
Configurações de replicação
Você pode definir configurações para a tarefa de replicação de dados.
-
Abra a tarefa de replicação e clique em Configurações na barra de ferramentas.
O diálogo Configurações: <Task-Name> é aberto. As configurações disponíveis estão descritas abaixo.
Geral
Nesta guia, você pode alterar o modo de replicação, as configurações de preparação (quando disponíveis), o modo de aplicação das alterações ao destino e as configurações de publicação.
Modo de replicação
Os seguintes modos de replicação estão disponíveis:
-
Carga total: Carrega os dados das tabelas de origem selecionadas na plataforma de destino e cria as tabelas de destino, se necessário. O carregamento total ocorre automaticamente quando a tarefa é iniciada, mas também pode ser realizado manualmente se necessário. O carregamento total manual seria necessário, por exemplo, se você precisasse replicar atualizações em visualizações (que não são capturadas durante a CDC) ou se estivesse replicando de uma fonte de dados que não aceita CDC.
Nota informativaAo usar um conector de aplicativo SaaS, esta opção estará sempre ativada, pois o carregamento total é necessário. -
Aplicar alterações: Mantém as tabelas de destino atualizadas com quaisquer alterações feitas nas tabelas de origem.
-
Armazenar alterações: Armazena as alterações nas tabelas de origem em Tabelas de alterações (uma por tabela de origem).
Para obter mais informações, consulte Salvar alterações.
Ao trabalhar com Gateway Data Movement, exceto ao usar fontes de aplicativos SaaS, as alterações são capturadas da fonte quase em tempo real. Ao trabalhar sem Gateway Data Movement (por exemplo, com uma assinatura do Iniciante do Qlik Talend Cloud ou ao selecionar Nenhum) ou ao usar fontes de aplicativos SaaS, as alterações são capturadas de acordo com as configurações do agendador. Para obter mais informações, consulte Scheduling tasks.
Se você selecionar Armazenar alterações ou Aplicar alterações, e sua fonte de dados:
-
Não é um aplicativo SaaS
-
Contém conjuntos de dados que suportam CDC e conjuntos de dados que suportam apenas carregamento total (como exibições)
Duas pipelines de dados serão criadas. Um pipeline será criado para tabelas que suportam CDC, e outro pipeline será criado para conjuntos de dados que suportam apenas Carregamento total.
Método de carregamento
Ao replicar para o Snowflake, você pode escolher um dos seguintes métodos de carregamento:
-
Carregamento em massa (o padrão)
Ao selecionar Carregamento em massa, você poderá ajustar os parâmetros de carregamento na guia Carregamento de dados.
-
Snowpipe Streaming
Nota informativaO Snowpipe Streaming só estará disponível para seleção se as condições a seguir forem atendidas:
- O modo de replicação Armazenar alterações está habilitado, sem Aplicar alterações.
- O Mecanismo de autenticação no conector Snowflake está definido como Par de chaves.
- Se você estiver usando o Gateway Data Movement, será necessária a versão 2024.11.45 ou posterior.
Se você selecionar Snowpipe Streaming, certifique-se de estar familiarizado com as limitações e considerações ao usar esse método. Além disso, se você selecionar Snowpipe Streaming e, em seguida, ativar o modo de replicação Aplicar alterações ou desativar Armazenar alterações, o método de carregamento voltará automaticamente para Carregamento em massa.
Os principais motivos para escolher o Snowpipe Streaming em vez do Carregamento em massa são os seguintes:
-
Menos dispendioso: como o Snowpipe Streaming não usa o armazém do Snowflake, os custos operacionais devem ser significativamente mais baratos, embora isso dependa do seu caso de uso específico.
-
Latência reduzida: como os dados são transmitidos diretamente para as tabelas de destino (em vez de via preparação), a replicação da fonte de dados para o destino deve ser mais rápida.
Conectando-se a uma área de teste
Ao replicar para os armazéns de dados listados abaixo, você precisa definir uma área de teste. Os dados são processados e preparados na área de preparação antes de serem transferidos para o armazém.
Selecione uma área de preparação existente ou clique em Criar nova para definir uma nova área de preparação e siga as instruções em Conectando ao armazenamento na nuvem.
Para editar as configurações de conexão, clique em Editar. Para testar a conexão (recomendado), clique em Testar conexão.
Para obter informações sobre quais áreas de preparo são suportadas com quais armazéns de dados, consulte a coluna Compatível como uma área de teste em Casos de uso da plataforma alvo e versões compatíveis.
Aplicar modo de alterações
As alterações são aplicadas às tabelas de destino usando um dos seguintes métodos:
- Otimizado para batch: Este é o padrão. Quando essa opção é selecionada, as alterações são aplicadas em lotes. Ocorre uma ação de pré-processamento para agrupar as transações em lotes da maneira mais eficiente.
- Transacional: Selecione essa opção para aplicar cada transação individualmente, na ordem em que ela for confirmada. Nesse caso, a integridade referencial estrita é garantida para todas as tabelas.
Configurações de publicação
-
Publicar no catálogo
Selecione esta opção para publicar esta versão dos dados no Catálogo como um conjunto de dados. O conteúdo do Catálogo será atualizado na próxima vez que você preparar esta tarefa.
Para obter mais informações sobre o Catálogo, consulte Compreendendo seus dados com ferramentas de catálogo.
Configurações de proxy ao usar o Gateway Data Movement
-
Ao usar o Data Movement gateway, conecte-se via proxy a
Ao usar o Gateway Data Movement, você pode se conectar à plataforma de destino e à plataforma (área) de teste via proxy.
Para obter mais informações sobre como configurar o Gateway Data Movement para usar um servidor proxy, consulte Configurando o locatário do Qlik Cloud e um servidor proxy.
-
Plataforma de destino
Nota informativaDisponível ao usar o Snowflake e o Databricks. -
Plataforma de teste
Nota informativaDisponível ao usar o Google BigQuery, o Amazon Redshift, o Microsoft Fabric e o Databricks.
-
Upload de dados
Esta guia só será mostrada durante a replicação para um destino de armazém de dados ou Kafka. Além disso, as configurações nesta guia serão diferentes de acordo com o destino selecionado.
Relevante para todos os destinos de armazém de dados
Tamanho máximo do arquivo
O tamanho máximo que um arquivo pode atingir antes de ser fechado. Arquivos menores podem ser carregados mais rapidamente (dependendo da rede) e melhorar o desempenho quando usados em conjunto com a opção de execução paralela. No entanto, geralmente é considerado uma má prática sobrecarregar o banco de dados com arquivos pequenos.
Relevante apenas para destino do Snowflake
Na guia Geral, você pode selecionar se deseja carregar os dados para o Snowflake usando o Carregamento em massa ou o Snowpipe Streaming. Quando o Snowpipe Streaming estiver selecionado, a guia Carregamento de dados não será exibida. Quando a opção Carregamento em massa for selecionada, as configurações a seguir estarão disponíveis:
-
Tamanho máximo do arquivo (MB): Relevante para a Carga Completa inicial e CDC. O tamanho máximo que um arquivo pode atingir antes de ser carregado para o destino. Se você encontrar problemas de desempenho, tente ajustar esse parâmetro.
-
Número de arquivos a carregar em um lote: Relevante apenas para a Carga Completa inicial. O número de arquivos a serem carregados em um único lote. Se você encontrar problemas de desempenho, tente ajustar esse parâmetro.
Para obter uma descrição dos métodos de carregamento Carregamento em massa e Snowpipe Streaming, consulte Geral.
Relevante apenas para destino Kafka
Propriedades da mensagem
Compactação
Opcionalmente, selecione um dos métodos de compressão disponíveis (Snappy ou Gzip). O padrão é Nenhum.
Publicação de mensagens de dados
Escolha uma das seguintes opções de Publicar os dados em:
- Tópico específico: Publica os dados em um único tópico. Digite um nome de tópico ou use o botão de procurar para selecionar o tópico desejado.
-
Tópico separado para cada tabela: Publica os dados em vários tópicos correspondentes aos nomes das tabelas de origem.
O nome do topic de destino consiste no nome do esquema de origem e no nome da tabela de origem, separados por um ponto (por exemplo, dbo.Employees). O formato do nome do topic de destino é importante, pois você precisará preparar estes topics com antecedência.
Se os tópicos não existirem, configure os brokers com auto.create.topics.enable=true para permitir que a tarefa de dados crie os tópicos durante a execução. Caso contrário, a tarefa falhará.
Para obter informações sobre como substituir essa configuração no nível do conjunto de dados, consulte Substituindo configurações de tarefa para conjuntos de dados individuais ao publicar no Kafka
Chave da mensagem
Selecione uma das opções disponíveis.
-
Colunas da chave primária: Para cada mensagem, a chave de mensagem conterá o valor da coluna da chave primária.
Quando Por chave de mensagem for selecionado como a Estratégia de partição, as mensagens com o mesmo valor de chave primária serão gravadas na mesma partição.
-
Esquema e nome da tabela: Para cada mensagem, a chave de mensagem conterá uma combinação de esquema e nome da tabela (por exemplo, dbo+Employees).
Quando Por chave de mensagem for selecionado como a Estratégia de partição, as mensagens com o mesmo nome de esquema e de tabela serão gravadas na mesma partição.
- Nenhum: Cria mensagens sem uma chave de mensagem.
Para obter informações sobre como substituir essa configuração no nível do conjunto de dados, consulte Substituindo configurações de tarefa para conjuntos de dados individuais ao publicar no Kafka
Estratégia de particionamento
Selecione Aleatório ou Por chave de mensagem. Se você selecionar Aleatório, cada mensagem será gravada em uma partição selecionada aleatoriamente. Se você selecionar Por chave de mensagem, as mensagens serão gravadas em partições com base na Chave de mensagem (descrita acima).
Publicação de mensagens de metadados
Estratégia de nome do assunto
A primeira estratégia (Nome do esquema e da tabela) é uma estratégia de propriedade da Qlik, enquanto as outras três são estratégias padrão de nome de assunto da Confluent.
Selecione uma das estratégias de nome de assunto disponíveis.
- Nome do esquema e da tabela (padrão)
- Nome do tópico
- Nome do registro
- Nome do tópico e do registro
Para mais informações sobre as estratégias de nome de assunto da Confluent, consulte Estratégia de nome de assunto
Modo de compatibilidade de assunto
Selecione um dos seguintes modos de compatibilidade na lista suspensa Modo de compatibilidade de assunto:
-
Usar padrões do Schema Registry: Recupera o nível de compatibilidade da configuração do servidor de registro de esquemas.
-
Retroativo - Somente o esquema mais recente: Novos esquemas podem ler dados correspondentes e dados produzidos somente pelo esquema registrado mais recente.
-
Transitivo Retroativo - Todos os esquemas anteriores: Novos esquemas podem ler dados produzidos por todos os esquemas registrados anteriormente.
-
Avançar - Somente o esquema mais recente: O esquema registrado mais recentemente pode ler os dados produzidos pelo novo esquema.
-
Transitivo Direto - Todos os esquemas anteriores: Todos os esquemas previamente registrados podem ler os dados produzidos pelo novo esquema.
-
Completo - Somente o esquema mais recente: O novo esquema é compatível com versões anteriores e futuras do esquema registrado mais recente.
-
Transitivo Completo - Todos os esquemas anteriores: O novo esquema é compatível com versões anteriores e futuras de todos os esquemas previamente registrados.
-
Nenhum
- Dependendo da Estratégia de nome de assunto selecionada, alguns dos modos de compatibilidade podem não estar disponíveis.
-
Ao publicar mensagens em um registro de esquemas, o modo de compatibilidade de assunto padrão para todos os Assuntos da tabela de controle recém-criados será Nenhum, independentemente do Modo de compatibilidade de assunto selecionado.
Se você quiser que o Modo de compatibilidade de assunto selecionado também se aplique às tabelas de controle, defina o parâmetro interno setNonCompatibilityForControlTables no conector de destino Kafka como false.
Use um proxy para conectar-se ao Confluent Schema Registry
Esta opção é suportada apenas ao publicar no Confluent Schema Registry.
Ative se o seu Gateway Data Movement estiver configurado para usar um servidor proxy.
Atributos da mensagem
Você pode especificar atributos de mensagem personalizada que substituirão os atributos de mensagem padrão. Isso é útil se o aplicativo consumidor precisar processar a mensagem em um formato específico.
Atributos de mensagem personalizada podem ser definidos nos níveis de tarefa e de tabela. Quando os atributos são definidos nos níveis de tarefa e de tabela, os atributos de mensagem definidos para a tabela terão precedência sobre os definidos para a tarefa.
Para obter informações sobre como substituir os atributos de mensagem no nível do conjunto de dados, consulte Substituindo configurações de tarefa para conjuntos de dados individuais ao publicar no Kafka
Mensagens estruturadas hierárquicas não são aceitas.
Regras gerais e diretrizes de uso
Ao definir uma mensagem personalizada, é importante considerar as regras e diretrizes de uso listadas abaixo.
Nomes de seção
Aplicam-se as seguintes regras de nomenclatura:
- Nomes de seção devem começar com os caracteres a-z, A-Z ou _ (um sublinhado) e podem então ser seguidos por qualquer um dos seguintes caracteres: a-z, A-Z, 0-9, _
- Com exceção do Nome do registro e das Seções de nome da chave (que não terminam com uma barra), remover a barra dos nomes das seções irá nivelar a hierarquia da seção associada (consulte Barras abaixo).
- Todos os nomes de seção, exceto Nome do registro e Nome da chave, podem ser excluídos (consulte Exclusão abaixo)
-
Os nomes de seção Nome dos dados e Incluir dados anteriores do registro não podem ser excluídos juntos
-
Os nomes de seção Nome dos dados e Incluir dados anteriores do registro não podem ser iguais
Alguns dos nomes de seção na UI terminam com uma barra (por exemplo, beforeData/beforeData/). A finalidade da barra é manter uma hierarquia das diferentes seções dentro da mensagem. Se a barra for removida, ocorrerá o seguinte:
- A estrutura hierárquica dessa seção será nivelada, resultando na remoção do nome da seção da mensagem
- O nome da seção será prefixado aos metadados reais, diretamente ou usando um caractere separador (por exemplo, um sublinhado) que você anexou ao nome
Exemplo de uma mensagem de dados quando headers/ é especificado com uma barra:
"message":{
"data":{
"COL1": "159",
"COL2": "159"
},
"beforeData": null,
"headers": {
"operation": "INSERT",
"changeSequence": "2018100811484900000000233",
Exemplo de uma mensagem de dados quando headers_ é especificado com um sublinhado em vez de uma barra:
"message":{
"data":{
"COL1": "159",
"COL2": "159"
},
"beforeData": null,
"headers_operation": "INSERT",
"headers_changeSequence": "2018100811484900000000233",
A exclusão do nome de uma seção da mensagem irá aplanar a estrutura hierárquica dessa seção. Isso fará com que todos os dados dessa seção apareçam imediatamente abaixo do conteúdo da seção anterior.
Exemplo de uma mensagem de dados com o nome da seção headers :
"message":{
"data":{
"COL1": "159",
"COL2": "159"
},
"headers": {
"operation": "INSERT",
"changeSequence": "2018100811484900000000233",
Exemplo de uma mensagem de dados sem o nome da seção headers :
"message":{
"data":{
"COL1": "159",
"COL2": "159"
},
"beforeData": null,
"operation": "INSERT",
"changeSequence": "2018100811484900000000233",
Variáveis
Você pode adicionar variáveis a nomes clicando no botão ![]() no final da linha. As seguintes variáveis estão disponíveis:
no final da linha. As seguintes variáveis estão disponíveis:
- SERVER_NAME - o nome do host do servidor Gateway Data Movement
- TARGET_TABLE_NAME - o nome da tabela
- TARGET_TABLE_OWNER - o proprietário da tabela
- TASK_NAME - o nome da tarefa de dados
A variável TARGET_TABLE_OWNER não está disponível para as opções Nome do registro e Nome da chave (descritas na tabela abaixo).
Definindo atributos de mensagem personalizada
Para definir um formato de mensagem personalizada, ative Usar configurações personalizadas e configure as opções conforme descrito na tabela abaixo.
Para reverter para os atributos de mensagem padrão, desative Usar configurações personalizadas.
| Opção | Descrição |
|---|---|
|
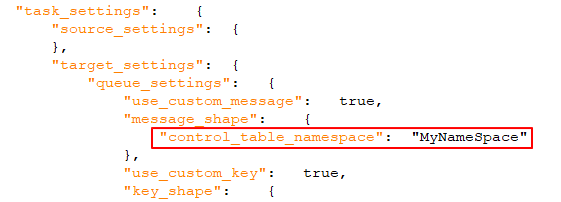
Quando ativado (o padrão), um identificador exclusivo será incluído na mensagem. Deve ser uma string, separada por pontos. Observe que o namespace será incluído tanto na mensagem quanto na chave de mensagem. Exemplo: mycompany.queue.msg Nome padrão: com.attunity.queue.msg.{{TASK_NAME}}.{{TARGET_TABLE_OWNER}}.{{TARGET_TABLE_NAME}} Nome padrão para tabelas de controle: com.attunity.queue.msg.{{TARGET_TABLE_NAME}} Nota informativa
O namespace da tabela de controle padrão não pode ser alterado pela interface do usuário. No entanto, você pode alterar o namespace da tabela de controle padrão da seguinte forma:
|
|
|
Nome do registro |
O nome do registro (mensagem). Nome padrão: DataRecord |
|
Nome de dados |
Todas as colunas de dados incluídas no registro. Nome padrão: data/ |
|
Incluir headers |
Quando ativado (padrão), as colunas de cabeçalho serão incluídas na mensagem. As colunas de cabeçalho fornecem informações adicionais sobre as operações de origem. Para obter mais informações, consulte Incluir os seguintes cabeçalhos abaixo. |
|
Incluir namespace de cabeçalhos |
Quando ativado (padrão), um identificador único para a seção de colunas do cabeçalho será incluído na mensagem. Deve ser uma string, separada por pontos. Exemplo: headers.queue.msg Nome padrão: com.attunity.queue.msg |
|
Nome dos cabeçalhos |
O nome da seção que contém os cabeçalhos de coluna Qlik. Nome padrão: headers/ |
|
Para obter uma descrição das colunas de cabeçalho disponíveis, consulte Mensagens de dados na Qlik Ajuda. Padrão: Todas as colunas são incluídas por padrão, exceto a coluna ID de esquema externo. |
|
|
Incluir dados anteriores do registro |
Quando ativado (o padrão), os dados pré e pós-ATUALIZAÇÃO serão incluídos nas mensagens de ATUALIZAÇÃO. Para incluir apenas os dados pós-ATUALIZAÇÃO nas mensagens, desative a opção. Nome padrão: beforeData/ |
|
Nome da chave |
O nome da seção que contém a chave de mensagem. Nome padrão: keyRecord Esta opção é aplicável apenas quando:
|
Configurações adicionais
-
Tamanho máximo da mensagem
No campo Tamanho máximo da mensagem, especifique o tamanho máximo das mensagens que os brokers estão configurados para receber (message.max.bytes). A tarefa de dados não enviará mensagens maiores que o tamanho máximo.
Metadados do
Básico
-
Esquema da tabela de destino
O esquema no destino para o qual as tabelas de origem serão replicadas se você não quiser usar o esquema da tabela de origem (ou se não houver nenhum esquema no banco de dados de origem).
Nota informativaAo replicar para um destino Oracle, o esquema da tabela de destino padrão é "system". Observe também que, se você deixar este campo vazio (nesse caso, o esquema de origem será usado), você deverá se certificar de que o esquema de origem já existe no destino. Caso contrário, a tarefa falhará.Nota informativaO comprimento máximo permitido para o nome do esquema é de 128 caracteres.
Mapeamento de colunas JSON
Mapear colunas JSON de origem compatíveis para colunas JSON no destino
-
Se você estiver usando o Gateway Data Movement para acessar sua fonte de dados, é necessária a versão 2024.11.70 ou posterior.
Quando essa opção for selecionada, as colunas JSON na origem serão automaticamente mapeadas para colunas JSON no destino.
O estado e a visibilidade dessa opção são determinados pelos seguintes fatores:
-
Novas tarefas: Essa opção será ativada por padrão se tanto a fonte de dados quanto o destino aceitarem o tipo de dados JSON.
-
Tarefas existentes: Esta opção estará desabilitada por padrão, mesmo que tanto a origem quanto o destino aceitem o tipo de dados JSON. Isso acontece para preservar a compatibilidade com processos posteriores, como transformações, que esperam que os dados de destino estejam no formato STRING (que é o comportamento legado). Você pode deixar a opção desabilitada ou editar os processos downstream para que sejam compatíveis com o formato JSON e então habilitar esta opção.
-
Tarefas novas e existentes: Se apenas a fonte de dados for compatível com o tipo de dados JSON, essa opção não estará visível. Se o suporte a JSON for adicionado ao destino em um estágio posterior, a opção se tornará visível, mas permanecerá desativada. Isso acontece para preservar a compatibilidade com processos posteriores, como transformações, que esperam que os dados de destino estejam no formato STRING (que é o comportamento legado).
Configurações de LOB
As configurações de LOB disponíveis diferem de acordo com o destino de replicação selecionado. Como os destinos do armazém de dados não suportam tamanhos ilimitados de colunas de LOB, esta opção não estará disponível ao replicar para um armazém de dados.
Configurações de LOB para destinos que não são armazéns de dados
- Não incluir colunas LOB: selecione esta opção se não desejar que as colunas LOB de origem sejam replicadas.
-
Limitar o tamanho da coluna LOB a (KB): este é o padrão. Selecione esta opção se precisar apenas replicar LOBs pequenos ou se a plataforma de destino não for compatível com o tamanho de LOB ilimitado. O valor máximo permitido para este campo é 102.400 KB (100 MB).
Ao replicar LOBs pequenos, esta opção é mais eficiente do que a opção Não limitar o tamanho da coluna LOB, pois os LOBs são replicados "inline" em vez de por meio de "pesquisa" da origem. Durante o processamento de alterações, pequenos LOBs geralmente são replicados por meio de "pesquisa" na origem.
O limite se aplica ao número de bytes LOB que são lidos do ponto de extremidade de origem. Para colunas BLOB, o tamanho do BLOB de destino será exatamente de acordo com o limite especificado. Para colunas CLOB e NCLOB, o tamanho do LOB de destino pode ser diferente do limite especificado se os LOBs de origem e de destino não tiverem o mesmo conjunto de caracteres. Nesse caso, a tarefa de dados executará a conversão do conjunto de caracteres, o que pode resultar em uma discrepância entre os tamanhos de LOB de origem e de destino.
Como o valor de Limitar tamanho do LOB a está em bytes, o tamanho deve ser calculado de acordo com as seguintes fórmulas:
- BLOB: o comprimento do maior LOB.
- NCLOB: o comprimento do TEXT mais longo em caracteres multiplicado por dois (já que cada caractere é tratado como um byte duplo). Se os dados incluírem caracteres de 4 bytes, multiplique-os por quatro.
- CLOB: o comprimento do TEXT mais longo em caracteres (já que cada caractere é tratado como um caractere UTF8). Se os dados incluírem caracteres de 4 bytes, multiplique-os por dois.
Nota informativa- Quaisquer LOBs maiores que o tamanho especificado serão truncados.
- Durante o Processamento de mudanças da origem Oracle, os BLOBs in-line são replicados in-line.
- As alterações nessa configuração afetarão apenas as tabelas existentes depois que elas forem recarregadas.
-
Não limitar o tamanho da coluna LOB: Quando esta opção for selecionada, as colunas LOB serão replicadas, independentemente do tamanho.
Nota informativaA replicação de colunas LOB pode afetar o desempenho. Isso é especialmente verdadeiro no caso de colunas LOB grandes que exigem que a tarefa de replicação execute uma pesquisa na tabela de origem para recuperar o valor do LOB de origem.-
Otimizar quando o tamanho do LOB for menor que: Selecione esta opção quando precisar replicar LOBs pequenos e grandes e a maioria dos LOBs for pequena.
Nota informativaEsta opção é compatível somente com as seguintes fontes e destinos:
-
Fontes: Oracle, Microsoft SQL server, MySQL, PostgreSQL e IBM DB2 para LUW
-
Alvos: Oracle, Microsoft SQL Server, MySQL, PostgreSQL.
Quando esta opção for selecionada, durante o carregamento total, os LOBs pequenos serão replicados "inline" (o que é mais eficiente) e os LOBs grandes serão replicados realizando uma pesquisa na tabela de origem. Durante o processamento de alterações, entretanto, LOBs pequenos e grandes serão replicados executando uma pesquisa na tabela de origem.
Nota informativaQuando esta opção for selecionada, a tarefa de replicação verificará todos os tamanhos de LOB para determinar quais transferir "inline". LOBs maiores que o tamanho especificado serão replicados usando o modo LOB completo.
Portanto, se você souber que a maioria dos LOBs são maiores que a configuração especificada, é preferível usar a opção Replicate colunas LOB ilimitadas em vez disso.
-
-
Tamanho do bloco (KB): opcionalmente, altere o tamanho dos blocos LOB a serem usados ao replicar os dados para o destino. O tamanho padrão do bloco deve ser suficiente na maioria dos casos, mas, se você encontrar problemas de desempenho, ajustar o tamanho poderá melhorar o desempenho.
Nota informativaCom alguns bancos de dados, a validação do tipo de dados ocorre quando os dados são inseridos ou atualizados. Nesses casos, replicação de tipos de dados estruturados (por exemplo, XML, JSON, GEOGRAPHY, etc.) poderá falhar se os dados forem maiores que o tamanho do bloco especificado.
-
Configurações de LOB para destinos de armazém de dados compatíveis
-
Incluir colunas LOB e limitar o tamanho da coluna a (KB):
Você pode optar por incluir colunas LOB na tarefa e definir o tamanho máximo do LOB. LOBs maiores que o tamanho máximo serão truncados.
Avançado
Configurações da tabela de controle
-
Esquema das tabelas de controle: Especifique o esquema de destino para as tabelas de controle se não desejar que elas sejam criadas no esquema de origem (o padrão) ou no esquema de destino.
Nota informativaO comprimento máximo permitido para o nome do esquema é de 128 caracteres. - Criar tabelas de controle de destino no tablespace: Quando o destino de replicação for o Oracle, especifique o espaço de tabela onde deseja que as tabelas de controle de destino sejam criadas. Se você não inserir informações nesse campo, as tabelas serão criadas no espaço de tabela padrão do banco de dados de destino.
- Criar índices para tabelas de controle de destino no tablespace: Quando o destino de replicação for o Oracle, especifique o espaço de tabela onde deseja que os índices da tabela de controle sejam criados. Se você não inserir informações nesse campo, os índices serão criados no mesmo espaço de tabela das tabelas de controle.
- Intervalo de tempo do histórico de replicação (minutos): a duração de cada intervalo de tempo na tabela de controle Histórico de replicação. O padrão é 5 minutos.
Seleção da tabela de controle
Selecione as tabelas de controle que você deseja criar na plataforma de destino:
| Nome lógico | Nome no alvo |
|---|---|
| Exceções de aplicação | attrep_apply_exceptions |
| Status da replicação | attrep_status |
| Tabelas suspendidas | attrep_suspended_tables |
| Histórico de replicação | attrep_history |
| Histórico DDL |
attrep_ddl_history A tabela Histórico de DDL é compatível apenas com as seguintes plataformas de destino:
|
Para obter mais informações sobre tabelas de controle, consulte Tabelas de controle.
Carregamento total
Básico
Essas configurações serão aplicadas durante a fase de preparação da tarefa de dados e sempre que uma tabela for recarregada.
Se a tabela de destino já existir: selecione uma das opções a seguir para determinar como os dados devem ser carregados nas tabelas de destino:
A opção de eliminar ou truncar as tabelas de destino será relevante somente se tais operações forem compatíveis com o endpoint de origem.
-
Eliminar e criar tabela: A tabela de destino é eliminada e uma nova tabela é criada em seu lugar.
Nota informativaAs tabelas de controle da tarefa de replicação não serão eliminadas. No entanto, quaisquer tabelas suspensas eliminadas também serão excluídas da tabela de controle attrep_suspended_tables se a tarefa associada for recarregada.
-
TRUNCATE antes de carregar: os dados são truncados sem afetar os metadados da tabela de destino. Observe que, quando esta opção é selecionada, habilitar a opção Criar chave primária ou índice exclusivo após a conclusão do carregamento total não terá efeito.
Nota informativaNão há suporte quando o Microsoft Fabric é a plataforma de destino. - Ignorar: Os dados e metadados existentes da tabela de destino não serão afetados. Novos dados serão adicionados à tabela.
Avançado
Ajuste de desempenho
Se a replicação de dados for excessivamente lenta, o ajuste dos parâmetros a seguir poderá melhorar o desempenho.
- Número máximo de tabelas: insira o número máximo de tabelas a serem carregadas no destino por vez. O valor padrão é 5.
-
Tempo limite de consistência da transação (segundos): insira o número de segundos que a tarefa de replicação deve aguardar o fechamento das transações abertas, antes de iniciar a operação de carregamento total. O valor padrão é 600 (10 minutos). A tarefa de replicação iniciará o carregamento total após o valor do tempo limite ser atingido, mesmo se houver transações abertas.
Nota informativaPara replicar transações que estavam abertas quando o carregamento total foi iniciado, mas que só foram confirmadas depois que o valor do tempo limite foi atingido, é necessário recarregar as tabelas de destino. - Taxa de confirmação durante carregamento total: o número máximo de eventos que podem ser transferidos juntos. O valor padrão é 10.000.
Após a conclusão do carregamento total
Você pode configurar a tarefa para parar automaticamente após a conclusão do carregamento total. Isso é útil se você precisar executar operações de DBA nas tabelas de destino antes da fase Aplicar alterações (ou seja. CDC) fase começa.
Durante o carregamento total, todas as operações de DML executadas nas tabelas de origem são armazenadas em cache. Quando o carregamento total for concluído, as alterações armazenadas em cache serão aplicadas automaticamente às tabelas de destino (desde que as opções Antes/Depois da aplicação das alterações armazenadas em cache descritas abaixo estejam desabilitadas).
-
Criar chave primária ou índice exclusivo: Selecione esta opção se desejar atrasar a criação da chave primária ou do índice exclusivo no destino até que o carregamento total seja concluído.
Nota informativaEssas configurações não estão disponíveis para tarefas que usam um conector de aplicativo SaaS. - Interromper a tarefa:
Nota informativa
Estas configurações não estão disponíveis ao replicar para destinos de armazém de dados
-
Antes que as alterações em cache sejam aplicadas: Selecione para interromper a tarefa após a conclusão do carregamento total.
-
Após a aplicação das alterações em cache: Selecione para interromper a tarefa assim que os dados estiverem consistentes em todas as tabelas da tarefa.
Nota informativaAo configurar a tarefa para ser interrompida após a conclusão do carregamento total, observe o seguinte:
- A tarefa não para no momento em que o carregamento total é concluído. Ela será interrompida somente após a captura do primeiro lote de alterações (pois é isso que aciona a interrupção da tarefa). Isso pode demorar um pouco, dependendo da frequência com que o banco de dados de origem é atualizado. Depois que a tarefa for interrompida, as alterações não serão aplicadas ao destino até que a tarefa seja retomada.
- Escolher Antes que as alterações em cache sejam aplicadas pode afetar o desempenho, pois as alterações em cache só serão aplicadas às tabelas (mesmo aquelas que já concluíram o carregamento total) depois que a última tabela concluir o carregamento total.
- Quando esta opção for selecionada e um DDL for executado em uma das tabelas de origem durante o processo de carregamento total (em uma tarefa Carregamento total e Aplicar alterações), a tarefa de replicação recarregará a tabela. Isso significa efetivamente que quaisquer operações DML executadas nas tabelas de origem serão replicadas para o destino antes que a tarefa seja interrompida.
-
Para carga inicial
| Usar dados em cache |
Esta opção permite usar dados em cache que foram lidos ao gerar metadados com a opção Verificação de dados completa selecionada. Isso cria menos sobrecarga em relação ao uso e cotas da API, pois os dados já são lidos da origem. Quaisquer alterações desde a verificação de dados inicial podem ser selecionadas pelo Change data capture (CDC). |
| Carregar dados da fonte |
Esta opção executa um novo carregamento da fonte de dados. Esta opção é útil se:
|
Aplicar alterações
Essas configurações só estão disponíveis quando o modo de replicação Aplicar alterações está habilitado.
Básico
Selecione o tipo de alterações DDL a serem aplicadas ao destino
As opções a seguir determinam se as operações DDL executadas na tabela de origem correspondente também serão executadas na tabela de destino.
-
Eliminar tabela: Selecione para eliminar a tabela de destino quando a tabela de origem for eliminada.
Nota informativaNão compatível quando o Kafka é a plataforma de destino. -
Truncar tabela: Selecione para truncar a tabela de destino quando a tabela de origem estiver truncada.
Nota informativaNão há suporte quando o Microsoft Fabric é a plataforma de destino. -
Alterar tabela: Selecione para alterar a tabela de destino quando a tabela de origem for alterada.
Nota informativaA renomeação de uma tabela não é compatível quando o Kafka é a plataforma de destino.
Ajuste do processamento de alterações
-
Aplicar alterações em lote a várias tabelas simultaneamente: A seleção desta opção pode melhorar o desempenho ao aplicar alterações de diversas tabelas de origem.
Nota informativaEsta opção só tem suporte quando:
- O modo Aplicar alterações estiver definido como Otimizado em lote. Para obter mais informações, consulte Configurações de replicação.
- Os destinos de replicação não são MySQL, PostgreSQL, Oracle e Google BigQuery.
-
Número máximo de tabelas: O número máximo de tabelas às quais aplicar alterações em lote simultaneamente. O padrão é cinco, o máximo é 50 e o mínimo é dois.
Quando a opção Aplicar alterações em lote a diversas tabelas simultaneamente está habilitada, as seguintes limitações se aplicam:
-
Os padrões da política de tratamento de erros de tarefa permanecerão inalterados para erros Ambientais e de Tabela, mas os padrões para erros de Dados e erros de Aplicação de conflitos serão os seguintes:
- Erros de dados:
- Erros de truncamento de dados: Gravar registro na tabela de exceções
- Outros erros de dados: Suspender tabela
- Erros de conflitos de aplicação:
- Exclusões: Ignorar registro
Inserções: ATUALIZAR o registro de destino existente
Nota informativaIsso não é relevante para um destino Snowflake (já que o Snowflake não oferece suporte a chaves primárias).- Atualizações: Ignorar registro
- Ação de escalonamento:
- A Ação de escalonamento para erros de Dados e Conflitos de aplicação não é compatível.
- Não há suporte para a tabela de controle attrep_apply_exception.
- Para erros de dados:
- A opção Gravar registro na tabela de exceções só está disponível para erros de truncamento de dados.
- Não há opção Ignorar.
- Para conflitos de aplicação:
- A opção Gravar registro na tabela de exceções não está disponível.
A opção Ignorar só está disponível para Nenhum registro encontrado para aplicação de um conflito de aplicação UPDATE.
- Erros de dados:
Consulte também: Tratamento de erros.
-
-
Limitar o número de alterações aplicadas por instrução de processamento de alterações para: Para limitar o número de alterações aplicadas em uma única instrução de processamento de alterações, marque essa caixa de seleção e, opcionalmente, altere o valor padrão. O valor padrão é 10,000.
Nota informativaEsta opção é compatível apenas com os seguintes destinos: MySQL, PostgreSQL, Oracle e Google BigQuery.
Avançado
Consulte Ajuste do processamento de alterações.
Salvar alterações
Essas configurações só estão disponíveis quando o modo de replicação Armazenar alterações está habilitado.
Básico
Opções de DDL
Selecione uma das opções a seguir para determinar como tratar operações DDL nas tabelas de origem:
- Aplicar à tabela de alterações: as operações de DDL nas tabelas de origem (como uma coluna sendo adicionada) serão aplicadas apenas às tabelas de alterações correspondentes.
- Ignorar: todas as operações de DDL para tabelas de origem serão ignoradas.
Avançado
Na atualização
Selecione Armazenar imagem anterior e posterior para armazenar os dados pré-UPDATE e os dados pós-UPDATE. Quando essa opção não estiver selecionada, apenas os dados pós-UPDATE serão armazenados.
Criação de tabela de alterações
A seção a seguir descreve as opções disponíveis ao armazenar alterações em tabelas de alterações.
- Sufixo: Especifique uma string para usar como sufixo para todas as tabelas de alterações. O valor padrão é __ct. Os nomes da tabela de alterações são o nome da tabela de destino com o sufixo anexado. Assim, por exemplo, usando o valor padrão, o nome da Tabela de Alteração será HR__ct.
- Prefixo da coluna do cabeçalho: Especifique uma sequência para usar como prefixo para todas as colunas do cabeçalho da tabela de alterações. O valor padrão é header__. Por exemplo, ao usar o valor padrão, a coluna do cabeçalho stream_position será chamada header__stream_position.
Para obter mais informações sobre tabelas de alterações, consulte Usando tabelas de alterações.
Se a tabela de alterações existir quando o carregamento total for iniciado: selecione uma das seguintes opções para determinar como carregar as tabelas de alterações quando a replicação de carregamento total for iniciada:
- Eliminar e criar tabela de alterações: a tabela é eliminada e uma nova tabela é criada em seu lugar.
-
Excluir alterações antigas e armazene novas alterações na tabela de alterações existente: os dados são truncados e adicionados sem afetar os metadados da tabela.
Nota informativaNão há suporte quando o Microsoft Fabric é a plataforma de destino. - Manter alterações antigas e armazenar novas alterações na tabela de alterações existente: os dados e metadados da tabela de alterações existente não são afetados.
Colunas de cabeçalho da tabela
As colunas do cabeçalho da tabela de alterações fornecem informações sobre as operações de processamento de alterações, como o tipo de operação (por exemplo, INSERT), o tempo de confirmação e assim por diante. Se você não precisar de todas essas informações, poderá configurar a tarefa de movendo para criar as tabelas de alterações com colunas de cabeçalho selecionadas (ou nenhuma), reduzindo assim seu espaço no banco de dados de destino.
Para obter uma descrição das colunas de cabeçalho, consulte Tabelas de alterações.
Tratamento de erros
Básico
Conflitos de aplicação
Chave duplicada ao aplicar INSERT: Selecione qual ação realizar quando houver um conflito com uma operação INSERT.
-
Ignorar: a tarefa continua e o erro é ignorado.
-
ATUALIZAR o registro de destino existente: o registro de destino com a mesma chave primária do registro de origem INSERIDO é atualizado.
- Registrar registro na tabela de exceções (padrão): a tarefa continua e o erro é gravado na tabela de exceções.
-
Suspender tabela: a tarefa continua, mas os dados da tabela com o registro de erro são movidos para um estado de erro e seus dados não são replicados.
- Parar tarefa: a tarefa é interrompida e é necessária intervenção manual.
Nenhum registro encontrado para aplicação de um UPDATE: Selecione qual ação será realizada quando houver um conflito com uma operação UPDATE.
- Ignorar: a tarefa continua e o erro é ignorado.
-
INSERIR o registro de destino ausente: o registro de destino ausente será inserido na tabela de destino. Quando o endpoint de origem for Oracle, a seleção dessa opção exigirá que o log complementar seja ativado para todas as colunas da tabela de origem.
- Registrar registro na tabela de exceções (padrão): a tarefa continua e o erro é gravado na tabela de exceções.
-
Suspender tabela: a tarefa continua, mas os dados da tabela com o registro de erro são movidos para um estado de erro e seus dados não são replicados.
- Parar tarefa: a tarefa é interrompida e é necessária intervenção manual.
Avançado
O tratamento de erros de dados tem suporte apenas no modo de replicação Aplicar alterações (não em Carregamento total).
Erros de dados
Para erros de truncamento de dados: Selecione o que você deseja que aconteça quando ocorrer um truncamento em um ou mais registros específicos. Você pode selecionar uma das seguintes situações na lista:
- Ignorar: A tarefa continua e o erro é ignorado.
- Gravar registro na tabela de exceções (padrão): A tarefa continua e o erro é gravado na tabela de exceções.
- Suspender tabela: A tarefa continua, mas os dados da tabela com o registro de erro são movidos para um estado de erro e seus dados não são replicados
- Parar tarefa: A tarefa é interrompida e é necessária intervenção manual.
Para outros erros de dados: Selecione o que você deseja que aconteça quando ocorrer um erro em um ou mais registros específicos. Você pode selecionar uma das seguintes situações na lista:
- Ignorar: A tarefa continua e o erro é ignorado.
- Gravar registro na tabela de exceções (padrão): A tarefa continua e o erro é gravado na tabela de exceções.
- Suspender tabela: A tarefa continua, mas os dados da tabela com o registro de erro são movidos para um estado de erro e seus dados não são replicados
- Parar tarefa: A tarefa é interrompida e é necessária intervenção manual.
Escalar o tratamento de erros quando outros erros de dados atingirem (por tabela): Marque esta caixa de seleção para escalar o tratamento de erros quando o número de erros de dados não truncados (por tabela) atingir o valor especificado. Os valores válidos são de 1 a 10.000.
Ação de escalonamento: Escolha o que deve acontecer quando o tratamento de erros for escalado. Observe que as ações disponíveis dependem da ação selecionada na lista suspensa Para outros erros de dados descrita acima.
-
Suspender tabela (padrão): A tarefa continua, mas os dados da tabela com o registro de erro são movidos para um estado de erro e seus dados não são movido.
Nota informativaO comportamento difere de acordo com o modo de processamento de alterações:
-
No modo Aplicação transacional, as últimas alterações não serão movido.
-
No modo de Aplicação otimizada em lote, é possível uma situação em que os dados não serão movido ou serão apenas movido parcialmente.
-
- Parar tarefa: A tarefa é interrompida e é necessária intervenção manual.
- Gravar registro na tabela de exceções: A tarefa continua e o registro é gravado na tabela de exceções.
Erros de tabela
Ao encontrar um erro de tabela: selecione uma das seguintes opções na lista suspensa:
- Suspender tabela (padrão): a tarefa continua, mas os dados da tabela com o registro de erro são movidos para um estado de erro e seus dados não são replicados
- Parar tarefa: a tarefa é interrompida e é necessária intervenção manual.
Escalar o tratamento de erros quando os erros de tabela forem atingidos (por tabela): marque esta caixa de seleção para escalar o tratamento de erros quando o número de conflitos de aplicação (por tabela) atingir o valor especificado. Os valores válidos são de 1 a 10.000.
Ação de escalonamento: a política de escalonamento para erros de tabela é definida como Parar tarefa e não pode ser alterada.
Conflitos de aplicação
Nenhum registro encontrado para aplicação de DELETE: selecione qual ação será realizada quando houver um conflito com uma operação DELETE.
- Ignorar: a tarefa continua e o erro é ignorado.
- Registrar registro na tabela de exceções: a tarefa continua, e o registro é gravado na tabela de exceções.
- Suspender tabela: a tarefa continua, mas os dados da tabela com o registro de erro são movidos para um estado de erro e seus dados não são replicados.
- Parar tarefa: a tarefa é interrompida e é necessária intervenção manual.
Escalar o tratamento de erros quando conflitos de aplicação atingirem (por tabela): marque esta caixa de seleção para escalar o tratamento de erros quando o número de conflitos de aplicação (por tabela) atingir o valor especificado. Os valores válidos são de 1 a 10.000.
Ação de escalonamento: escolha o que deve acontecer quando o tratamento de erros for escalado:
- Registrar registro na tabela de exceções (padrão): a tarefa continua e o erro é gravado na tabela de exceções.
-
Suspender tabela: a tarefa continua, mas os dados da tabela com o registro de erro são movidos para um estado de erro e seus dados não são replicados.
Nota informativaO comportamento difere de acordo com o modo de processamento de alterações:
-
No modo Aplicação transacional, as últimas alterações não serão replicadas.
-
No modo Aplicação otimizada em lote, é possível uma situação em que não haverá replicação de dados ou a replicação de dados será parcial.
-
-
Parar tarefa: a tarefa é interrompida e é necessária intervenção manual.
Erros ambientais
-
Contagem máxima de repetições: Selecione esta opção e especifique o número máximo de tentativas para repetir uma tarefa quando ocorrer um erro ambiental recuperável. Depois que a tarefa for repetida o número especificado de vezes, a tarefa será interrompida e a intervenção manual será necessária.
Para nunca repetir uma tarefa, desmarque a caixa de seleção ou especifique "0".
Para repetir uma tarefa um número infinito de vezes, especifique "-1"
-
Intervalo entre novas tentativas (segundos): Use o contador para selecionar ou digitar o número de segundos que o sistema aguarda entre as tentativas de repetir uma tarefa.
Os valores válidos são de 0 a 2.000.
-
- Aumentar o intervalo de repetição para interrupções longas: Marque esta caixa de seleção para aumentar o intervalo de novas tentativas para interrupções longas. Quando esta opção está habilitada, o intervalo entre cada nova tentativa é duplicado, até que o Intervalo máximo de repetição seja atingido (e continue tentando de acordo com o intervalo máximo especificado).
- Intervalo máximo de repetição (segundos): Use o contador para selecionar ou digitar o número de segundos de espera entre as tentativas de repetir uma tarefa quando a opção Aumentar intervalo de repetição para interrupções longas estiver ativada. Os valores válidos são de 0 a 2.000.
Ajuste do processamento de alterações
Ajuste de descarga da transação
-
Descarregar a transação em andamento para o disco se:
A tarefa de replicação geralmente mantém os dados da transação na memória até que sejam totalmente confirmados na origem e/ou destino. No entanto, as transações maiores que a memória alocada ou que não forem confirmadas dentro do limite de tempo especificado serão descarregadas no disco.
- O tamanho da memória de transação excede (MB): o tamanho máximo que todas as transações podem ocupar na memória antes de serem descarregadas no disco. O valor padrão é 1024.
- A duração da transação excede (segundos): o tempo máximo que cada transação pode permanecer na memória antes de ser descarregada no disco. A duração é calculada a partir do momento em que a tarefa de replicação começou a capturar a transação. O valor padrão é 60.
Ajuste em lote
As configurações dessa guia são determinadas pelo modo Aplicar alterações.
Configurações que só estão disponíveis quando o "Modo de aplicação" é "Otimizada em lote"
- Aplicar alterações em lote em intervalos:
-
Maior que: o tempo mínimo de espera entre cada aplicação de alterações em lote. O valor padrão é 1.
Aumentar o valor de Mais que diminui a frequência com que as alterações são aplicadas ao destino enquanto aumenta o tamanho dos lotes. Isso pode melhorar o desempenho ao aplicar alterações em bancos de dados de destino otimizados para processamento de lotes grandes.
- Menor que: o tempo máximo de espera entre cada aplicação de alterações em lote (antes de declarar um tempo limite). Em outras palavras, a latência máxima aceitável. O valor padrão é 30. Este valor determina o tempo máximo de espera antes de aplicar as alterações, após o valor de Mais que ter sido atingido.
-
Forçar a aplicação de um lote quando a memória de processamento exceder (MB): a quantidade máxima de memória a ser usada para pré-processamento no modo Aplicação otimizada em lote. O valor padrão é 500.
Para o tamanho máximo do lote, defina esse valor para a maior quantidade de memória que você puder alocar para a tarefa de replicação. Isso pode melhorar o desempenho ao aplicar alterações em bancos de dados de destino otimizados para processamento de lotes grandes.
Configurações que só estão disponíveis quando o "Modo de aplicação" é "Transacional"
As configurações a seguir são aplicáveis somente ao trabalhar no modo de aplicação "Transacional". Observe que "Transactional" é o único modo de aplicação disponível (e, portanto, não selecionável) ao replicar para o Snowflake, e o Método de carregamento é o Snowpipe Streaming.
-
Número mínimo de alterações por transação: O número mínimo de alterações a serem incluídas em cada transação. O valor padrão é 1000.
Nota informativaAs alterações serão aplicadas ao alvo quando o número de alterações for igual ou superior ao valor Número mínimo de alterações por transação OU quando o valor de Tempo máximo para transações em lote antes da aplicação (segundos) descrito abaixo for atingido - o que ocorrer primeiro. Como a frequência das alterações aplicadas ao destino é controlada por esses dois parâmetros, as alterações nos registros de origem podem não ser refletidas imediatamente nos registros de destino.
- Tempo máximo para transações em lote antes da aplicação (segundos): o tempo máximo para coletar transações em lotes antes de declarar um tempo limite. O valor padrão é 1.
Intervalo
-
Ler alterações a cada (minutos)
Defina o intervalo entre a leitura de alterações na origem, em minutos. O intervalo válido é de 1 a 1440.
Nota informativaEssa opção é apenas para tarefas que usam:
- Gateway Data Movement
- O método de atualização Aplicar alterações ou Armazenar alterações
Verificar alterações
-
De acordo com o intervalo de extração delta: Quando esta opção é selecionada, a tarefa de dados verifica se há alterações de acordo com o intervalo de extração Delta.
Nota informativaO intervalo começará após cada "rodada". Uma rodada pode ser definida como o tempo que a tarefa de dados leva para ler as alterações das tabelas de origem e enviá-las para o destino (como uma única transação). A duração de uma rodada varia de acordo com o número de tabelas e alterações. Assim, se você especificar um intervalo de 10 minutos e uma rodada levar 4 minutos, então o tempo real entre as verificações de alterações será de 14 minutos.-
Intervalo de extração de delta: A frequência com que os deltas serão extraídos do seu sistema. O padrão é a cada 60 segundos.
-
-
Conforme programado: quando esta opção é selecionada, a tarefa de dados extrairá o delta uma vez e depois parará. Em seguida, continuará sendo executado conforme programado.
Nota informativaEsta opção é relevante apenas se o intervalo entre os ciclos CDC for de 24 horas ou mais.Para obter informações sobre agendamento:
-
"Tarefas de replicação de dados" em um projeto de replicação, consulte Programando tarefas
-
Ajuste diverso
Tamanho do cache de instruções (número de instruções)
O número máximo de instruções preparadas a serem armazenadas no servidor para execução posterior (ao aplicar alterações no destino). O padrão é 50. O máximo é 200.
DELETE e INSERT ao atualizar uma coluna de chave primária
Esta opção está disponível apenas quando o Armazenar alterações modo de replicação está ativado, e requer que o log suplementar completo esteja ativado no banco de dados de origem.
Enviar marcador de exclusão em caso de DELETE.
Quando esta opção for selecionada, apenas a chave de mensagem será preenchida; a mensagem em si será nula, indicando que o item foi excluído. Isso pode ajudar os consumidores a detectar que uma operação de EXCLUSÃO foi realizada.
Armazenar dados de recuperação de tarefa no banco de dados alvo
Selecione esta opção para armazenar informações de recuperação específicas da tarefa no banco de dados de destino. Quando esta opção é selecionada, a tarefa de replicação cria uma tabela nomeada attrep_txn_state no banco de dados de destino. Essa tabela contém dados de transação que podem ser usados para recuperar uma tarefa caso os arquivos na pasta Dados do Gateway Data Movement estejam corrompidos ou se o dispositivo de armazenamento que contém a pasta Dados falhar.
Aplicar alterações usando SQL MERGE
Quando esta opção estiver não selecionada, a tarefa de replicação executará instruções INSERT, UPDATE e DELETE em massa separadas para cada um dos diferentes tipos de alteração na tabela Alterações de Rede.
Embora esse método seja altamente eficiente, habilitar a opção Aplicar alterações usando SQL MERGE é ainda mais eficiente ao trabalhar com endpoints compatíveis com essa opção.
Isso se deve aos seguintes motivos:
- Reduz o número de instruções SQL executadas por tabela de três para uma. A maioria das operações UPDATE em bancos de dados em nuvem grandes, imutáveis e baseados em arquivos (como o Google Cloud BigQuery) envolvem a reescrita dos arquivos afetados. Com tais operações, a redução de instruções SQL por tabela de três para uma é muito significativa.
- O banco de dados de destino só precisa verificar a tabela Alterações de rede uma vez, reduzindo significativamente a E/S.
Otimizar inserções
Quando Aplicar alterações usando SQL MERGE estiver selecionado junto com a opção Otimizar inserções e as alterações consistirem apenas em INSERTs, a tarefa de replicação executará INSERTs em vez de usar SQL MERGE. Observe que, embora isso geralmente melhore o desempenho e, portanto, reduza os custos, também pode resultar em registros duplicados no banco de dados de destino.
- As opções Aplicar alterações usando SQL MERGE e Otimizar inserções estão disponíveis apenas para tarefas configuradas com os seguintes endpoints de destino:
- Google Cloud BigQuery
- Databricks
- Snowflake
- As opções Aplicar alterações usando SQL MERGE e Otimizar inserções não são suportadas com os seguintes endpoints de origem:
- Salesforce
- Oracle
-
Quando a opção Aplicar alterações usando SQL MERGE está habilitada:
- Erros de dados não fatais ou erros de dados que não podem ser recuperados serão tratados como erros de tabela.
- A política de tratamento de erros Aplicar conflitos não será editável com as configurações a seguir.
- Nenhum registro encontrado para aplicação de DELETE: Ignorar registro
Duplicar chave ao aplicar INSERT: ATUALIZAR o registro de destino existente
Nota informativaSe a opção Otimizar inserções também estiver selecionada, a opção Chave duplicada ao aplicar INSERT será definida como Permitir duplicatas nos destinos.- Nenhum registro encontrado para aplicar uma ATUALIZAÇÃO: INSIRA o registro de destino ausente
- Ação de escalonamento: Gravar registro na tabela de exceções
- As seguintes opções Para outros erros de dados Política de tratamento de erros de dados não estarão disponíveis:
- Ignorar registro
- Gravar registro na tabela de exceções
- A operação SQL MERGE real só será executada nas tabelas de destino finais. As operações INSERT serão executadas nas tabelas de alterações intermediárias (quando os modos de replicação Aplicar alterações ou Armazenar alterações estiverem habilitados).
Aplicação transacional
Ao replicar para destinos de armazém de dados ou ao trabalhar sem o Gateway Data Movement, essas opções não são relevantes, pois o Modo Aplicar é sempre Otimizado em lote, com uma exceção.
A exceção é quando a replicação é feita para o Snowflake e o Método de carregamento é definido como Snowpipe Streaming.
As configurações a seguir estão disponíveis somente ao trabalhar no modo de aplicação transacional. Ao replicar para bancos de dados, o modo Aplicar pode ser definido como Otimizado em lote ou Transacional. No entanto, ao replicar para o destino do Snowflake e o Método de carregamento estiver definido como Snowpipe Streaming, o modo de aplicação será sempre transacional e, portanto, não poderá ser definido.
-
Número mínimo de alterações por transação: O número mínimo de alterações a serem incluídas em cada transação. O valor padrão é 1000.
Nota informativaA tarefa de replicação aplica as alterações ao destino quando o número de alterações é igual ou superior ao valor de Número mínimo de alterações por transação OU quando o valor de tempo limite do lote é atingido (veja abaixo) - o que ocorrer primeiro. Como a frequência das alterações aplicadas ao destino é controlada por esses dois parâmetros, as alterações nos registros de origem podem não ser refletidas imediatamente nos registros de destino. - Tempo máximo para transações em lote antes da aplicação (segundos): o tempo máximo para coletar transações em lotes antes de declarar um tempo limite. O valor padrão é 1.
Evolução automática do esquema
Selecione como lidar com os seguintes tipos de alterações de DDL no esquema. Depois de alterar as configurações de evolução do esquema, você deve preparar a tarefa novamente. A tabela abaixo descreve quais ações estão disponíveis para as alterações de DDL compatíveis.
| Alteração de DDL | Aplicar ao destino | Ignorar | Suspender tabela | Interromper tarefa |
|---|---|---|---|---|
| Adicionar coluna | Sim | Sim | Sim | Sim |
| Alterar tipo de dados da coluna | Sim | Sim | Sim | Sim |
| Renomear coluna | Sim | Não | Sim | Sim |
|
Renomear tabela Nota informativaNão compatível quando o Kafka é a plataforma de destino.
|
Não | Não | Sim | Sim |
| Excluir coluna | Sim | Sim | Sim | Sim |
|
Eliminar tabela Nota informativaNão compatível quando o Kafka é a plataforma de destino.
|
Sim | Sim | Sim | Sim |
| Criar tabela
Se você usou uma Regra de seleção para adicionar conjuntos de dados que correspondem a um padrão, novas tabelas que atendem ao padrão serão detectadas e adicionadas. |
Sim | Sim | Não | Não |
Substituição de caracteres
Você pode substituir ou excluir caracteres de origem no banco de dados de destino e/ou substituir ou excluir caracteres de origem que não são compatíveis com um conjunto de caracteres selecionado.
-
Todos os caracteres devem ser especificados como pontos de código Unicode.
- A substituição de caracteres também será realizada nas tabelas de controle.
-
Valores inválidos serão indicados por um triângulo vermelho no canto superior direito da célula da tabela. Passar o cursor do mouse sobre o triângulo mostrará a mensagem de erro.
-
Quaisquer transformações globais ou em nível de tabela definidas para a tarefa serão executadas após a conclusão da substituição de caracteres.
-
As ações de substituição definidas na tabela Substituir ou excluir caracteres de origem são executadas antes da ação de substituição definida na tabela Substituir ou excluir caracteres de origem não compatíveis com o conjunto de caracteres selecionado.
- A substituição de caracteres não aceita tipos de dados LOB.
Substituindo ou excluindo caracteres de origem
Use a tabela Substituir ou excluir caracteres de origem para definir substituições para caracteres de origem específicos. Isso pode ser útil, por exemplo, quando a representação Unicode de um caractere é diferente nas plataformas de origem e de destino. Por exemplo, no Linux, o caractere de menos no conjunto de caracteres Shift_JIS é representado como U+2212, mas no Windows é representado como U+FF0D.
| Até | Faça isto |
|---|---|
|
Defina ações de substituição. |
|
|
Editar o caractere de origem ou destino especificado |
Clique em |
|
Excluir entradas da tabela |
Clique em |
Substituindo ou excluindo caracteres de origem não compatíveis com o conjunto de caracteres selecionado
Use a tabela Caracteres de origem não compatíveis com o conjunto de caracteres para definir um único caractere de substituição para todos os caracteres não compatíveis com o conjunto de caracteres selecionado.
| Até | Faça isto |
|---|---|
|
Defina ou edite uma ação de substituição. |
|
|
Desabilite a ação de substituição. |
Selecione a entrada em branco na lista suspensa Conjunto de caracteres. |
Mais opções
Essas opções não são expostas na UI, pois são relevantes apenas para versões ou ambientes específicos. Consequentemente, não as defina, a menos que seja explicitamente instruído a fazê-lo pelo Suporte da Qlik ou na documentação do produto.
Para definir uma opção, basta copiá-la no campo Adicionar nome do recurso e clicar em Adicionar. Em seguida, defina o valor ou habilite a opção de acordo com as instruções que você recebeu.
Carregando segmentos de conjuntos de dados em paralelo
Durante o carregamento total, você pode acelerar o carregamento de grandes conjuntos de dados dividindo o conjunto de dados em segmentos, que serão carregados em paralelo. As tabelas podem ser divididas por intervalos de dados, todas as partições, todas as subpartições ou partições específicas.
Para obter mais informações, consulte Replicando segmentos de conjuntos de dados em paralelo.
Programando tarefas
Em alguns casos, você pode precisar agendar sua tarefa para propagar alterações da fonte de dados para a plataforma de destino.
Para obter mais informações, consulte Scheduling tasks.