden. Für solche Vorgänge ist die Reduzierung der SQL-Anweisungen pro Tabelle von drei auf eine sehr signifikant.
- Die Zieldatenbank muss die Tabelle „Net Changes“ nur einmal scannen, was die E/A erheblich reduziert.
Inserts optimieren
Wenn Änderungen mit SQL MERGE anwenden zusammen mit der Option Inserts optimieren ausgewählt wird und es sich bei den Änderungen nur um INSERTs handelt, führt die Replikationsaufgabe INSERTs anstelle von SQL MERGE aus. Dies steigert in der Regel die Leistung und senkt die Kosten. Es kann aber auch zu duplizierten Datensätzen in der Zieldatenbank kommen.
- Die Optionen Änderungen mit SQL MERGE anwenden und Inserts optimieren sind nur für Aufgaben verfügbar, die mit den folgenden Zielendpunkten konfiguriert wurden:
- Google Cloud BigQuery
- Databricks
- Snowflake
- Die Optionen Änderungen mit SQL MERGE anwenden und Inserts optimieren werden für die folgenden Quellendpunkte nicht unterstützt:
- Salesforce
- Oracle
-
Wenn die Option Änderungen mit SQL MERGE anwenden aktiviert ist:
- Nicht schwerwiegende Datenfehler oder Datenfehler, die nicht wiederhergestellt werden können, werden als Tabellenfehler behandelt.
- Die Fehlerbehandlungsrichtlinie bei Anwendungskonflikten ist in den folgenden Einstellungen nicht bearbeitbar.
- Kein Datensatz für die Anwendung von DELETE gefunden: Datensatz ignorieren
Schlüssel beim Anwenden von INSERT duplizieren: UPDATE für vorhandenen Zieldatensatz
InformationshinweisWenn auch die Option Inserts optimieren ausgewählt ist, wird die Option Beim Anwenden von INSERT Schlüssel duplizieren auf Duplikate im Ziel zulassen festgelegt.- Kein Datensatz für die Anwendung eines UPDATE gefunden: INSERT für fehlenden Zieldatensatz
- Eskalationsaktion: Datensatz in Ausnahmetabelle protokollieren
- Die folgenden Optionen Für andere Datenfehler Datenfehlerbehandlungsrichtlinie sind nicht verfügbar:
- Datensatz ignorieren
- Datensatz in Ausnahmetabelle protokollieren
- Der Vorgang SQL MERGE selbst wird nur in den endgültigen Zieltabellen durchgeführt. INSERT-Vorgänge werden in den Änderungszwischentabellen durchgeführt (wenn die Replikationsmodi Änderungen anwenden oder Änderungen speichern aktiviert sind).
Transaktional anwenden
Beim Replizieren an Data Warehouse-Ziele oder wenn Sie ohne Data Movement Gateway arbeiten, sind diese Optionen mit einer Ausnahme nicht relevant, da der Anwendungsmodus immer Stapeloptimiert ist.
Diese Ausnahme ist die Replikation an Snowflake, wenn die Lademethode auf Snowpipe Streaming festgelegt ist.
Die folgenden Einstellungen sind nur verfügbar, wenn im Anwendungsmodus „Transaktional“ gearbeitet wird. Bei der Replikation an Datenbanken kann der Anwendungsmodus entweder auf Stapeloptimiert oder auf Transaktional festgelegt werden. Bei der Replikation an ein Snowflake-Ziel und der Festlegung der Lademethode auf Snowpipe Streaming ist der Anwendungsmodus jedoch immer transaktional und kann daher nicht festgelegt werden.
-
Mindestanzahl Änderungen pro Transaktion: Die Mindestanzahl der Änderungen, die in jede Transaktion eingeschlossen werden sollen. Der Standardwert ist 1000.
InformationshinweisDie Replikationsaufgabe wendet die Änderungen auf das Ziel an, entweder, wenn die Anzahl der Änderungen größer oder gleich dem Wert für Mindestanzahl Änderungen pro Transaktion ist, ODER wenn der Zeitüberschreitungswert für den Stapel erreicht ist (siehe unten), je nachdem, welcher Fall zuerst eintritt. Da die Häufigkeit der Änderungsanwendung auf das Ziel von diesen beiden Parametern gesteuert wird, sind Änderungen an den Quelldatensätzen möglicherweise nicht sofort in den Zieldatensätzen ersichtlich. - Maximale Zeit für Stapeltransaktionen vor der Anwendung (Sekunden): Die maximale Zeit zum Erfassen von Transaktionen in Stapeln, bevor eine Zeitüberschreitung eintritt. Der Standardwert ist 1.
Automatische Schemaentwicklung
Wählen Sie aus, wie die folgenden DDL-Änderungstypen im Schema behandelt werden sollen. Wenn Sie die Einstellungen für die Schemaentwicklung geändert haben, müssen Sie die Aufgabe erneut vorbereiten. In der folgenden Tabelle wird beschrieben, welche Aktionen für die unterstützten DDL-Änderungen verfügbar sind.
| DDL-Änderung | Auf Ziel anwenden | Ignorieren | Tabelle aussetzen | Aufgabe anhalten |
|---|---|---|---|---|
| Spalte hinzufügen | Ja | Ja | Ja | Ja |
| Spaltendatentyp ändern | Ja | Ja | Ja | Ja |
| Spalte umbenennen | Ja | Nein | Ja | Ja |
|
Tabelle umbenennen InformationshinweisWird nicht unterstützt, wenn Kafka die Zielplattform ist.
|
Nein | Nein | Ja | Ja |
| Spalte verwerfen | Ja | Ja | Ja | Ja |
|
Tabelle löschen InformationshinweisWird nicht unterstützt, wenn Kafka die Zielplattform ist.
|
Ja | Ja | Ja | Ja |
| Tabelle erstellen
Wenn Sie eine Auswahlregel verwendet haben, um Datensätze hinzuzufügen, die einem Muster entsprechen, werden neue Tabellen, die mit dem Muster übereinstimmen, erkannt und hinzugefügt. |
Ja | Ja | Nein | Nein |
Zeichenersetzung
Sie können Quellzeichen in der Zieldatenbank ersetzen oder löschen, bzw. Sie können Quellzeichen ersetzen oder löschen, die von einem ausgewählten Zeichensatz nicht unterstützt werden.
-
Alle Zeichen müssen als Unicode-Codepunkte angegeben werden.
- Die Zeichenersetzung wird auch in den Kontrolltabellen durchgeführt.
-
Ungültige Werte werden durch ein rotes Dreieck oben rechts in der Tabellenzelle gekennzeichnet. Wenn Sie den Mauszeiger über das Dreieck halten, wird die Fehlermeldung angezeigt.
-
Alle Umwandlungen auf Tabellenebene bzw. globalen Umwandlungen, die für die Aufgabe definiert sind, werden nach Abschluss der Zeichenersetzung durchgeführt.
-
Ersetzungsaktionen, die in der Tabelle Quellzeichen ersetzen oder löschen definiert sind, werden vor der Ersetzungsaktion in der Tabelle Quellzeichen ersetzen oder löschen, die vom ausgewählten Zeichensatz nicht unterstützt werden durchgeführt.
- Die Zeichenersetzung unterstützt keine LOB-Datentypen.
Ersetzen oder Löschen von Quellzeichen
Verwenden Sie die Tabelle Quellzeichen ersetzen oder löschen, um Ersetzungen für spezifische Quellzeichen zu definieren. Das kann beispielsweise nützlich sein, wenn die Unicode-Darstellung eines Zeichens in der Quell- und Zielplattform unterschiedlich ist. Zum Beispiel wird unter Linux das Minuszeichen im Shift_JIS-Zeichensatz als U+2212 dargestellt, unter Windows jedoch als U+FF0D.
| Zweck | Vorgang |
|---|---|
|
Ersetzungsaktionen definieren. |
|
|
Das angegebene Quell- oder Zielzeichen bearbeiten |
Klicken Sie auf |
|
Einträge aus der Tabelle löschen |
Klicken Sie auf |
Ersetzen oder Löschen von Quellzeichen, die vom ausgewählten Zeichensatz nicht unterstützt werden
Verwenden Sie die Tabelle Vom Zeichensatz nicht unterstützte Quellzeichen, um ein einzelnes Ersatzzeichen für alle vom ausgewählten Zeichensatz nicht unterstützte Zeichen zu definieren.
| Zweck | Vorgang |
|---|---|
|
Eine Ersetzungsaktion definieren oder bearbeiten. |
|
|
Die Ersetzungsaktion deaktivieren. |
Wählen Sie den leeren Eintrag aus der Dropdown-Liste Zeichensatz aus. |
Weitere Optionen
Diese Optionen werden in der Benutzeroberfläche nicht angezeigt, da sie nur für bestimmte Versionen oder Umgebungen relevant sind. Daher sollten Sie diese Optionen nur festlegen, wenn Sie ausdrücklich vom Qlik-Support oder in der Produktdokumentation dazu angewiesen werden.
Um eine Option festzulegen, kopieren Sie einfach die Option in das Feld Feature-Namen hinzufügen und klicken Sie auf Hinzufügen. Legen Sie dann den Wert fest oder aktivieren Sie die Option, je nach den erhaltenen Anweisungen.
Paralleles Laden von Datensatzsegmenten
Beim vollständigen Laden können Sie das Laden großer Datensätze beschleunigen, indem Sie den Datensatz in Segmente aufteilen, die dann parallel geladen werden. Tabellen können nach Datenbereichen, allen Partitionen, allen Unterpartitionen oder bestimmten Partitionen aufgeteilt werden.
Weitere Informationen finden Sie unter Paralleles Replizieren von Datensatzsegmenten.
Planen von Aufgaben
In einigen Fällen müssen Sie Ihre Aufgabe möglicherweise planen, um Änderungen von der Datenquelle auf die Zielplattform zu übertragen.
Weitere Informationen finden Sie unter Scheduling tasks.