
Ustawienia replikacji
Można skonfigurować ustawienia zadania replikacji danych.
-
Otwórz zadanie replikacji i kliknij Ustawienia na pasku narzędzi.
Otworzy się okno dialogowe Ustawienia: <Task-Name>. Dostępne ustawienia opisano poniżej.
Ogólny
Na tej karcie możesz zmienić tryb replikacji, ustawienia tymczasowe (jeśli są dostępne), tryb stosowania zmian w celu oraz ustawienia publikacji.
Tryb replikacji
Dostępne są następujące tryby replikacji:
-
Pełne ładowanie: Ładuje dane z wybranych tabel źródłowych na platformę docelową i w razie potrzeby tworzy tabele docelowe. Pełne ładowanie następuje automatycznie w momencie rozpoczęcia zadania, ale w razie potrzeby można je wykonać także ręcznie. Ręczne pełne ładowanie byłoby wymagane na przykład w przypadku konieczności replikacji aktualizacji widoków (które nie są przechwytywane podczas CDC) lub w przypadku replikacji ze źródła danych, które nie obsługuje CDC.
InformacjaPodczas korzystania z łącznika aplikacji SaaS, ta opcja będzie zawsze włączona, ponieważ wymagane jest pełne ładowanie. -
Zastosuj zmiany: Zapewnia aktualność tabel docelowych względem wszelkich zmian wprowadzonych w tabelach źródłowych.
-
Przechowuj zmiany: Przechowuje zmiany w tabelach źródłowych w tabelach zmian (po jednej na tabelę źródłową).
Więcej informacji zawiera temat Zmiany przechowywania.
Podczas pracy z Brama danych ruchu danych, z wyjątkiem korzystania ze źródeł aplikacji SaaS, zmiany są przechwytywane ze źródła w czasie niemal rzeczywistym. Podczas pracy bez Brama danych ruchu danych (na przykład w ramach subskrypcji Qlik Talend Cloud Starter lub po wybraniu ustawienia Brak) lub podczas korzystania ze źródeł aplikacji SaaS, zmiany są przechwytywane zgodnie z ustawieniami harmonogramu. Więcej informacji zawiera temat Scheduling tasks.
Jeśli wybierzesz Zapisz zmiany lub Zastosuj zmiany, a Twoje źródło danych:
-
Nie jest aplikacją SaaS
-
Zawiera zestawy danych obsługujące CDC oraz zestawy danych obsługujące tylko pełne ładowanie (takie jak widoki)
Dwa potoki danych zostaną utworzone. Jeden potok zostanie utworzony dla tabel obsługujących CDC, i drugi potok zostanie utworzony dla zestawów danych obsługujących tylko Pełne ładowanie.
Metoda ładowania
Podczas replikacji do Snowflake można wybrać jedną z następujących metod ładowania:
-
Ładowanie zbiorcze (domyślnie)
Jeśli wybierzesz opcję Ładowanie zbiorcze, będzie można dostosować parametry ładowania na karcie Przesyłanie danych.
-
Snowpipe Streaming
InformacjaFunkcja Snowpipe Streaming będzie dostępna do wyboru tylko po spełnieniu następujących warunków:
- Tryb replikacji jest ustawiony na Zapisz zmiany bez Zastosuj zmiany
- Mechanizm uwierzytelniania w łączniku Snowflake jest ustawiony na Para kluczy.
- W przypadku korzystania z Brama danych ruchu danych jest wymagana wersja 2024.11.45 lub nowsza.
Jeśli wybierzesz opcję Snowpipe Streaming, musisz znać ograniczenia i uwagi dotyczące korzystania z tej metody. Dodatkowo, jeśli wybierzesz Snowpipe Streaming, a następnie włączysz tryb replikacji Zastosuj zmiany lub wyłączysz Zachowaj zmiany, metoda ładowania zostanie automatycznie przełączona z powrotem na Ładowanie zbiorcze.
Główne powody, dla których warto wybrać Snowpipe Streaming zamiast Ładowania zbiorczego to:
-
Mniejsze koszty: ponieważ Snowpipe Streaming nie korzysta z hurtowni danych Snowflake, koszty operacyjne powinny być znacznie niższe, choć będzie to zależeć od konkretnego zastosowania.
-
Mniejsze opóźnienia: ponieważ dane są przesyłane strumieniowo bezpośrednio do tabel danych w miejscu docelowym (bez etapu przejściowego), replikacja ze źródła danych do miejsca docelowego powinna być szybsza.
Łączenie z obszarem tymczasowym
W przypadku replikacji do hurtowni danych wymienionych poniżej należy ustawić obszar tymczasowy. Dane są przetwarzane i przygotowywane w obszarze tymczasowym przed przesłaniem do hurtowni danych.
Wybierz istniejący obszar tymczasowy lub kliknij opcję Utwórz nowy, aby zdefiniować nowy obszar przejściowy, i postępuj zgodnie z instrukcjami w temacie Łączenie z pamięcią w chmurze.
Aby edytować ustawienia połączenia, kliknij Edytuj. Aby przetestować połączenie (zalecane), kliknij Testuj połączenie.
Aby uzyskać informacje o tym, które obszary tymczasowe są obsługiwane w których hurtowniach danych, zobacz kolumnę Obsługiwane jako obszar przejściowy w temacie Zastosowania platformy docelowej i obsługiwane wersje.
Tryb stosowania zmian
Zmiany są stosowane do tabel docelowych przy użyciu jednej z następujących metod:
- Optymalizacja pod kątem partii: jest to ustawienie domyślne. Po wybraniu tej opcji zmiany są stosowane partiami. Następuje działanie przed przetwarzaniem mające na celu jak najefektywniejsze pogrupowanie transakcji w partie.
- Stosowanie transakcyjne: Wybierz tę opcję, aby zastosować każdą transakcję indywidualnie, w kolejności zatwierdzania. W tym przypadku w odniesieniu do wszystkich tabel jest zapewniana pełna integralność referencyjna.
Ustawienia publikacji
-
Opublikuj w katalogu
Wybierz tę opcję, aby opublikować tę wersję danych w Katalogu jako zbiór danych. Zawartość Katalogu zostanie zaktualizowana przy następnym przygotowywaniu zadania.
Aby uzyskać więcej informacji na temat Katalogu, zobacz Rozumienie danych za pomocą narzędzi katalogu.
Ustawienia serwera proxy przy użyciu Brama danych ruchu danych
-
Podczas używania Data Movement gateway łącz się przez proxy z
Przy użyciu Brama danych ruchu danych można połączyć się z platformą docelową i platformą przejściową (obszarem) za pośrednictwem serwera proxy.
Aby uzyskać więcej informacji na temat konfigurowania Brama danych ruchu danych pod kątem użycia serwera proxy, patrz Konfigurowanie dzierżawy Qlik Cloud i serwera proxy.
-
Platforma docelowa
InformacjaDostępne przy użyciu Snowflake i Databricks. -
Platformą tymczasową
InformacjaDostępne przy użyciu Google BigQuery, Amazon Redshift, Microsoft Fabric i Databricks.
-
Przesyłania danych
Ta karta będzie wyświetlana tylko podczas replikacji do miejsca docelowego typu hurtownia danych lub Kafka. Dodatkowo, ustawienia na tej karcie będą się różnić w zależności od wybranego miejsca docelowego.
Istotne dla wszystkich celów hurtowni danych
Maksymalny rozmiar pliku
Maksymalny rozmiar, jaki może osiągnąć plik przed zamknięciem. Mniejsze pliki mogą być przesyłane szybciej (w zależności od sieci), a jeśli są używane w połączeniu z opcją wykonywania równoległego, może to poprawić wydajność. Ogólnie jednak zaśmiecanie bazy danych małymi plikami uważa się za złą praktykę.
Dotyczy tylko miejsca docelowego Snowflake
Na karcie Ogólne można wybrać, czy dane mają być ładowane do Snowflake przy użyciu Ładowania zbiorczego, czy Snowpipe Streaming. Po wybraniu opcji Snowpipe Streaming karta Przesyłanie danych nie będzie wyświetlana. Po wybraniu opcji Ładowanie zbiorcze będą dostępne następujące ustawienia:
-
Maksymalny rozmiar pliku (MB): Dotyczy początkowego pełnego ładowania i CDC. Maksymalny rozmiar, jaki może osiągnąć plik przed załadowaniem do miejsca docelowego. Jeśli wystąpią problemy z wydajnością, dostosowanie tego parametru może pomóc.
-
Liczba plików do załadowania w partii: Dotyczy tylko początkowego pełnego ładowania. Liczba plików do załadowania w pojedynczej partii. Jeśli wystąpią problemy z wydajnością, dostosowanie tego parametru może pomóc.
Opis metod ładowania Ładowanie pełne i Snowpipe Streaming można znaleźć w temacie Ogólny.
Dotyczy tylko miejsca docelowego Kafka
Właściwości wiadomości
Kompresja
Opcjonalnie wybierz jedną z dostępnych metod kompresji (Snappy lub Gzip). Wartością domyślną jest Brak.
Publikowanie wiadomości danych
Wybierz jedną z następujących opcji Publikuj dane do:
- Konkretny temat: Publikuje dane w jednym temacie. Wpisz nazwę tematu lub użyj przycisku przeglądania, aby wybrać żądany temat.
-
Oddzielny temat dla każdej tabeli: Publikuje dane w wielu tematach odpowiadających nazwom tabel źródłowych.
Nazwa docelowa topic składa się z nazwy schematu źródłowego i nazwy tabeli źródłowej, oddzielonych kropką (na przykład, dbo.Employees). Format nazwy docelowej topic jest ważny, ponieważ będziesz musiał przygotować te topic z wyprzedzeniem.
Jeśli tematy nie istnieją, skonfiguruj brokerów za pomocą auto.create.topics.enable=true, aby umożliwić zadaniu danych tworzenie tematów podczas działania. W przeciwnym razie zadanie zakończy się niepowodzeniem.
Aby uzyskać informacje na temat zastępowania tego ustawienia na poziomie zestawu danych, zobacz Zastępowanie ustawień zadania dla poszczególnych zestawów danych podczas publikowania w usłudze Kafka
Klucz wiadomości
Spośród dostępnych opcji wybierz jedną.
-
Kolumny klucza podstawowego: Dla każdej wiadomości klucz wiadomości będzie zawierał wartość kolumny klucza podstawowego.
Gdy Według klucza wiadomości jest wybrana jako Strategia partycjonowania, wiadomości składające się z tej samej wartości klucza podstawowego zostaną zapisane do tej samej partycji.
-
Nazwa schematu i tabeli: Dla każdej wiadomości klucz wiadomości będzie zawierał kombinację schematu i nazwy tabeli (na przykład, dbo+Employees).
Gdy Według klucza wiadomości jest wybrana jako Strategia partycjonowania, wiadomości składające się z tego samego schematu i nazwy tabeli zostaną zapisane do tej samej partycji.
- Brak: Tworzy wiadomości bez klucza wiadomości.
Aby uzyskać informacje na temat zastępowania tego ustawienia na poziomie zestawu danych, zobacz Zastępowanie ustawień zadania dla poszczególnych zestawów danych podczas publikowania w usłudze Kafka
Strategia partycjonowania
Wybierz Losowo lub Według klucza wiadomości. Jeśli wybierzesz Losowo, każda wiadomość zostanie zapisana do losowo wybranej partycji. Jeśli wybierzesz Według klucza wiadomości, wiadomości zostaną zapisane do partycji na podstawie wybranego Klucza wiadomości (opisanego powyżej).
Publikowanie wiadomości metadanych
Strategia nazw tematów
Pierwsza strategia (Schemat i nazwa tabeli) jest zastrzeżoną Qlik strategią, podczas gdy pozostałe trzy to standardowe strategie nazewnictwa tematów Confluent.
Wybierz jedną z dostępnych strategii nazewnictwa tematów.
- Schemat i nazwa tabeli (domyślne)
- Nazwa tematu
- Nazwa rekordu
- Nazwa tematu i rekordu
Więcej informacji na temat strategii nazw tematów Confluent można znaleźć w Strategia nazewnictwa tematów
Tryb zgodności tematu
Wybierz jeden z następujących trybów zgodności z listy rozwijanej Tryb zgodności tematu:
-
Użyj domyślnych ustawień rejestru schematów: Pobiera poziom zgodności z konfiguracji serwera rejestru schematów.
-
Wsteczna - Tylko najnowszy schemat: Nowe schematy mogą odczytywać odpowiednie dane oraz dane wyprodukowane tylko przez najnowszy zarejestrowany schemat.
-
Przechodniość wsteczna – Wszystkie poprzednie schematy: Nowe schematy mogą odczytywać dane wyprodukowane przez wszystkie wcześniej zarejestrowane schematy.
-
Do przodu - Tylko najnowszy schemat: Najnowszy zarejestrowany schemat może odczytywać dane wyprodukowane przez nowy schemat.
-
Przejściowa do przodu - Wszystkie poprzednie schematy: Wszystkie wcześniej zarejestrowane schematy mogą odczytywać dane wyprodukowane przez nowy schemat.
-
Pełny - Tylko najnowszy schemat: Nowy schemat jest wstecznie i w przód zgodny z najnowszym zarejestrowanym schematem.
-
Pełna przechodniość - Wszystkie poprzednie schematy: Nowy schemat jest wstecznie i przyszłościowo kompatybilny ze wszystkimi wcześniej zarejestrowanymi schematami.
-
BRAK
- W zależności od wybranej strategii nazewnictwa tematów, niektóre tryby zgodności mogą być niedostępne.
-
Podczas publikowania wiadomości w rejestrze schematów, domyślny tryb zgodności tematów dla wszystkich nowo utworzonych tematów tabel kontrolnych będzie ustawiony na Brak, niezależnie od wybranego trybu zgodności tematów.
Jeśli chcesz, aby wybrany tryb zgodności tematów miał zastosowanie również do tabel kontrolnych, ustaw wewnętrzny parametr setNonCompatibilityForControlTables w docelowym łączniku Kafka na false.
Użyj serwera proxy, aby połączyć się z rejestrem schematów Confluent
Ta opcja jest obsługiwana tylko podczas publikowania w Confluent Schema Registry.
Włącz, jeśli Twoja Brama danych ruchu danych jest skonfigurowana do używania serwera proxy.
Atrybuty wiadomości
Możesz określić niestandardowe atrybuty wiadomości, które zastąpią domyślne atrybuty wiadomości. Jest to przydatne, jeśli aplikacja konsumenta musi przetworzyć wiadomość w określonym formacie.
Niestandardowe atrybuty wiadomości można zdefiniować zarówno na poziomie zadania, jak i tabeli. Gdy atrybuty są zdefiniowane zarówno na poziomie zadania i tabeli, atrybuty wiadomości zdefiniowane dla tabeli będą miały pierwszeństwo przed tymi zdefiniowanymi dla zadania.
Aby uzyskać informacje na temat nadpisywania atrybutów wiadomości na poziomie zestawu danych, zobacz Zastępowanie ustawień zadania dla poszczególnych zestawów danych podczas publikowania w usłudze Kafka
Hierarchiczne wiadomości strukturalne nie są obsługiwane.
Ogólne zasady i wytyczne dotyczące użytkowania
Podczas definiowania niestandardowej wiadomości należy wziąć pod uwagę zasady i wytyczne dotyczące użytkowania wymienione poniżej.
Nazwy sekcji
Obowiązują następujące zasady nazewnictwa:
- Nazwy sekcji muszą zaczynać się od znaków a-z, A-Z lub _ (podkreślenie), a następnie mogą być obserwowane przez dowolne z następujących znaków: a-z, A-Z, 0-9, _
- Z wyjątkiem nazwy rekordu i sekcji nazwy klucza (które nie kończą się ukośnikiem), usunięcie ukośnika z nazw sekcji spłaszczy hierarchię powiązanej sekcji (zobacz Ukośniki poniżej).
- Wszystkie nazwy sekcji z wyjątkiem nazwy rekordu i nazwy klucza mogą zostać usunięte (zobacz Usunięcie poniżej)
-
Nazwy sekcji Nazwa danych i Dołącz rekord Przed-danymi nie mogą być usunięte jednocześnie
-
Nazwy sekcji Nazwa danych i Dołącz rekord Przed danymi nie mogą być takie same
Niektóre nazwy sekcji w interfejsie użytkownika kończą się ukośnikiem (np. beforeData/beforeData/). Celem ukośnika jest utrzymanie hierarchii różnych sekcji w wiadomości. Jeśli ukośnik zostanie usunięty, nastąpi co następuje:
- Hierarchiczna struktura tej sekcji zostanie spłaszczona, co spowoduje usunięcie nazwy sekcji z wiadomości
- Nazwa sekcji zostanie dodana jako prefiks do rzeczywistych metadanych, bezpośrednio lub za pomocą znaku separatora (np. podkreślenia), który został dodany do nazwy
Przykład wiadomości danych, gdy headers/ jest określony ze ukośnikiem:
"message":{
"data":{
"COL1": "159",
"COL2": "159"
},
"beforeData": null,
"headers": {
"operation": "INSERT",
"changeSequence": "2018100811484900000000233",
Przykład wiadomości danych, gdy headers_ jest określony z podkreśleniem zamiast ukośnika:
"message":{
"data":{
"COL1": "159",
"COL2": "159"
},
"beforeData": null,
"headers_operation": "INSERT",
"headers_changeSequence": "2018100811484900000000233",
Usunięcie nazwy sekcji z wiadomości spłaszczy hierarchiczną strukturę tej sekcji. Spowoduje to, że wszystkie dane tej sekcji pojawią się bezpośrednio pod zawartością poprzedniej sekcji.
Przykład wiadomości danych z nazwą headers sekcji:
"message":{
"data":{
"COL1": "159",
"COL2": "159"
},
"headers": {
"operation": "INSERT",
"changeSequence": "2018100811484900000000233",
Przykład wiadomości danych bez nazwy headers sekcji:
"message":{
"data":{
"COL1": "159",
"COL2": "159"
},
"beforeData": null,
"operation": "INSERT",
"changeSequence": "2018100811484900000000233",
Zmienne
Możesz dodawać zmienne do nazw, klikając przycisk ![]() na końcu wiersza. Dostępne są następujące zmienne:
na końcu wiersza. Dostępne są następujące zmienne:
- SERVER_NAME - Nazwa hosta serwera Brama danych ruchu danych
- TARGET_TABLE_NAME - Nazwa tabeli
- TARGET_TABLE_OWNER - Właściciel tabeli
- TASK_NAME - Nazwa zadania danych
Zmienna TARGET_TABLE_OWNER nie jest dostępna dla opcji Nazwa rekordu i Nazwa klucza (opisanych w poniższej tabeli).
Definiowanie niestandardowych atrybutów wiadomości
Aby zdefiniować niestandardowy format wiadomości, włącz opcję Użyj ustawień niestandardowych i skonfiguruj opcje zgodnie z opisem w poniższej tabeli.
Aby przywrócić domyślne atrybuty wiadomości, wyłącz opcję Użyj ustawień niestandardowych.
| Opcja | Opis |
|---|---|
|
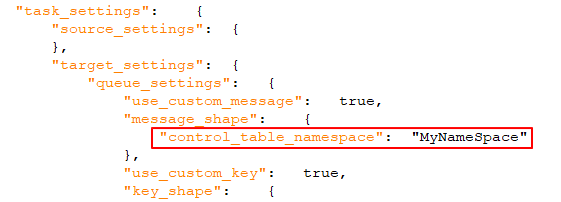
Po włączeniu (domyślnie) do wiadomości zostanie dołączony unikalny identyfikator. Powinien to być ciąg znaków, rozdzielony kropkami. Zwróć uwagę, że przestrzeń nazw będzie zawarta zarówno w wiadomości, jak i w kluczu wiadomości. Przykład: mycompany.queue.msg Domyślna nazwa: com.attunity.queue.msg.{{NAZWA_ZADANIA}}.{{TARGET_TABLE_OWNER}}.{{TARGET_TABLE_NAME}} Nazwa domyślna dla tabel kontrolnych: com.attunity.queue.msg.{{TARGET_TABLE_NAME}} Informacja
Domyślna przestrzeń nazw tabeli sterującej nie może być zmieniona za pośrednictwem interfejsu użytkownika. Można jednak zmienić domyślną przestrzeń nazw tabeli sterującej w następujący sposób:
|
|
|
Nazwa rekordu |
Nazwa rekordu (wiadomości). Nazwa domyślna: Rekord danych |
|
Nazwa danych |
Wszystkie kolumny danych zawarte w rekordzie. Nazwa domyślna: dane/ |
|
Uwzględnij nagłówki |
Po włączeniu (domyślnie) kolumny nagłówka zostaną uwzględnione w wiadomości. Kolumny nagłówka dostarczają dodatkowych informacji o operacjach źródłowych. Więcej informacji można znaleźć w Dołącz następujące nagłówki poniżej. |
|
Dołącz przestrzeń nazw nagłówków |
Po włączeniu (domyślnie) unikatowy identyfikator dla sekcji kolumn nagłówka zostanie uwzględniony w wiadomości. Powinien to być ciąg znaków, rozdzielony kropkami. Przykład: nagłówki.kolejka.wiadomość Nazwa domyślna: com.attunity.queue.msg |
|
Nazwa nagłówka |
Nazwa sekcji zawierającej Qlik nagłówki kolumn. Nazwa domyślna: nagłówki/ |
|
Opis dostępnych kolumn nagłówkowych znajduje się w Wiadomościach danych w Pomocy Qlik. Domyślnie: Wszystkie kolumny są domyślnie uwzględnione, z wyjątkiem kolumny Zewnętrzny identyfikator schematu. |
|
|
Dołącz element przed danymi rekordu |
Po włączeniu (domyślnie), zarówno dane sprzed, jak i po aktualizacji zostaną uwzględnione w komunikatach UPDATE. Aby uwzględnić w komunikatach tylko dane po aktualizacji, wyłącz tę opcję. Nazwa domyślna: beforeData/ |
|
Nazwa klucza |
Nazwa sekcji zawierającej klucz wiadomości. Nazwa domyślna: keyRecord Ta opcja ma zastosowanie tylko wtedy, gdy:
|
Ustawienia dodatkowe
-
Maksymalny rozmiar wiadomości
W polu Maksymalny rozmiar wiadomości określ maksymalny rozmiar wiadomości, które broker(y) są skonfigurowane do odbierania (message.max.bytes). Zadanie danych nie będzie wysyłać wiadomości większych niż maksymalny rozmiar.
Metadane
Podstawowa
-
Schemat tabeli docelowej
Schemat w miejscu docelowym, do którego zostaną zreplikowane tabele źródłowe, jeśli nie chcesz używać schematu tabeli źródłowej (lub jeśli w źródłowej bazie danych nie ma schematu).
InformacjaPodczas replikacji do miejsca docelowego Oracle domyślnym schematem tabeli docelowej jest „system”. Pamiętaj też, że jeśli pozostawisz to pole puste (w takim przypadku zostanie użyty schemat źródłowy), schemat źródłowy musi już istnieć w miejscu docelowym. W przeciwnym razie zadanie zakończy się niepowodzeniem.InformacjaMaksymalna dozwolona długość nazwy schematu wynosi 128 znaków.
Mapowanie kolumn JSON
Mapowanie zgodnych źródłowych kolumn JSON na kolumny JSON w miejscu docelowym
-
Jeżeli w celu uzyskiwania dostępu do źródła danych używasz Brama danych ruchu danych, jest wymagana wersja 2024.11.70 lub późniejsza.
Po wybraniu tej opcji kolumny JSON w źródle zostaną automatycznie zamapowane na kolumny JSON w miejscu docelowym.
Stan i widoczność tej opcji są określone przez następujące czynniki:
-
Nowe zadania: Ta opcja zostanie domyślnie włączona, jeśli zarówno źródło, jak i cel obsługują typ danych JSON.
-
Istniejące zadania: Ta opcja będzie domyślnie wyłączona, nawet jeśli zarówno źródło, jak i cel obsługują typ danych JSON. Ma to na celu zachowanie kompatybilności wstecznej z późniejszymi procesami – takimi jak transformacje – które oczekują, że dane docelowe będą w formacie STRING (co jest dotychczasowym zachowaniem). Możesz pozostawić tę opcję wyłączoną lub edytować procesy podrzędne, aby były zgodne z formatem JSON, a następnie włączyć tę opcję.
-
Nowe i istniejące zadania: Jeśli tylko źródło obsługuje typ danych JSON, ta opcja nie będzie widoczna. Jeśli obsługa JSON zostanie dodana do elementu docelowego na późniejszym etapie, opcja stanie się widoczna, ale pozostanie wyłączona. Ma to na celu zachowanie kompatybilności wstecznej z późniejszymi procesami – takimi jak transformacje – które oczekują, że dane docelowe będą w formacie STRING (co jest dotychczasowym zachowaniem).
Ustawienia obiektu LOB
Dostępne ustawienia obiektu LOB różnią się w zależności od wybranego celu replikacji. Ponieważ cele hurtowni danych nie obsługują nieograniczonej wielkości kolumn LOB, ta opcja nie będzie dostępna podczas replikacji do hurtowni danych.
Ustawienia obiektów LOB dla miejsc docelowych, które nie są hurtowniami danych
- Nie uwzględniaj kolumn LOB: Wybierz tę opcję, jeśli nie chcesz, aby źródłowe kolumny LOB były replikowane.
-
Ogranicz rozmiar kolumny LOB do (KB): jest to ustawienie domyślne. Wybierz tę opcję, jeśli potrzebujesz replikować tylko małe obiekty LOB lub platforma docelowa nie obsługuje nieograniczonego rozmiaru obiektów LOB. Maksymalna dozwolona wartość dla tego pola to 102400 KB (100 MB).
Podczas replikacji małych obiektów LOB ta opcja jest bardziej wydajna niż opcja Nie ograniczaj rozmiaru kolumny LOB, ponieważ replikowane obiekty LOB są wstawione, a nie wyszukiwane ze źródła. Podczas przetwarzania zmian małe obiekty LOB są zwykle replikowane poprzez wyszukiwanie ze źródła.
Limit ma zastosowanie do liczby bajtów LOB odczytywanych z punktu końcowego źródła. W przypadku kolumn BLOB docelowy rozmiar obiektu BLOB będzie dokładnie zgodny z określonym limitem. W przypadku kolumn CLOB i NCLOB docelowy rozmiar obiektu LOB może różnić się od określonego limitu, jeśli źródłowy i docelowy LOB nie mają tego samego zestawu znaków. W takim przypadku zadanie danych wykona konwersję zestawu znaków, co może spowodować rozbieżność między źródłowym i docelowym rozmiarem LOB.
Ponieważ wartość Ogranicz rozmiar obiektu LOB do jest wyrażona w bajtach, rozmiar należy obliczyć według poniższych wzorów:
- BLOB: długość największego obiektu LOB.
- NCLOB: Długość najdłuższego TEKSTU w znakach pomnożona przez dwa (ponieważ każdy znak jest traktowany jako znak dwubajtowy). Jeśli dane zawierają znaki 4-bajtowe, pomnóż je przez cztery.
- CLOB: Długość najdłuższego TEKSTU w znakach (ponieważ każdy znak jest traktowany jako znak UTF-8). Jeśli dane zawierają znaki 4-bajtowe, pomnóż je przez dwa.
Informacja- Wszelkie obiekty LOB większe niż określony rozmiar zostaną obcięte.
- Podczas przetwarzania zmian ze źródła Oracle wstawione obiekty BLOB są replikowane bezpośrednio.
- Zmiany tego ustawienia będą miały wpływ tylko na istniejące tabele po ich przeładowaniu.
-
Nie ograniczaj rozmiaru kolumny LOB: Po wybraniu tej opcji kolumny LOB zostaną zreplikowane niezależnie od rozmiaru.
InformacjaReplikowanie kolumn LOB może wpływać na wydajność. Dotyczy to szczególnie dużych kolumn LOB, które wymagają przeprowadzenia przez zadanie replikacji wyszukiwania w tabeli źródłowej w celu pobrania źródłowej wartości LOB.-
Optymalizuj, gdy rozmiar obiektu LOB jest mniejszy niż: Wybierz tę opcję, jeśli chcesz replikować zarówno małe, jak i duże obiekty LOB, a większość obiektów LOB jest mała.
InformacjaTa opcja jest obsługiwana tylko w przypadku następujących źródeł i miejsc docelowych:
-
Źródła: Oracle, serwer Microsoft SQL, MySQL, PostgreSQL i IBM DB2 for LUW
-
Cele: Oracle, Microsoft SQL Server, MySQL, PostgreSQL.
Po wybraniu tej opcji podczas pełnego ładowania małe obiekty LOB będą replikowane jako wstawione (co jest wydajniejsze), a duże obiekty LOB będą replikowane poprzez wyszukiwanie w tabeli źródłowej. Podczas przetwarzania zmian zarówno małe, jak i duże obiekty LOB zostaną jednak zreplikowane przez wyszukiwanie w tabeli źródłowej.
InformacjaGdy ta opcja jest zaznaczona, zadanie replikacji sprawdzi wszystkie rozmiary obiektów LOB, aby określić, które z nich mają zostać przesłane jako wstawione. Obiekty LOB większe niż określony rozmiar zostaną zreplikowane w trybie pełnego LOB.
Dlatego jeśli wiesz, że większość obiektów LOB jest większa niż określone ustawienie, lepiej użyć zamiast tego opcji Replicate nieograniczone kolumny LOB.
-
-
Wielkość fragmentu (KB): opcjonalnie zmień rozmiar fragmentów LOB, które mają być używane podczas replikowania danych do miejsca docelowego. W większości przypadków powinien wystarczyć domyślny rozmiar fragmentu, ale jeśli napotkasz problemy z wydajnością, dostosowanie rozmiaru może poprawić wydajność.
InformacjaW przypadku niektórych baz danych sprawdzanie typu danych odbywa się podczas wstawiania lub aktualizacji danych. W takich przypadkach replikacja strukturalnych typów danych (np. XML, JSON, GEOGRAPHY, itp.) może się nie powieść, jeśli dane będą większe niż określony rozmiar fragmentu.
-
Ustawienia obiektów LOB dla obsługiwanych miejsc docelowych typu hurtownia danych
-
Uwzględnij kolumny LOB i ogranicz rozmiar kolumn do (KB):
Możesz zdecydować o uwzględnieniu kolumn LOB w zadaniu i określić maksymalny rozmiar LOB. Obiekty LOB, które mają rozmiar większy od maksymalnego, zostaną przycięte.
Zaawansowane
Ustawienia tabel kontrolnych
-
Schemat tabel kontrolnych: Określ schemat docelowy dla tabel kontrolnych, jeśli nie chcesz, aby były one tworzone w schemacie źródłowym (domyślnie) lub w schemacie docelowym.
InformacjaMaksymalna dozwolona długość nazwy schematu wynosi 128 znaków. - Utwórz docelowe tabele kontrolne w przestrzeni tabel: Jeśli miejsce docelowe replikacji to Oracle, określ obszar tabel, w którym mają zostać utworzone docelowe tabele kontrolne. Jeśli w tym polu nie wprowadzisz żadnych informacji, tabele zostaną utworzone w domyślnym obszarze tabel w docelowej bazie danych.
- Utwórz indeksy dla docelowych tabel kontrolnych w przestrzeni tabel: Jeśli miejsce docelowe replikacji to Oracle, określ obszar tabel, w którym mają zostać utworzone indeksy tabel kontrolnych. Jeśli w tym polu nie wprowadzisz żadnych informacji, indeksy zostaną utworzone w tym samym obszarze tabel co tabele kontrolne.
- Szczelina czasowa w replikacji (minuty): Długość każdego przedziału czasowego w tabeli kontrolnej Historia replikacji. Wartością domyślną jest 5 minut.
Wybór tabel kontrolnych
Wybierz tabele kontrolne, które chcesz utworzyć na platformie docelowej:
| Nazwa logiczna | Nazwa w celu |
|---|---|
| Zastosuj wyjątki | attrep_apply_exceptions |
| Status replikacji | attrep_status |
| Zawieś tabele | attrep_suspended_tables |
| Historia replikacji | attrep_history |
| Historia DDL |
attrep_ddl_history Tabela Historla DDL jest obsługiwana tylko w przypadku następujących platform docelowych:
|
Więcej informacji na temat tabel kontrolnych zawiera temat Tabele kontrolne.
Pełne ładowanie
Podstawowa
Te ustawienia zostaną zastosowane na etapie przygotowania zadania danych oraz za każdym razem, gdy tabela zostanie ponownie załadowana.
Jeśli tabela docelowa już istnieje: wybierz jedną z następujących opcji, aby określić sposób ładowania danych do tabel docelowych:
Opcja usunięcia lub obcięcia tabel docelowych ma zastosowanie tylko wtedy, gdy takie operacje są obsługiwane przez źródłowy punkt końcowy.
-
Usuń i utwórz tabelę: Tabela docelowa zostanie usunięta, a na jej miejscu zostanie utworzona nowa tabela.
InformacjaTabele kontrolne zadania replikacji nie zostaną usunięte. Wszystkie zawieszone tabele, które zostaną usunięte, zostaną jednak również usunięte z tabeli kontrolnej attrep_suspended_tables, jeśli powiązane zadanie zostanie przeładowane.
-
OBETNIJ przed załadowaniem: dane są obcinane bez wpływu na metadane tabeli docelowej. Należy pamiętać, że po wybraniu tej opcji włączenie opcji Utwórz klucz główny lub unikalny indeks po zakończeniu pełnego ładowania nie będzie miało żadnego efektu.
InformacjaFunkcja nie jest obsługiwana, kiedy platformą docelową jest Microsoft Fabric. - Ignoruj: Nie będzie to miało wpływu na istniejące dane i metadane tabeli docelowej. Nowe dane zostaną dodane do tabeli.
Zaawansowane
Strojenie wydajności
Jeśli replikacja danych jest zbyt powolna, dostosowanie poniższych parametrów może poprawić wydajność.
- Maksymalna liczba tabel: wprowadź maksymalną liczbę tabel, które można załadować jednocześnie do miejsca docelowego. Wartością domyślną jest 5.
-
Limit czasu spójności transakcji (sekundy): wprowadź liczbę sekund oczekiwania przez zadanie replikacji na zamknięcie otwartych transakcji przed rozpoczęciem operacji Pełne ładowanie. Wartością domyślną jest 600 (10 minut). Zadanie replikacji rozpocznie pełne ładowanie po osiągnięciu limitu czasu, nawet jeśli będą istnieć otwarte transakcje.
InformacjaAby zreplikować transakcje, które były otwarte w momencie rozpoczęcia pełnego ładowania, ale zostały zatwierdzone dopiero po osiągnięciu limitu czasu, należy przeładować tabele docelowe. - Współczynnik zatwierdzania podczas pełnego ładowania: Maksymalna liczba zdarzeń, które można przenieść razem. Wartością domyślną jest 10000.
Po zakończeniu pełnego ładowania
Możesz ustawić automatyczne zatrzymanie zadania po zakończeniu pełnego ładowania. Przydaje się to, gdy trzeba wykonać operacje DBA na tabelach docelowych przed rozpoczęciem fazy stosowania zmian (tj. CDC) rozpoczyna się faza.
Podczas pełnego ładowania wszystkie operacje DML wykonywane na tabelach źródłowych są buforowane. Po zakończeniu pełnego ładowania buforowane zmiany są automatycznie stosowane do tabel docelowych (o ile opisane poniżej opcje Przed/Po zastosowaniu zbuforowanych zmian są wyłączone).
-
Utwórz klucz główny lub unikatowy indeks: Wybierz tę opcję, jeśli chcesz opóźnić utworzenie klucza głównego lub unikatowego indeksu w miejscu docelowym do czasu zakończenia pełnego ładowania.
InformacjaTe ustawienia nie są dostępne dla zadań używających łącznika aplikacji SaaS. - Zatrzymaj zadanie:
Informacja
Te ustawienia nie są dostępne podczas replikacji do hurtowni danych
-
Zanim zastosowane zostaną zmiany z pamięci podręcznej: Wybierz, aby zatrzymać zadanie po zakończeniu pełnego ładowania.
-
Po zastosowaniu zmian z pamięci podręcznej: Wybierz, aby zatrzymać zadanie, gdy tylko dane będą spójne we wszystkich tabelach zadania.
InformacjaKonfigurując zatrzymanie zadania po zakończeniu pełnego ładowania, należy pamiętać, że:
- Zadanie nie zatrzymuje się w momencie zakończenia pełnego ładowania. Zostanie zatrzymane dopiero po przechwyceniu pierwszej partii zmian (ponieważ to właśnie powoduje zatrzymanie zadania). Może to chwilę potrwać, w zależności od częstotliwości aktualizacji źródłowej bazy danych. Po zatrzymaniu zadania zmiany nie zostaną zastosowane do celu, dopóki zadanie nie zostanie wznowione.
- Wybranie opcji Przed zastosowaniem zbuforowanych zmian może mieć wpływ na wydajność, ponieważ zbuforowane zmiany zostaną zastosowane do tabel (nawet tych, które zakończyły już pełne ładowanie) dopiero po zakończeniu pełnego ładowania ostatniej tabeli.
- Po wybraniu tej opcji i wykonaniu operacji DDL na jednej z tabel źródłowych podczas procesu pełnego ładowania (w zadaniu Pełne ładowanie i Zastosuj zmiany) zadanie replikacji spowoduje przeładowanie tabeli. Oznacza to w praktyce, że wszelkie operacje DML wykonane na tabelach źródłowych zostaną zreplikowane do obiektu docelowego przed zatrzymaniem zadania.
-
Do początkowego ładowania
| Użyj danych z pamięci podręcznej |
Ta opcja umożliwia korzystanie z buforowanych danych, które zostały odczytane podczas generowania metadanych z wybraną opcją Pełne skanowanie danych. Powoduje to mniejsze obciążenie związane z wykorzystaniem interfejsu API i limitami, ponieważ dane są już odczytywane ze źródła. Wszelkie zmiany od początkowego skanowania danych mogą zostać uwzględnione przez przechwytywanie zmian danych (CDC). |
| Załaduj dane ze źródła |
Ta opcja wykonuje nowe ładowanie ze źródła danych. Ta opcja jest przydatna, jeśli:
|
Zastosuj zmiany
Te ustawienia są dostępne tylko wtedy, gdy włączony jest tryb replikacji Zastosuj zmiany.
Podstawowa
Wybierz rodzaj zmian DDL do zastosowania do celu
Poniższe opcje określają, czy operacje DDL wykonane na odpowiedniej tabeli źródłowej zostaną również wykonane na tabeli docelowej.
-
Usuń tabelę: Wybierz tę opcję, aby usunąć tabelę docelową, gdy zostanie usunięta tabela źródłowa.
InformacjaFunkcja nie jest obsługiwana, kiedy platformą docelową jest Kafka. -
Obetnij tabelę: Wybierz tę opcję, aby obciąć tabelę docelową, gdy zostanie obcięta tabela źródłowa.
InformacjaFunkcja nie jest obsługiwana, kiedy platformą docelową jest Microsoft Fabric. -
Zmień tabelę: Wybierz, aby zmienić tabelę docelową, gdy zostanie zmieniona tabela źródłowa.
InformacjaZmiana nazwy tabeli nie jest obsługiwana, kiedy platformą docelową jest Kafka.
Dostrajanie przetwarzania zmian
-
Stosuj zmiany w partiach jednocześnie do wielu tabel: Wybranie tej opcji może poprawić wydajność podczas stosowania zmian z wielu tabel źródłowych.
InformacjaTa opcja jest obsługiwana tylko wtedy, gdy:
- Tryb stosowania zmian jest ustawiony na Optymalizacja pod kątem partii. Więcej informacji zawiera temat Ustawienia replikacji.
- Miejscami docelowymi replikacji nie są MySQL, PostgreSQL, Oracle ani Google BigQuery.
-
Maksymalna liczba tabel: Maksymalna liczba tabel, w których można jednocześnie zastosować zmiany zbiorcze. Wartość domyślna to 5, maksymalna to 50, a minimalna to 2.
Gdy włączona jest opcja Stosuj zmiany w partiach jednocześnie do wielu tabel, obowiązują następujące ograniczenia:
-
Domyślne zasady obsługi błędów zadań pozostaną niezmienione w przypadku błędów Środowiskowych i błędów Tabel, ale wartości domyślne dla błędów Danych i błędów Konfliktów stosowania będą następujące:
- Błędy danych:
- Błędy obcięcia danych: Zarejestruj rekord w tabeli wyjątków
- Inne błędy danych: Zawieszenie tabeli
- Błędy konfliktów stosowania:
- Usuwa: Ignoruj rekord
Wstawienia: AKTUALIZUJ istniejący rekord docelowy
InformacjaNie dotyczy to miejsca docelowego Snowflake (ponieważ Snowflake nie obsługuje kluczy głównych).- Aktualizacje: Ignoruj rekord
- Działanie eskalacji:
- Działanie eskalacji zarówno w przypadku błędów Danych, jak i błędów Konfliktów stosowania nie jest obsługiwane.
- Tabela kontrolna attrep_apply_exception nie jest obsługiwana.
- W przypadku błędów danych:
- Opcja Zarejestruj rekord w tabeli wyjątków jest dostępna tylko w przypadku błędów obcięcia danych.
- Nie ma opcji Ignoruj.
- W przypadku konfliktów stosowania:
- Opcja Zarejestruj rekord w tabeli wyjątków nie jest dostępna.
Opcja Ignoruj jest dostępna tylko dla konfliktu stosowania Nie znaleziono rekordu do zastosowania AKTUALIZACJI.
- Błędy danych:
Zobacz również: Obsługa błędów.
-
-
Ogranicz liczbę zmian stosowanych na instrukcję przetwarzania zmian do: Aby ograniczyć liczbę zmian stosowanych w pojedynczej instrukcji przetwarzania zmian, zaznacz to pole wyboru, a następnie opcjonalnie zmień wartość domyślną. Wartością domyślną jest 10,000.
InformacjaTa opcja jest obsługiwana tylko z następującymi miejscami docelowymi: MySQL, PostgreSQL, Oracle i Google BigQuery.
Zaawansowane
Zobacz Dostrajanie przetwarzania zmian.
Zmiany przechowywania
Te ustawienia są dostępne tylko wtedy, gdy włączony jest tryb replikacji Zapisz zmiany.
Podstawowa
Opcje DDL
Wybierz jedną z następujących opcji, aby określić sposób obsługi operacji DDL na tabelach źródłowych:
- Zastosuj do tabeli zmian: Operacje DDL na tabelach źródłowych (takie jak dodawanie kolumny) zostaną zastosowane tylko do odpowiednich tabel zmian.
- Ignoruj: wszystkie operacje DDL wykonywane na tabelach źródłowych będą ignorowane.
Zaawansowane
Po aktualizacji
Wybierz opcję Zapisz obraz przed i obraz po, aby przechowywać zarówno dane sprzed operacji UPDATE, jak i dane po operacji UPDATE. Jeśli ta opcja nie zostanie wybrana, będą przechowywane tylko dane po operacji UPDATE.
Zmień tworzenie tabeli
W poniższej sekcji opisano opcje dostępne podczas zapisywania zmian w tabelach zmian.
- Sufiks: Określ ciąg, który będzie używany jako sufiks dla wszystkich tabel zmian. Wartość domyślna to __ct. Nazwy tabeli zmian są nazwą tabeli docelowej z dołączonym sufiksem. Na przykład, jeżeli używa się wartości domyślnej, nazwą tabeli zmian będzie HR__ct.
- Prefiks kolumny nagłówka: Określ ciąg, który będzie używany jako prefiks dla wszystkich kolumn nagłówka tabeli zmian. Wartość domyślna to header__. Na przykład, jeżeli używa się wartości domyślnej, kolumna nagłówka stream_position będzie nosić nazwę header__stream_position.
Więcej informacji na temat tabel zmian zawiera temat Używanie tabel zmian.
Jeśli tabela zmian będzie istnieć, gdy rozpocznie się pełne ładowanie: Wybierz jedną z poniższych opcji, aby określić sposób ładowania tabel zmian po rozpoczęciu replikacji z pełnym ładowaniem:
- Usuń i utwórz tabelę zmian: tabela zostanie usunięta, a na jej miejscu zostanie utworzona nowa tabela.
-
Usuń stare zmiany i zachowaj zmiany w istniejącej tabeli zmian: dane są obcinane i dodawane bez wpływu na metadane tabeli.
InformacjaFunkcja nie jest obsługiwana, kiedy platformą docelową jest Microsoft Fabric. - Zachowaj stare zmiany i zapisz nowe zmiany w istniejącej tabeli zmian: nie ma to wpływu na dane i metadane istniejącej tabeli zmian.
Kolumny nagłówka tabeli
Kolumny nagłówka tabeli zmian zawierają informacje o operacjach przetwarzania zmian, takie jak typ operacji (np. INSERT), czas zatwierdzenia itp. Jeśli nie potrzebujesz wszystkich tych informacji, możesz skonfigurować zadanie przenoszenie tak, aby tworzyło tabele zmian z wybranymi kolumnami nagłówków (lub żadnymi), zmniejszając w ten sposób miejsce zajmowane przez nie w docelowej bazie danych.
Opis kolumn nagłówka zawiera temat Tabele zmian.
Obsługa błędów
Podstawowa
Konflikty stosowania
Zduplikowany klucz podczas stosowania INSERT: Wybierz, jakie działanie należy podjąć w przypadku konfliktu z operacją INSERT.
-
Ignoruj: zadanie jest kontynuowane, a błąd jest ignorowany.
-
Zastosuj UPDATE do istniejącego rekordu docelowego: aktualizowany jest rekord docelowy z tym samym kluczem podstawowym co WSTAWIONY rekord źródłowy.
- Zarejestruj rekord w tabeli wyjątków (domyślnie): zadanie jest kontynuowane, a błąd jest zapisywany w tabeli wyjątków.
-
Zawieś tabelę: zadanie jest kontynuowane, ale dane z tabeli z rekordem z błędem są przenoszone do stanu błędu i nie są replikowane.
- Zatrzymaj zadanie: zadanie jest zatrzymywane i jest wymagana interwencja ręczna.
Nie znaleziono rekordu do zastosowania UPDATE: wybierz, jakie działanie podjąć w przypadku konfliktu z operacją UPDATE.
- Ignoruj: zadanie jest kontynuowane, a błąd jest ignorowany.
-
Użyj operacji INSERT do brakującego rekordu docelowego: brakujący rekord docelowy zostanie wstawiony do tabeli docelowej. Jeśli źródłowym punktem końcowym jest Oracle, wybranie tej opcji wymaga włączenia dodatkowego rejestrowania dla wszystkich kolumn tabeli źródłowej.
- Zarejestruj rekord w tabeli wyjątków (domyślnie): zadanie jest kontynuowane, a błąd jest zapisywany w tabeli wyjątków.
-
Zawieś tabelę: zadanie jest kontynuowane, ale dane z tabeli z rekordem z błędem są przenoszone do stanu błędu i nie są replikowane.
- Zatrzymaj zadanie: zadanie jest zatrzymywane i jest wymagana interwencja ręczna.
Zaawansowane
Obsługa błędów danych jest dostepna tylko w trybie replikacji stosowania zmian (nie w trybie pełnego ładowania).
Błędy danych
W przypadku błędów obcinania danych: Wybierz, co ma się stać, gdy w jednym lub większej liczbie określonych rekordów nastąpi obcięcie. Możesz wybrać jedną z następujących opcji z listy:
- Ignoruj: Zadanie jest kontynuowane, a błąd jest ignorowany.
- Zarejestruj rekord w tabeli wyjątków (domyślnie): Zadanie jest kontynuowane, a błąd jest zapisywany w tabeli wyjątków.
- Zawieś tabelę: Zadanie jest kontynuowane, ale dane z tabeli z rekordem z błędem są przenoszone do stanu błędu i nie są replikowane
- Zatrzymaj zadanie: Zadanie jest zatrzymywane i jest wymagana interwencja ręczna.
W przypadku innych błędów danych: Wybierz, co ma się stać, gdy w jednym lub większej liczbie określonych rekordów wystąpi błąd. Możesz wybrać jedną z następujących opcji z listy:
- Ignoruj: Zadanie jest kontynuowane, a błąd jest ignorowany.
- Zarejestruj rekord w tabeli wyjątków (domyślnie): Zadanie jest kontynuowane, a błąd jest zapisywany w tabeli wyjątków.
- Zawieś tabelę: Zadanie jest kontynuowane, ale dane z tabeli z rekordem z błędem są przenoszone do stanu błędu i nie są replikowane
- Zatrzymaj zadanie: Zadanie jest zatrzymywane i jest wymagana interwencja ręczna.
Eskaluj obsługę błędów, kiedy inne błędy danych osiągną (na tabelę): Zaznacz to pole wyboru, aby eskalować obsługę błędów, gdy liczba błędów danych niespowodowanych przez obcięcia (na tabelę) osiągnie określoną wartość. Prawidłowe wartości są z zakresu 1–10 000.
Działanie eskalacji: Wybierz, co powinno się wydarzyć w przypadku eskalacji obsługi błędów. Należy pamiętać, że dostępne działania zależą od działania wybranego z listy rozwijanej W przypadku innych błędów danych opisanej powyżej.
-
Zawieś tabelę (domyślnie): Zadanie jest kontynuowane, ale dane z tabeli z rekordem z błędem są przenoszone do stanu błędu i nie są przeniesione.
InformacjaDziałanie różni się w zależności od trybu przetwarzania zmian:
-
W trybie stosowania transakcyjnego ostatnie zmiany nie będą przeniesione.
-
W trybie Stosowanie zoptymalizowane pod kątem partii może dojść do sytuacji, w której dane nie będą przeniesione wcale lub będą przeniesione tylko częściowo.
-
- Zatrzymaj zadanie: Zadanie jest zatrzymywane i jest wymagana interwencja ręczna.
- Zarejestruj rekord w tabeli wyjątków: Zadanie jest kontynuowane, a rekord jest zapisywany w tabeli wyjątków.
Błędy tabeli
W przypadku napotkania błędu tabeli: wybierz jedną z poniższych opcji z listy rozwijanej:
- Zawieś tabelę (domyślnie): zadanie jest kontynuowane, ale dane z tabeli z rekordem z błędem są przenoszone do stanu błędu i nie są replikowane.
- Zatrzymaj zadanie: zadanie jest zatrzymywane i jest wymagana interwencja ręczna.
Eskaluj obsługę błędów, kiedy inne błędy tabeli osiągną (na tabelę): zaznacz to pole wyboru, aby eskalować obsługę błędów, gdy liczba błędów tabeli (na tabelę) osiągnie określoną wartość. Prawidłowe wartości są z zakresu 1–10 000.
Działanie eskalacji: zasada eskalacji błędów tabeli jest ustawiona na Zatrzymaj zadanie i nie można jej zmienić.
Konflikty stosowania
Nie znaleziono rekordu do zastosowania DELETE: wybierz, jakie działanie zostanie podjęte w przypadku konfliktu z operacją DELETE.
- Ignoruj: zadanie jest kontynuowane, a błąd jest ignorowany.
- Zarejestruj rekord w tabeli wyjątków: zadanie jest kontynuowane, a rekord jest zapisywany w tabeli wyjątków.
- Zawieś tabelę: zadanie jest kontynuowane, ale dane z tabeli z rekordem z błędem są przenoszone do stanu błędu i nie są replikowane.
- Zatrzymaj zadanie: zadanie jest zatrzymywane i jest wymagana interwencja ręczna.
Eskaluj obsługę, gdy konflikty stosowania sięgną (na tabelę):: zaznacz to pole wyboru, aby eskalować obsługę błędów, gdy liczba konfliktów stosowania (na tabelę) osiągnie określoną wartość. Prawidłowe wartości są z zakresu 1–10 000.
Działanie eskalacji: wybierz, co powinno się wydarzyć w przypadku eskalacji obsługi błędów.
- Zarejestruj rekord w tabeli wyjątków (domyślnie): zadanie jest kontynuowane, a błąd jest zapisywany w tabeli wyjątków.
-
Zawieś tabelę: zadanie jest kontynuowane, ale dane z tabeli z rekordem z błędem są przenoszone do stanu błędu i nie są replikowane.
InformacjaDziałanie różni się w zależności od trybu przetwarzania zmian:
-
W trybie stosowania transakcyjnego ostatnie zmiany nie zostaną zreplikowane.
-
W trybie stosowania zoptymalizowanego pod kątem partii może wystąpić sytuacja, w której dane nie będą replikowane lub replikacja danych będzie częściowa.
-
-
Zatrzymaj zadanie: zadanie jest zatrzymywane i jest wymagana interwencja ręczna.
Błędy środowiskowe
-
Maksymalna liczba ponownych prób: Wybierz tę opcję, a następnie określ maksymalną liczbę prób ponawiania zadania w razie wystąpienia błędu środowiskowego umożliwiającego odzyskanie. Po określonej liczbie ponownych prób zadanie zostaje zatrzymane i wymagana jest ręczna interwencja.
Aby nigdy nie ponawiać wykonywania zadania, usuń zaznaczenie pola wyboru lub określ „0”.
Aby ponawiać zadanie nieskończoną liczbę razy, określ „-1”.
-
Interwał między kolejnymi próbami (w sekundach): Użyj licznika, aby wybrać lub wpisać liczbę sekund oczekiwania przez system pomiędzy kolejnymi próbami wykonania zadania.
Prawidłowe wartości są z zakresu 0–2000.
-
- Zwiększ interwał ponawiania prób w przypadku długich przestojów: Zaznacz to pole wyboru, aby zwiększyć interwał ponownych prób w przypadku długich przestojów. Gdy ta opcja jest włączona, odstęp między kolejnymi próbami jest podwajany aż do osiągnięcia Maksymalnego interwału ponownych prób (i próby są kontynuowane zgodnie z określonym maksymalnym interwałem).
- Maksymalny interwał ponownych prób (w sekundach): Użyj licznika, aby wybrać, lub wpisz liczbę sekund oczekiwania pomiędzy kolejnymi próbami wykonania zadania, gdy włączona jest opcja Zwiększ interwał ponawiania prób w przypadku długich przestojów. Prawidłowe wartości są z zakresu 0–2000.
Dostrajanie przetwarzania zmian
Dostrajanie odciążania transakcji
-
Odciąż transakcje w toku na dysku, jeśli:
Zadanie replikacji zwykle przechowuje dane transakcji w pamięci, dopóki nie zostaną w pełni zatwierdzone w źródle i/lub celu. Transakcje, które są większe niż przydzielona pamięć lub które nie zostaną zatwierdzone w określonym limicie czasu, zostaną jednak przeniesione na dysk.
- Rozmiar pamięci transakcji przekracza (MB): maksymalny rozmiar, jaki wszystkie transakcje mogą zajmować w pamięci przed przeniesieniem na dysk. Wartością domyślną jest 1024.
- Czas trwania transakcji przekracza (w sekundach): maksymalny czas, przez który każda transakcja może pozostać w pamięci przed przeniesieniem na dysk. Czas trwania jest liczony od momentu rozpoczęcia rejestrowania transakcji przez zadanie replikacji. Wartością domyślną jest 60.
Strojenie wsadowe
Ustawienia na tej karcie zależą od trybu funkcji Zastosuj zmiany.
Ustawienia dostępne tylko wtedy, gdy Tryb stosowania ma ustawienie Optymalizacja pod kątem partii
- Zastosuj zmiany wsadowe w interwałach:
-
Większy niż: minimalny czas oczekiwania pomiędzy każdym zastosowaniem zmian wsadowych. Wartością domyślną jest 1.
Zwiększanie wartości dłużej niż zmniejsza częstotliwość stosowania zmian w miejscu docelowym, jednocześnie zwiększając rozmiar partii. Może to poprawić wydajność podczas stosowania zmian do docelowych baz danych zoptymalizowanych pod kątem przetwarzania dużych partii.
- Mniejszy niż: maksymalny czas oczekiwania pomiędzy każdym zastosowaniem zmian wsadowych (przed zadeklarowaniem limitu czasu). Innymi słowy jest to maksymalne akceptowalne opóźnienie. Wartością domyślną jest 30. Wartość ta określa maksymalny czas oczekiwania przed zastosowaniem zmian po osiągnięciu wartości Dłużej niż.
-
Wymuś zastosowanie partii, gdy pamięć przetwarzania przekroczy (MB): maksymalna ilość pamięci używana do wstępnego przetwarzania w trybie Stosowanie zoptymalizowane pod kątem partii. Wartością domyślną jest 500.
Aby ustawić maksymalny rozmiar partii, ustaw tę wartość na największą ilość pamięci, jaką możesz przydzielić zadaniu replikacji. Może to poprawić wydajność podczas stosowania zmian do docelowych baz danych zoptymalizowanych pod kątem przetwarzania dużych partii.
Ustawienia dostępne tylko wtedy, gdy Tryb stosowania ma ustawienie Transakcyjny
Poniższe ustawienia są dostępne tylko podczas pracy w transakcyjnym trybie stosowania. Należy pamiętać, że tryb transakcyjny jest jedynym dostępnym trybem stosowania (i dlatego nie można go wybrać) podczas replikacji do Snowflake, a Metodą ładowania jest Snowpipe Streaming.
-
Minimalna liczba zmian na transakcję: minimalna liczba zmian, które należy uwzględnić w każdej transakcji. Wartością domyślną jest 1000.
InformacjaZmiany są stosowane do miejsca docelowego, gdy liczba zmian jest równa lub większa od Minimalnej liczby zmian na transakcję LUB po osiągnięciu opisanej poniżej wartości Maksymalny czas dla transakcji wsadowych przed zastosowaniem (w sekundach) w zależności od tego, co nastąpi wcześniej. Ponieważ częstotliwość zmian stosowanych do miejsca docelowego jest kontrolowana przez te dwa parametry, zmiany w rekordach źródłowych mogą nie zostać natychmiast odzwierciedlone w rekordach docelowych.
- Maksymalny czas dla transakcji wsadowych przed zastosowaniem (w sekundach): maksymalny czas gromadzenia transakcji w partiach przed zadeklarowaniem upłynięcia limitu czasu. Wartością domyślną jest 1.
Interwał
-
Odczytuj zmiany co (w minutach)
Interwał w minutach między odczytywaniem zmian ze źródła. Prawidłowy zakres wynosi od 1 do 1440.
InformacjaTa opcja jest dostępna tylko dla zadań używających:
- Brama danych ruchu danych
- Metoda aktualizacji Zastosuj zmiany lub Przechowaj zmiany
Sprawdź zmiany
-
Zgodnie z interwałem ekstrakcji delty: Po wybraniu tej opcji zadanie danych sprawdza zmiany zgodnie z interwałem ekstrakcji delty.
InformacjaInterwał rozpocznie się po każdej „rundzie”. Runda może być zdefiniowana jako czas potrzebny zadaniu danych na odczytanie zmian z tabel źródłowych i wysłanie ich do celu (jako pojedyncza transakcja). Długość rundy różni się w zależności od liczby tabel i zmian. Jeśli więc określisz interwał 10 minut, a runda trwa 4 minuty, to rzeczywisty czas między sprawdzaniem zmian wyniesie 14 minut.-
Częstotliwość ekstrakcji delty: Częstotliwość, z jaką delty będą wyodrębniane z Twojego systemu. Wartością domyślną jest co 60 sekund.
-
-
Zgodnie z harmonogramem: Po wybraniu tej opcji zadanie danych wyodrębni deltę raz, a następnie zostanie zatrzymane. Następnie będzie kontynuować działanie zgodnie z harmonogramem.
InformacjaTa opcja jest istotna tylko wtedy, gdy odstęp między cyklami CDC wynosi 24 godziny lub więcej.Informacje na temat planowania:
-
"Zadania Replicate data" w projekcie replikacji, zobacz Planowanie zadań
-
Różnie ustawienia strojenia
Rozmiar pamięci podręcznej instrukcji (liczba instrukcji)
Maksymalna liczba przygotowanych instrukcji do przechowywania na serwerze w celu późniejszego wykonania (podczas stosowania zmian w miejscu docelowym). Wartością domyślną jest 50. Maksymalna liczba to 200.
Używaj instrukcji DELETE i INSERT podczas aktualizacji kolumny klucza głównego
Ta opcja jest dostępna tylko wtedy, gdy Przechowuj zmiany tryb replikacji jest włączony i wymaga włączenia pełnego rejestrowania dodatkowego w źródłowej bazie danych.
Wyślij znacznik usunięcia po poleceniu DELETE
Po wybraniu tej opcji wypełniony zostanie tylko klucz wiadomości; sama wiadomość będzie mieć wartość null, co oznacza, że element został usunięty. Może to pomóc konsumentom wykryć, że operacja USUŃ została wykonana.
Przechowuj dane odzyskiwania zadania w docelowej bazie danych
Wybierz tę opcję, aby zapisać informacje dotyczące odzyskiwania specyficzne dla zadania w docelowej bazie danych. Gdy ta opcja jest zaznaczona, zadanie replikacji tworzy tabelę o nazwie attrep_txn_state w docelowej bazie danych. Ta tabela zawiera dane transakcji, których można użyć do odzyskania zadania w przypadku uszkodzenia plików w folderze Data Brama danych ruchu danych lub awarii urządzenia pamięci masowej zawierającego folder Data.
Zastosuj zmiany za pomocą SQL MERGE
Jeśli ta opcja nie zostanie wybrana, zadanie replikacji wykona oddzielne zbiorcze instrukcje INSERT, UPDATE i DELETE dla każdego typu zmian w tabeli Net Changes.
Chociaż ta metoda jest bardzo efektywna, włączenie opcji Zastosuj zmiany za pomocą SQL MERGE jest jeszcze bardziej wydajne podczas pracy z punktami końcowymi obsługującymi tę opcję.
Dzieje się tak z następujących powodów:
- Zmniejsza liczbę instrukcji SQL uruchamianych na tabelę z trzech do jednej. Większość operacji UPDATE w dużych, niezmiennych, opartych na plikach bazach danych w chmurze (takich jak Google Cloud BigQuery) wiąże się z ponownym zapisywaniem plików, których to dotyczy. Przy takich operacjach redukcja instrukcji SQL na tabelę z trzech do jednej jest bardzo znacząca.
- Docelowa baza danych musi tylko raz przeskanować tabelę Net Changes, co znacznie ogranicza liczbę operacji wejścia/wyjścia.
Optymalizacja operacji INSERT
Jeśli wybrano opcję Zastosuj zmiany za pomocą SQL MERGE wraz z opcją Optymalizuj operacje INSERT, a zmiany składają się wyłącznie z INSERT, zadanie replikacji wykona operacje INSERT, zamiast używać SQL MERGE. Chociaż zwykle poprawia to wydajność, a tym samym zmniejsza koszty, może również powodować powielanie rekordów w docelowej bazie danych.
- Opcje Zastosuj zmiany za pomocą SQL MERGE i Optymalizuj operacje INSERT są dostępne tylko w przypadku zadań skonfigurowanych z następującymi docelowymi punktami końcowymi:
- Google Cloud BigQuery
- Databricks
- Snowflake
- Opcje Zastosuj zmiany za pomocą SQL MERGE i Optymalizuj operacje INSERT nie są obsługiwane w przypadku następujących źródłowych punktów końcowych:
- Salesforce
- Oracle
-
Gdy włączona jest opcja Zastosuj zmiany za pomocą SQL MERGE:
- Błędy danych niekrytyczne lub błędy danych, których nie można odzyskać, będą traktowane jako błędy tabeli.
- Zasada obsługi błędów konfliktów stosowania nie będzie edytowalna przy następujących ustawieniach.
- Nie znaleziono rekordu do zastosowania DELETE: ignoruj rekord
Zduplikowany klucz podczas stosowania INSERT: AKTUALIZUJ istniejący rekord docelowy
InformacjaJeżeli wybrana jest także opcja Optymalizuj operacje INSERT, opcja Duplikuj klucz podczas stosowania operacji INSERT zostanie ustawiona na Zezwalaj na duplikaty w miejscach docelowych.- Nie znaleziono rekordu do zastosowania UPDATE: Użyj operacji INSERT do brakującego rekordu docelowego
- Akcja eskalacji: Zarejestruj rekord w tabeli wyjątków
- Następujące opcje Zasady obsługi błędów danych W przypadku innych błędów danych nie będą dostępne:
- Ignoruj rekord
- Zarejestruj rekord w tabeli wyjątków
- Rzeczywista operacja SQL MERGE zostanie wykonana tylko na końcowych tabelach w miejscu docelowym. Operacje INSERT zostaną wykonane na pośrednich tabelach zmian (gdy włączony jest tryb replikacji Zastosuj zmiany lub Zapisz zmiany).
Stosowanie transakcyjne
W przypadku replikacji do obiektów docelowych typu hurtownia danych lub podczas pracy bez Brama danych ruchu danych opcje te nie mają zastosowania, ponieważ trybem stosowania jest zawsze Optymalizacja pod kątem partii z jednym wyjątkiem.
Wyjątkiem jest sytuacja, gdy replikacja odbywa się do Snowflake, a Metoda ładowania jest ustawiona na Snowpipe Streaming.
Poniższe ustawienia są dostępne tylko podczas pracy w transakcyjnym trybie stosowania. W przypadku replikacji do baz danych tryb stosowania może być ustawiony jako Zoptymalizowany pod kątem partii lub Transakcyjny. Jednak w przypadku replikacji do celu Snowflake i ustawienia Metody ładowania na Snowpipe Streaming, tryb stosowania jest zawsze transakcyjny i dlatego nie można go ustawić.
-
Minimalna liczba zmian na transakcję: minimalna liczba zmian, które należy uwzględnić w każdej transakcji. Wartością domyślną jest 1000.
InformacjaZadanie replikacji stosuje zmiany do miejsca docelowego, gdy liczba zmian jest równa lub większa od Minimalnej liczby zmian na transakcję LUB po osiągnięciu limitu czasu partii (patrz poniżej) w zależności od tego, co nastąpi wcześniej. Ponieważ częstotliwość zmian stosowanych do miejsca docelowego jest kontrolowana przez te dwa parametry, zmiany w rekordach źródłowych mogą nie zostać natychmiast odzwierciedlone w rekordach docelowych. - Maksymalny czas dla transakcji wsadowych przed zastosowaniem (w sekundach): maksymalny czas gromadzenia transakcji w partiach przed zadeklarowaniem upłynięcia limitu czasu. Wartością domyślną jest 1.
Automatyczna ewolucja schematu
Wybierz sposób obsługi następujących typów zmian DDL w schemacie. Po zmianie ustawień ewolucji schematu należy ponownie przygotować zadanie. Poniższa tabela opisuje, które działania są dostępne w przypadku obsługiwanych zmian DDL.
| Zmiana DDL | Zastosuj do celu | Ignoruj | Zawieś tabelę | Zatrzymaj zadanie |
|---|---|---|---|---|
| Dodaj kolumnę | Tak | Tak | Tak | Tak |
| Zmień typ danych kolumny | Tak | Tak | Tak | Tak |
| Zmień nazwę kolumny | Tak | Nie | Tak | Tak |
|
Zmień nazwę tabeli InformacjaFunkcja nie jest obsługiwana, kiedy platformą docelową jest Kafka.
|
Nie | Nie | Tak | Tak |
| Usuń kolumnę | Tak | Tak | Tak | Tak |
|
Usuwanie tabeli InformacjaFunkcja nie jest obsługiwana, kiedy platformą docelową jest Kafka.
|
Tak | Tak | Tak | Tak |
| Utwórz tabelę
Jeśli użyto reguły wyboru, aby dodać zestawy danych pasujące do wzorca, nowe tabele spełniające ten wzorzec zostaną wykryte i dodane. |
Tak | Tak | Nie | Nie |
Podstawianie znaków
Możesz zastąpić lub usunąć znaki źródłowe w docelowej bazie danych i/lub znaki źródłowe, które nie są obsługiwane przez wybrany zestaw znaków.
-
Wszystkie znaki muszą być określone jako punkty kodu Unicode.
- Zastępowanie znaków będzie również wykonywane w tabelach kontrolnych.
-
Nieprawidłowe wartości zostaną oznaczone czerwonym trójkątem w prawym górnym rogu komórki tabeli. Wskazanie trójkąta kursorem myszy spowoduje wyświetlenie komunikatu o błędzie.
-
Wszelkie transformacje na poziomie tabeli lub globalne zdefiniowane dla zadania zostaną wykonane po zakończeniu zastępowania znaków.
-
Działania zastępowania zdefiniowane w tabeli Zastąp lub usuń znaki źródłowe są wykonywane przed działaniem zastępowania zdefiniowanym w tabeli Zastąp lub usuń znaki źródłowe nieobsługiwane przez wybrany zestaw znaków.
- Zastępowanie znaków nie obsługuje typów danych LOB.
Zastępowanie lub usuwanie znaków źródłowych
Użyj tabeli Zastąp lub usuń znaki źródłowe, aby zdefiniować zamienniki dla określonych znaków źródłowych. Może to być przydatne na przykład wtedy, gdy reprezentacja znaku w Unicode jest inna na platformie źródłowej i docelowej. Na przykład w systemie Linux znak minus w zestawie znaków Shift_JIS jest reprezentowany jako U+2212, ale w systemie Windows jest reprezentowany jako U+FF0D.
| Cel | Działanie |
|---|---|
|
Zdefiniowanie działań zastępowania |
|
|
Edytowanie określonego znaku źródłowego lub docelowego |
Kliknij |
|
Usunięcie wpisów z tabeli |
Kliknij |
Zastępowanie lub usuwanie znaków źródłowych nieobsługiwanych przez wybrany zestaw znaków
Użyj tabeli Nieobsługiwane znaki źródłowe według zestawu znaków, aby zdefiniować pojedynczy znak zastępczy dla wszystkich znaków nieobsługiwanych przez wybrany zestaw znaków.
| Cel | Działanie |
|---|---|
|
Zdefiniowanie lub edycja działania zastępowania |
|
|
Wyłączenie działania zastępowania. |
Wybierz pusty wpis z listy rozwijanej Zestaw znaków. |
Więcej opcji
Te opcje nie są widoczne w interfejsie, ponieważ dotyczą tylko określonych wersji lub środowisk. W związku z tym nie należy ustawiać tych opcji, chyba że zostanie to wyraźnie zalecone przez Pomoc techniczną Qlik lub dokumentację produktu.
Aby ustawić opcję, po prostu skopiuj ją do pola Dodaj nazwę cechy i kliknij Dodaj. Następnie ustaw wartość lub włącz opcję zgodnie z otrzymaną instrukcją.
Równoległe ładowanie segmentów zestawu danych
Podczas pełnego ładowania można przyspieszyć ładowanie dużych zestawów danych, dzieląc zestaw danych na segmenty, które będą ładowane równolegle. Tabele można dzielić według zakresów danych, wszystkich partycji, wszystkich podpartycji lub określonych partycji.
Więcej informacji zawiera temat Równoległe replikowanie segmentów zestawu danych.
Planowanie zadań
W niektórych przypadkach może być konieczne zaplanowanie zadania w celu propagowania zmian ze źródła danych na platformę docelową.
Więcej informacji zawiera temat Scheduling tasks.