
Instellingen voor replicatie
U kunt instellingen configureren voor de taak voor gegevensreplicatie.
-
Open de replicatietaak en klik op Instellingen in de werkbalk.
Het dialoogvenster Instellingen: <Taaknaam> wordt geopend. De beschikbare instellingen worden hieronder beschreven.
Algemeen
Op dit tabblad kunt u de replicatiemodus, de staging-instellingen (indien beschikbaar), de modus voor het toepassen van wijzigingen op het doel en de publicatie-instellingen wijzigen.
Replicatiemodus
De volgende replicatiemodi zijn beschikbaar:
-
Volledige lading: Laadt de gegevens van de geselecteerde brontabellen naar het doelplatform en maakt indien nodig de doeltabellen. De volledige lading vindt automatisch plaats als de taak is gestart, maar kan indien mogelijk ook handmatig worden uitgevoerd. Handmatige volledige lading is bijvoorbeeld nodig als u updates naar Weergaven moet repliceren (die niet worden vastgelegd tijdens CDC) of als u repliceert vanaf een gegevensbron die CDC niet ondersteunt.
-
Wijzigingen toepassen: Werkt de doeltabellen continu bij met wijzigingen die in de brontabellen zijn aangebracht.
-
Wijzigingen opslaan: Slaat de wijzigingen van de brontabellen op in wijzigingstabellen (één per brontabel).
Ga voor meer informatie naar Instellingen voor replicatie.
Bij het werken met Data Movement gateway worden wijzigingen van de bron vrijwel direct vastgelegd. Als u werkt zonder Data Movement gateway (bijvoorbeeld met een Qlik Talend Cloud Starter-abonnement of als u Geen hebt geselecteerd), worden wijzigingen vastgelegd volgens de planningsinstellingen. Ga voor meer informatie naar Instellingen voor replicatie.
Als u Wijzigingen opslaan of Wijzigingen toepassen selecteert en uw brongegevens tabellen bevatten die geen CDC ondersteunen, of weergaven, worden er twee gegevenspijplijnen gemaakt. Eén pijplijn voor tabellen die CDC ondersteunen, en een andere pijplijn voor alle andere tabellen en weergaven die alleen Volledige lading ondersteunen.
Laadmethode
Bij replicatie naar Snowflake kunt u een van de volgende laadmethoden kiezen:
-
Bulkladen (de standaardinstelling)
Als u Bulkladen selecteert, kunt u de laadparameters afstemmen op het tabblad Gegevens uploaden.
-
Snowpipe Streaming
InformatieSnowpipe Streaming is alleen beschikbaar voor selectie als aan de volgende voorwaarden is voldaan:
- De replicatiemodus Wijzigingen opslaan is ingeschakeld, zonder Wijzigingen toepassen.
- Het Authenticatiemechanisme in de Snowflake-connector is ingesteld op Sleutelpaar.
- Als u Data Movement gateway gebruikt, is versie 2024.11.45 of later vereist.
Als u Snowpipe Streaming selecteert, zorg er dan voor dat u bekend bent met de beperkingen en overwegingen bij het gebruik van deze methode. Bovendien, als u Snowpipe Streaming selecteert en vervolgens de replicatiemodus Wijzigingen toepassen inschakelt of Wijzigingen opslaan uitschakelt, wordt de laadmethode automatisch teruggezet naar Bulkladen.
De belangrijkste redenen om Snowpipe Streaming te verkiezen boven Bulkladen zijn:
-
Minder duur: Aangezien Snowpipe Streaming het Snowflake-warehouse niet gebruikt, zouden de operationele kosten aanzienlijk lager moeten zijn, hoewel dit afhangt van uw specifieke use case.
-
Verminderde latentie: Aangezien de gegevens rechtstreeks naar de doeltabellen worden gestreamd (in tegenstelling tot via staging), zou de replicatie van de gegevensbron naar het doel sneller moeten zijn.
Verbinding maken met een staging-gebied
Bij het repliceren van de onderstaande datawarehouses, moet u een tussenopslag instellen. Gegevens worden verwerkt en voorbereid in de tussenopslag voordat ze naar het warehouse worden verzonden.
Selecteer een bestaande tussenopslag of klik op Nieuwe maken om een nieuwe tussenopslag te definiëren en volg de instructies in Verbinding maken met een cloudopslag.
Klik op Bewerken om de verbindingsinstellingen te bewerken. Klik op Verbinding testen om de verbinding te testen (aanbevolen).
Raadpleeg de kolom Ondersteund als tussenopslaggebied in Gebruikscases doelplatform en ondersteunde versies voor informatie over welke tussenopslaggebieden voor welk datawarehouse worden ondersteund.
Modus voor wijzigingen toepassen
Wijzigingen worden toegepast op de doeltabellen met behulp van een van de volgende methoden:
- Batch geoptimaliseerd: Dit is de standaardinstelling. Als deze optie is geselecteerd, worden wijzigingen batchgewijs toegepast. Er wordt een voorverwerkingsactie uitgevoerd om de transacties zo efficiënt mogelijk te groeperen in batches.
- Transactioneel: Selecteer deze optie om elke transactie afzonderlijk toe passen, in de vastgelegde volgorde. In dit geval wordt strikte referentiële integriteit verzekerd voor alle tabellen.
Publicatie-instellingen
-
Publiceren naar catalogus
Selecteer deze optie om deze versie van de gegevens naar Catalogus te publiceren als een gegevensset. De inhoud van de catalogus wordt bijgewerkt de volgende keer dat u deze taak voorbereidt.
Voor meer informatie over Catalogus, zie Uw gegevens begrijpen met catalogushulpmiddelen.
Proxy-instellingen bij gebruik van Data Movement gateway
-
Bij gebruik van Data Movement gateway, verbinding maken via proxy met
Bij gebruik van Data Movement gateway kunt u via een proxy verbinding maken met het doelplatform en het staging-platform (gebied).
Voor meer informatie over het configureren van Data Movement gateway om een proxyserver te gebruiken, zie De Qlik Cloud-tenant en een proxyserver instellen.
-
Doelplatform
InformatieBeschikbaar bij gebruik van Snowflake en Databricks. -
Staging-platform
InformatieBeschikbaar bij gebruik van Google BigQuery, Amazon Redshift, Microsoft Fabric en Databricks.
-
Gegevens uploaden
Dit tabblad wordt alleen weergegeven bij replicatie naar een datawarehouse of Kafka-doel. Bovendien verschillen de instellingen op dit tabblad afhankelijk van het geselecteerde doel.
Relevant voor alle datawarehouse-doelen
Maximale bestandsgrootte
De maximumgrootte die een bestand kan bereiken voordat het wordt gesloten. Kleinere bestanden worden mogelijk sneller geüpload (afhankelijk van het netwerk) en verbeteren de prestaties indien ze worden gebruikt in combinatie met de optie Parallelle uitvoering. Het wordt over het algemeen afgeraden om de database te vullen met kleine bestanden.
Alleen relevant voor Snowflake-doel
Op het tabblad Algemeen kunt u selecteren of u de gegevens naar Snowflake wilt laden met behulp van Bulkladen of Snowpipe Streaming. Wanneer Snowpipe Streaming is geselecteerd, wordt het tabblad Gegevens uploaden niet weergegeven. Wanneer Bulkladen is geselecteerd, zijn de volgende instellingen beschikbaar:
-
Maximale bestandsgrootte (MB): Relevant voor de initiële volledige lading en CDC. De maximale grootte die een bestand kan bereiken voordat het naar het doel wordt geladen. Als u prestatieproblemen ondervindt, probeer dan deze parameter aan te passen.
-
Aantal bestanden dat in een batch moet worden geladen: Alleen relevant voor de initiële volledige lading. Het aantal bestanden dat in één batch moet worden geladen. Als u prestatieproblemen ondervindt, probeer dan deze parameter aan te passen.
Voor een beschrijving van de laadmethoden Bulkladen en Snowpipe Streaming, zie Algemeen.
Alleen relevant voor Kafka-doel
Berichteigenschappen
Compressie
Selecteer optioneel een van de beschikbare compressiemethoden (Snappy of Gzip). De standaardinstelling is Geen.
Gegevensberichten publiceren
Kies een van de volgende opties voor De gegevens publiceren naar:
- Specifiek onderwerp: Publiceert de gegevens naar één onderwerp. Typ een onderwerpnaam of gebruik de bladerknop om het gewenste onderwerp te selecteren.
-
Aparte onderwerpen voor elke tabel: Publiceert de gegevens naar meerdere onderwerpen die overeenkomen met de brontabelnamen.
De doel-topicnaam bestaat uit de naam van het bronschema en de naam van de brontabel, gescheiden door een punt (bijvoorbeeld, dbo.Employees). Het formaat van de doel-topicnaam is belangrijk, aangezien u deze topic's van tevoren moet voorbereiden.
Als de onderwerpen niet bestaan, configureer dan de brokers met auto.create.topics.enable=true om de gegevenstaak in staat te stellen de onderwerpen tijdens runtime te maken. Anders zal de taak mislukken.
Voor informatie over het overschrijven van deze instelling op gegevenssetniveau, zie Taakinstellingen overschrijven voor afzonderlijke datasets bij publicatie naar Kafka
Berichtsleutel
Selecteer een van de beschikbare opties.
-
Primaire sleutelkolommen: Voor elk bericht bevat de berichtsleutel de waarde van de primaire sleutelkolom.
Wanneer Op berichtsleutel is geselecteerd als de Partitiestrategie, worden berichten die uit dezelfde primaire sleutelwaarde bestaan naar dezelfde partitie geschreven.
-
Schema- en tabelnaam: Voor elk bericht bevat de berichtsleutel een combinatie van schema- en tabelnaam (bijvoorbeeld dbo+Employees).
Wanneer Op berichtsleutel is geselecteerd als de Partitiestrategie, worden berichten die uit dezelfde schema- en tabelnaam bestaan naar dezelfde partitie geschreven.
- Geen: Maakt berichten zonder een berichtsleutel.
Voor informatie over het overschrijven van deze instelling op gegevenssetniveau, zie Taakinstellingen overschrijven voor afzonderlijke datasets bij publicatie naar Kafka
Partitiestrategie
Selecteer Willekeurig of Op berichtsleutel. Als u Willekeurig selecteert, wordt elk bericht naar een willekeurig geselecteerde partitie geschreven. Als u Op berichtsleutel selecteert, worden berichten naar partities geschreven op basis van de geselecteerde Berichtsleutel (hierboven beschreven).
Metagegevensberichten publiceren
Strategie voor onderwerpnaam
De eerste strategie (Schema- en tabelnaam) is een bedrijfseigen Qlik-strategie, terwijl de andere drie standaard Confluent-strategieën voor onderwerpnamen zijn.
Selecteer een van de beschikbare strategieën voor onderwerpnamen.
- Schema- en tabelnaam (standaard)
- Onderwerpnaam
- Recordnaam
- Onderwerp- en recordnaam
Voor meer informatie over de strategieën voor onderwerpnamen van Confluent, zie Strategie voor onderwerpnaam
Compatibiliteitsmodus voor onderwerp
Selecteer een van de volgende compatibiliteitsmodi in de vervolgkeuzelijst Compatibiliteitsmodus voor onderwerp:
-
Standaardinstellingen van Schema Registry gebruiken: Haalt het compatibiliteitsniveau op uit de serverconfiguratie van Schema Registry.
-
Achterwaarts - Alleen nieuwste schema: Nieuwe schema's kunnen alleen overeenkomstige gegevens lezen en gegevens die zijn geproduceerd door het laatst geregistreerde schema.
-
Achterwaarts transitief - Alle vorige schema's: Nieuwe schema's kunnen gegevens lezen die zijn geproduceerd door alle eerder geregistreerde schema's.
-
Voorwaarts - Alleen nieuwste schema: Het laatst geregistreerde schema kan gegevens lezen die zijn geproduceerd door het nieuwe schema.
-
Voorwaarts transitief - Alle vorige schema's: Alle eerder geregistreerde schema's kunnen gegevens lezen die zijn geproduceerd door het nieuwe schema.
-
Volledig - Alleen nieuwste schema: Het nieuwe schema is achterwaarts en voorwaarts compatibel met het laatst geregistreerde schema.
-
Volledig transitief - Alle vorige schema's: Het nieuwe schema is achterwaarts en voorwaarts compatibel met alle eerder geregistreerde schema's.
-
Geen
- Afhankelijk van de geselecteerde Strategie voor onderwerpnaam zijn sommige compatibiliteitsmodi mogelijk niet beschikbaar.
-
Bij het publiceren van berichten naar een Schema Registry is de standaard compatibiliteitsmodus voor onderwerpen voor alle nieuw gemaakte Onderwerpen voor controletabellen Geen, ongeacht de geselecteerde Compatibiliteitsmodus voor onderwerp.
Als u wilt dat de geselecteerde Compatibiliteitsmodus voor onderwerp ook van toepassing is op controletabellen, stelt u de interne parameter setNonCompatibilityForControlTables in de Kafka-doelconnector in op false.
Een proxy gebruiken om verbinding te maken met Confluent Schema Registry
Deze optie wordt alleen ondersteund bij publicatie naar de Confluent Schema Registry.
Schakel in als uw Data Movement gateway is geconfigureerd om een proxyserver te gebruiken.
Berichtkenmerken
U kunt aangepaste berichtkenmerken opgeven die de standaardberichtkenmerken overschrijven. Dit is handig als de consumentenapplicatie het bericht in een bepaalde indeling moet verwerken.
Aangepaste berichtkenmerken kunnen zowel op taak- als op tabelniveau worden gedefinieerd. Wanneer de kenmerken op zowel taak- als tabelniveau zijn gedefinieerd, hebben de berichtkenmerken die voor de tabel zijn gedefinieerd voorrang op de kenmerken die voor de taak zijn gedefinieerd.
Voor informatie over het overschrijven van de berichtkenmerken op gegevenssetniveau, zie Taakinstellingen overschrijven voor afzonderlijke datasets bij publicatie naar Kafka
Hiërarchisch gestructureerde berichten worden niet ondersteund.
Algemene regels en richtlijnen voor gebruik
Bij het definiëren van een aangepast bericht is het belangrijk om de onderstaande regels en richtlijnen voor gebruik in overweging te nemen.
Sectienamen
De volgende naamgevingsregels zijn van toepassing:
- Sectienamen moeten beginnen met de tekens a-z, A-Z of _ (een onderstrepingsteken) en kunnen vervolgens worden gevolgd door een van de volgende tekens: a-z, A-Z, 0-9, _
- Met uitzondering van de secties Recordnaam en Sleutelnaam (die niet eindigen op een schuine streep), zal het verwijderen van de schuine streep uit sectienamen de hiërarchie van de bijbehorende sectie afvlakken (zie Schuine strepen hieronder).
- Alle sectienamen behalve Recordnaam en Sleutelnaam kunnen worden verwijderd (zie Verwijdering hieronder)
-
De sectienamen Gegevensnaam en Record Before-data opnemen kunnen niet beide worden verwijderd
-
De sectienamen Gegevensnaam en Record Before-data opnemen mogen niet hetzelfde zijn
Sommige sectienamen in de gebruikersinterface eindigen op een schuine streep (bijv. beforeData/). Het doel van de schuine streep is om een hiërarchie van de verschillende secties binnen het bericht te behouden. Als de schuine streep wordt verwijderd, gebeurt het volgende:
- De hiërarchische structuur van die sectie wordt afgevlakt, wat ertoe leidt dat de sectienaam uit het bericht wordt verwijderd
- De sectienaam wordt als voorvoegsel aan de daadwerkelijke metagegevens toegevoegd, hetzij rechtstreeks, hetzij met behulp van een scheidingsteken (bijv. een onderstrepingsteken) dat u aan de naam hebt toegevoegd
Voorbeeld van een gegevensbericht wanneer headers/ is opgegeven met een schuine streep:
"message":{
"data":{
"COL1": "159",
"COL2": "159"
},
"beforeData": null,
"headers": {
"operation": "INSERT",
"changeSequence": "2018100811484900000000233",
Voorbeeld van een gegevensbericht wanneer headers_ is opgegeven met een onderstrepingsteken in plaats van een schuine streep:
"message":{
"data":{
"COL1": "159",
"COL2": "159"
},
"beforeData": null,
"headers_operation": "INSERT",
"headers_changeSequence": "2018100811484900000000233",
Het verwijderen van een sectienaam uit het bericht zal de hiërarchische structuur van die sectie afvlakken. Dit zal ertoe leiden dat alle gegevens van die sectie onmiddellijk onder de inhoud van de voorgaande sectie verschijnen.
Voorbeeld van een gegevensbericht met de sectienaam headers :
"message":{
"data":{
"COL1": "159",
"COL2": "159"
},
"headers": {
"operation": "INSERT",
"changeSequence": "2018100811484900000000233",
Voorbeeld van een gegevensbericht zonder de sectienaam headers :
"message":{
"data":{
"COL1": "159",
"COL2": "159"
},
"beforeData": null,
"operation": "INSERT",
"changeSequence": "2018100811484900000000233",
Variabelen
U kunt variabelen aan namen toevoegen door op de knop ![]() aan het einde van de rij te klikken. De volgende variabelen zijn beschikbaar:
aan het einde van de rij te klikken. De volgende variabelen zijn beschikbaar:
- SERVER_NAME - De hostnaam van de Data Movement gateway-server
- TARGET_TABLE_NAME - De naam van de tabel
- TARGET_TABLE_OWNER - De tabeleigenaar
- TASK_NAME - De naam van de gegevenstaak
De variabele TARGET_TABLE_OWNER is niet beschikbaar voor de opties Recordnaam en Sleutelnaam (beschreven in de onderstaande tabel).
Aangepaste berichtkenmerken definiëren
Om een aangepaste berichtindeling te definiëren, schakelt u Aangepaste instellingen gebruiken in en configureert u de opties zoals beschreven in de onderstaande tabel.
Om terug te keren naar de standaardberichtkenmerken, schakelt u Aangepaste instellingen gebruiken uit.
| Optie | Beschrijving |
|---|---|
|
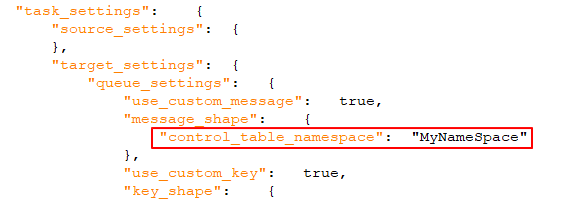
Wanneer ingeschakeld (de standaardinstelling), wordt een unieke identificatie in het bericht opgenomen. Dit moet een tekenreeks zijn, gescheiden door punten. Merk op dat de naamruimte zowel in het bericht als in de berichtsleutel wordt opgenomen. Voorbeeld: mycompany.queue.msg Standaardnaam: com.attunity.queue.msg.{{TASK_NAME}}.{{TARGET_TABLE_OWNER}}.{{TARGET_TABLE_NAME}} Standaardnaam voor controletabellen: com.attunity.queue.msg.{{TARGET_TABLE_NAME}} Informatie
De standaardnaamruimte voor controletabellen kan niet worden gewijzigd via de gebruikersinterface. U kunt de standaardnaamruimte voor controletabellen echter als volgt wijzigen:
|
|
|
Recordnaam |
De naam van de record (bericht). Standaardnaam: DataRecord |
|
Gegevensnaam |
Alle gegevenskolommen die in de record zijn opgenomen. Standaardnaam: data/ |
|
Kopteksten opnemen |
Wanneer ingeschakeld (de standaardinstelling), worden koptekstkolommen in het bericht opgenomen. Koptekstkolommen bieden aanvullende informatie over de bronbewerkingen. Voor meer informatie, zie De volgende kopteksten opnemen hieronder. |
|
Naamruimte voor kopteksten opnemen |
Wanneer ingeschakeld (de standaardinstelling), wordt een unieke identificatie voor de sectie met koptekstkolommen in het bericht opgenomen. Dit moet een tekenreeks zijn, gescheiden door punten. Voorbeeld: headers.queue.msg Standaardnaam: com.attunity.queue.msg |
|
Naam van kopteksten |
De naam van de sectie die de Qlik-kolomkoppen bevat. Standaardnaam: headers/ |
|
Voor een beschrijving van de beschikbare koptekstkolommen raadpleegt u Gegevensberichten in de Qlik Help. Standaard: Alle kolommen zijn standaard opgenomen, behalve de kolom Externe schema-ID. |
|
|
Record Before-data opnemen |
Wanneer ingeschakeld (de standaardinstelling), worden zowel pre- als post-UPDATE-gegevens opgenomen in UPDATE-berichten. Om alleen de post-UPDATE-gegevens in berichten op te nemen, schakelt u de optie uit. Standaardnaam: beforeData/ |
|
Sleutelnaam |
De naam van de sectie die de berichtsleutel bevat. Standaardnaam: keyRecord Deze optie is alleen van toepassing wanneer:
|
Aanvullende instellingen
-
Maximale berichtgrootte
Geef in het veld Maximale berichtgrootte de maximale grootte op van berichten die de broker(s) zijn geconfigureerd om te ontvangen (message.max.bytes). De gegevenstaak verzendt geen berichten die groter zijn dan de maximale grootte.
Metagegevens
Basis
-
Doeltabelschema
Het schema op het doel waarnaar de brontabellen worden gerepliceerd als u het brontabelschema niet wilt gebruiken (of als er geen schema in de brondatabase is).
InformatieBij replicatie naar een Oracle-doel is het standaard doeltabelschema "system". Merk ook op dat als u dit veld leeg laat (in welk geval het bronschema wordt gebruikt), u ervoor moet zorgen dat het bronschema al op het doel bestaat. Anders zal de taak mislukken.InformatieDe maximaal toegestane lengte voor de schemanaam is 128 tekens.
JSON-kolomtoewijzing
Wijs compatibele JSON-kolommen van de bron toe aan JSON-kolommen in het doel
-
Als u Data Movement gateway gebruikt om toegang te krijgen tot uw gegevensbron, is versie 2024.11.70 of later vereist.
-
Alleen ondersteund met Preview-connectors voor een SaaS-applicatie.
Wanneer deze optie is geselecteerd, worden JSON-kolommen in de bron automatisch toegewezen aan JSON-kolommen in het doel.
De status en zichtbaarheid van deze optie wordt bepaald door de volgende factoren:
-
Nieuwe taken: Deze optie wordt standaard ingeschakeld als zowel de bron als het doel het JSON-gegevenstype ondersteunen.
-
Bestaande taken: Deze optie is standaard uitgeschakeld, zelfs als zowel de bron als het doel het JSON-gegevenstype ondersteunen. Dit is om achterwaartse compatibiliteit te behouden met stroomafwaartse processen - zoals transformaties - die verwachten dat de doelgegevens in STRING-indeling zijn (wat het verouderde gedrag is). U kunt de optie uitgeschakeld laten of u kunt de downstreamprocessen bewerken zodat ze compatibel zijn met de JSON-indeling en vervolgens deze optie inschakelen.
-
Nieuwe en bestaande taken: Als alleen de bron het JSON-gegevenstype ondersteunt, is deze optie niet zichtbaar. Als JSON-ondersteuning in een later stadium aan het doel wordt toegevoegd, wordt de optie zichtbaar, maar blijft deze uitgeschakeld. Dit is om achterwaartse compatibiliteit te behouden met downstream processen - zoals transformaties - die verwachten dat de doelgegevens in STRING-indeling zijn (wat het verouderde gedrag is).
LOB-instellingen
 , zowel in het dialoogvenster Verbinding maken als in de online Help.
, zowel in het dialoogvenster Verbinding maken als in de online Help.De beschikbare LOB-instellingen verschillen afhankelijk van het geselecteerde replicatiedoel. Aangezien datawarehouse-doelen geen onbeperkte LOB-kolomgroottes ondersteunen, is deze optie niet beschikbaar bij replicatie naar een datawarehouse.
LOB-instellingen voor doelen die geen datawarehouses zijn
- LOB-kolommen niet opnemen: Selecteer dit als u niet wilt dat bron-LOB-kolommen worden gerepliceerd.
-
LOB-kolomgrootte beperken tot (KB): Dit is de standaardinstelling. Selecteer deze optie als u alleen kleine LOB's hoeft te repliceren of als het doelplatform geen onbeperkte LOB-grootte ondersteunt. De maximaal toegestane waarde voor dit veld is 102400 KB (100 MB).
Bij het repliceren van kleine LOB's is deze optie efficiënter dan de optie LOB-kolomgrootte niet beperken, aangezien de LOB's "uitgelijnd" worden gerepliceerd in plaats van via "opzoeken" vanuit de bron. Tijdens wijzigingsverwerking worden kleine LOB's meestal gerepliceerd via "opzoeken" vanuit de bron.
De limiet is van toepassing op het aantal LOB-bytes dat van het broneindpunt wordt gelezen. Voor BLOB-kolommen is de doel-BLOB-grootte exact volgens de opgegeven limiet. Voor CLOB- en NCLOB-kolommen kan de doel-LOB-grootte afwijken van de opgegeven limiet als de bron- en doel-LOB niet dezelfde tekenset hebben. In dit geval voert de gegevenstaak een tekensetconversie uit, wat kan leiden tot een discrepantie tussen de bron- en doel-LOB-groottes.
Aangezien de waarde van LOB-grootte beperken tot in bytes is, moet de grootte worden berekend volgens de volgende formules:
- BLOB: De lengte van de grootste LOB.
- NCLOB: De lengte van de langste TEKST in tekens vermenigvuldigd met twee (aangezien elk teken als een dubbele byte wordt behandeld). Als de gegevens 4-byte tekens bevatten, vermenigvuldigt u dit met vier.
- CLOB: De lengte van de langste TEKST in tekens (aangezien elk teken als een UTF8-teken wordt behandeld). Als de gegevens 4-byte tekens bevatten, vermenigvuldigt u dit met twee.
Informatie- LOB's die groter zijn dan de opgegeven grootte, worden afgekapt.
- Tijdens wijzigingsverwerking vanuit een Oracle-bron worden uitgelijnde BLOB's uitgelijnd gerepliceerd.
- Wijzigingen in deze instelling zijn alleen van invloed op bestaande tabellen nadat ze opnieuw zijn geladen.
-
LOB-kolomgrootte niet beperken: Wanneer deze optie is geselecteerd, worden LOB-kolommen gerepliceerd, ongeacht de grootte.
InformatieHet repliceren van LOB-kolommen kan de prestaties beïnvloeden. Dit geldt met name voor grote LOB-kolommen waarbij de replicatietaak een opzoekactie in de brontabel moet uitvoeren om de bron-LOB-waarde op te halen.-
Optimaliseren wanneer LOB-grootte kleiner is dan: Selecteer deze optie wanneer u zowel kleine als grote LOB's moet repliceren en de meeste LOB's klein zijn.
InformatieDeze optie wordt alleen ondersteund met de volgende bronnen en doelen:
-
Bronnen: Oracle, Microsoft SQL Server, MySQL, PostgreSQL en IBM DB2 voor LUW
-
Doelen: Oracle, Microsoft SQL Server, MySQL, PostgreSQL.
Wanneer deze optie is geselecteerd, worden de kleine LOB's tijdens de volledige lading "uitgelijnd" gerepliceerd (wat efficiënter is), en worden de grote LOB's gerepliceerd door een opzoekactie in de brontabel uit te voeren. Tijdens wijzigingsverwerking worden echter zowel kleine als grote LOB's gerepliceerd door een opzoekactie in de brontabel uit te voeren.
InformatieWanneer deze optie is geselecteerd, controleert de replicatietaak alle LOB-groottes om te bepalen welke "uitgelijnd" moeten worden overgedragen. LOB's die groter zijn dan de opgegeven grootte, worden gerepliceerd met behulp van de modus Volledige LOB.
Daarom, als u weet dat de meeste LOB's groter zijn dan de opgegeven instelling, verdient het de voorkeur om in plaats daarvan de optie Onbeperkte LOB-kolommen repliceren te gebruiken.
-
-
Chunkgrootte (KB): Wijzig optioneel de grootte van de LOB-chunks die moeten worden gebruikt bij het repliceren van de gegevens naar het doel. De standaard chunkgrootte zou in de meeste gevallen moeten volstaan, maar als u prestatieproblemen ondervindt, kan het aanpassen van de grootte de prestaties verbeteren.
InformatieBij sommige databases vindt validatie van het gegevenstype plaats wanneer de gegevens worden ingevoegd of bijgewerkt. In dergelijke gevallen kan de replicatie van gestructureerde gegevenstypen (bijv. XML, JSON, GEOGRAPHY, enz.) mislukken als de gegevens groter zijn dan de opgegeven chunkgrootte.
-
LOB-instellingen voor ondersteunde datawarehouse-doelen
-
LOB-kolommen opnemen en kolomgrootte beperken tot (KB):
U kunt ervoor kiezen om LOB-kolommen in de taak op te nemen en de maximale LOB-grootte in te stellen. LOB's die groter zijn dan de maximale grootte, worden afgekapt.
Geavanceerd
Instellingen voor controletabellen
-
Schema voor controletabellen: Geef het doelschema voor de controletabellen op als u niet wilt dat ze in het bronschema (de standaardinstelling) of in het doelschema worden gemaakt.
InformatieDe maximaal toegestane lengte voor de schemanaam is 128 tekens. - Doelcontroletabellen maken in tabelruimte: Als het replicatiedoel Oracle is, geef dan de tabelruimte op waarin u de doelcontroletabellen wilt maken. Als u geen gegevens opgeeft in dit veld, worden de tabellen gemaakt in de standaardtabelruimte in de doeldatabase.
- Indexen maken voor doelcontroletabellen in tabelruimte: Als het replicatiedoel Oracle is, geef dan de tabelruimte op waarin u de doelcontrole-indexen wilt maken. Als u geen gegevens opgeeft in dit veld, worden de indexen gemaakt in dezelfde tabelruimte als de controletabellen.
- Tijdslot voor replicatiegeschiedenis (minuten): De lengte van elk tijdslot in de controletabel Replicationgeschiedenis. De standaardinstelling is 5 minuten.
Selectie van controletabellen
Selecteer de controletabellen die u op het doelplatform wilt maken:
| Logische naam | Naam in doel |
|---|---|
| Uitzonderingen toepassen | attrep_apply_exceptions |
| Replicatiestatus | attrep_status |
| Opgeschorte tabellen | attrep_suspended_tables |
| Replicatiegeschiedenis | attrep_history |
| DDL-geschiedenis |
attrep_ddl_history De DDL‑geschiedenistabel wordt alleen ondersteund door de volgende doelplatformen:
|
Voor meer informatie over controletabellen, zie Controletabellen.
Volledige lading
, zowel in het dialoogvenster Verbinding maken als in de online Help.Basis
Deze instellingen worden toegepast tijdens de voorbereidingsfase van de gegevenstaak en telkens wanneer een tabel opnieuw wordt geladen.
Als doeltabel al bestaat: Selecteer een van de volgende opties om te bepalen hoe de gegevens naar de doeltabellen moeten worden geladen:
De optie om de doeltabellen te verwijderen of af te kappen is alleen relevant als dergelijke bewerkingen door het broneindpunt worden ondersteund.
-
Tabel verwijderen en maken: De doeltabel wordt verwijderd en er wordt een nieuwe tabel in de plaats gemaakt.
InformatieDe controletabellen van de replicatietaak worden niet verwijderd. Eventuele opgeschorte tabellen die worden verwijderd, worden echter ook verwijderd uit de controletabel attrep_suspended_tables als de bijbehorende taak opnieuw wordt geladen.
-
AFKAPPEN voor het laden: Gegevens worden afgekapt zonder de metagegevens van de doeltabel te beïnvloeden. Merk op dat wanneer deze optie is geselecteerd, het inschakelen van de optie Primaire sleutel of unieke index maken nadat volledige lading is voltooid geen effect heeft.
InformatieNiet ondersteund wanneer Microsoft Fabric het doelplatform is. - Negeren: Bestaande gegevens en metagegevens van de doeltabel worden niet beïnvloed. Nieuwe gegevens worden aan de tabel toegevoegd.
Geavanceerd
Prestaties afstemmen
Als gegevensreplicatie buitensporig traag is, kan het aanpassen van de volgende parameters de prestaties verbeteren.
- Maximumaantal tabellen: Voer het maximumaantal tabellen in dat tegelijkertijd in het doel moet worden geladen. De standaardwaarde is 5.
-
Time-out voor transactieconsistentie (seconden): Voer het aantal seconden in dat de replicatietaak moet wachten tot openstaande transacties zijn gesloten, voordat de bewerking voor volledige lading begint. De standaardwaarde is 600 (10 minuten). De replicatietaak begint met de volledige lading nadat de time-outwaarde is bereikt, zelfs als er openstaande transacties zijn.
InformatieOm transacties te repliceren die openstonden toen de volledige lading begon, maar pas werden vastgelegd nadat de time-outwaarde was bereikt, moet u de doeltabellen opnieuw laden. - Commit-snelheid tijdens volledige lading: Het maximumaantal gebeurtenissen dat samen kan worden overgedragen. De standaardwaarde is 10000.
Nadat de volledige lading is voltooid
U kunt de taak zo instellen dat deze automatisch stopt nadat de volledige lading is voltooid. Dit is handig als u DBA-bewerkingen op de doeltabellen moet uitvoeren voordat de fase Wijzigingen toepassen (d.w.z. CDC) van de taak begint.
Tijdens de volledige lading worden alle DML-bewerkingen die op de brontabellen worden uitgevoerd, in de cache opgeslagen. Wanneer de volledige lading is voltooid, worden de in de cache opgeslagen wijzigingen automatisch toegepast op de doeltabellen (zolang de hieronder beschreven opties Voordat/Nadat in de cache opgeslagen wijzigingen zijn toegepast zijn uitgeschakeld).
- Primaire sleutel of unieke index maken: Selecteer deze optie als u het maken van een primaire sleutel of unieke index op het doel wilt uitstellen tot nadat de volledige lading is voltooid.
- De taak stoppen:
Informatie
Deze instellingen zijn niet beschikbaar wanneer:
- Repliceren vanuit SaaS-applicatiebronnen (aangezien er geen in de cache opgeslagen gebeurtenissen zijn)
- Repliceren naar datawarehouse-doelen
-
Voordat in de cache opgeslagen wijzigingen zijn toegepast: Selecteer om de taak te stoppen nadat de volledige lading is voltooid.
-
Nadat in de cache opgeslagen wijzigingen zijn toegepast: Selecteer om de taak te stoppen zodra de gegevens consistent zijn in alle tabellen in de taak.
InformatieLet op het volgende wanneer u de taak configureert om te stoppen nadat de volledige lading is voltooid:
- De taak stopt niet op het moment dat de volledige lading is voltooid. Deze wordt pas gestopt nadat de eerste batch met wijzigingen is vastgelegd (aangezien dit de trigger is om de taak te stoppen). Dit kan even duren, afhankelijk van hoe vaak de brondatabase wordt bijgewerkt. Nadat de taak is gestopt, worden de wijzigingen pas op het doel toegepast als de taak wordt hervat.
- Het kiezen van Voordat in de cache opgeslagen wijzigingen zijn toegepast kan de prestaties beïnvloeden, aangezien de in de cache opgeslagen wijzigingen pas op tabellen worden toegepast (zelfs op tabellen die de volledige lading al hebben voltooid) nadat de laatste tabel de volledige lading heeft voltooid.
- Wanneer deze optie is geselecteerd en er een DDL wordt uitgevoerd op een van de brontabellen tijdens het proces van de volledige lading (in een taak Volledige lading en wijzigingen toepassen), zal de replicatietaak de tabel opnieuw laden. Dit betekent in feite dat alle DML-bewerkingen die op de brontabellen worden uitgevoerd, naar het doel worden gerepliceerd voordat de taak stopt.
Voor initiële lading
Bij het verplaatsen van gegevens vanuit een SaaS-applicatiebron, kunt u instellen hoe de initiële volledige lading moet worden uitgevoerd:
| Cachegegevens gebruiken |
Met deze optie kunt u cachegegevens gebruiken die zijn gelezen toen metagegevens met Volledige gegevensscan werden geselecteerd. Dit zorgt voor minder overhead met betrekking tot API-gebruik en quota, in verhouding tot wanneer de gegevens al zijn gelezen vanuit de bron. Alle wijzigingen sinds de initiële gegevensscan kunnen worden opgepikt door Change data capture (CDC). |
| Gegevens laden vanuit bron |
Deze optie voert een nieuwe lading vanuit de gegevensbron uit. Deze optie is nuttig als:
|