
Inställningar för replikering
Du kan konfigurera inställningar för datareplikeringsuppgiften.
-
Öppna replikeringsuppgiften och klicka på Inställningar i verktygsfältet.
Dialogrutan Inställningar: <Task-Name> öppnas. De tillgängliga inställningarna beskrivs nedan.
Allmänt
På den här fliken kan du ändra replikeringsläget, staging-inställningarna (när de är tillgängliga), läget för att tillämpa ändringar på målet och publiceringsinställningar.
Replikeringsläge
Följande replikeringslägen är tillgängliga:
-
Fullständig laddning Laddar data från de valda källtabellerna till målplattformen och skapar måltabellerna vid behov. Den fullständiga laddningen sker automatiskt när uppgiften startar, men kan också utföras manuellt vid behov. Manuell fullständig laddning krävs t.ex. om du behöver replikera uppdateringar till vyer (som inte fångas upp under CDC) eller om du replikerar från en datakälla som inte stöder CDC.
-
Tillämpa ändringar: Håller måltabellerna uppdaterade med de ändringar som görs i källtabellerna.
-
Lagra ändringar: Lagrar ändringarna i källtabellerna i Change Tables (en per källtabell).
Se Lagra ändringar för mer information.
När du arbetar med Data Movement gateway registreras ändringar från källan i nära realtid. När du arbetar utan Data Movement gateway (t.ex. med en Qlik Talend Cloud Starter-prenumeration eller när du väljer Inga) registreras ändringar enligt schemaläggarens inställningar. Se Inställningar för replikering för mer information.
Om du väljer Lagra ändringar eller Tillämpa ändringar och dina källdata innehåller tabeller som inte stöder CDC, eller vyer, skapas två data-pipelines. En pipeline för tabeller som stöder CDC, och en annan pipeline för alla andra tabeller och vyer som endast stöder Fullständig laddning.
Laddningsmetod
När du replikerar till Snowflake kan du välja en av följande laddningsmetoder:
-
Massladdning (standard)
Om du väljer Massladdning kan du justera laddningsparametrarna på fliken Datauppladdning.
-
Snowpipe Streaming
Anteckning om informationSnowpipe Streaming kommer endast att vara tillgängligt för val om följande villkor är uppfyllda:
- Replikeringsläget Lagra ändringar är aktiverat, utan Tillämpa ändringar.
- Autentiseringsmekanism i Snowflake-kopplingen är inställd på Nyckelpar.
- Om du använder Data Movement gateway krävs version 2024.11.45 eller senare.
Om du väljer Snowpipe Streaming, se till att du är bekant med begränsningarna och övervägandena när du använder den här metoden. Dessutom, om du väljer Snowpipe Streaming och sedan aktiverar replikeringsläget Tillämpa ändringar eller inaktiverar Lagra ändringar, kommer laddningsmetoden automatiskt att växlas tillbaka till Massladdning.
De främsta anledningarna till att välja Snowpipe Streaming framför Massladdning är:
-
Mindre kostsamt: Eftersom Snowpipe Streaming inte använder Snowflake-lagret bör driftskostnaderna vara betydligt billigare, även om detta beror på ditt specifika användningsfall.
-
Minskad latens: Eftersom data strömmas direkt till måltabellerna (i motsats till via staging) bör replikering från datakällan till målet vara snabbare.
Ansluta till ett staging-område
När replikering görs till de datalager som anges nedan behöver du konfigurera ett mellanlagringsområde. Data bearbetas och förbereds i mellanlagringsområdet innan det överförs till lagret.
Välj antingen ett befintligt mellanlagringsområde eller klicka på Skapa ny för att definiera ett nytt mellanlagringsområdet och följ instruktionerna i Ansluta till molnlagring.
Klicka på Redigera för att redigera kopplingsinställningarna. Klicka på Testa koppling för att testa kopplingen (rekommenderas).
Information om vilka mellanlagringsområden som stöds med vilka datalager finns i kolumnen Stöds som ett mellanlagringsområde i Användningsfall och versioner som stöds på målplattformen.
Läget Tillämpa ändringar
Ändringar tillämpas på måltabellerna med en av följande metoder:
- Batchoptimerad: detta är standardvärdet. När det här alternativet väljs tillämpas ändringar i batcher. En förbearbetningsåtgärd inträffar för att gruppera transaktionerna i batcher på det mest effektiva sättet.
- Transaktionell: Välj det här alternativet för att tillämpa varje transaktion individuellt i den ordning den allokeras. I det här fallet är strikt referentiell integritet säkerställd för alla tabeller.
Publiceringsinställningar
-
Publicera till katalog
Välj det här alternativet för att publicera den här versionen av data till Katalog som en datamängd. Kataloginnehållet uppdateras nästa gång du förbereder den här uppgiften.
Mer information om Katalog finns i Förstå data med hjälp av katalogverktyg.
Proxyinställningar vid användning av Data Movement gateway
-
När du använder Data Movement gateway, anslut via proxy till
När du använder Data Movement gateway kan du ansluta till målplattformen och staging-plattformen (området) via en proxy.
Mer information om hur du konfigurerar Data Movement gateway för att använda en proxyserver finns i Ställa in Qlik Cloud-klientorganisationen och en proxyserver.
-
Målplattform
Anteckning om informationTillgängligt vid användning av Snowflake och Databricks. -
Staging-plattform
Anteckning om informationTillgängligt vid användning av Google BigQuery, Amazon Redshift, Microsoft Fabric och Databricks.
-
Datauppladdning
Den här fliken visas endast vid replikering till ett datalager eller Kafka-mål. Dessutom kommer inställningarna på den här fliken att skilja sig åt beroende på det valda målet.
Relevant för alla datalagermål
Maximal filstorlek
Den maximala storleken en fil kan nå innan den stängs. Mindre filer kan laddas upp snabbare (beroende på nätverket) och förbättrar prestandan när de används i kombination med alternativet parallell körning. Att belamra databasen med små filer anses emellertid generellt vara en dålig arbetsmetod.
Endast relevant för Snowflake-mål
På fliken Allmänt kan du välja om du vill ladda data till Snowflake med Massladdning eller Snowpipe Streaming. När Snowpipe Streaming är valt visas inte fliken Datauppladdning. När Massladdning är valt är följande inställningar tillgängliga:
-
Maximal filstorlek (MB): Relevant för den initiala fullständiga laddningen och CDC. Den maximala storlek en fil kan nå innan den laddas till målet. Om du stöter på prestandaproblem kan du prova att justera den här parametern.
-
Antal filer att ladda i en batch: Endast relevant för den initiala fullständiga laddningen. Antalet filer som ska laddas i en enda batch. Om du stöter på prestandaproblem kan du prova att justera den här parametern.
För en beskrivning av laddningsmetoderna Massladdning och Snowpipe Streaming, se Allmänt.
Endast relevant för Kafka-mål
Meddelandeegenskaper
Komprimering
Välj eventuellt en av de tillgängliga komprimeringsmetoderna (Snappy eller Gzip). Standard är Ingen.
Publicering av datameddelanden
Välj ett av följande alternativ för Publicera data till:
- Specifikt ämne: Publicerar data till ett enda ämne. Skriv antingen ett ämnesnamn eller använd bläddringsknappen för att välja önskat ämne.
-
Separat ämne för varje tabell: Publicerar data till flera ämnen som motsvarar källtabellernas namn.
Målets topic namn består av källschemanamnet och källtabellnamnet, separerat med en punkt (till exempel, dbo.Employees). Formatet på målets topic namn är viktigt eftersom du kommer att behöva förbereda dessa topics i förväg.
Om ämnena inte finns konfigurerar du mäklarna med auto.create.topics.enable=true för att göra det möjligt för datauppgiften att skapa ämnena under körning. Annars kommer uppgiften att misslyckas.
Information om hur du åsidosätter den här inställningen på datamängdsnivå finns i Åsidosätta uppgiftsinställningar för enskilda datamängder vid publicering till Kafka
Meddelandenyckel
Välj ett av de tillgängliga alternativen.
-
Primärnyckelkolumner: För varje meddelande kommer meddelandenyckeln att innehålla värdet för primärnyckelkolumnen.
När Efter meddelandenyckel har valts som Partitionsstrategi kommer meddelanden som består av samma primärnyckelvärde att skrivas till samma partition.
-
Schema- och tabellnamn: För varje meddelande kommer meddelandenyckeln att innehålla en kombination av schema- och tabellnamn (till exempel dbo+Employees).
När Efter meddelandenyckel har valts som Partitionsstrategi kommer meddelanden som består av samma schema- och tabellnamn att skrivas till samma partition.
- Ingen: Skapar meddelanden utan en meddelandenyckel.
Information om hur du åsidosätter den här inställningen på datamängdsnivå finns i Åsidosätta uppgiftsinställningar för enskilda datamängder vid publicering till Kafka
Partitionsstrategi
Välj antingen Slumpmässig eller Efter meddelandenyckel. Om du väljer Slumpmässig kommer varje meddelande att skrivas till en slumpmässigt vald partition. Om du väljer Efter meddelandenyckel kommer meddelanden att skrivas till partitioner baserat på den valda Meddelandenyckel (beskrivs ovan).
Publicering av metadatameddelanden
Strategi för ämnesnamn
Den första strategin (Schema- och tabellnamn) är en proprietär Qlik-strategi medan de andra tre är standardstrategier för Confluent-ämnesnamn.
Välj en av de tillgängliga strategierna för ämnesnamn.
- Schema- och tabellnamn (standard)
- Ämnesnamn
- Postnamn
- Ämnes- och postnamn
Mer information om Confluents strategier för ämnesnamn finns i Strategi för ämnesnamn
Kompatibilitetsläge för ämne
Välj ett av följande kompatibilitetslägen i listrutan Kompatibilitetsläge för ämne:
-
Använd standardvärden för schemaregister: Hämtar kompatibilitetsnivån från schemaregistrets serverkonfiguration.
-
Bakåt - Endast senaste schema: Nya scheman kan endast läsa motsvarande data och data som producerats av det senast registrerade schemat.
-
Bakåt transitivt - Alla tidigare scheman: Nya scheman kan läsa data som producerats av alla tidigare registrerade scheman.
-
Framåt - Endast senaste schema: Det senast registrerade schemat kan läsa data som producerats av det nya schemat.
-
Framåt transitivt - Alla tidigare scheman: Alla tidigare registrerade scheman kan läsa data som producerats av det nya schemat.
-
Fullständig - Endast senaste schema: Det nya schemat är bakåt- och framåtkompatibelt med det senast registrerade schemat.
-
Fullständig transitiv - Alla tidigare scheman: Det nya schemat är bakåt- och framåtkompatibelt med alla tidigare registrerade scheman.
-
Ingen
- Beroende på vald Strategi för ämnesnamn kanske vissa av kompatibilitetslägena inte är tillgängliga.
-
När du publicerar meddelanden till ett schemaregister kommer standardkompatibilitetsläget för ämne för alla nyskapade Kontrolltabellsämnen att vara Ingen, oavsett valt Kompatibilitetsläge för ämne.
Om du vill att det valda Kompatibilitetsläge för ämne även ska gälla för kontrolltabeller ställer du in den interna parametern setNonCompatibilityForControlTables i Kafka-målkopplingen till false.
Använd en proxy för att ansluta till Confluent Schema Registry
Det här alternativet stöds endast vid publicering till Confluent Schema Registry.
Slå på om din Data Movement gateway är konfigurerad för att använda en proxyserver.
Meddelandeattribut
Du kan ange anpassade meddelandeattribut som åsidosätter standardmeddelandeattributen. Detta är användbart om konsumentapplikationen behöver bearbeta meddelandet i ett visst format.
Anpassade meddelandeattribut kan definieras på både uppgifts- och tabellnivå. När attributen definieras på både uppgifts- och tabellnivå kommer de meddelandeattribut som definierats för tabellen att ha företräde framför de som definierats för uppgiften.
Information om hur du åsidosätter meddelandeattributen på datamängdsnivå finns i Åsidosätta uppgiftsinställningar för enskilda datamängder vid publicering till Kafka
Hierarkiskt strukturerade meddelanden stöds inte.
Allmänna regler och riktlinjer för användning
När du definierar ett anpassat meddelande är det viktigt att överväga de regler och riktlinjer för användning som listas nedan.
Avsnittsnamn
Följande namnregler gäller:
- Avsnittsnamn måste börja med tecknen a-z, A-Z eller _ (ett understreck) och kan sedan följas av något av följande tecken: a-z, A-Z, 0-9, _
- Med undantag för avsnitten Postnamn och Nyckelnamn (som inte slutar med ett snedstreck), kommer borttagning av snedstrecket från avsnittsnamn att platta ut hierarkin för det tillhörande avsnittet (se Snedstreck nedan).
- Alla avsnittsnamn utom Postnamn och Nyckelnamn kan raderas (se Radering nedan)
-
Avsnittsnamnen Datanamn och Inkludera post Före-data kan inte båda raderas
-
Avsnittsnamnen Datanamn och Inkludera post Före-data kan inte vara desamma
Vissa av avsnittsnamnen i användargränssnittet slutar med ett snedstreck (t.ex. beforeData/). Syftet med snedstrecket är att upprätthålla en hierarki av de olika avsnitten i meddelandet. Om snedstrecket tas bort inträffar följande:
- Den hierarkiska strukturen för det avsnittet kommer att plattas ut, vilket resulterar i att avsnittsnamnet tas bort från meddelandet
- Avsnittsnamnet kommer att läggas till som ett prefix till de faktiska metadata, antingen direkt eller med hjälp av ett avgränsningstecken (t.ex. ett understreck) som du lade till i namnet
Exempel på ett datameddelande när headers/ anges med ett snedstreck:
"message":{
"data":{
"COL1": "159",
"COL2": "159"
},
"beforeData": null,
"headers": {
"operation": "INSERT",
"changeSequence": "2018100811484900000000233",
Exempel på ett datameddelande när headers_ anges med ett understreck i stället för ett snedstreck:
"message":{
"data":{
"COL1": "159",
"COL2": "159"
},
"beforeData": null,
"headers_operation": "INSERT",
"headers_changeSequence": "2018100811484900000000233",
Om du raderar ett avsnittsnamn från meddelandet plattas den hierarkiska strukturen för det avsnittet ut. Detta kommer att resultera i att alla data i det avsnittet visas omedelbart under innehållet i det föregående avsnittet.
Exempel på ett datameddelande med avsnittsnamnet headers :
"message":{
"data":{
"COL1": "159",
"COL2": "159"
},
"headers": {
"operation": "INSERT",
"changeSequence": "2018100811484900000000233",
Exempel på ett datameddelande utan avsnittsnamnet headers :
"message":{
"data":{
"COL1": "159",
"COL2": "159"
},
"beforeData": null,
"operation": "INSERT",
"changeSequence": "2018100811484900000000233",
Variabler
Du kan lägga till variabler i namn genom att klicka på knappen ![]() i slutet av raden. Följande variabler är tillgängliga:
i slutet av raden. Följande variabler är tillgängliga:
- SERVER_NAME - Värdnamnet för Data Movement gateway-servern
- TARGET_TABLE_NAME - Tabellens namn
- TARGET_TABLE_OWNER - Tabellens ägare
- TASK_NAME - Datauppgiftens namn
Variabeln TARGET_TABLE_OWNER är inte tillgänglig för alternativen Postnamn och Nyckelnamn (beskrivs i tabellen nedan).
Definiera anpassade meddelandeattribut
För att definiera ett anpassat meddelandeformat slår du på Använd anpassade inställningar och konfigurerar alternativen enligt beskrivningen i tabellen nedan.
För att återgå till standardmeddelandeattributen slår du av Använd anpassade inställningar.
| Alternativ | Beskrivning |
|---|---|
|
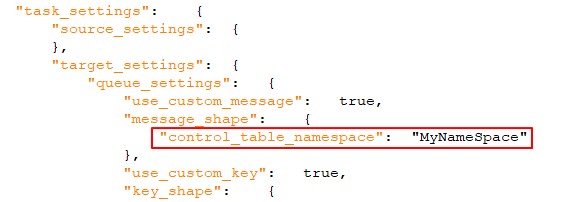
När det är påslaget (standard) kommer en unik identifierare att inkluderas i meddelandet. Detta bör vara en sträng, separerad med punkter. Observera att namnområdet kommer att inkluderas i både meddelandet och meddelandenyckeln. Exempel: mycompany.queue.msg Standardnamn: com.attunity.queue.msg.{{TASK_NAME}}.{{TARGET_TABLE_OWNER}}.{{TARGET_TABLE_NAME}} Standardnamn för kontrolltabeller: com.attunity.queue.msg.{{TARGET_TABLE_NAME}} Anteckning om information
Standardnamnområdet för kontrolltabeller kan inte ändras via användargränssnittet. Du kan dock ändra standardnamnområdet för kontrolltabeller på följande sätt:
|
|
|
Postnamn |
Namnet på posten (meddelandet). Standardnamn: DataRecord |
|
Datanamn |
Alla datakolumner som ingår i posten. Standardnamn: data/ |
|
Inkludera rubriker |
När det är påslaget (standard) kommer rubrikkolumner att inkluderas i meddelandet. Rubrikkolumner ger ytterligare information om källoperationerna. Mer information finns i Inkludera följande rubriker nedan. |
|
Inkludera namnområde för rubriker |
När det är påslaget (standard) kommer en unik identifierare för avsnittet med rubrikkolumner att inkluderas i meddelandet. Detta bör vara en sträng, separerad med punkter. Exempel: headers.queue.msg Standardnamn: com.attunity.queue.msg |
|
Rubriknamn |
Namnet på avsnittet som innehåller Qlik-kolumnrubrikerna. Standardnamn: headers/ |
|
För en beskrivning av de tillgängliga rubrikkolumnerna, se Datameddelanden i Qlik-hjälpen. Standard: Alla kolumner är inkluderade som standard, förutom kolumnen Externt schema-ID. |
|
|
Inkludera post Före-data |
När det är påslaget (standard) kommer både data före och efter UPDATE att inkluderas i UPDATE-meddelanden. För att endast inkludera data efter UPDATE i meddelanden slår du av alternativet. Standardnamn: beforeData/ |
|
Nyckelnamn |
Namnet på avsnittet som innehåller meddelandenyckeln. Standardnamn: keyRecord Det här alternativet är endast tillämpligt när:
|
Ytterligare inställningar
-
Maximal meddelandestorlek
I fältet Maximal meddelandestorlek anger du den maximala storleken på meddelanden som mäklaren/mäklarna är konfigurerade att ta emot (message.max.bytes). Datauppgiften kommer inte att skicka meddelanden som är större än den maximala storleken.
Metadata
Grundläggande
-
Måltabellschema
Schemat på målet till vilket källtabellerna kommer att replikeras om du inte vill använda källtabellschemat (eller om det inte finns något schema i källdatabasen).
Anteckning om informationNär du replikerar till ett Oracle-mål är standardmåltabellschemat "system". Observera också att om du lämnar det här fältet tomt (i vilket fall källschemat kommer att användas), måste du se till att källschemat redan finns på målet. Annars kommer uppgiften att misslyckas.Anteckning om informationDen maximalt tillåtna längden för schemanamnet är 128 tecken.
JSON-kolumnmappning
Mappa kompatibla JSON-kolumner från källa till mål
-
Om du använder Data Movement gateway för att komma åt din datakälla, krävs version 2024.11.70 eller senare.
-
Stöds endast med förhandsgranskningskopplingar för SaaS-applikationer.
När det här alternativet är valt mappas JSON-kolumner på källan automatiskt till JSON-kolumner på målet.
Det här alternativets tillstånd och synlighet bestäms av följande faktorer:
-
Nya uppgifter: Detta alternativ kommer att vara aktiverat som standard om både källan och målet stöder JSON-datatypen.
-
Befintliga uppgifter: Detta alternativ kommer att vara inaktiverat som standard, även om både källan och målet stöder JSON-datatypen. Detta är för att bevara bakåtkompatibilitet med nedströms processer – såsom transformationer – som förväntar sig att måldata ska vara i STRING-format (vilket är det äldre beteendet). Du kan antingen lämna alternativet inaktiverat eller så kan du redigera de nedströms processerna så att de är kompatibla med JSON-format, och sedan aktivera det här alternativet.
-
Nya och befintliga uppgifter: Om bara källan stöder JSON-datatypen kommer detta alternativ inte att vara synligt. Om JSON-stöd läggs till målet i ett senare skede kommer alternativet att bli synligt men förbli inaktiverat. Detta är för att bevara bakåtkompatibilitet med nedströms processer – såsom transformationer – som förväntar sig att måldata ska vara i STRING-format (vilket är det äldre beteendet).
LOB-inställningar
 -knapp, både i dialogrutan Skapa koppling och i onlinehjälpen.
-knapp, både i dialogrutan Skapa koppling och i onlinehjälpen.De tillgängliga LOB-inställningarna skiljer sig åt beroende på det valda replikeringsmålet. Eftersom datalagermål inte stöder obegränsade LOB-kolumnstorlekar kommer det här alternativet inte att vara tillgängligt vid replikering till ett datalager.
LOB-inställningar för mål som inte är datalager
- Inkludera inte LOB-kolumner: Välj detta om du inte vill att LOB-källkolumner ska replikeras.
-
Begränsa LOB-kolumnstorlek till (KB): Detta är standard. Välj det här alternativet om du bara behöver replikera små LOB:ar eller om målplattformen inte stöder obegränsad LOB-storlek. Det maximalt tillåtna värdet för det här fältet är 102400 KB (100 MB).
När du replikerar små LOB:ar är det här alternativet mer effektivt än alternativet Begränsa inte LOB-kolumnstorlek eftersom LOB:arna replikeras "inline" i motsats till via "uppslagning" från källan. Under ändringsbearbetning replikeras små LOB:ar vanligtvis via "uppslagning" från källan.
Begränsningen gäller antalet LOB-byte som läses från källslutpunkten. För BLOB-kolumner kommer mål-BLOB-storleken att vara exakt enligt den angivna gränsen. För CLOB- och NCLOB-kolumner kan mål-LOB-storleken skilja sig från den angivna gränsen om käll- och mål-LOB inte har samma teckenuppsättning. I det här fallet kommer datauppgiften att utföra teckenuppsättningskonvertering, vilket kan resultera i en avvikelse mellan käll- och mål-LOB-storlekarna.
Eftersom värdet för Begränsa LOB-storlek till är i byte bör storleken beräknas enligt följande formler:
- BLOB: Längden på den största LOB:en.
- NCLOB: Längden på den längsta TEXTEN i tecken multiplicerat med två (eftersom varje tecken hanteras som en dubbelbyte). Om data inkluderar 4-byte-tecken multiplicerar du det med fyra.
- CLOB: Längden på den längsta TEXTEN i tecken (eftersom varje tecken hanteras som ett UTF8-tecken). Om data inkluderar 4-byte-tecken multiplicerar du det med två.
Anteckning om information- Alla LOB:ar som är större än den angivna storleken kommer att trunkeras.
- Under ändringsbearbetning från Oracle-källa replikeras inline-BLOB:ar inline.
- Ändringar av den här inställningen kommer endast att påverka befintliga tabeller efter att de har laddats om.
-
Begränsa inte LOB-kolumnstorlek: När det här alternativet är valt kommer LOB-kolumner att replikeras, oavsett storlek.
Anteckning om informationReplikering av LOB-kolumner kan påverka prestandan. Detta gäller särskilt för stora LOB-kolumner som kräver att replikeringsuppgiften utför en uppslagning från källtabellen för att hämta käll-LOB-värdet.-
Optimera när LOB-storleken är mindre än: Välj det här alternativet när du behöver replikera både små och stora LOB:ar, och de flesta LOB:arna är små.
Anteckning om informationDet här alternativet stöds endast med följande källor och mål:
-
Källor: Oracle, Microsoft SQL Server, MySQL, PostgreSQL och IBM DB2 for LUW
-
Mål: Oracle, Microsoft SQL Server, MySQL, PostgreSQL.
När det här alternativet är valt kommer de små LOB:arna under fullständig laddning att replikeras "inline" (vilket är mer effektivt), och de stora LOB:arna kommer att replikeras genom att utföra en uppslagning från källtabellen. Under ändringsbearbetning kommer dock både små och stora LOB:ar att replikeras genom att utföra en uppslagning från källtabellen.
Anteckning om informationNär det här alternativet är valt kommer replikeringsuppgiften att kontrollera alla LOB-storlekar för att avgöra vilka som ska överföras "inline". LOB:ar som är större än den angivna storleken kommer att replikeras med Full LOB-läge.
Därför, om du vet att de flesta LOB:arna är större än den angivna inställningen, är det att föredra att använda alternativet Replikera obegränsade LOB-kolumner i stället.
-
-
Chunk-storlek (KB): Ändra eventuellt storleken på de LOB-chunks som ska användas vid replikering av data till målet. Standard-chunk-storleken bör räcka i de flesta fall, men om du stöter på prestandaproblem kan en justering av storleken förbättra prestandan.
Anteckning om informationMed vissa databaser sker validering av datatyp när data infogas eller uppdateras. I sådana fall kan replikering av strukturerade datatyper (t.ex. XML, JSON, GEOGRAPHY, etc.) misslyckas om data är större än den angivna chunk-storleken.
-
LOB-inställningar för datalagermål som stöds
-
Inkludera LOB-kolumner och begränsa kolumnstorlek till (KB):
Du kan välja att inkludera LOB-kolumner i uppgiften och ställa in den maximala LOB-storleken. LOB:ar som är större än den maximala storleken kommer att trunkeras.
Avancerat
Inställningar för kontrolltabell
-
Schema för kontrolltabeller: Ange målschemat för kontrolltabellerna om du inte vill att de ska skapas i källschemat (standard) eller i målschemat.
Anteckning om informationDen maximalt tillåtna längden för schemanamnet är 128 tecken. - Skapa målkontrolltabeller i tabellutrymme: När replikeringsmålet är Oracle anger du det tabellutrymme där du vill att målkontrolltabellerna ska skapas. Om du inte anger någon information i det här fältet kommer tabellerna att skapas i standardtabellutrymmet i måldatabasen.
- Skapa index för målkontrolltabeller i tabellutrymme: När replikeringsmålet är Oracle anger du det tabellutrymme där du vill att kontrolltabellsindexen ska skapas. Om du inte anger någon information i det här fältet skapas indexen i samma tabellutrymme som kontrolltabellerna.
- Tidslucka för replikeringshistorik (minuter): Längden på varje tidslucka i kontrolltabellen Replikeringshistorik. Standard är 5 minuter.
Val av kontrolltabell
Välj de kontrolltabeller du vill ska skapas på målplattformen:
| Logiskt namn | Namn i mål |
|---|---|
| Tillämpa undantag | attrep_apply_exceptions |
| Replikeringsstatus | attrep_status |
| Pausade tabeller | attrep_suspended_tables |
| Replikeringshistorik | attrep_history |
| DDL-historik |
attrep_ddl_history DDL-historiktabellen stöds endast på följande målplattformar:
|
Mer information om kontrolltabeller finns i Kontrolltabeller.
Fullständig laddning
-knapp, både i dialogrutan Skapa koppling och i onlinehjälpen.Grundläggande
Dessa inställningar kommer att tillämpas under förberedelsestadiet för datauppgiften och varje gång en tabell laddas om.
Om måltabellen redan finns: Välj ett av följande för att avgöra hur data ska laddas till måltabellerna:
Alternativet att ta bort eller trunkera måltabellerna är endast relevant om sådana operationer stöds av källslutpunkten.
-
Ta bort och skapa tabell: Måltabellen tas bort och en ny tabell skapas i dess ställe.
Anteckning om informationReplikeringsuppgiftens kontrolltabeller kommer inte att tas bort. Eventuella pausade tabeller som tas bort kommer dock också att raderas från kontrolltabellen attrep_suspended_tables om den tillhörande uppgiften laddas om.
-
TRUNKERA före laddning: Data trunkeras utan att måltabellens metadata påverkas. Observera att när det här alternativet är valt kommer aktivering av alternativet Skapa primärnyckel eller unikt index efter att fullständig laddning har slutförts inte att ha någon effekt.
Anteckning om informationStöds inte när Microsoft Fabric är målplattformen. - Ignorera: Befintliga data och metadata för måltabellen kommer inte att påverkas. Nya data kommer att läggas till i tabellen.
Avancerat
Prestandajustering
Om datareplikeringen är överdrivet långsam kan en justering av följande parametrar förbättra prestandan.
- Maximalt antal tabeller: Ange det maximala antalet tabeller som ska laddas in i målet på en gång. Standardvärdet är 5.
-
Timeout för transaktionskonsistens (sekunder): Ange antalet sekunder som replikeringsuppgiften ska vänta på att öppna transaktioner ska stängas innan operationen för fullständig laddning påbörjas. Standardvärdet är 600 (10 minuter). Replikeringsuppgiften kommer att påbörja den fullständiga laddningen efter att timeout-värdet har uppnåtts även om det finns öppna transaktioner.
Anteckning om informationFör att replikera transaktioner som var öppna när den fullständiga laddningen startade men som endast bekräftades efter att timeout-värdet uppnåddes, måste du ladda om måltabellerna. - Bekräftelsehastighet under fullständig laddning: Det maximala antalet händelser som kan överföras tillsammans. Standardvärdet är 10000.
Efter att fullständig laddning har slutförts
Du kan ställa in uppgiften så att den stoppas automatiskt efter att den fullständiga laddningen har slutförts. Detta är användbart om du behöver utföra DBA-operationer på måltabellerna innan uppgiftens fas Tillämpa ändringar (dvs. CDC) börjar.
Under fullständig laddning cachas alla DML-operationer som körs på källtabellerna. När den fullständiga laddningen har slutförts tillämpas de cachade ändringarna automatiskt på måltabellerna (så länge alternativen Innan/Efter cachade ändringar tillämpas som beskrivs nedan är inaktiverade).
- Skapa primärnyckel eller unikt index: Välj det här alternativet om du vill fördröja skapandet av primärnyckel eller unikt index på målet tills efter att den fullständiga laddningen har slutförts.
- Stoppa uppgiften:
Anteckning om information
Dessa inställningar är inte tillgängliga när:
- Du replikerar från SaaS-applikationskällor (eftersom det inte finns några cachade händelser)
- Du replikerar till datalagermål
-
Innan cachade ändringar tillämpas: Välj för att stoppa uppgiften efter att den fullständiga laddningen har slutförts.
-
Efter att cachade ändringar har tillämpats: Välj för att stoppa uppgiften så snart data är konsekventa över alla tabeller i uppgiften.
Anteckning om informationNär du konfigurerar uppgiften att stoppas efter att den fullständiga laddningen har slutförts, observera följande:
- Uppgiften stoppas inte i samma ögonblick som den fullständiga laddningen slutförs. Den kommer endast att stoppas efter att den första batchen av ändringar har fångats (eftersom det är detta som utlöser att uppgiften stoppas). Detta kan ta ett tag beroende på hur ofta källdatabasen uppdateras. Efter att uppgiften har stoppats kommer ändringarna inte att tillämpas på målet förrän uppgiften återupptas.
- Att välja Innan cachade ändringar tillämpas kan påverka prestandan, eftersom de cachade ändringarna endast kommer att tillämpas på tabeller (även de som redan har slutfört fullständig laddning) efter att den sista tabellen har slutfört fullständig laddning.
- När det här alternativet är valt och en DDL körs på en av källtabellerna under processen för fullständig laddning (i en uppgift för fullständig laddning och tillämpa ändringar), kommer replikeringsuppgiften att ladda om tabellen. Detta innebär i praktiken att alla DML-operationer som körs på källtabellerna kommer att replikeras till målet innan uppgiften stoppas.
För initial laddning
När data flyttas från en SaaS-programkälla kan du ställa in hur den initiala fullständiga laddningen ska utföras.
| Använd cachelagrade data |
Med det här alternativet kan du använda mellanlagrade data som lästes in när metadata genererades med Fullständig datasökning valt. Då skapas mindre overhead avseende API-användning och kvoter, eftersom data redan läses in från källan. Alla ändringar sedan den initiala datasökningen kan plockas upp av Change data capture (CDC). |
| Ladda data från källa |
Med det här alternativet utförs en ny laddning från datakällan. Det här alternativet är användbart när:
|
Tillämpa ändringar
Dessa inställningar är endast tillgängliga när replikeringsläget Tillämpa ändringar är aktiverat.
Grundläggande
Välj typ av DDL-ändringar att tillämpa på målet
Följande alternativ avgör om DDL-operationer som utförs på motsvarande källtabell också ska utföras på måltabellen.
-
Ta bort tabell: Välj för att ta bort måltabellen när källtabellen tas bort.
Anteckning om informationStöds inte när Kafka är målplattformen. -
Trunkera tabell: Välj för att trunkera måltabellen när källtabellen trunkeras.
Anteckning om informationStöds inte när Microsoft Fabric är målplattformen. -
Ändra tabell: Välj för att ändra måltabellen när källtabellen ändras.
Anteckning om informationAtt byta namn på en tabell stöds inte när Kafka är målplattformen.
Justering av ändringsbearbetning
-
Tillämpa batchade ändringar på flera tabeller samtidigt: Om du väljer det här alternativet kan prestandan förbättras när du tillämpar ändringar från flera källtabeller.
Anteckning om informationDet här alternativet stöds endast när:
- Läget Tillämpa ändringar är inställt på Batchoptimerat. Mer information finns i Inställningar för replikering.
- Replikeringsmålen inte är MySQL, PostgreSQL, Oracle och Google BigQuery.
-
Maximalt antal tabeller: Det maximala antalet tabeller att tillämpa batchade ändringar på samtidigt. Standard är fem, max är 50 och minimum är två.
När alternativet Tillämpa batchade ändringar på flera tabeller samtidigt är aktiverat gäller följande begränsningar:
-
Standardvärdena för uppgiftens felhanteringspolicy kommer att vara oförändrade för Miljö- och Tabell-fel, men standardvärdena för Data-fel och Tillämpa konflikter-fel kommer att vara följande:
- Datafel:
- Datatrunkeringsfel: Logga post till undantagstabellen
- Andra datafel: Pausa tabell
- Tillämpa konflikter-fel:
- Borttagningar: Ignorera post
Infogningar: UPPDATERA den befintliga målposten
Anteckning om informationDetta är inte relevant för ett Snowflake-mål (eftersom Snowflake inte stöder primärnycklar).- Uppdateringar: Ignorera post
- Eskaleringsåtgärd:
- Eskaleringsåtgärd för både Data-fel och Tillämpa konflikter stöds inte.
- Kontrolltabellen attrep_apply_exception stöds inte.
- För datafel:
- Alternativet Logga post till undantagstabellen är endast tillgängligt för datatrunkeringsfel.
- Det finns inget Ignorera -alternativ.
- För Tillämpa konflikter:
- Alternativet Logga post till undantagstabell är inte tillgängligt.
- Alternativet Ignorera är endast tillgängligt för tillämpningskonflikten Ingen post hittades för att tillämpa en UPPDATERING .
- Datafel:
Se även: Felhantering.
-
Begränsa antalet ändringar som tillämpas per ändringsbearbetningssats till: För att begränsa antalet ändringar som tillämpas i en enda ändringsbearbetningssats markerar du den här kryssrutan och ändrar sedan eventuellt standardvärdet. Standardvärdet är 10 000.
Anteckning om informationDet här alternativet stöds endast med följande mål: MySQL, PostgreSQL, Oracle och Google BigQuery.
Avancerat
Se Justering av ändringsbearbetning.
Lagra ändringar
Dessa inställningar är endast tillgängliga när Lagra ändringar-läget för replikering är aktiverat.
Grundläggande
DDL-alternativ
Välj ett av följande alternativ för att bestämma hur DDL-åtgärder på källtabellerna ska hanteras:
- Tillämpa på ändringstabell: DDL-åtgärder på källtabellerna (som att en kolumn läggs till) kommer endast att tillämpas på motsvarande ändringstabeller.
- Ignorera: Alla DDL-åtgärder på källtabeller kommer att ignoreras.
Avancerat
Vid uppdatering
Välj Lagra före- och efterbild för att lagra både data före UPDATE och data efter UPDATE. När det inte är valt lagras endast data efter UPDATE.
Skapande av ändringstabell
Följande delavsnitt beskriver de alternativ som är tillgängliga när ändringar lagras i ändringstabeller.
- Suffix: Ange en sträng att använda som suffix för alla ändringstabeller. Standardvärdet är __ct. Ändringstabellernas namn är namnet på måltabellen med suffixet tillagt. Så till exempel, om standardvärdet används, blir namnet på ändringstabellen HR__ct.
- Prefix för rubrikkolumn: Ange en sträng att använda som prefix för alla rubrikkolumner i ändringstabellen. Standardvärdet är header__. Till exempel, när standardvärdet används, kommer rubrikkolumnen stream_position att kallas header__stream_position.
För mer information om ändringstabeller, se Använda Ändringstabeller.
Om ändringstabell finns när fullständig laddning startar: Välj ett av följande för att bestämma hur ändringstabellerna ska laddas när replikering med fullständig laddning startar:
- Ta bort och skapa ändringstabell: Tabellen tas bort och en ny tabell skapas i dess ställe.
-
Ta bort gamla ändringar och lagra nya ändringar i befintlig ändringstabell: Data trunkeras och läggs till utan att påverka tabellens metadata.
Anteckning om informationStöds inte när Microsoft Fabric är målplattformen. - Behåll gamla ändringar och lagra nya ändringar i befintlig ändringstabell: Data och metadata för den befintliga ändringstabellen påverkas inte.
Tabellrubrikkolumner
Ändringstabellens rubrikkolumner ger information om Ändringsbearbetningsåtgärder, till exempel typ av åtgärd (t.ex. INSERT), överföringstidpunkt och så vidare. Om du inte behöver all den här informationen kan du konfigurera flyttar-uppgiften så att Ändringstabeller skapas med valda rubrikkolumner (eller inga kolumner) så att deras fotavtryck i måldatabasen minskar.
För en beskrivning av rubrikkolumnerna, se Ändringstabeller.
Felhantering
Grundläggande
Tillämpningskonflikter
Dubblettnyckel vid tillämpning av INSERT: Välj vilken åtgärd som ska vidtas när det uppstår en konflikt med en INSERT-åtgärd.
-
Ignorera: Uppgiften fortsätter och felet ignoreras.
-
UPPDATERA den befintliga målposten: Målposten med samma primärnyckel som den INFOGADE källposten uppdateras.
- Logga post till undantagstabellen (standard): Uppgiften fortsätter och felet skrivs till undantagstabellen.
-
Pausa tabell: Uppgiften fortsätter men data från tabellen med felposten flyttas till ett feltillstånd och dess data replikeras inte.
- Stoppa uppgift: Uppgiften stoppas och manuellt ingripande krävs.
Ingen post hittades för tillämpning av en UPDATE: Välj vilken åtgärd som ska vidtas när det uppstår en konflikt med en UPDATE-åtgärd.
- Ignorera: Uppgiften fortsätter och felet ignoreras.
-
INFOGA den saknade målposten: Den saknade målposten kommer att infogas i måltabellen. När källslutpunkten är Oracle kräver valet av detta alternativ att kompletterande loggning är aktiverad för alla källtabellens kolumner.
- Logga post till undantagstabellen (standard): Uppgiften fortsätter och felet skrivs till undantagstabellen.
-
Pausa tabell: Uppgiften fortsätter men data från tabellen med felposten flyttas till ett feltillstånd och dess data replikeras inte.
- Stoppa uppgift: Uppgiften stoppas och manuellt ingripande krävs.
Avancerat
Datafelhantering stöds endast i replikeringsläget Tillämpa ändringar (inte fullständig laddning).
Datafel
För datatrunkeringsfel: Välj vad du vill ska hända när en trunkering sker i en eller flera poster. Du kan välja något av följande från listan:
- Ignorera: Uppgiften fortsätter och felet ignoreras.
- Logga post i undantagstabellen (standard): Uppgiften fortsätter och felet skrivs till undantagstabellen.
- Inaktivera tabell: Uppgiften fortsätter men data från tabellen med felposten flyttas till ett feltillstånd och dess data replikeras inte
- Stoppa uppgift: Uppgiften stoppas och manuellt ingrepp krävs.
För övriga datafel: Välj vad du vill ska hända när ett fel sker i en eller flera poster. Du kan välja något av följande från listan:
- Ignorera: Uppgiften fortsätter och felet ignoreras.
- Logga post i undantagstabellen (standard): Uppgiften fortsätter och felet skrivs till undantagstabellen.
- Inaktivera tabell: Uppgiften fortsätter men data från tabellen med felposten flyttas till ett feltillstånd och dess data replikeras inte
- Stoppa uppgift: Uppgiften stoppas och manuellt ingrepp krävs.
Eskalera felhantering när övriga datafel når (per tabell) : Välj den här kryssrutan för att eskalera felhantering när antalet icke-trunkeringsdatafel (per tabell) når det angivna antalet: Giltiga värden är 1–10 000.
Eskaleringsåtgärd: Välj vad som ska hända när felhantering eskaleras. Observera att de tillgängliga åtgärderna beror på vilken åtgärd som väljs från listrutan För övriga datafel som beskrivs ovan.
-
Inaktivera tabell (standard): Uppgiften fortsätter men data från tabellen med felposten flyttas till ett feltillstånd och dess data flyttad inte.
Anteckning om informationBeteendet skiljer sig åt beroende på ändringsbearbetningsläge:
-
I Transaktionell tillämpning-läget kommer de senaste ändringarna inte att flyttad.
-
I Batchoptimerad tillämpning kan en situation uppstå där data inte flyttad alls, eller bara delvis flyttad.
-
- Stoppa uppgift: Uppgiften stoppas och manuellt ingrepp krävs.
- Logga post i undantagstabellen: Uppgiften fortsätter och posten skrivs till undantagstabellen.
Tabellfel
Antal försök innan ett tabellfel returneras
Det här alternativet låter dig styra när principen för hantering av tabellfel ska utlösas. Som standard, efter att ett tabellfel uppstått, kommer tabellen att pausas eller uppgiften att stoppas (enligt den valda åtgärden) efter tre försök. Ibland uppstår ett tabellfel på grund av planerat underhåll av SaaS-applikationen. I dessa fall kanske standardantalet försök inte räcker för att underhållet ska slutföras innan principen för hantering av tabellfel utlöses. Detta beror också på uppgiftens schemaläggningsintervall, eftersom ett nytt försök kommer att utföras varje gång uppgiften körs. Så, till exempel, om du schemalägger en uppgift att köras varje timme och SaaS-applikationen tas offline för underhåll precis när uppgiften börjar köras, kommer standardinställningen med tre försök att tillåta att SaaS-applikationen är offline i upp till tre timmar utan att principen för hantering av tabellfel utlöses. Ett längre underhållsfönster skulle kräva att du ökar antalet försök (eller ändrar schemaläggningen) för att förhindra att principen för hantering av tabellfel utlöses.
Sammanfattningsvis, om du är medveten om att din SaaS-applikation genomgår periodiskt underhåll, är bästa praxis att öka antalet försök enligt schemaläggningen så att underhållet kan slutföras utan att principen för hantering av tabellfel utlöses.
-
Det här alternativet visas endast för uppgifter som är konfigurerade med en Lite- eller Standard SaaS-applikationskoppling.
-
Om du använder Data Movement gateway krävs version 2024.11.70 eller senare.
När du stöter på ett tabellfel: välj något av följande från listrutan:
- Stänga av tabell (standard): uppgiften fortsätter men data från tabellen med felposten flyttas till ett feltillstånd och dess data replikeras inte.
- Stoppa uppgift : uppgiften stoppas och manuellt ingrepp krävs.
Eskalera felhantering när tabellfel når (per tabell): välj den här kryssrutan för att eskalera felhantering när antalet tillämpningskonflikter (per tabell) når det angivna antalet. Giltiga värden är 1–10 000.
Eskaleringspolicy: eskaleringspolicyn för tabellfel är inställd på Stoppa uppgift och kan inte ändras.
Tillämpningskonflikter
Ingen post hittades för tillämpning av en DELETE: Välj vilken åtgärd som vidtas när det uppstår en konflikt med en DELETE-åtgärd.
- Ignorera: Uppgiften fortsätter och felet ignoreras.
- Logga post till undantagstabellen: Uppgiften fortsätter och posten skrivs till undantagstabellen.
- Pausa tabell: Uppgiften fortsätter men data från tabellen med felposten flyttas till ett feltillstånd och dess data replikeras inte.
- Stoppa uppgift: Uppgiften stoppas och manuellt ingripande krävs.
Eskalera felhantering när tillämpningskonflikter når (per tabell): Markera den här kryssrutan för att eskalera felhanteringen när antalet tillämpningskonflikter (per tabell) når det angivna antalet. Giltiga värden är 1–10 000.
Eskaleringsåtgärd: Välj vad som ska hända när felhanteringen eskaleras:
- Logga post till undantagstabellen (standard): Uppgiften fortsätter och felet skrivs till undantagstabellen.
-
Pausa tabell: Uppgiften fortsätter, men data från tabellen med felposten flyttas till ett feltillstånd och dess data replikeras inte.
Anteckning om informationBeteendet skiljer sig åt beroende på läget för ändringsbearbetning:
-
I läget Transaktionell tillämpning kommer de senaste ändringarna inte att replikeras
-
I läget Satsoptimerad tillämpning är en situation möjlig där det inte sker någon replikering av data eller där datareplikeringen blir partiell.
-
-
Stoppa uppgift: Uppgiften stoppas och manuellt ingripande krävs.
Miljöfel
-
Maximalt antal nya försök: Välj det här alternativet och ange sedan det maximala antalet försök att utföra en uppgift igen när ett återställningsbart miljöfel inträffar. Efter att uppgiften har försökt utföras det angivna antalet gånger stoppas uppgiften och manuellt ingrepp krävs.
För att aldrig försöka utföra uppgiften igen avmarkerar du kryssrutan eller anger "0".
För att försöka utföra uppgiften ett oändligt antal gånger anger du "-1".
-
Mellanrum mellan försök (sekunder): Använd räknaren för att välja eller ange antalet sekunder som systemet väntar mellan försöken att utföra en uppgift.
Giltiga värden är 0–2 000.
-
- Förläng intervallet mellan försök vid långa avbrott: Välj den här kryssrutan för att förlänga intervallet mellan försök vid långa avbrott. När det här alternativet är aktiverat fördubblas intervallet mellan varje försök tills Maximalt intervall nås (och fortsätter att försöka enligt det angivna maximala intervallet).
- Maximalt intervall mellan försök (sekunder): Använd räknaren för att välja eller ange antalet sekunder för väntetiden mellan försöken att utföra en uppgift när alternativet Förläng intervallet för nytt försök vid långa avbrott är aktiverat. Giltiga värden är 0–2 000.
Justering av ändringsbearbetning
Justering av transaktionsavlastning
-
Avlasta pågående transaktion till disk om:
Replikeringsuppgiften behåller vanligtvis transaktionsdata i minnet tills den är helt bekräftad till källan och/eller målet. Transaktioner som är större än det tilldelade minnet eller som inte bekräftas inom den angivna tidsgränsen kommer dock att avlastas till disk.
- Transaktionsminnesstorlek överstiger (MB): Den maximala storlek som alla transaktioner kan uppta i minnet innan de avlastas till disk. Standardvärdet är 1024.
- Transaktionens varaktighet överstiger (sekunder): Den maximala tid som varje transaktion kan stanna i minnet innan den avlastas till disk. Varaktigheten beräknas från den tidpunkt då replikeringsuppgiften började fånga transaktionen. Standardvärdet är 60.
Satsjustering
Inställningarna på den här fliken bestäms av läget Tillämpa ändringar.
Inställningar som endast är tillgängliga när "Tillämpningsläge" är "Satsoptimerat"
- Tillämpa satsändringar i intervaller:
-
Större än: Den minsta tid att vänta mellan varje tillämpning av satsändringar. Standardvärdet är 1.
Att öka värdet för Längre än minskar frekvensen med vilken ändringar tillämpas på målet samtidigt som storleken på satserna ökar. Detta kan förbättra prestandan när ändringar tillämpas på måldatabaser som är optimerade för att bearbeta stora satser.
- Mindre än: Den maximala tid att vänta mellan varje tillämpning av satsändringar (innan en timeout deklareras). Med andra ord, den maximala acceptabla latensen. Standardvärdet är 30. Detta värde bestämmer den maximala tid att vänta innan ändringarna tillämpas, efter att värdet för Längre än har uppnåtts.
-
Tvinga tillämpning av en sats när bearbetningsminnet överstiger (MB): Den maximala mängd minne som ska användas för förbearbetning i Satsoptimerat tillämpningsläge. Standardvärdet är 500.
För maximal satsstorlek, ställ in detta värde på den högsta mängd minne du kan tilldela replikeringsuppgiften. Detta kan förbättra prestandan när ändringar tillämpas på måldatabaser som är optimerade för att bearbeta stora satser.
Inställningar som endast är tillgängliga när "Tillämpningsläge" är "Transaktionellt"
Följande inställningar är endast tillämpliga när du arbetar i "Transaktionellt" tillämpningsläge. Observera att "Transaktionellt" är det enda tillgängliga tillämpningsläget (och därför inte valbart) vid replikering till Snowflake, och Laddningsmetod är Snowpipe-strömning.
-
Maximalt antal ändringar per transaktion: Det minsta antalet ändringar som ska tas med i varje transaktion. Som standard är värdet 1000.
Anteckning om informationÄndringarna tillämpas i målet antingen när antalet ändringar är lika med eller större än värdet Minsta antalet ändringar per transaktion ELLER när värdet Maximal tid att samla transaktioner i batcher före tillämpning (sekunder) som beskrivs nedan nås, beroende på vilket som kommer först. Eftersom frekvensen av ändringar som tillämpas på målet styrs av dessa två parametrar kommer ändringar i källposterna eventuellt inte att återspeglas omedelbart i målposterna.
- Maxtid att samla transaktioner i batcher före tillämpning (sekunder): maxtiden för att samla transaktioner i batcher innan en tidsgräns överskrids. Som standard är värdet 1.
Intervall
Inställningar vid användning av SAP ODP- och SaaS (Lite)-applikationskopplingar
-
Läs in ändringar var (minuter)
Ställ in antal minuter för intervallet mellan inläsning av ändringar från källan. Giltigt intervall är 1 till 1 440.
Anteckning om informationDet här alternativet är endast tillgängligt när dataarbetsuppgiften definieras med:
- Data Movement gateway
- Någon av följande källor:
- SaaS-applikation endast via Lite-kopplingar
- SAP ODP
- Uppdateringsmetoden Tillämpa ändringar eller Lagra ändringar
Inställningar vid användning av SAP OData-kopplingen
Kontrollera om det finns ändringar
-
I enlighet med intervallet för deltaextraheringNär det här alternativet är valt kontrollerar datauppgiften om det finns ändringar enligt intervallet för deltaextrahering.
Anteckning om informationIntervallet startar efter varje ”runda”. En runda kan definieras som den tid det tar för datauppgiften att läsa ändringarna från källtabellerna och skicka dem till målet (som en enskild transaktion). Längden på en runda varierar beroende på antalet tabeller och ändringar. Så om du anger ett intervall på 10 minuter och en runda tar 4 minuter, kommer den faktiska tiden mellan kontrollerna efter ändringar att vara 14 minuter.-
Intervall för deltaextrahering: Frekvensen med vilken deltan kommer att extraheras från ditt system. Standardtiden är var 60:e sekund.
-
-
Enligt schema: När det här alternativet är valt kommer datauppgiften att extrahera deltat en gång och sedan stoppa. Den kommer sedan att fortsätta att köras enligt schema.
Anteckning om informationDet här alternativet är endast relevant om intervallet mellan CDC-cyklerna är 24 timmar eller mer.För information om schemaläggning:
-
"Replikera data-uppgifter" i ett replikeringsprojekt, se Schemalägga uppgifter
-
Diverse justeringar
Cachestorlek för satser (antal satser)
Det maximala antalet förberedda satser att lagra på servern för senare körning (när ändringar tillämpas på målet). Standard är 50. Max är 200.
DELETE och INSERT vid uppdatering av en primärnyckelkolumn
Detta alternativ kräver att fullständig kompletterande loggning är aktiverad i källdatabasen.
Skicka tombstone vid DELETE
När detta alternativ är valt kommer endast meddelandenyckeln att fyllas i; själva meddelandet kommer att vara null, vilket indikerar att objektet har tagits bort. Detta kan hjälpa konsumenter att upptäcka att en DELETE-åtgärd har utförts.
Lagra återställningsdata för uppgift i måldatabas
Välj detta alternativ för att lagra uppgiftsspecifik återställningsinformation i måldatabasen. När detta alternativ är valt skapar replikeringsuppgiften en tabell med namnet attrep_txn_state i måldatabasen. Denna tabell innehåller transaktionsdata som kan användas för att återställa en uppgift i händelse av att filerna i mappen Data Movement gateway Data är skadade eller om lagringsenheten som innehåller mappen Data har kraschat.
Tillämpa ändringar med SQL MERGE
När detta alternativ inte är valt kommer replikeringsuppgiften att köra separata bulk-INSERT-, UPDATE- och DELETE-satser för var och en av de olika ändringstyperna i nettoändringstabellen.
Även om denna metod är mycket effektiv, är det ännu mer effektivt att aktivera alternativet Tillämpa ändringar med SQL MERGE när du arbetar med slutpunkter som stöder detta alternativ.
Detta beror på följande skäl:
- Det minskar antalet SQL-satser som körs per tabell från tre till en. De flesta UPDATE-åtgärder i stora, oföränderliga, filbaserade molndatabaser (som Google Cloud BigQuery) innebär omskrivning av påverkade filer. Med sådana åtgärder är minskningen av SQL-satser per tabell från tre till en mycket betydande.
- Måldatabasen behöver bara skanna nettoändringstabellen en gång, vilket avsevärt minskar I/O.
Optimera infogningar
När Tillämpa ändringar med SQL MERGE är valt tillsammans med alternativet Optimera infogningar och ändringarna endast består av INSERT-åtgärder, kommer replikeringsuppgiften att utföra INSERT-åtgärder istället för att använda SQL MERGE. Observera att även om detta vanligtvis förbättrar prestandan och därmed minskar kostnaderna, kan det också resultera i dubblettposter i måldatabasen.
- Alternativen Tillämpa ändringar med SQL MERGE och Optimera infogningar är endast tillgängliga för uppgifter som konfigurerats med följande målslutpunkter:
- Google Cloud BigQuery
- Databricks
- Snowflake
- Alternativen Tillämpa ändringar med SQL MERGE och Optimera infogningar stöds inte med följande källslutpunkter:
- Salesforce
- Oracle
-
När alternativet Tillämpa ändringar med SQL MERGE är aktiverat:
- Icke-kritiska datafel eller datafel som inte kan återställas kommer att hanteras som tabellfel.
- Felhanteringspolicyn för tillämpningskonflikter kommer att vara icke-redigerbar med följande inställningar.
- Ingen post hittades för tillämpning av DELETE: Ignorera post
Dubblettnyckel vid tillämpning av INSERT: UPPDATERA den befintliga målposten
Anteckning om informationOm alternativet Optimera infogningar också är valt kommer alternativet Dubblettnyckel vid tillämpning av INSERT att ställas in på Tillåt dubbletter i mål.- Ingen post hittades för tillämpning av en UPDATE: INFOGA den saknade målposten
- Eskaleringsåtgärd: Logga post till undantagstabell
- Följande alternativ för För andra datafel i felhanteringspolicyn för data kommer inte att vara tillgängliga:
- Ignorera post
- Logga post till undantagstabellen
- Själva SQL MERGE-åtgärden kommer endast att utföras på de slutliga måltabellerna. INSERT-åtgärder kommer att utföras på de mellanliggande ändringstabellerna (när replikeringslägena Tillämpa ändringar eller Lagra ändringar är aktiverade).
Transaktionell tillämpning
Vid replikering till datalagermål eller vid arbete utan Data Movement gateway är dessa alternativ inte relevanta eftersom Tillämpningsläge alltid är Satsoptimerat, med ett undantag.
Undantaget från detta är vid replikering till Snowflake och Laddningsmetod är inställd på Snowpipe-strömning.
Följande inställningar är endast tillgängliga när du arbetar i transaktionellt tillämpningsläge. Vid replikering till databaser kan Tillämpningsläge ställas in på antingen Satsoptimerat eller Transaktionellt. Men vid replikering till Snowflake-mål och Laddningsmetod är inställd på Snowpipe-strömning är tillämpningsläget alltid transaktionellt och kan därför inte ställas in.
-
Minsta antal ändringar per transaktion: Det minsta antalet ändringar som ska inkluderas i varje transaktion. Standardvärdet är 1000.
Anteckning om informationReplikeringsuppgiften tillämpar ändringarna på målet antingen när antalet ändringar är lika med eller större än värdet för Minsta antal ändringar per transaktion ELLER när timeout-värdet för satsen uppnås (se nedan) - beroende på vilket som inträffar först. Eftersom frekvensen av ändringar som tillämpas på målet styrs av dessa två parametrar, kanske ändringar i källposterna inte omedelbart återspeglas i målposterna. - Maximal tid att samla transaktioner i satser innan tillämpning (sekunder): Den maximala tiden att samla transaktioner i satser innan en timeout deklareras. Standardvärdet är 1.
Schemautveckling
Välj hur följande typer av DDL-ändringar i schemat ska hanteras. När du har ändrat inställningarna för schemautveckling måste du förbereda uppgiften igen. Tabellen nedan beskriver vilka åtgärder som är tillgängliga för de DDL-ändringar som stöds.
-knapp, både i dialogrutan Skapa koppling och i onlinehjälpen.| DDL-ändring | Tillämpa på mål | Ignorera | Pausa tabell | Stoppa uppgift |
|---|---|---|---|---|
| Lägg till kolumn | Ja | Ja | Ja | Ja |
| Ändra kolumndatatyp | Ja | Ja | Ja | Ja |
| Byt namn på kolumn | Ja | Nej | Ja | Ja |
|
Byt namn på tabell Anteckning om informationStöds inte när Kafka är målplattformen.
|
Nej | Nej | Ja | Ja |
| Ta bort kolumn | Ja | Ja | Ja | Ja |
|
Ta bort tabell Anteckning om informationStöds inte när Kafka är målplattformen.
|
Ja | Ja | Ja | Ja |
| Skapa tabell
Om du använde en Urvalsregel för att lägga till dataset som matchar ett mönster, kommer nya tabeller som uppfyller mönstret att upptäckas och läggas till. |
Ja | Ja | Nej | Nej |
Teckenersättning
Du kan ersätta eller ta bort källtecken i måldatabasen och/eller du kan ersätta eller ta bort källtecken som inte stöds av en vald teckenuppsättning.
-
Alla tecken måste anges som Unicode-kodpunkter.
- Teckenersättning kommer också att utföras på -kontrolltabellerna.
-
Ogiltiga värden anges med en röd triangel uppe till höger på tabellcellen. Hovra med muspekaren över triangeln för att visa felmeddelandet.
-
Alla omvandlingar på tabellnivå eller globalt som definierats för uppgiften kommer att utföras efter att teckenersättningen har slutförts.
-
Ersättningsåtgärder som definierats i tabellen Ersätt eller ta bort källtecken utförs innan ersättningsåtgärden som definierats i tabellen Ersätt eller ta bort källtecken som inte stöds av en vald teckenuppsättning.
- Teckenersättningen har inte stöd för LOB-datatyper.
Byta ut eller radera källtecken
Använd tabellen Ersätt eller ta bort källtecken för att definiera ersättningar för specifika källtecken. Detta kan exempelvis vara användbart när Unicode-representationen av ett tecken är olika på käll- och målplattformarna. Exempelvis visas minustecknet i teckenuppsättningen Shift_JIS som U+2212 på Linux, men på Windows visas det som U+FF0D.
| Till | Gör så här |
|---|---|
|
Definiera ersättningsåtgärder |
|
|
Redigera det angivna käll- eller måltecknet |
Klicka på |
|
Ta bort poster från tabellen |
Klicka på |
Ersätta eller ta bort källtecken som inte stöds av den valda teckenuppsättningen.
Använd tabellen Källtecken som inte stöds av teckenuppsättning för att definiera ett enda ersättningstecken för alla tecken som inte stöds av den valda teckenuppsättningen.
| Till | Gör så här |
|---|---|
|
Definiera eller redigera en ersättningsåtgärd |
|
|
Inaktivera ersättningsåtgärden. |
Välj den tomma posten från listrutan Teckenuppsättning. |
Fler alternativ
Dessa alternativ visas inte i gränssnittet eftersom de bara är relevanta för specifika versioner eller miljöer. Konfigurera därför inte dessa alternativ om du inte uttryckligen har blivit instruerad att göra det av Qlik Support eller om det står i produktdokumentationen.Qlik
För att ställa in ett alternativ kopierar du bara alternativet i fältet Lägg till funktionsnamn och klickar på Lägg till. Ställ sedan in värdet eller aktivera alternativet enligt de instruktioner du har fått.
Ladda datasetsegment parallellt
Under fullständig laddning kan du påskynda laddningen av stora dataset genom att dela upp datasetet i segment, som kommer att laddas parallellt. Tabeller kan delas upp efter dataintervall, alla partitioner, alla underpartitioner eller specifika partitioner.
För mer information, se Parallell replikering av datauppsättningssegment.
Schemalägga uppgifter
I följande användningsfall måste du definiera ett schemaläggningsintervall för att uppdatera målet med ändringar som gjorts i källan:
- Åtkomst till en datakälla utan Data Movement gateway
- Användning av en förhandsgranskningskoppling för SaaS-applikationer. Förhandsgranskningskopplingar indikeras med en -knapp, både i dialogrutan Skapa koppling och i onlinehjälpen.
- När ändringar fångas från en SAP OData-källa med alternativet Enligt schema.
Schemat bestämmer hur ofta måldataseten kommer att uppdateras med ändringar i källdataseten. Medan schemat bestämmer uppdateringsfrekvensen, bestämmer datasettypen uppdateringsmetoden. Om källdataseten stöder CDC (Change data capture) kommer endast ändringarna i källdata att replikeras och tillämpas på motsvarande måltabeller. Om källdataseten inte stöder CDC (till exempel vyer) kommer ändringar att tillämpas genom omladdning av alla källdata till motsvarande måltabeller. Om vissa av källdataseten stöder CDC och andra inte, kommer två separata underuppgifter att skapas (förutsatt att replikeringsalternativen Tillämpa ändringar eller Lagra ändringar är valda): en för att ladda om de dataset som inte stöder CDC, och den andra för att fånga ändringarna i dataset som stöder CDC. I det här fallet, för att säkerställa datakonsistens, rekommenderas det starkt att inte behålla samma schemaläggningsintervall för båda uppgifterna (om du bestämmer dig för att ändra uppdateringsfrekvensen i framtiden).
Information om minsta schemaläggningsintervall beroende på typ av datakälla och prenumerationsnivå finns i Minsta tillåtna schemaläggningsintervall.
För att ändra schemaläggningen:
-
Öppna ditt projekt och gör sedan något av följande:
- I uppgiftsvyn klickar du på
 på en replikeringsuppgift och väljer Schemaläggning.
på en replikeringsuppgift och väljer Schemaläggning. - I pipeline-vyn klickar du på
 på en replikeringsuppgift och väljer Schemaläggning.
på en replikeringsuppgift och väljer Schemaläggning. - Öppna replikeringsuppgiften och klicka på verktygsfältsknappen Schemaläggning .
- I uppgiftsvyn klickar du på
- Ändra schemaläggningsinställningarna efter behov och klicka sedan på OK.
Köra en missad körning för en uppgift baserad på Data Movement gateway
Ibland kan ett nätverksproblem leda till att kopplingen till Data Movement gateway går förlorad. Om kopplingen till Data Movement gateway inte återställs före nästa schemalagda körning kommer inte dataaktiviteten att kunna köras som schemalagt. I sådana fall kan du välja om du vill köra en körning eller inte omedelbart efter att kopplingen har återställts.
Standardinställningarna för alla Data Movement gateways är definierade i aktivitetscentret Administration. Du kan åsidosätta dessa inställningar för enskilda uppgifter enligt beskrivningen nedan.
För att göra detta
-
Öppna ditt projekt och gör sedan något av följande:
-
I uppgiftsvyn klickar du på
på datauppgiften och väljer Schemaläggning. -
I pipeline-vyn klickar du på
på datauppgiften och väljer Schemaläggning. -
Öppna datauppgiften och klicka på verktygsfältsknappen Schemaläggning .
Dialogrutan Schemaläggning - <uppgift> öppnas.
-
-
Slå på Använd anpassade inställningar för den här uppgiften.
-
Längst ner i dialogrutan väljer du ett av följande alternativ för Kör missade schemalagda uppgifter.
-
Så snart som möjligt och sedan enligt schema om det är viktigt att köra en uppgift före nästa schemalagda instans
-
Enligt schema för att köra uppgiften vid nästa schemalagda instans
-
-
Spara dina inställningar.
Se även: Utförande av en uppgiftskörning efter ett missat schema.