
Impostazioni di replica
È possibile configurare le impostazioni per l'attività di replica dati.
-
Aprire l'attività di replica e fare clic su Impostazioni nella barra degli strumenti.
Viene visualizzata la finestra di dialogo Impostazioni: <Task-Name>. Le impostazioni disponibili sono descritte di seguito.
Generali
In questa scheda, è possibile modificare la modalità di replica, le impostazioni di staging (quando disponibili), la modalità di applicazione delle modifiche alla destinazione e le impostazioni di pubblicazione.
Modalità di replica
Sono disponibili le seguenti modalità di replica:
-
Caricamento completo: Carica i dati dalle tabelle di origine selezionate sulla piattaforma di destinazione e, se necessario, crea le tabelle di destinazione. Il caricamento completo viene eseguito automaticamente all'avvio dell'attività, ma può anche essere eseguito manualmente in caso di necessità. Il caricamento completo manuale è necessario, ad esempio, se bisogna replicare gli aggiornamenti delle Viste (che non vengono acquisiti durante le attività di CDC) o se si esegue la replica da una sorgente dati che non supporta le attività CDC.
Nota informaticaQuando si utilizza un connettore di applicazione SaaS, questa opzione sarà sempre abilitata poiché è richiesto il caricamento completo. -
Applica modifiche: mantiene le tabelle di destinazione aggiornate riportando qualsiasi modifica apportata alle tabelle di origine.
-
Archivia modifiche: Archivia le modifiche alle tabelle di origine nelle Tabelle di modifica (una per ogni tabella di origine).
Per ulteriori informazioni, vedere Salva modifiche.
Quando si utilizza il Gateway Data Movement, tranne quando si utilizzano sorgenti di applicazioni SaaS, le modifiche vengono acquisite dalla sorgente pressoché in tempo reale. Quando non si utilizza Gateway Data Movement (per esempio, con una Avvio Qlik Talend Cloud sottoscrizione o quando si seleziona Nessuno) o quando si utilizzano origini di applicazioni SaaS, le modifiche vengono acquisite in base alle impostazioni dell'utilità di pianificazione. Per ulteriori informazioni, vedere Scheduling tasks.
Se si seleziona Archivia modifiche o Applica modifiche, e la sorgente dati:
-
Non è un'applicazione SaaS
-
Contiene set di dati che supportano CDC e set di dati che supportano solo il caricamento completo (come le viste)
Due pipeline di dati verranno create. Una pipeline verrà creata per le tabelle che supportano la proprietà CDC, e un'altra pipeline verrà creata per i set di dati che supportano solo il Caricamento completo.
Metodo di caricamento
Quando si effettua la replica su Snowflake, è possibile scegliere uno dei seguenti metodi di caricamento:
-
Caricamento in blocco (impostazione predefinita)
Se si seleziona Caricamento in blocco, sarà possibile regolare i parametri di caricamento nella scheda Caricamento dati.
-
Snowpipe Streaming
Nota informaticaSnowpipe Streaming sarà disponibile per la selezione solo se sono soddisfatte le seguenti condizioni:
- La modalità di replica Archivia modifiche è abilitata senza Applica modifiche.
- Il Meccanismo di autenticazione nel connettore Snowflake è impostato su Coppia di chiavi.
- Se si utilizza Gateway Data Movement, è richiesta la versione 2024.11.45 o una successiva.
Se si seleziona Snowpipe Streaming, assicurarsi di comprendere le limitazioni e considerazioni quando si usa questo metodo. Inoltre, se si seleziona Snowpipe Streaming e poi si attiva la modalità di replica Applica le modifiche o si disattiva Archivia modifiche, il metodo di caricamento tornerà automaticamente a Caricamento in blocco.
Le ragioni principali per scegliereSnowpipe Streaming anziché Caricamento in blocco sono elencate di seguito:
-
Meno costoso: poiché Snowpipe Streaming non utilizza il warehouse di Snowflake, i costi operativi dovrebbero essere significativamente più bassi, anche se ciò dipenderà dal proprio caso d'uso specifico.
-
Latenza ridotta: poiché i dati vengono inviati in streaming direttamente alle tabelle di destinazione (anziché tramite lo staging), la replica dalla sorgente dati alla destinazione dovrebbe essere più veloce.
Connessione a un'area di staging
Quando si effettua la replica nei data warehouse elencati di seguito, è necessario impostare un'area di staging. I dati vengono elaborati e preparati nell'area di staging prima di essere trasferiti nel warehouse.
Selezionare un'area di staging o fare clic su Crea nuovo per definire una nuova area di staging, quindi seguire le istruzioni nella sezione Connessione a un'archiviazione cloud.
Per modificare le impostazioni della connessione, fare clic su Modifica. Per testare la connessione (procedura consigliata), fare clic su Prova connessione.
Per informazioni su quali aree di staging sono supportate con determinati data warehouse, vedere la colonna Supportata come area di staging inCasi d'uso della piattaforma di destinazione e versioni supportate.
Applica modalità di modifica
Le modifiche vengono applicate nelle tabelle di destinazione utilizzando uno dei metodi seguenti:
- Batch ottimizzato: è il batch predefinito. Quando questa opzione è selezionata, le modifiche vengono applicate in batch. Viene eseguita un'azione di pre-elaborazione per raggruppare le transazioni in batch nel modo più efficace.
- Transazionale: selezionare questa opzione per applicare ogni transazione individualmente, nell'ordine di esecuzione del relativo commit. In questo caso, una rigida integrità referenziale è garantita per tutte le tabelle.
Impostazioni di pubblicazione
-
Pubblica nel catalogo
Selezionare questa opzione per pubblicare questa versione dei dati nel Catalogo come un set di dati. Il contenuto del Catalogo verrà aggiornato la volta successiva che si prepara l'attività.
Per ulteriori informazioni sul Catalogo, vedere Informazioni sui dati con gli strumenti del catalogo.
Impostazioni proxy quando si utilizza Gateway Data Movement
-
Quando si utilizza Data Movement gateway, connettersi tramite proxy a
Quando si utilizza Gateway Data Movement, è possibile connettersi alla piattaforma di destinazione e alla piattaforma di staging (area) tramite un proxy.
Per maggiori informazioni sulla configurazione di Gateway Data Movement per fare in modo che utilizzi un server proxy, vedere Impostazione del tenant Qlik Cloud e di un server proxy.
-
Piattaforma di destinazione
Nota informaticaDisponibile quando si utilizzano Snowflake e Databricks. -
Piattaforma di staging
Nota informaticaDisponibile quando si utilizzano Google BigQuery, Amazon Redshift, Microsoft Fabric e Databricks.
-
Caricamento dati
Questa scheda verrà visualizzata solo quando si effettua la replica in una destinazione del data warehouse o Kafka. Inoltre, le impostazioni in questa scheda differiranno in base alla destinazione selezionata.
Rilevante per tutte le destinazioni di data warehouse
Dimensione massima del file
Le dimensioni massime che può raggiungere un file prima che venga chiuso. I file di dimensioni inferiori possono essere caricati più velocemente (dipendendo dalla rete) e migliorare le prestazioni quando sono utilizzati insieme all'opzione di esecuzione parallela. Tuttavia, in generale si considera una cattiva prassi ingombrare il database con file di piccole dimensioni.
Rilevante solo per la destinazione Snowflake
Nella scheda Generale, è possibile scegliere se caricare i dati su Snowflake utilizzando il Caricamento in blocco o Snowpipe Streaming. Quando è selezionata l'opzione Snowpipe Streaming, la scheda Caricamento dati non verrà visualizzata. Quando è selezionata l'opzione Caricamento in blocco, saranno disponibili le seguenti impostazioni:
-
Dimensione massima del file (MB): Rilevante per il carico completo iniziale e il CDC. Le dimensioni massime che può raggiungere un file prima che venga caricato nella destinazione. Se si riscontrano problemi di prestazioni, provare a regolare il parametro.
-
Numero di file da caricare in un batch: Rilevante solo per il Full Load iniziale. Il numero di file da caricare in un singolo batch. Se si riscontrano problemi di prestazioni, provare a regolare il parametro.
Per una descrizione dei metodi di caricamento Caricamento in blocco e Snowpipe Streaming , consultare Generali.
Rilevante solo per la destinazione Kafka
Proprietà messaggio
Compressione
Selezionare facoltativamente uno dei metodi di compressione disponibili (Snappy o Gzip). Il valore predefinito è Nessuna.
Pubblicazione messaggi dati
Scegliere una delle seguenti Pubblica i dati in opzioni:
- Argomento specifico: Pubblica i dati su un singolo argomento. Digitare un nome di argomento o utilizzare il pulsante Sfoglia per selezionare l'argomento desiderato.
-
Argomento separato per ogni tabella: Pubblica i dati su più argomenti corrispondenti ai nomi delle tabelle di origine.
Il nome topic di destinazione è costituito dal nome dello schema di origine e dal nome della tabella di origine, separati da un punto (ad esempio, dbo.Employees). Il formato del nome topic di destinazione è importante in quanto dovrai preparare questi topic in anticipo.
Se gli argomenti non esistono, configurare i broker con auto.create.topics.enable=true per consentire all'attività di dati di creare gli argomenti durante il runtime. In caso contrario, l'attività non verrà completata.
Per informazioni sulla sovrascrittura di questa impostazione a livello di set di dati, vedere Sostituzione delle impostazioni dell'attività per singoli set di dati durante la pubblicazione in Kafka
Chiave messaggio
Selezionare una delle opzioni disponibili.
-
Colonne chiave primaria: Per ogni messaggio, la chiave del messaggio conterrà il valore della colonna chiave primaria.
Quando Per chiave messaggio è selezionata come strategia di partizionamento, i messaggi costituiti dallo stesso valore di chiave primaria verranno scritti nella stessa partizione.
-
Nome schema e tabella: Per ogni messaggio, la chiave del messaggio conterrà una combinazione di nome schema e tabella (ad esempio, dbo+Employees).
Quando Per chiave messaggio è selezionata come strategia di partizionamento, i messaggi costituiti dallo stesso nome schema e tabella verranno scritti nella stessa partizione.
- Nessuno: Crea messaggi senza una chiave del messaggio.
Per informazioni sulla sovrascrittura di questa impostazione a livello di set di dati, vedere Sostituzione delle impostazioni dell'attività per singoli set di dati durante la pubblicazione in Kafka
Strategia di partizione
Selezionare Casuale o Per chiave del messaggio. Se si seleziona Casuale, ogni messaggio verrà scritto in una partizione selezionata casualmente. Se si seleziona Per chiave del messaggio, i messaggi verranno scritti nelle partizioni in base alla Chiave del messaggio selezionata (descritta sopra).
Pubblicazione messaggi metadati
Strategia nome soggetto
La prima strategia (Nome schema e tabella) è una strategia proprietaria Qlik mentre le altre tre sono strategie standard di denominazione del soggetto Confluent.
Selezionare una delle strategie di denominazione del soggetto disponibili.
- Nome schema e tabella (predefinito)
- Nome argomento
- Registra nome
- Nome argomento e record
Per maggiori informazioni sulle strategie di denominazione dei soggetti di Confluent, vedi Strategia di denominazione dei soggetti
Modalità di compatibilità soggetto
Seleziona una delle seguenti modalità di compatibilità dall'elenco a discesa Modalità di compatibilità del soggetto:
-
Usa le impostazioni predefinite del Registry schema: Recupera il livello di compatibilità dalla configurazione del server del Registry schema.
-
Retrocompatibile - Solo l'ultimo schema: I nuovi schemi possono leggere i dati corrispondenti e i dati prodotti solo dall'ultimo schema registrato.
-
Transitivo all'indietro - Tutti gli schemi precedenti: I nuovi schemi possono leggere i dati prodotti da tutti gli schemi registrati in precedenza.
-
In avanti - Solo schema più recente: L'ultimo schema registrato può leggere i dati prodotti dal nuovo schema.
-
Transitivo in avanti - Tutti gli schemi precedenti: Tutti gli schemi registrati in precedenza possono leggere i dati prodotti dal nuovo schema.
-
Completo - Solo l'ultimo schema: Il nuovo schema è compatibile all'indietro e in avanti con l'ultimo schema registrato.
-
Completamente transitivo - Tutti gli schemi precedenti: Il nuovo schema è compatibile all'indietro e in avanti con tutti gli schemi precedentemente registrati.
-
Nessuno
- A seconda della strategia di denominazione del soggetto selezionata, alcune delle modalità di compatibilità potrebbero non essere disponibili.
-
Quando si pubblicano messaggi in un Registro schemi, la modalità di compatibilità del soggetto predefinita per tutti i soggetti della tabella di controllo appena creati sarà Nessuno, indipendentemente dalla modalità di compatibilità del soggetto selezionata.
Se si desidera che la modalità di compatibilità del soggetto selezionata si applichi anche alle tabelle di controllo, impostare il parametro interno setNonCompatibilityForControlTables nel connettore di destinazione Kafka su false.
Usa un proxy per connetterti a Confluent Schema Registry
Questa opzione è supportata solo durante la pubblicazione nel Confluent Schema Registry.
Attiva se il tuo Gateway Data Movement è configurato per usare un server proxy.
Attributi messaggio
È possibile specificare attributi di messaggio personalizzati che sovrascriveranno gli attributi di messaggio predefiniti. Ciò è utile se l'applicazione consumer deve elaborare il messaggio in un formato particolare.
Gli attributi di messaggio personalizzati possono essere definiti sia a livello di attività che a livello di tabella. Quando gli attributi sono definiti sia a livello di attività che a livello di tabella, gli attributi di messaggio definiti per la tabella avranno la precedenza su quelli definiti per l'attività.
Per informazioni sulla sovrascrittura degli attributi del messaggio a livello di set di dati, vedere Sostituzione delle impostazioni dell'attività per singoli set di dati durante la pubblicazione in Kafka
I messaggi strutturati gerarchicamente non sono supportati.
Regole generali e linee guida per l'utilizzo
Quando si definisce un messaggio personalizzato, è importante considerare le regole e le linee guida per l'utilizzo elencate di seguito.
Nomi delle sezioni
Si applicano le seguenti regole di denominazione:
- I nomi delle sezioni devono iniziare con i caratteri a-z, A-Z o _ (un underscore) e possono quindi essere seguiti da uno qualsiasi dei seguenti caratteri: a-z, A-Z, 0-9, _
- Ad eccezione delle Nome record e sezioni Nome chiave (che non terminano con una barra), la rimozione della barra dai nomi delle sezioni appiattirà la gerarchia della sezione associata (vedi Barre di seguito).
- Tutti i nomi delle sezioni eccetto Nome record e Nome chiave possono essere eliminati (vedi Eliminazione di seguito)
-
I nomi delle sezioni Nome dati e Includi record Prima dei dati non possono essere eliminati entrambi
-
I nomi di sezione Nome Data e Includi record Prima-data non possono essere uguali.
Alcuni dei nomi di sezione nell'interfaccia utente terminano con una barra (ad es. beforeData/beforeData/). Lo scopo della barra è mantenere una gerarchia delle diverse sezioni all'interno del messaggio. Se la barra viene rimossa, si verificherà quanto segue:
- La struttura gerarchica di quella sezione verrà appiattita, con la conseguente rimozione del nome della sezione dal messaggio
- Il nome della sezione verrà anteposto ai metadati effettivi, direttamente o utilizzando un carattere separatore (ad esempio un trattino basso) che hai aggiunto al nome
Esempio di messaggio di dati quando headers/ è specificato con una barra:
"message":{
"data":{
"COL1": "159",
"COL2": "159"
},
"beforeData": null,
"headers": {
"operation": "INSERT",
"changeSequence": "2018100811484900000000233",
Esempio di messaggio di dati quando headers_ è specificato con un trattino basso invece di una barra:
"message":{
"data":{
"COL1": "159",
"COL2": "159"
},
"beforeData": null,
"headers_operation": "INSERT",
"headers_changeSequence": "2018100811484900000000233",
L'eliminazione di un nome di sezione dal messaggio appiattirà la struttura gerarchica di quella sezione. Ciò comporterà che tutti i dati di quella sezione appaiano immediatamente sotto il contenuto della sezione precedente.
Esempio di messaggio di dati con il headers nome della sezione:
"message":{
"data":{
"COL1": "159",
"COL2": "159"
},
"headers": {
"operation": "INSERT",
"changeSequence": "2018100811484900000000233",
Esempio di messaggio di dati senza il headers nome della sezione:
"message":{
"data":{
"COL1": "159",
"COL2": "159"
},
"beforeData": null,
"operation": "INSERT",
"changeSequence": "2018100811484900000000233",
Variabili
È possibile aggiungere variabili ai nomi facendo clic sul ![]() pulsante alla fine della riga. Le seguenti variabili sono disponibili:
pulsante alla fine della riga. Le seguenti variabili sono disponibili:
- SERVER_NAME - Il nome host del Gateway Data Movement server
- TARGET_TABLE_NAME - Il nome della tabella
- TARGET_TABLE_OWNER - Il proprietario della tabella
- TASK_NAME - Il nome dell'attività dati
La variabile TARGET_TABLE_OWNER non è disponibile per le opzioni Nome record e Nome chiave (descritte nella tabella seguente).
Definizione di attributi di messaggio personalizzati
Per definire un formato di messaggio personalizzato, attivare Usa impostazioni personalizzate e configurare le opzioni come descritto nella tabella seguente.
Per ripristinare gli attributi di messaggio predefiniti, disattivare Usa impostazioni personalizzate.
| Opzione | Descrizione |
|---|---|
|
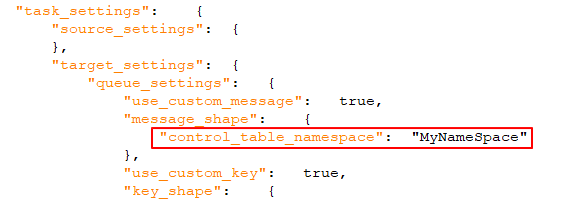
Quando attivato (l'impostazione predefinita), un identificatore univoco sarà incluso nel messaggio. Questa dovrebbe essere una stringa, separata da punti. Si noti che lo spazio dei nomi verrà incluso sia nel messaggio che nella chiave del messaggio. Esempio: mycompany.queue.msg Nome predefinito: com.attunity.queue.msg.{{NOME_ATTIVITÀ}}.{{TARGET_TABLE_OWNER}}.{{TARGET_TABLE_NAME}} Nome predefinito per le tabelle di controllo: com.attunity.queue.msg.{{TARGET_TABLE_NAME}} Nota informatica
Lo spazio dei nomi predefinito della tabella di controllo non può essere modificato tramite l'interfaccia utente. È possibile, tuttavia, modificare lo spazio dei nomi predefinito della tabella di controllo come segue:
|
|
|
Registra nome |
Il nome del record (messaggio). Nome predefinito: Record di dati |
|
Nome dati |
Tutte le colonne di dati incluse nel record. Nome predefinito: dati/ |
|
Includi intestazioni |
Quando attivato (impostazione predefinita), le colonne di intestazione saranno incluse nel messaggio. Le colonne di intestazione forniscono informazioni aggiuntive sulle operazioni di origine. Per maggiori informazioni, vedi Includi le seguenti intestazioni di seguito. |
|
Includi spazio dei nomi intestazioni |
Quando attivato (l'impostazione predefinita), un identificatore univoco per la sezione delle colonne di intestazione sarà incluso nel messaggio. Questa dovrebbe essere una stringa, separata da punti. Esempio: intestazioni.coda.msg Nome predefinito: com.attunity.queue.msg |
|
Nome intestazioni |
Il nome della sezione contenente le Qlik intestazioni di colonna. Nome predefinito: intestazioni/ |
|
Per una descrizione delle colonne di intestazione disponibili, fare riferimento a Messaggi di dati nella Guida di Qlik. Impostazioni predefinite: Tutte le colonne sono incluse per impostazione predefinita, eccetto la colonna ID schema esterno. |
|
|
Includi record prima dei dati |
Quando attivato (l'impostazione predefinita), sia i dati pre che post UPDATE saranno inclusi nei messaggi UPDATE. Per includere solo i dati post UPDATE nei messaggi, disattiva l'opzione. Nome predefinito: beforeData/ |
|
Nome chiave |
Il nome della sezione contenente la chiave del messaggio. Nome predefinito: keyRecord Questa opzione è applicabile solo quando:
|
Impostazioni aggiuntive
-
Dimensione massima messaggio
Nel campo Dimensione massima messaggio , specificare la dimensione massima dei messaggi che i broker sono configurati per ricevere (message.max.bytes). L'attività di dati non invierà messaggi di dimensioni superiori alla dimensione massima.
Metadati
Base
-
Schema tabella di destinazione
Lo schema nella destinazione in base al quale le tabelle di origine verranno replicate se non si desidera utilizzare lo schema della tabella di origine (o se non è presente nessuno schema nel database di origine).
Nota informaticaQuando si utilizza la replica per una destinazione Oracle, lo schema della tabella di destinazione predefinita è "system". Notare anche che se si lascia questo campo vuoto (nel quale caso verrà utilizzato lo schema di origine), è necessario assicurarsi che lo schema di origine esiste già nella destinazione. In caso contrario, l'attività non verrà completata.Nota informaticaLa lunghezza massima consentita per il nome dello schema è di 128 caratteri.
Mappatura colonna JSON
Mappare le colonne JSON compatibili dell'origine alle colonne JSON della destinazione.
-
Se si utilizza Gateway Data Movement per accedere alla sorgente dati, è richiesta la versione 2024.11.70 o successive.
Quando questa opzione è selezionata, le colonne JSON sull'origine verranno mappate automaticamente alle colonne JSON sulla destinazione.
Lo stato e la visibilità di questa opzione sono determinati dai seguenti fattori:
-
Nuove attività: Questa opzione sarà abilitata per impostazione predefinita se sia la sorgente che la destinazione supportano il tipo di dati JSON.
-
Attività esistenti: Questa opzione sarà disabilitata per impostazione predefinita, anche se sia la sorgente che la destinazione supportano il tipo di dati JSON. Questo per preservare la compatibilità con i processi a valle, come le trasformazioni, che prevedono che i dati di destinazione siano in formato STRING (che è il comportamento legacy). È possibile lasciare l'opzione disattivata o modificare i processi a valle per renderli compatibili con il formato JSON e quindi attivare questa opzione.
-
Attività nuove ed esistenti: Se solo la sorgente supporta il tipo di dati JSON, questa opzione non sarà visibile. Se il supporto JSON viene aggiunto alla destinazione in una fase successiva, l'opzione diventerà visibile ma rimarrà disabilitata. Questo per preservare la compatibilità con i processi a valle, come le trasformazioni, che prevedono che i dati di destinazione siano in formato STRING (che è il comportamento legacy).
Impostazioni delle colonne LOB
Le impostazioni disponibili per le colonne LOB differiscono in base alla destinazione selezionata per la replica. Poiché le destinazioni del data warehouse non supportano colonne LOB di dimensioni illimitate, questa opzione non sarà disponibile quando si effettua la replica su un data warehouse.
Impostazioni delle LOB per le destinazioni che non sono dei data warehouse
- Non includere colonne LOB: selezionare questa opzione se non si desidera che le colonne LOB di origine vengano replicate.
-
Limita dimensione colonna LOB a (KB): questa è l'opzione predefinita. Selezionare questa opzione se è necessario replicare solo un numero ridotto di LOB o se la piattaforma di destinazione non supporta dimensioni illimitate per le LOB. Il valore massimo consentito per questo campo è 102.400 KB (100 MB).
Quando si replica un numero ridotto di LOB, questa opzione è più efficiente di Consenti dimensioni LOB illimitate, poiché le LOB vengono replicate "inline" anziché tramite un'operazione di "lookup" dalla sorgente. Durante l'elaborazione delle modifiche, le LOB di piccole dimensioni di solito vengono effettuare la replica tramite un'operazione di "lookup" dalla sorgente.
Il limite si applica al numero di byte della LOB letti dall'endpoint di origine. Per le colonne BLOB, la dimensione BLOB di destinazione sarà esattamente conforme al limite specificato. Per le colonne CLOB ed NCLOB, la dimensione LOB di destinazione potrebbe differire dal limite specificato se la tabella LOB di origine e quella di destinazione non hanno lo stesso set di caratteri. In questo caso, l'attività dati eseguirà la conversione del set di caratteri, il che potrebbe causare una discrepanza tra le dimensioni della LOB di origine e quella di destinazione.
Poiché il valore limite per le dimensioni delle LOB è espresso in byte, queste devono essere calcolate utilizzando le formule elencate di seguito.
- BLOB: la lunghezza della LOB più grande.
- NCLOB: la lunghezza di TEXT (testo) più lunga in caratteri moltiplicata per due (poiché ogni carattere viene gestito da due byte). Se i dati includono caratteri di 4 byte, è necessario moltiplicare il numero per quattro.
- CLOB: la lunghezza di TEXT (testo) più lunga in caratteri (poiché ogni carattere viene gestito come un carattere UTF8). Se i dati includono caratteri di 4 byte, è necessario moltiplicare il numero per due.
Nota informatica- Qualsiasi LOB le cui dimensioni superino quelle specificate verrà troncata.
- Durante l'elaborazione delle modifiche da una sorgente Oracle, le BLOB inline vengono replicate inline.
- Le modifiche a questa impostazione verranno applicate alle tabelle esistenti solo dopo il loro ricaricamento.
-
Non limitare le dimensioni delle colonne LOB: Quando questa opzione è selezionata, le colonne LOB verranno replicate, indipendentemente dalle dimensioni.
Nota informaticaLa replica delle colonne LOB può avere un impatto sulle prestazioni. Questo vale in particolare nel caso di colonne LOB di grandi dimensioni, per le quali l'attività deve eseguire un'operazione di ricerca dalla tabella di origine per recuperare il valore LOB di origine.-
Ottimizza quando la dimensione LOB è inferiore a: Selezionare questa opzione quando è necessario replicare LOB di piccole e grandi dimensioni, e la maggior parte degli LOB è di piccole dimensioni.
Nota informaticaQuesta opzione è supportata solo con le destinazioni e sorgenti descritte di seguito.
-
Origini: Oracle, Microsoft SQL server, MySQL, PostgreSQL e IBM DB2 per LUW
-
Destinazioni: Oracle, Microsoft SQL Server, MySQL, PostgreSQL.
Quando questa opzione è selezionata, durante il caricamento completo, le LOB di piccole dimensioni verranno replicate "inline" (un processo più efficiente), mentre le LOB di grandi dimensioni verranno replicate eseguendo una ricerca (lookup) nella tabella di origine. Durante l'elaborazione delle modifiche, tuttavia, le LOB sia di piccole che di grandi dimensioni verranno replicate eseguendo una ricerca dalla tabella di origine.
Nota informaticaQuando questa opzione è selezionata, l'attività di replica verificherà le dimensioni di tutte le LOB per determinare quelle da trasferire "inline". Le LOB con dimensioni maggiori di quelle specificate verranno effettuare la replica utilizzando la modalità LOB completa.
Pertanto, se si sa che la maggior parte delle LOB hanno dimensioni maggiori dell'impostazione specificata, è preferibile utilizzare invece l'opzione Replicate colonne LOB illimitate.
-
-
Dimensione blocco (KB): facoltativamente, modificare le dimensioni dei blocchi LOB per utilizzare quando si effettua la replica dei dati nella destinazione. Le dimensioni predefinite dei blocchi dovrebbero essere sufficienti nella maggior parte dei casi, ma se si rilevano problemi nelle prestazioni, regolare le dimensioni potrebbe aiutare a migliorarle.
Nota informaticaCon alcuni database, la convalida del tipo di dati viene completata quando i dati vengono inseriti o aggiornati. In questi casi, replica di tipi di dati strutturati (ad es. XML, JSON, GEOGRAPHY, ecc.) potrebbe non riuscire se le dimensioni dei dati sono maggiori delle dimensioni del blocco specificate.
-
Impostazioni delle colonne LOB per le destinazioni supportate per i data warehouse
-
Includi colonne LOB e limita dimensione della colonna a (KB):
È possibile scegliere di includere le colonne LOB nell'attività e di impostare le dimensioni massime delle LOB. Le LOB di dimensioni maggiori rispetto alla dimensione massima verranno troncate.
Avanzate
Impostazioni tabella di controllo
-
Schema tabelle di controllo: Specificare lo schema di destinazione per le tabelle di controllo se non si desidera che vengano create nello schema di origine (l'opzione predefinita) o nello schema di destinazione.
Nota informaticaLa lunghezza massima consentita per il nome dello schema è di 128 caratteri. - Crea tabelle di controllo di destinazione nello spazio tabelle: Quando la destinazione della replica è Oracle, specificare lo spazio tabelle dove si desidera creare le tabelle di controllo di destinazione. Se non si inserisce alcuna informazione in questo campo, le tabelle verranno create nello spazio tabelle predefinito nel database di destinazione.
- Crea indici per le tabelle di controllo di destinazione nello spazio tabelleQuando la destinazione della replica è Oracle, specificare lo spazio tabelle dove si desidera creare gli indici delle tabelle di controllo. Se non si inserisce alcuna informazione in questo campo, gli indici verranno creati nello stesso spazio tabelle delle tabelle di controllo.:
- Timeslot cronologia replica (minuti): la durata di ogni slot temporale nella tabella di controllo Cronologia replica. Il valore predefinito è 5 minuti.
Selezione della tabella di controllo
Selezionare le tabelle di controllo che si desidera che vengano create nella piattaforma di destinazione:
| Nome logico | Nome in destinazione |
|---|---|
| Applica eccezioni | attrep_app_eccezioni |
| Stato replica | attrep_stato |
| Tabelle sospese | attrep_tabelle_sospese |
| Cronologia replica | attrep_rendiconto |
| Cronologia DDL |
attrep_ddl_history La tabella Cronologia DDL è supportata solo dalle seguenti piattaforme di destinazione:
|
Per maggiori informazioni sulle tabelle di controllo, vedere Tabelle di controllo.
Caricamento completo
Base
Queste impostazioni verranno applicate durante la fase di preparazione dell'attività dati e ogni volta che una tabella viene ricaricata.
Se la tabella di destinazione esiste già: selezionare una delle seguenti opzioni per determinare la modalità di caricamento dei dati nelle tabelle di destinazione:
L'opzione che consente di ignorare o troncare le tabelle di destinazione è rilevante solo se tali operazioni sono supportate dall'endpoint di origine.
-
Elimina e crea tabella: la tabella di destinazione viene eliminata e al suo posto viene creata una nuova tabella.
Nota informaticaLe tabelle di controllo per le attività di replica non verranno eliminate. Tuttavia, qualsiasi tabella sospesa che viene eliminata sarà rimossa anche dalla Tabella di controllo attrep_suspended_tables se l'attività associata viene ricaricata.
-
TRUNCATE prima del caricamento: i dati vengono troncati senza modificare i metadati della tabella di destinazione. Notare che quando questa opzione è selezionata, l'abilitazione dell'opzione Crea chiave primaria o indice univoco una volta completato il caricamento completo non avrà alcun effetto.
Nota informaticaLa funzionalità non è supportata se la piattaforma di destinazione è Microsoft Fabric. - Ignora: i dati e metadati esistenti della tabella di destinazione non verranno modificati. I nuovi dati verranno aggiunti alla tabella.
Avanzate
Regolazione prestazioni
Se la replica dati è eccessivamente lenta, la regolazione dei seguenti parametri può migliorare le prestazioni.
- Numero massimo di tabelle: inserire il numero massimo di tabelle da caricare in una volta nella destinazione. Il valore predefinito è 5.
-
Timeout coerenza transazione (secondi): inserire il numero di secondi che l'attività di replica deve attendere prima di chiudere le transazioni aperte, prima di avviare l'operazione Caricamento completo. Il valore predefinito è 600 (10 minuti). L'attività di replica avvierà il caricamento completo una volta che viene raggiunto il valore di timeout, anche se vi sono transazioni aperte.
Nota informaticaPer replicare le transazioni aperte all'avvio di Caricamento completo ma che sono state applicate solo dopo che è stato raggiunto il valore di timeout, è necessario ricaricare le tabelle di destinazione. - Frequenza di commit durante il caricamento completo: il numero massimo di eventi che è possibile trasferire insieme. Il valore predefinito è 10000.
Dopo il completamento del caricamento completo
È possibile impostare l'attività in modo che si interrompa automaticamente una volta completato il Caricamento completo. Questa opzione è utile se bisogna eseguire le operazioni DBA sulle tabelle di destinazione prima che inizi la fase Applica modifiche (ossia Inizia la fase CDC).
Durante il Caricamento completo, qualsiasi operazione DML eseguita nelle tabelle di origine è salvata nella cache. Una volta completato il Caricamento completo, le modifiche salvate nella cache vengono applicate automaticamente alle tabelle di destinazione (a condizione che le opzioni Prima/Dopo l'applicazione delle modifiche nella cache descritte di seguito non siano selezionate).
-
Crea chiave primaria o indice univoco: Selezionare questa opzione se si desidera ritardare la creazione della chiave primaria o dell'indice univoco sulla destinazione fino al completamento del caricamento completo.
Nota informaticaQuesta impostazione non è disponibile per le attività che utilizzano un connettore di applicazione SaaS. - Arresta attività:
Nota informatica
Queste impostazioni non sono disponibili quando si effettua la replica sulle destinazioni di data warehouse
Prima che le modifiche memorizzate nella cache vengano applicate: selezionare questa opzione per arrestare l'attività una volta completato il Caricamento completo.
Dopo l'applicazione delle modifiche memorizzate nella cache: selezionare questa opzione per interrompere l'attività non appena i dati sono coerenti in tutte le tabelle dell'attività.
Nota informaticaQuando si configura l'attività in modo che si interrompa una volta completato il Caricamento completo, tenere presente quanto segue:
- L'attività non si interrompe nel momento in cui viene completato il Caricamento completo. Verrà interrotta solo dopo l'acquisizione dell primo batch di modifiche (poiché proprio questa azione fa in modo che l'attività si interrompa). Questa operazione potrebbe richiedere tempo, a seconda della frequenza con cui il database di origine viene aggiornato. Una volta che l'attività si interrompe, le modifiche non verranno applicate fino a quando quest'ultima non viene ripresa.
- La selezione di Prima dell'applicazione delle modifiche nella cache può avere un impatto sulle prestazioni, poiché le modifiche nella cache verranno applicate solo alle tabelle (anche quelle che hanno già completato il caricamento completo) dopo che l'ultima tabella completa il Caricamento completo.
- Quando questa opzione è selezionata e viene eseguita un'istruzione DDL in una delle tabelle di origine durante il processo di caricamento completo (in un'attività Caricamento completo e Applica modifiche), l'attività di replica ricaricherà la tabella. Ciò significa che qualsiasi operazione DML eseguita nelle tabelle di origine verrà replicata nella destinazione prima dell'interruzione dell'attività.
Per il caricamento iniziale
| Usa dati in cache |
Quest'opzione consente di utilizzare i dati in cache letti quando si generano metadati con l'opzione Scansione dati completa selezionata. Ciò garantisce un minor tempo di overhead per quanto concerne le quote e l'utilizzo di API, visto che i dati vengono già letti dalla sorgente. Qualsiasi modifica successiva alla scansione dati iniziale può essere rilevata da Change Data Capture (CDC). |
| Carica dati dalla sorgente |
Quest'opzione esegue un nuovo caricamento dalla sorgente dati. Quest'opzione è utile se:
|
Applica le modifiche
Queste impostazioni sono disponibili quando la modalità Archivia modifiche è abilitata.
Base
Seleziona il tipo di modifiche DDL da applicare alla destinazione
Le opzioni determinano se le operazioni DDL eseguite nella tabella di origine corrispondente verranno eseguite anche nella tabella di destinazione.
-
Elimina tabella: Selezionare di eliminare la tabella di destinazione quando viene eliminata la tabella di origine.
Nota informaticaLa funzionalità non è supportata se la piattaforma di destinazione è Kafka. -
Tronca tabella: selezionare di troncare la tabella di destinazione quando la tabella di origine viene troncata.
Nota informaticaLa funzionalità non è supportata se la piattaforma di destinazione è Microsoft Fabric. -
Modifica tabella: Selezionare per modificare la tabella di destinazione quando la tabella di origine viene modificata.
Nota informaticaLa ridenominazione di una tabella non è supportata quando Kafka è la piattaforma di destinazione.
Regolazione di elaborazione delle modifiche
-
Applica modifiche in lotti a più tabelle simultaneamente: la selezione di questa opzione potrebbe migliorare le prestazioni quando si applicano le modifiche da più tabelle di origine.
Nota informaticaQuesta opzione è supportata solo nei seguenti casi:
- L'opzioneModalità di applicazione modifiche è impostata su Batch ottimizzato. Per ulteriori informazioni, vedere Impostazioni di replica.
- Le destinazioni della replica non sono MySQL, PostgreSQL, Oracle e Google BigQuery.
-
Numero massimo di tabelle: Il numero massimo di tabelle a cui applicare contemporaneamente le modifiche in batch. Il numero predefinito è cinque, il massimo è 50, mentre il minimo è due.
Quando l'opzione Applica modifiche in batch a più tabelle simultaneamente è abilitata, si applicano le seguenti limitazioni:
-
Le impostazioni predefinite della politica di gestione degli errori nelle attività rimarrà invariata per gli errori Ambientale e Tabella, ma le impostazioni predefinite per gli errori nei Dati e Applica conflitti saranno i seguenti:
- Errori dati:
- Errori di troncamento dei dati: Registra record nella tabella delle eccezioni
- Altri errori di dati: Sospendi tabella
- Errori conflitti di applicazione:
- Elimina: ignora record
Inserimenti: Aggiorna il record di destinazione esistente con UPDATE
Nota informaticaQuesta opzione non è rilevante per una destinazione Snowflake (poiché Snowflake non supporta le chiavi primarie).- Aggiornamenti: ignora record
- Azione di riassegnazione:
- L'Azione di riassegnazione per gli errori nei Dati e Applica conflitti non è supportata.
- la Tabella di controllo attrep_apply_exception non è supportata.
- Per gli errori nei dati:
- l'opzione Registra record nella tabella delle eccezioni è disponibile solo per gli errori di troncamento dei dati.
- L'opzione Ignora non è disponibile.
- Per i conflitti di applicazione:
- l'opzione Registra record nella tabella delle eccezioni non è disponibile.
L'opzione Ignora è disponibile solo per Nessun record trovato per l'applicazione di un UPDATE il conflitto di applicazione.
- Errori dati:
Vedere anche: Gestione errori.
-
-
Limitare il numero di modifiche applicate per istruzione di elaborazione delle modifiche a: per limitare il numero di modifiche applicate per ogni singola istruzione di elaborazione delle modifiche, selezionare questa casella, quindi, facoltativamente, modificare il valore predefinito. Il valore predefinito è 10,000.
Nota informaticaQuesta opzione è supportata solo con le seguenti destinazioni: MySQL, PostgreSQL, Oracle e Google BigQuery.
Avanzate
Vedere Regolazione di elaborazione delle modifiche.
Salva modifiche
Queste impostazioni sono disponibili quando è selezionata la modalità di replica Archivia modifiche.
Base
Opzioni DDL
Selezionare una delle seguenti opzioni per determinare la modalità di gestione delle operazioni DDL nelle tabelle di origine:
- Applica a tabella di modifica: le operazioni DDL nelle tabelle di origine (ad esempio una colonna che viene aggiunta) verranno applicate solo alle tabelle di modifica corrispondenti.
- Ignora: tutte le operazioni DDL nelle tabelle di origine verranno ignorate.
Avanzate
All'aggiornamento
Selezionare Archivia immagine prima e dopo per archiviare i dati prima e dopo l'operazione di UPDATE. Quando questa opzione non è selezionata, verranno archiviati solo i dati successivi all'operazione di UPDATE.
Creazione di una tabella di modifica
La sezione seguente descrive le opzioni che sono disponibili quando si archiviano le modifiche nelle Tabelle delle modifiche.
- Suffisso: consente di specificare una stringa da utilizzare come suffisso per tutte le Tabelle delle modifiche. Il valore predefinito è __ct. I nomi della Tabella delle modifiche sono il nome della tabella di destinazione con il suffisso aggiunto. Quindi, per esempio, se si utilizza il valore predefinito, il nome della Tabella delle modifiche sarà HR__ct.
- Prefisso colonna intestazione: consente di specificare una stringa da utilizzare come prefisso per tutte le colonne di intestazione delle Tabelle delle modifiche. Il valore predefinito è header__. Per esempio, quando si utilizza il valore predefinito, la colonna di intestazione stream_position sarà denominata header__stream_position.
Per maggiori informazioni sulle Tabelle delle modifiche, vedere Utilizzo delle tabelle di modifica.
Se la tabella di modifica esiste quando viene avviato il caricamento completo: selezionare una delle opzioni elencate descritte di seguito per determinare come caricare le tabelle di modifica quando viene avviata la replica Caricamento completo.
- Elimina e crea tabella delle modifiche: la tabella viene eliminata e al suo posto viene creata una nuova tabella.
-
Elimina modifiche anteriori e archivia le nuove modifiche nella tabella di modifica esistente: i dati vengono troncati e aggiunti senza alterare i metadati della tabella.
Nota informaticaLa funzionalità non è supportata se la piattaforma di destinazione è Microsoft Fabric. - Mantieni vecchie modifiche e archivia nuove modifiche in una tabella di modifica esistente: i dati e i metadati della Tabella delle modifiche esistente non vengono modificati.
Colonne di intestazione tabella
Le colonne di intestazione della Tabella di modifica forniscono informazioni sulle operazioni di Elaborazione modifica operazione come il tipo operazione (ad es. INSERT), l'ora in cui è stato eseguito il commit, e così via. Se tali informazioni non sono necessarie, è possibile configurare l'attività di spostamento per creare le tabelle di modifica con le colonne di intestazione selezionate (o nessuna), pertanto l'ingombro di memoria nel database di destinazione.
Per una descrizione delle colonne di intestazione, vedere Tabelle di modifica.
Gestione errori
Base
Conflitti di applicazione
Chiave duplicata durante l'applicazione di INSERT: selezionare l'azione da eseguire quando si verifica un conflitto con un'operazione INSERT.
-
Ignora: l'attività continua e l'errore viene ignorato.
-
Aggiorna il record di destinazione esistente con UPDATE: viene aggiornato il record di destinazione con la stessa chiave primaria del record di origine inserito con operazione INSERT.
- Registra record nella tabella delle eccezioni (opzione predefinita): l'attività continua e l'errore viene scritto nella tabella delle eccezioni.
-
Sospendi tabella: l'attività continua, ma i dati dalla tabella con il record dell'errore passano a uno stato di errore e i dati correlati non vengono replicati.
- Interrompi attività: l'attività viene interrotta ed è richiesto l'intervento manuale.
Nessun record trovato per l'applicazione di un UPDATE: Selezionare l'azione da intraprendere quando si verifica un conflitto con un'operazione di UPDATE.
- Ignora: l'attività continua e l'errore viene ignorato.
-
Inserisci il record di destinazione mancante con INSERT: il record di destinazione mancante verrà inserito nella tabella di destinazione. Quando l'endpoint di origine è Oracle, la selezione di questa opzione richiede un accesso supplementare per poter accedere a tutte le colonne della tabella di origine.
- Registra record nella tabella delle eccezioni (opzione predefinita): l'attività continua e l'errore viene scritto nella tabella delle eccezioni.
-
Sospendi tabella: l'attività continua, ma i dati dalla tabella con il record dell'errore passano a uno stato di errore e i dati correlati non vengono replicati.
- Interrompi attività: l'attività viene interrotta ed è richiesto l'intervento manuale.
Avanzate
La gestione degli errori di dati è supportata solo nella modalità di replica Applica modifiche (non con Caricamento completo).
Errori nei dati
Per errori di troncamento di dati: selezionare l'azione da eseguire quando si verifica un troncamento in uno o più record specifici. È possibile selezionare una delle seguenti opzioni dall'elenco:
- Ignora: l'attività continua e l'errore viene ignorato.
- Registra record nella tabella delle eccezioni (opzione predefinita): l'attività continua e l'errore viene scritto nella tabella delle eccezioni.
- Sospendi tabella: l'attività continua, ma i dati dalla tabella con il record dell'errore viene spostato in uno stato di errore e i relativi dati non vengono replicati.
- Arresta attività: l'attività viene interrotta ed è richiesto l'intervento manuale.
Per gli altri errori nei dati: selezionare l'azione da eseguire quando si verifica un errore in uno o più record specifici. È possibile selezionare una delle seguenti opzioni dall'elenco:
- Ignora: l'attività continua e l'errore viene ignorato.
- Registra record nella tabella delle eccezioni (opzione predefinita): l'attività continua e l'errore viene scritto nella tabella delle eccezioni.
- Sospendi tabella: l'attività continua, ma i dati dalla tabella con il record dell'errore viene spostato in uno stato di errore e i relativi dati non vengono replicati.
- Arresta attività: l'attività viene interrotta ed è richiesto l'intervento manuale.
Riassegna gestione errore quando gli altri errori nei dati raggiungono (per tabella): selezionare questa casella di controllo per riassegnare la gestione dell'errore quando il numero di errori nei dati che non sono relativi al troncamento (per tabella) raggiunge la quantità specificata. I valori validi sono 1-10.000.
Azione di riassegnazione: scegliere l'azione da eseguire quando si riassegna la gestione dell'errore. Notare che le operazioni disponibili dipendono dall'azione selezionata dall'elenco a discesa Per gli altri errori nei dati descritto prima.
-
Sospendi tabella (opzione predefinita): l'attività continua, ma i dati dalla tabella con il record dell'errore viene spostato in uno stato di errore e i relativi dati non vengono spostato.
Nota informaticaIl comportamento è differente a seconda della Modalità di elaborazione modifiche:
-
Nella modalità di Applicazione transazionale, le ultime modifiche non vengono spostato.
-
Nella modalità Applicazione ottimizzata in batch, può verificarsi una situazione in cui i dati verranno spostato solo parzialmente o non verranno spostato affatto.
-
- Arresta attività: l'attività viene interrotta ed è richiesto l'intervento manuale.
- Registra record nella tabella delle eccezioni: l'attività continua e il record viene scritto nella tabella delle eccezioni.
Errori tabella
Quando rileva un errore tabella: selezionare una delle opzioni descritte di seguito dall'elenco a discesa:
- Sospendi tabella: (opzione predefinita) l'attività continua, ma i dati dalla tabella con il record dell'errore passano a uno stato di errore e i dati correlati non vengono replicati.
- Interrompi attività: l'attività viene interrotta ed è richiesto l'intervento manuale.
Riassegna gestione quando gli errori di tabelle raggiungono (per tabella): selezionare questa casella di controllo per riassegnare la gestione dell'errore quando il numero di errori della tabella (per tabella) raggiunge il numero specificato. I valori validi sono 1-10.000.
Azione di riassegnazione: i criteri di riassegnazione per gli errori nella tabella sono impostati su Interrompi attività e non è possibile modificarli.
Conflitti di applicazione
Nessun record trovato per l'applicazione di DELETE: selezionare l'azione da intraprendere quando si verifica un conflitto con un'operazione di DELETE.
- Ignora: l'attività continua e l'errore viene ignorato.
- Registra record nella tabella delle eccezioni: l'attività continua e il record viene scritto nella tabella delle eccezioni.
- Sospendi tabella: l'attività continua, ma i dati dalla tabella con il record dell'errore passano a uno stato di errore e i dati correlati non vengono replicati.
- Interrompi attività: l'attività viene interrotta ed è richiesto l'intervento manuale.
Riassegna gestione dell'errore quando Conflitti di applicazione raggiunge (per tabella): selezionare questa casella di controllo per riassegnare la gestione dell'errore quando il numero di Conflitti di applicazione nella tabella (per tabella) raggiunge la quantità specificata. I valori validi sono 1-10.000.
Azione di riassegnazione: scegliere l'azione da eseguire quando si riassegna la gestione dell'errore.
- Registra record nella tabella delle eccezioni (opzione predefinita): l'attività continua e l'errore viene scritto nella tabella delle eccezioni.
-
Sospendi tabella: l'attività continua, ma i dati dalla tabella con il record dell'errore passano a uno stato di errore e i dati correlati non vengono replicati.
Nota informaticaIl comportamento è differente a seconda della Modalità di elaborazione modifiche:
-
Nella modalità di applicazione Transazionale, le ultime modifiche non vengono replicate.
-
Nella modalità di applicazione Batch ottimizzato, si può verificare una situazione in cui non sarà disponibile la replica dei dati o quest'ultima sarà solo parziale.
-
-
Interrompi attività: l'attività viene interrotta ed è richiesto l'intervento manuale.
Errori ambientali
-
Numero massimo di tentativi: selezionare questa opzione, quindi specificare il numero massimo di tentativi in cui cercare di eseguire l'attività quando si verifica un errore ambientale recuperabile. Una volta completato il numero di tentativi specificato per eseguire l'attività, questa viene interrotta ed è richiesto l'intervento manuale da parte dell'utente.
Per fare in modo che non venga eseguito nessun tentativo, deselezionare la casella di controllo o specificare "0".
Per impostare un numero infinito di tentativi, specificare "-1"
-
Intervallo tra nuovi tentativi (secondi): utilizzare il contatore per selezionare o digitare il numero di secondi che il sistema deve attendere tra un tentativo e l'altro quando tenta di eseguire un'attività.
I valori validi sono 0-2.000.
-
- Aumenta intervallo di tentativi per interruzioni prolungate: selezionare questa casella di controllo per aumentare l'intervallo tra i tentativi per le interruzioni prolungate. Quando questa opzione è abilitata, la durata dell'intervallo tra ciascun tentativo di esecuzione dell'attività raddoppia, fino al raggiungimento dell'Intervallo massimo di tentativi (i tentativi continuano a essere eseguiti in base all'intervallo massimo specificato).
- Intervallo massimo di tentativi (secondi): utilizzare il contatore per selezionare o digitare il numero di secondi da attendere tra un tentativo di eseguire un'attività quando l'opzione Aumenta intervallo di tentativi per interruzioni prolungate è selezionata. I valori validi sono 0-2.000.
Regolazione di elaborazione delle modifiche
Regolazione offload della transazione
-
Offload della transazione in corso al disco se:
L'attività di replica di norma mantiene i dati delle transazioni in memoria fino a quando non vengono completamente implementate nella sorgente e/o destinazione. Tuttavia, per le transazioni con dimensioni più grandi rispetto alla memoria allocata o che non vengono implementate entro il limite di tempo specificato, viene effettuato l'offload su disco.
- Le dimensioni della memoria delle transazioni totali superano (MB): le dimensioni massime che tutte le transazioni possono occupare in memoria prima che venga effettuato l'offload su disco. Il valore predefinito è 1024.
- La durata della transazione supera (secondi): l'intervallo massimo di tempo che ogni transazione può rimanere in memoria prima che venga effettuato l'offload su disco. La durata viene calcolata dall'ora in cui l'attività di replica ha iniziato l'acquisizione della transazione. Il valore predefinito è 60.
Regolazione batch
Le impostazioni in questa scheda sono determinate dalla modalità Applica modifiche.
Le impostazioni che sono disponibili solo quando l'opzione "Applica modalità" è impostata su "Batch ottimizzato".
- Applica modifiche in batch a intervalli:
-
Superiore a: l'intervallo minimo di tempo durante il quale attendere tra ogni applicazione di modifiche in batch. Il valore predefinito è 1.
Se si aumenta il valore nell'opzione Più a lungo di diminuisce la frequenza con la quale le modifiche vengono applicate alla destinazione quando si aumentano le dimensioni dei batch. In questo modo, è possibile migliorare le prestazioni quando si applicano modifiche ai database di destinazione che sono ottimizzati per l'elaborazione di batch di grandi dimensioni.
- Inferiore a: l'intervallo massimo di tempo durante il quale attendere tra ogni applicazione di modifiche in batch (prima di dichiarare il timeout). Quindi, corrisponde alla latenza massima accettabile. Il valore predefinito è 30. Questo valore determina l'intervallo massimo di tempo da attendere prima di applicare le modifiche, dopo che è stato raggiunto il valore Più a lungo di.
-
Applicazione forzata batch quando la memoria di elaborazione supera i limiti (MB): la quantità massima di memoria da utilizzare per la pre-elaborazione nella modalità di applicazione Batch ottimizzato. Il valore predefinito è 500.
Per le dimensioni massime dei batch, impostare questo valore sulla quantità massima di memoria che è possibile assegnare per le attività di replica. In questo modo, è possibile migliorare le prestazioni quando si applicano modifiche ai database di destinazione che sono ottimizzati per l'elaborazione di batch di grandi dimensioni.
Le impostazioni che sono disponibili solo quando l'opzione "Applica modalità" è impostata su "Transazionale".
Le seguenti impostazioni sono applicabili solo quando di utilizza la modalità di applicazione "Transazionale". Notare che "Transazionale" è l'unica modalità di applicazione disponibile (e quindi non selezionabile) quando si replica su Snowflake, e il metodo di caricamento è Snowpipe Streaming.
-
Numero minimo di modifiche per transazione: il numero minimo di modifiche da includere in ogni transazione. Il valore predefinito è 1000.
Nota informaticaLe modifiche verranno applicate alla destinazione quando il numero di modifiche è uguale o maggiore del valore dell'opzione Numero minimo di modifiche per transazione O quando il valore Tempo massimo per raggruppare le transazioni in lotti prima dell'applicazione (secondi), a seconda di quale condizione si verifica per prima. Poiché la frequenza delle modifiche applicate nella destinazione è controllata da questi due parametri, le modifiche ai record di origine potrebbero non essere riflesse immediatamente nei record di destinazione.
- Tempo massimo per raggruppare le transazioni in lotti prima dell'applicazione (secondi): il tempo massimo per raccogliere le transazioni in batch prima che venga dichiarato un timeout. Il valore predefinito è 1.
Intervallo
-
Leggi modifiche ogni (minuti)
Impostare l'intervallo tra le modifiche di lettura dalla sorgente in minuti. L'intervallo valido è compreso tra 1 e 1440.
Nota informaticaQuesta opzione è disponibile solo per le attività che utilizzano:
- Gateway Data Movement
- Il metodo di aggiornamento Applica modifiche o Memorizza modifiche
Verifica la presenza di modifiche
-
In base all'intervallo di estrazione delta: Quando questa opzione è selezionata, l'attività dati verifica la presenza di modifiche in base all'intervallo di estrazione delta.
Nota informaticaL'intervallo inizierà dopo ogni "round". Un round può essere definito come il tempo necessario all'attività dati per leggere le modifiche dalle tabelle di origine e inviarle alla destinazione (come singola transazione). La durata di un round varia in base al numero di tabelle e modifiche. Quindi, se si specifica un intervallo di 10 minuti e un ciclo richiede 4 minuti, il tempo effettivo tra una verifica e l'altra delle modifiche sarà di 14 minuti.-
Intervallo di estrazione delta: La frequenza con cui i delta verranno estratti dal sistema. L'intervallo predefinito è 60 secondi.
-
-
Come pianificato: quando questa opzione è selezionata, l'attività dati estrarrà il delta una volta e poi si arresterà. Quindi, continuerà l'esecuzione in base alla pianificazione.
Nota informaticaQuesta opzione è rilevante solo se l'intervallo tra i cicli CDC è di 24 ore o più.Per informazioni sulla pianificazione:
-
Per le "attività di replica dei dati" in un progetto di replica, consultare Attività di pianificazione
-
Regolazioni varie
Dimensioni della cache di istruzioni (numero di istruzioni)
Il numero massimo di istruzioni preparate per l'archiviazione sul server per l'esecuzione successiva (quando si applicano modifiche alla destinazione). Il valore predefinito è 50. Il valore massimo è 200.
Usa DELETE e INSERT per l'aggiornamento di una colonna della chiave primaria
Questa opzione è disponibile solo quando la modalità di replica Archivia modifiche è abilitata, e richiede l'accesso supplementare completo per poter essere abilitato nel database di origine.
Invia eliminazione definitiva all'eseguire DELETE
Quando questa opzione è selezionata, solo la chiave del messaggio verrà popolata; il messaggio stesso sarà nullo, indicando che l'elemento è stato eliminato. Questo può aiutare i consumer a rilevare che è stata eseguita un'operazione DELETE.
Archivia attività dati di recupero nel database di destinazione
selezionare questa opzione per archiviare le informazioni di recupero specifiche per l'attività nel database di destinazione. Quando questa opzione è selezionata, l'attività di replica crea una tabella denominata attrep_txn_state nel database di destinazione. Nella seguente tabella sono riportati i dati delle transazioni che possono essere utilizzati per recuperare un'attività nel caso in cui i file nella cartella Dati di Gateway Data Movement siano danneggiati o in caso di errore da parte del dispositivo contenente la cartella Dati.
Applica modifiche usando SQL MERGE
Quando questa opzione non è selezionata, l'attività di replica eseguirà le istruzioni INSERT, UPDATE e DELETE in blocco separate per ognuno dei differenti tipi di modifica nella tabella delle variazioni nette.
Sebbene questo metodo sia altamente efficiente, l'abilitazione dell'opzione Applica modifiche usando SQL MERGE è ancora più efficiente quando si utilizzano endpoint che supportano l'opzione.
Ciò è dovuto alle seguenti ragioni:
- Riduce il numero di istruzioni SQL eseguite per ogni tabella da tra a una. La maggior parte delle operazioni di UPDATE in database cloud immutabili e di grandi dimensioni (come ad esempio Google Cloud BigQuery), prevede la riscrittura dei file interessati. Con tali operazioni, la riduzione delle istruzioni SQL per tabella da tre a una è molto importante.
- Il database di destinazione deve scansionare la tabella delle variazioni nette una volta, riducendo in modo significativo le operazioni di I/O.
Ottimizza inserimenti
Quando l'opzione Applica modifiche usando SQL MERGE è selezionata insieme a Ottimizza inserimenti e le modifiche consistono unicamente di operazioni INSERT, l'attività di replica eseguirà queste ultime anziché utilizzare SQL MERGE. Notare che mentre ciò normalmente migliori le prestazioni riducendo i costi, potrebbe anche causare report duplicati nel database di destinazione.
- Le opzioni Applica modifiche usando SQL MERGE e Ottimizza inserimenti sono disponibili solo per le attività configurate con i seguenti endpoint di destinazione:
- Google Cloud BigQuery
- Databricks
- Snowflake
- Le opzioni Applica modifiche usando SQL MERGE e Ottimizza inserimenti non sono supportate con i seguenti endpoint di origine:
- Salesforce
- Oracle
-
Quando l'opzione Applica modifiche usando SQL MERGE è abilitata:
- Gli errori non fatali nei dati o gli errori nei dati che non è possibile recuperare saranno gestiti come errori di tabella.
- I Criteri di gestione degli errori di Applica conflitti non saranno modificabili con le seguenti impostazioni.
- Nessun record trovato per l'applicazione di DELETE: Ignora record
Chiave duplicata durante l'applicazione di INSERT: AGGIORNA il record di destinazione esistente
Nota informaticaSe è selezionata anche l'opzione Ottimizza inserimenti, il valore di Duplica chiave quando applichi INSERT verrà impostato su Consenti duplicati nelle destinazioni.- Nessun record trovato per l'applicazione di un UPDATE: inserire il record di destinazione mancante con INSERT.
- Azione di escalation: Registra record nella tabella delle eccezioni
- Le opzioni Per altri errori di dati e Criteri di gestione degli errori nei dati non saranno disponibili:
- ignora record
- Registra record nella tabella delle eccezioni
- L'operazione SQL MERGE effettiva verrà eseguita solo sulle tabelle di destinazione finali. Le operazioni INSERT verranno eseguite nelle tabelle di modifica intermediarie (quando sono abilitate le modalità di replica Applica modifiche o Archivia modifiche.
Applicazione transazionale
Quando si effettua la replica sulle destinazioni di un data warehouse o quando non si utilizza Gateway Data Movement, queste opzioni non sono rilevanti, poiché l'opzione Modalità di applicazioneè sempre impostata su Batch ottimizzato, con un'unica eccezione.
Fa eccezione la replica su Snowflake con il metodo di caricamento impostato su Snowpipe Streaming.
Le seguenti impostazioni sono disponibili solo quando di utilizza la modalità di applicazione transazionale. Quando si effettua la replica su un database, la modalità di applicazione può essere impostata su Batch ottimizzato o Transazionale. Tuttavia, quando si replica su una destinazione Snowflake e il metodo di caricamento è impostato su Snowpipe Streaming, la modalità di applicazione è sempre transazionale e quindi non può essere impostata.
-
Numero minimo di modifiche per transazione: il numero minimo di modifiche da includere in ogni transazione. Il valore predefinito è 1000.
Nota informaticaL'attività di replica applica le modifiche nella destinazione quando il numero di modifiche è uguale o maggiore del valore dell'opzione Numero minimo di modifiche per transazione OPPURE quando viene raggiunto il valore di timeout del batch (vedere sotto), a seconda di quale condizione si verifica per prima. Poiché la frequenza delle modifiche applicate nella destinazione è controllata da questi due parametri, le modifiche ai record di origine potrebbero non essere riflesse immediatamente nei record di destinazione. - Tempo massimo per raggruppare le transazioni in lotti prima dell'applicazione (secondi): il tempo massimo per raccogliere le transazioni in batch prima che venga dichiarato un timeout. Il valore predefinito è 1.
Evoluzione automatica dello schema
Selezionare come gestire i seguenti tipi di modifiche del DDL nello schema. Una volta modificate le impostazioni di evoluzione dello schema, è necessario preparare nuovamente l'attività. La tabella seguente descrive le azioni disponibili per le modifiche del DDL supportate.
| Cambiamento del DDL | Applica alla destinazione | Ignora | Sospendi tabella | Arresta attività |
|---|---|---|---|---|
| Aggiungi colonna | Sì | Sì | Sì | Sì |
| Modifica tipo dati colonne | Sì | Sì | Sì | Sì |
| Rinomina colonna | Sì | No | Sì | Sì |
|
Rinomina tabella Nota informaticaLa funzionalità non è supportata se la piattaforma di destinazione è Kafka.
|
No | No | Sì | Sì |
| Rilascia colonna | Sì | Sì | Sì | Sì |
|
Rilascia tabella Nota informaticaLa funzionalità non è supportata se la piattaforma di destinazione è Kafka.
|
Sì | Sì | Sì | Sì |
| Crea tabella
Se si è utilizzata una Regola di selezione per aggiungere set di dati che corrispondono a un modello, le nuove tabelle che soddisfano il modello verranno rilevate e aggiunte. |
Sì | Sì | No | No |
Sostituzione di caratteri
È possibile sostituire o eliminare i caratteri nel database di destinazione e/o sostituire o eliminare i caratteri di origine che non sono supportati da un set di caratteri selezionato.
-
Tutti i caratteri devono essere specificati come punti di codice Unicode.
- La sostituzione dei caratteri verrà eseguita anche nelle Tabelle di controllo.
-
I valori non validi saranno indicati da un triangolo rosso nella parte superiore destra della cella della tabella. Se si posiziona il cursore del mouse sul triangolo, viene visualizzato il messaggio di errore.
-
Qualsiasi trasformazione globale o a livello tabella definita per l'attività verrà eseguita una volta completata la sostituzione del carattere.
-
Le azioni di sostituzione definite nella tabella Sostituisci o elimina caratteri di origine vengono eseguite prima dell'azione di sostituzione definita nella tabella Sostituisci o elimina caratteri di origine non supportati dal set di caratteri selezionato.
- La sostituzione dei caratteri non supporta i tipi di dati LOB.
Sostituzione o eliminazione dei caratteri di origine
Utilizzare la tabella Sostituisci o elimina caratteri di origine per definire le sostituzioni per caratteri di origine specifici. Questa opzione può essere utile, ad esempio, quando la rappresentazione Unicode di un carattere è differente nelle piattaforme di origine e di destinazione. Ad esempio, su Linux, il carattere meno nel set di caratteri Shift_JIS è rappresentato come U+2212, ma su Windows è rappresentato come U+FF0D.
| Per | eseguire questa azione |
|---|---|
|
definire le azioni di sostituzione. |
|
|
Modificare i caratteri di origine o di destinazione specificati |
Fare clic su |
|
Elimina voci dalla tabella |
Fare clic su |
Sostituzione o eliminazione dei caratteri di origine non supportati dal set di caratteri selezionato
Utilizzare la tabella Caratteri di origine non supportati dal set di caratteri per definire un singolo carattere di sostituzione per tutti i caratteri non supportati dal set di caratteri selezionato.
| Per | eseguire questa azione |
|---|---|
|
definire o modificare le azioni di sostituzione. |
|
|
Disabilitare l'azione di sostituzione. |
Selezionare la voce vuota dall'elenco a comparsa Set di caratteri. |
Altre opzioni
Queste opzioni non sono esposte nell'interfaccia utente, dato che sono rilevanti solo per versioni o ambienti specifici. Di conseguenza, non impostare queste opzioni a meno che non sia stato esplicitamente indicato dal Supporto Qlik o dalla documentazione dei prodotti.
Per impostare un'opzione, semplicemente copiarla nel campo Aggiungi nome funzionalità e fare clic su Aggiungi. Quindi, impostare il valore o attivare l'opzione in base alle istruzioni ricevute.
Caricamento in parallelo di segmenti del set di dati
Durante un caricamento completo, è possibile velocizzare il caricamento dei set di dati di grandi dimensioni suddividendo il set di dati in segmenti, che verranno caricati in parallelo. Le tabelle possono essere suddivise per intervalli di dati, tutte le partizioni, tutte le sottopartizioni o per partizioni specifiche.
Per ulteriori informazioni, vedere Replica in parallelo di segmenti del set di dati.
Attività di pianificazione
In alcuni casi, potrebbe essere necessario pianificare l'attività per propagare le modifiche dalla sorgente dati alla piattaforma di destinazione.
Per ulteriori informazioni, vedere Scheduling tasks.