
Paramètres de réplication
Vous pouvez configurer les paramètres de la tâche de réplication de données.
-
Ouvrez la tâche Replicate et cliquez sur Paramètres dans la barre d'outils.
La boîte de dialogue Paramètres : <Nom-de-tâche> s'ouvre. Les paramètres disponibles sont décrits ci-dessous.
Généralités
Dans cet onglet, vous pouvez modifier le mode de réplication, les paramètres intermédiaires (le cas échéant), le mode d'application des modifications à la cible et les paramètres de publication.
Mode de réplication
Les modes de réplication suivants sont disponibles :
-
Chargement complet : Charge les données des tables sources sélectionnées dans la plateforme cible et crée les tables cibles, si nécessaire. Le chargement complet s'effectue automatiquement lorsque la tâche démarre, mais il peut également être effectué manuellement, si nécessaire. Un chargement complet manuel serait nécessaire, par exemple, si vous devez répliquer les mises à jour dans Vues (qui ne sont pas capturées lors de l'opération CDC) ou si vous effectuez une réplication à partir d'une source de données qui ne supporte pas l'opération CDC.
Note InformationsLors de l'utilisation d'un connecteur d'applications SaaS, cette option sera toujours activée, car Chargement complet est obligatoire. -
Appliquer les modifications : Maintient les tables cibles à jour en y ajoutant toutes les modifications apportées aux tables sources.
-
Stocker les modifications : Stocke les modifications apportées aux tables sources dans les tables de modifications (une par table source).
Pour plus d'informations, consultez Stocker les modifications.
Lors de l'utilisation de Passerelle de déplacement des données, sauf avec des sources d'applications SaaS, les modifications sont capturées auprès de la source quasiment en temps réel. Si vous travaillez sans Passerelle de déplacement des données (par exemple, avec un abonnement Démarreur Qlik Talend Cloud ou si vous sélectionnez Aucune) ou lors de l'utilisation de sources d'applications SaaS, les modifications sont capturées en fonction des paramètres du planificateur. Pour plus d'informations, consultez Scheduling tasks.
Si vous sélectionnez Stocker les modifications ou Appliquer les modifications et que votre source de données :
-
N'est pas une application SaaS
-
Contient des jeux de données qui supportent CDC et des jeux de données qui supportent Chargement complet uniquement (tels que les vues)
Deux pipelines de données seront créés. Un pipeline sera créé pour les tables qui supportent CDC et un autre pipeline sera créé pour les jeux de données qui supportent Chargement complet uniquement.
Méthode de chargement
Lorsque vous effectuez une réplication vers Snowflake, vous pouvez sélectionner l'une des méthodes de chargement suivantes :
-
Chargement en masse (par défaut)
Si vous sélectionnez Chargement en masse, vous serez en mesure d'affiner les paramètres de chargement dans l'onglet Chargement de données.
-
Snowpipe Streaming
Note InformationsSnowpipe Streaming pourra être sélectionné uniquement si les conditions suivantes sont remplies :
- Le mode de réplication Stocker les modifications est activé, sans Appliquer les modifications.
- Le Mécanisme d'authentification du connecteur Snowflake est défini sur Paire de clés.
- Si vous utilisez Passerelle de déplacement des données, la version 2024.11.45 ou une version ultérieure est requise.
Si vous sélectionnez Snowpipe Streaming, assurez-vous de connaître les Limitations et considérations lors de l'utilisation de cette méthode. En outre, si vous sélectionnez Snowpipe Streaming et que vous activez ensuite le mode de réplication Appliquer les modifications ou que vous désactivez Stocker les modifications, la méthode de chargement repassera automatiquement à Chargement en masse.
Les principaux motifs pour sélectionner Snowpipe Streaming au lieu de Chargement en masse sont les suivants :
-
Moins coûteux : étant donné que Snowpipe Streaming n'utilise pas l'entrepôt Snowflake, les coûts de fonctionnement devraient être beaucoup moins importants, même si cela dépendra de votre cas d'utilisation spécifique.
-
Latence réduite : étant donné que les données sont diffusées directement aux tables cibles (et non pas via une phase intermédiaire), la réplication de la source de données vers la cible devrait être plus rapide.
Connexion à une zone intermédiaire
Lors de la réplication dans les entrepôts de données répertoriés ci-dessous, vous devez définir une zone intermédiaire. Les données sont traitées et préparées dans la zone intermédiaire avant d'être transférées à l'entrepôt.
Sélectionnez une zone intermédiaire existante ou cliquez sur Créer nouveau pour définir une nouvelle zone intermédiaire et suivez les instructions à la section Connexion au stockage cloud.
Pour modifier les paramètres de connexion, cliquez sur Modifier. Pour tester la connexion (recommandé), cliquez sur Tester la connexion.
Pour des informations sur les zones intermédiaires supportées avec tel ou tel entrepôt de données, consultez la colonne Supporté comme zone intermédiaire à la section Cas d'utilisation des plateformes cibles et versions supportées.
Mode d'application des modifications
Les modifications sont appliquées aux tables cibles via l'une des méthodes suivantes :
- Lot optimisé : Il s'agit de la valeur par défaut. Lorsque cette option est sélectionnée, les modifications sont appliquées par lots. Une action de prétraitement s'effectue pour regrouper les transactions par lots de la manière la plus efficace.
- Transactionnel : Sélectionnez cette option pour appliquer chaque transaction individuellement, dans leur ordre de validation. Dans ce cas, une stricte intégrité référentielle est garantie pour toutes les tables.
Paramètres de publication
-
Publier dans le catalogue
Sélectionnez cette option pour publier cette version des données dans Catalogue sous forme de jeu de données. Le contenu de Catalogue sera mis à jour la prochaine fois que vous préparerez cette tâche.
Pour plus d'informations sur Catalogue, consultez Comprendre vos données grâce à des outils de catalogage.
Paramètres de proxy lors de l'utilisation de Passerelle de déplacement des données
-
Lorsque vous utilisez la passerelle Data Movement, connectez-vous via un proxy à
Lorsque vous utilisez Passerelle de déplacement des données, vous pouvez vous connecter à la plateforme cible et à la plateforme (zone) de staging via un proxy.
Pour plus d'informations sur la configuration de Passerelle de déplacement des données pour l'utilisation d'un serveur proxy, consultez Configuration du client Qlik Cloud et d'un serveur proxy.
-
la plateforme cible
Note InformationsDisponible lors de l'utilisation de Snowflake et Databricks. -
la plateforme intermédiaire
Note InformationsDisponible lors de l'utilisation de Google BigQuery, Amazon Redshift, Microsoft Fabric et Databricks.
-
Chargement de données
Cet onglet apparaîtra uniquement en cas de réplication dans une cible de type entrepôt de données ou Kafka. De plus, les paramètres de cet onglet varieront en fonction de la cible sélectionnée.
Pertinent pour toutes les cibles d'entrepôt de données
Taille de fichier maximale
Taille maximale d'un fichier avant sa fermeture. Il se peut que des fichiers plus petits soient chargés plus rapidement (suivant le réseau) et améliorent les performances lors de l'utilisation en combinaison avec l'option d'exécution parallèle. Cependant, il est généralement déconseillé d'encombrer la base de données de petits fichiers.
Applicable uniquement à la cible Snowflake
Dans l'onglet Général , vous pouvez décider de charger les données dans Snowflake à l'aide de Chargement en masse ou de Snowpipe Streaming. Lorsque Snowpipe Streaming est sélectionné, l'onglet Chargement de données n'apparaît pas. Lorsque Chargement en masse est sélectionné, les paramètres suivants sont disponibles :
-
Taille de fichier maximale (Mo) : Applicable au Chargement complet initial et à CDC. Taille maximale qu'un fichier peut atteindre avant qu'il soit chargé sur la cible. Si vous rencontrez des problèmes de performances, essayez de modifier ce paramètre.
-
Nombre de fichiers à charger par lot : Applicable au Chargement complet initial uniquement. Nombre de fichiers à charger dans un seul lot. Si vous rencontrez des problèmes de performances, essayez de modifier ce paramètre.
Pour une description des méthodes de chargement Chargement en masse et Snowpipe Streaming, consultez Généralités.
Applicable uniquement à la cible Kafka
Propriétés du message
Compression
Sélectionnez éventuellement l'une des méthodes de compression disponibles (Snappy ou Gzip). La valeur par défaut est Aucune.
Publication du message de données
Sélectionnez l'une des options Publier les données dans suivantes :
- Topic spécifique : Publie les données dans un seul topic. Saisissez un nom de topic ou utilisez le bouton Parcourir pour sélectionner le topic de votre choix.
-
Séparer les topics pour chaque table : Publie les données dans plusieurs topics correspondant aux noms de table source.
Le nom de topic cible se compose du nom de schéma source et du nom de table source, séparés par un point (par exemple, dbo.Employees). Le format du nom de topic cible est important, car vous devrez préparer ces topic à l'avance.
Si les topics n'existent pas, configurez les brokers avec auto.create.topics.enable=true pour permettre à la tâche de données de créer les topics lors de l'exécution. Sinon, la tâche échouera.
Pour plus d'informations sur le remplacement de ce paramètre au niveau du jeu de données, consultez Remplacement des paramètres de tâche des jeux de données individuels lors de la publication dans Kafka.
Clé du message
Sélectionnez l'une des options disponibles.
-
Colonnes de clé primaire : Pour chaque message, la clé de message contiendra la valeur de la colonne de clé primaire.
Lorsque Par clé du message est sélectionné comme Stratégie de partition, les messages ayant la même valeur de clé primaire seront écrits dans la même partition.
-
Schéma et nom de table : Pour chaque message, la clé de message contiendra une combinaison de schéma et de nom de table (par exemple, dbo+Employees).
Lorsque Par clé du message est sélectionné comme Stratégie de partition, les messages ayant le même schéma et le même nom de table seront écrits dans la même partition.
- Aucune : Crée des messages sans clé de message.
Pour plus d'informations sur le remplacement de ce paramètre au niveau du jeu de données, consultez Remplacement des paramètres de tâche des jeux de données individuels lors de la publication dans Kafka.
Stratégie de partition
Sélectionnez soit Aléatoire, soit Par clé du message. Si vous sélectionnez Aléatoire, chaque message sera écrit dans une partition sélectionnée de manière aléatoire. Si vous sélectionnez Par clé du message, les messages seront écrits dans des partitions en fonction de la Clé du message sélectionnée (décrite ci-dessus).
Publication du message de métadonnées
Stratégie du nom du sujet
La première stratégie (Schéma et nom de table) est une stratégie Qlik propriétaire, tandis que les trois autres sont des stratégies de nom de sujet Confluent standards.
Sélectionnez l'une des stratégies de nom de sujet disponibles.
- Schéma et nom de table (par défaut)
- Nom du topic
- Nom d'enregistrement
- Nom du topic et de l'enregistrement
Pour plus d'informations sur les stratégies de nom de sujet de Confluent, consultez Stratégie de nom de sujet.
Mode de compatibilité du sujet
Sélectionnez l'un des modes de compatibilité suivants dans la liste déroulante Mode de compatibilité du sujet :
-
Utiliser les valeurs par défaut du registre de schémas : Récupère le niveau de compatibilité auprès de la configuration du serveur de registre de schémas.
-
Descendante - dernier schéma uniquement : Les nouveaux schémas peuvent lire les données correspondantes et les données produites par le dernier schéma enregistré uniquement.
-
Descendante directe - tous les schémas précédents : Les nouveaux schémas peuvent lire les données produites par tous les schémas précédemment enregistrés.
-
Ascendante - dernier schéma uniquement : Le dernier schéma enregistré peut lire les données produites par le nouveau schéma.
-
Ascendante directe - tous les schémas précédents : Tous les schémas précédemment enregistrés peuvent lire les données produites par le nouveau schéma.
-
Complète - dernier schéma uniquement : Le nouveau schéma est compatible en amont et en aval avec le dernier schéma enregistré.
-
Complète directe - tous les schémas précédents : Le nouveau schéma est compatible en amont et en aval avec l'ensemble des schémas précédemment enregistrés.
-
Aucun
- Selon la Stratégie de nommage du sujet sélectionnée, il se peut que certains modes de compatibilité ne soient pas disponibles.
-
Lors de la publication de messages dans un registre de schémas, le mode de compatibilité de sujet par défaut pour tous les sujets de table de contrôle récemment créés sera Aucun, quel que soit le Mode de compatibilité du sujet sélectionné.
Si vous souhaitez que le Mode de compatibilité du sujet sélectionné s'applique également aux tables de contrôle, définissez le paramètre interne setNonCompatibilityForControlTables du connecteur cible Kafka sur false.
Utilisez un proxy pour vous connecter au Confluent Schema Registry
Cette option n'est supportée que lors de la publication dans le registre de schémas Confluent.
Activez-la si votre Passerelle de déplacement des données est configurée de sorte à utiliser un serveur proxy.
Attributs du message
Vous pouvez spécifier des attributs de message personnalisés qui remplaceront les attributs de message par défaut. Cela est utile si l'application consommatrice doit traiter le message dans un format particulier.
Les attributs de message personnalisés peuvent être définis aux niveaux de la tâche et de la table. Lorsque les attributs sont définis aux niveaux de la tâche et de la table, les attributs de message définis pour la table auront la priorité sur ceux définis pour la tâche.
Pour plus d'informations sur le remplacement des attributs de message au niveau du jeu de données, consultez Remplacement des paramètres de tâche des jeux de données individuels lors de la publication dans Kafka.
Les messages structurés de manière hiérarchique ne sont pas supportés.
Règles générales et directives d'utilisation
Lors de la définition d'un message personnalisé, il est important de prendre en compte les règles et les directives d'utilisation répertoriées ci-dessous.
Noms de section
Les règles de nommage suivantes s'appliquent :
- Les noms de section doivent commencer par les caractères a-z, A-Z ou _ (trait de soulignement) et peuvent ensuite être suivis de l'un des caractères suivants : a-z, A-Z, 0-9, _
- À l'exception des sections Nom d'enregistrement et Nom de clé (qui ne se terminent pas par une barre oblique), la suppression de la barre oblique des noms de section aplatira la hiérarchie de la section associée (consultez la section Barres obliques ci-dessous).
- Tous les noms de section, à l'exception de Nom d'enregistrement et Nom de clé, peuvent être supprimés (consultez la section Suppression ci-dessous).
-
Les noms de section Nom de données et Inclure l'enregistrement avant les données ne peuvent pas être supprimés tous les deux.
-
Les noms de section Nom de données et Inclure l'enregistrement avant les données ne peuvent pas être identiques.
Certains des noms de section de l'IU se terminent par une barre oblique (par exemple beforeData/). Le but de la barre oblique est de maintenir une hiérarchie des différentes sections au sein du message. Si la barre oblique est supprimée, cela entraîne les conséquences suivantes :
- La structure hiérarchique de cette section sera aplatie, ce qui entraînera la suppression du nom de section du message.
- Le nom de section sera préfixé aux métadonnées réelles, soit directement, soit via un caractère séparateur (par exemple, un trait de soulignement) que vous avez ajouté au nom.
Exemple de message de données lorsque headers/ est spécifié avec une barre oblique :
"message":{
"data":{
"COL1": "159",
"COL2": "159"
},
"beforeData": null,
"headers": {
"operation": "INSERT",
"changeSequence": "2018100811484900000000233",
Exemple de message de données lorsque headers_ est spécifié avec un trait de soulignement à la place d'une barre oblique :
"message":{
"data":{
"COL1": "159",
"COL2": "159"
},
"beforeData": null,
"headers_operation": "INSERT",
"headers_changeSequence": "2018100811484900000000233",
La suppression d'un nom de section du message aplatira la structure hiérarchique de cette section. Dans ce cas, toutes les données de cette section apparaîtront immédiatement en dessous du contenu de la section précédente.
Exemple de message de données avec le nom de section headers :
"message":{
"data":{
"COL1": "159",
"COL2": "159"
},
"headers": {
"operation": "INSERT",
"changeSequence": "2018100811484900000000233",
Exemple de message de données sans le nom de section headers :
"message":{
"data":{
"COL1": "159",
"COL2": "159"
},
"beforeData": null,
"operation": "INSERT",
"changeSequence": "2018100811484900000000233",
Variables
Vous pouvez ajouter des variables aux noms en cliquant sur le bouton ![]() à la fin de la ligne. Les variables suivantes sont disponibles :
à la fin de la ligne. Les variables suivantes sont disponibles :
- SERVER_NAME - Nom d'hôte du serveur Passerelle de déplacement des données
- TARGET_TABLE_NAME - Nom de la table
- TARGET_TABLE_OWNER - Propriétaire de la table
- TASK_NAME - Nom de la tâche de données
La variable TARGET_TABLE_OWNER n'est pas disponible pour les options Nom d'enregistrement et Nom de clé (décrites dans le tableau ci-dessous).
Définition des attributs de message personnalisés
Pour définir un format de message personnalisé, activez Utiliser les paramètres personnalisés et configurez les options comme indiqué dans le tableau ci-dessous.
Pour revenir aux attributs de message par défaut, désactivez Utiliser les paramètres personnalisés.
| Option | Description |
|---|---|
|
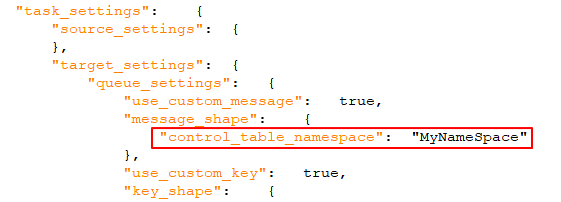
En cas d'activation (par défaut), un identifiant unique sera inclus dans le message. Il doit s'agir d'une chaîne séparée par des points. Notez que l'espace de noms sera inclus dans le message et la clé du message. Exemple : mycompany.queue.msg Nom par défaut : com.attunity.queue.msg.{{TASK_NAME}}.{{TARGET_TABLE_OWNER}}.{{TARGET_TABLE_NAME}} Nom par défaut des tables de contrôle : com.attunity.queue.msg.{{TARGET_TABLE_NAME}} Note Informations
L'espace de noms de table de contrôle par défaut ne peut pas être modifié via l'IU. Vous pouvez, cependant, modifier l'espace de noms de table de contrôle par défaut comme suit :
|
|
|
Nom d'enregistrement |
Nom de l'enregistrement (message). Nom par défaut : DataRecord |
|
Nom de données |
Toutes les colonnes de données incluses dans l'enregistrement. Nom par défaut : data/ |
|
Inclure les en-têtes |
En cas d'activation (par défaut), des colonnes d'en-tête seront incluses dans le message. Les colonnes d'en-tête fournissent des informations supplémentaires sur les opérations sources. Pour plus d'informations, consultez la section Inclure les en-têtes suivants ci-dessous. |
|
Inclure l'espace de noms des en-têtes |
En cas d'activation (par défaut), un identifiant unique pour la section de colonnes d'en-tête sera inclus dans le message. Il doit s'agir d'une chaîne séparée par des points. Exemple : headers.queue.msg Nom par défaut : com.attunity.queue.msg |
|
Noms des en-têtes |
Nom de la section contenant les en-têtes de colonne Qlik. Nom par défaut : headers/ |
|
Pour une description des colonnes d'en-tête disponibles, consultez la section Messages de données dans l'Aide Qlik. Par défaut : Toutes les colonnes sont incluses par défaut, à l'exception de la colonne ID de schéma externe. |
|
|
Inclure l'enregistrement avant les données |
En cas d'activation (par défaut), les données avant et après UPDATE seront incluses dans les messages UPDATE. Pour inclure uniquement les données après UPDATE dans les messages, désactivez l'option. Nom par défaut : beforeData/ |
|
Nom de la clé |
Nom de la section contenant la clé de message. Nom par défaut : keyRecord Cette option s'applique uniquement dans les cas suivants :
|
Paramètres supplémentaires
-
Taille maximale du message
Dans le champ Taille maximale du message, spécifiez la taille maximale des messages que le ou les brokers sont configurés pour recevoir (message.max.bytes). La tâche de données n'enverra pas de messages de taille supérieure à la taille maximale.
Métadonnées
Basic (Basique)
-
Schéma de table cible
Schéma de la cible dans laquelle les tables sources seront répliquées si vous ne souhaitez pas utiliser le schéma de table source (ou en l'absence de schéma dans la base de données source).
Note InformationsLors de la réplication vers une cible Oracle, le schéma de table cible par défaut est « system ». Notez également qui si vous laissez ce champ vide (auquel cas le schéma source sera utilisé), vous devez vous assurer que le schéma source existe déjà dans la cible. Sinon, la tâche échouera.Note InformationsLa longueur maximale autorisée, pour le nom de schéma, est de 128 caractères.
Mapping de colonnes JSON
Mapper les colonnes source compatibles JSON aux colonnes JSON sur la cible
-
Si vous utilisez Passerelle de déplacement des données pour accéder à votre source de données, la version 2024.11.70 ou une version ultérieure est nécessaire.
Lorsque cette option est sélectionnée, les colonnes JSON de la source sont automatiquement mappées vers les colonnes JSON de la cible.
L'état et la visibilité de cette option sont déterminés par les facteurs suivants :
-
Nouvelles tâches : cette option sera activée par défaut si la source et la cible supportent toutes les deux le type de données JSON.
-
Tâches existantes : cette option sera activée par défaut, même si la source et la cible supportent toutes les deux le type de données JSON. Ceci afin de préserver la rétrocompatibilité avec les processus en aval (tels que les transformations) qui s'attendent à ce que les données cibles se présentent au format STRING (le comportement hérité). Vous pouvez soit laisser l'option désactivée, soit modifier les processus en aval de sorte qu'ils soient compatibles avec le format JSON, puis activer cette option.
-
Tâches nouvelles et existantes : si seule la source supporte le type de données JSON, cette option ne sera pas visible. Si le support JSON est ajouté à la cible à un stade ultérieur, l'option deviendra visible, mais restera désactivée. Ceci afin de préserver la rétrocompatibilité avec les processus en aval (tels que les transformations) qui s'attendent à ce que les données cibles se présentent au format STRING (le comportement hérité).
Paramètres de LOB
Les paramètres de LOB disponibles varient suivant la cible de réplication sélectionnée. Étant donné que les cibles de type entrepôt de données ne supportent pas les tailles de colonne de LOB illimitées, cette option ne sera pas disponible lors de la réplication dans un entrepôt de données.
Paramètres de LOB de cibles qui ne sont pas des entrepôts de données
- Ne pas inclure les colonnes de LOB : Sélectionnez cette option si vous ne souhaitez pas répliquer les colonnes de LOB sources.
-
Limiter la taille des colonnes LOB à (Ko) : Il s'agit de l'option par défaut. Sélectionnez cette option si vous avez besoin de répliquer uniquement de petits LOB ou si la plateforme cible ne prend pas en charge la taille de LOB illimitée. La valeur maximale autorisée, pour ce champ, est de 102 400 Ko (100 Mo).
Lors de la réplication de petits LOB, cette option est plus efficace que l'option Ne pas limiter la taille des colonnes LOB, car les LOB sont répliqués "inline" et non via une recherche "lookup" depuis la source. Lors du traitement des modifications, les petits LOB sont généralement répliqués via une recherche "lookup" depuis la source.
La limite s'applique au nombre d'octets de LOB qui est lu à partir du point de terminaison source. Pour les colonnes BLOB, la taille de BLOB cible correspondra exactement à la limite spécifiée. Pour les colonnes CLOB et NCLOB, la taille de LOB cible peut différer de la limite spécifiée si le LOB source et le LOB cible n'ont pas le même jeu de caractères. Dans ce cas, la tâche de données effectuera une conversion de jeu de caractères, ce qui pourrait entraîner une différence entre les tailles des LOB source et cible.
Étant donné que la valeur de l'option Limiter la taille de LOB est exprimée en octets, la taille doit être calculée conformément aux formules suivantes :
- BLOB : longueur du plus grand LOB.
- NCLOB : Longueur du plus long TEXTE en caractères multipliés par deux (car chaque caractère est traité comme un double octet). Si les données incluent des caractères à 4 octets, multipliez-les par quatre.
- CLOB : Longueur du plus long TEXTE en caractères (car chaque caractère est traité comme un caractère UTF-8). Si les données incluent des caractères à 4 octets, multipliez-les par deux.
Note Informations- Tout LOB supérieur à la taille spécifiée sera tronqué.
- Lors du traitement des modifications depuis une source Oracle, les BLOB inline sont répliqués inline.
- Les modifications apportées à ce paramètre affecteront uniquement les tables existantes après leur actualisation.
-
Ne pas limiter la taille des colonnes LOB : Lorsque cette option est sélectionnée, les colonnes de LOB sont répliquées, quelle que soit leur taille.
Note InformationsLa réplication des colonnes de LOB peut avoir un impact sur les performances. Cela s'avère particulièrement vrai en cas de colonnes de LOB volumineuses nécessitant que la tâche de réplication effectue une recherche (lookup) depuis la table source pour récupérer la valeur de LOB source.-
Optimiser lorsque la taille de LOB est inférieure à : Sélectionnez cette option si vous devez répliquer des LOB de petite et de grande tailles et si la plupart des LOB sont de petite taille.
Note InformationsCette option est supportée uniquement avec les sources et cibles suivantes :
-
Sources : Oracle, Microsoft SQL server, MySQL, PostgreSQL et IBM DB2 for LUW
-
Cibles : Oracle, Microsoft SQL Server, MySQL, PostgreSQL.
Lorsque cette option est sélectionnée, lors du processus Chargement complet, les petits LOB sont répliqués "inline" (ce qui s'avère plus efficace) et les grands LOB sont répliqués via une recherche "lookup" depuis la table source. En revanche, lors du traitement des modifications, les LOB, petits et grands, sont répliqués via une recherche "lookup" depuis la table source.
Note InformationsLorsque cette option est sélectionnée, la tâche de réplication vérifie toutes les tailles de LOB pour déterminer ceux à transférer « inline ». Les LOB dont la taille est supérieure à la taille spécifiée sont répliqués en mode LOB complet.
Par conséquent, si vous savez que la plupart des LOB sont plus volumineux que le paramètre spécifié, il est préférable d'utiliser l'option Répliquer les colonnes de LOB illimitées .
-
-
Taille de bloc (Ko) : Vous pouvez éventuellement modifier la taille des blocs de LOB lors de la réplication des données dans la cible. La taille de bloc par défaut devrait suffire, dans la plupart des cas, mais, si vous rencontrez des problèmes de performances, l'ajustement de la taille peut aider à les résoudre.
Note InformationsAvec certaines bases de données, la validation du type de données a lieu lors de l'insertion ou de la mise à jour des données. Dans de tels cas, la réplication de types de données structurés (par ex., XML, JSON, GEOGRAPHY, etc.) risque d'échouer, si les données sont plus volumineuses que la taille de bloc spécifiée.
-
Paramètres de LOB des cibles de type entrepôt de données supportées
-
Inclure les colonnes LOB et limiter la taille des colonnes à (Ko) :
Vous pouvez choisir d'inclure des colonnes LOB dans la tâche et de définir la taille LOB maximale. Les LOB dépassant la taille maximale seront tronqués.
Avancé
Paramètres des tables de contrôle
-
Schéma des tables de contrôle : Spécifiez le schéma cible des tables de contrôle si vous ne souhaitez pas qu'elles soient créées dans le schéma source (par défaut) ou dans le schéma cible.
Note InformationsLa longueur maximale autorisée, pour le nom de schéma, est de 128 caractères. - Créer des tables de contrôle cibles dans l'espace de stockage (tablespace) : Lorsque la cible de réplication est Oracle, spécifiez l'espace de stockage (tablespace) dans lequel créer les tables de contrôle cibles. Si vous ne saisissez aucune information dans ce champ, les tables seront créées dans l'espace de stockage (tablespace) de la base de données cible.
- Créer des index pour les tables de contrôle cibles dans l'espace de stockage (tablespace) : Lorsque la cible de réplication est Oracle, spécifiez l'espace de stockage (tablespace) dans lequel créer les index des tables de contrôle. Si vous ne saisissez aucune information dans ce champ, les index seront créés dans le même espace de stockage (tablespace) que celui des tables de contrôle.
- Créneau horaire de l'historique des réplications (minutes) : Longueur de chaque créneau horaire de la table de contrôle Historique des réplications. La valeur par défaut est 5 minutes.
Sélection des tables de contrôle
Sélectionnez les tables de contrôle à créer sur la plateforme cible :
| Nom logique | Nom dans la cible |
|---|---|
| Appliquer les exceptions | attrep_apply_exceptions |
| État de réplication | attrep_status |
| Tables suspendues | attrep_suspended_tables |
| Historique des réplications | attrep_history |
| Historique DDL |
attrep_ddl_history La table Historique DDL est supportée uniquement avec les plateformes cibles suivantes :
|
Pour plus d'informations sur les tables de contrôle, consultez Tables de contrôle.
Chargement complet
Basic (Basique)
Ces paramètres seront appliqués lors de la phase de préparation de la tâche de données et chaque fois qu'une table est actualisée.
Si la table cible existe déjà : sélectionnez l'une des options suivantes pour déterminer la manière dont les données doivent être chargées dans les tables cibles :
L'option consistant à ignorer ou à tronquer les tables cibles est pertinente uniquement si lesdites opérations sont supportées par le point de terminaison source.
-
Abandonner et créer la table : La table cible est abandonnée et une nouvelle table est créée à sa place.
Note InformationsLes tables de contrôle de la tâche de réplication ne seront pas abandonnées. En revanche, toute table suspendue abandonnée sera également supprimée de la table de contrôle attrep_suspended_tables si la tâche associée est actualisée.
-
TRONQUER avant de charger : les données sont tronquées sans affecter les métadonnées de la table cible. Notez que, lorsque cette option est sélectionnée, l'activation de l'option Créer une clé primaire ou un index unique à la fin du chargement complet n'aura aucun effet.
Note InformationsNon supporté lorsque Microsoft Fabric est la plateforme cible. - Ignorer : Les métadonnées et les données existantes de la table cible ne seront pas affectées. De nouvelles données seront ajoutées à la table.
Avancé
Réglage des performances
Si la réplication de données est excessivement lente, l'ajustement des paramètres suivants peut améliorer les performances.
- Nombre maximal de tables : saisissez le nombre maximal de tables à charger en une seule fois dans la cible. La valeur par défaut est 5.
-
Délai d'expiration de la cohérence des transactions (secondes) : saisissez le nombre de secondes pendant lequel la tâche de réplication doit attendre la fermeture des transactions ouvertes avant de démarrer l'opération Chargement complet. La valeur par défaut est 600 (10 minutes). La tâche de réplication démarrera le chargement complet une fois la valeur de délai d'expiration atteinte, même en cas de transactions ouvertes.
Note InformationsPour répliquer des transactions ouvertes lors du démarrage de l'opération Chargement complet, mais validées uniquement après que la valeur du délai d'expiration a été atteinte, vous devez actualiser les tables cibles. - Taux de commit lors du chargement complet : Nombre maximal d'événements pouvant être transférés ensemble. La valeur par défaut est 10 000.
À la fin du chargement complet
Vous pouvez définir la tâche de sorte qu'elle s'arrête automatiquement une fois le chargement complet terminé. Cela s'avère utile si vous devez effectuer des opérations DBA sur les tables cibles avant le début de la phase Appliquer les modifications (à savoir, CDC) de la tâche.
Lors du chargement complet, toutes les opérations DML exécutées sur les tables sources sont mises en cache. À la fin du chargement complet, les modifications mises en cache sont automatiquement appliquées aux tables cibles (à condition que les options Avant/Après l'application des modifications mises en cache décrites ci-dessous soient désactivées).
-
Créer une clé primaire ou un index unique : Sélectionnez cette option pour différer la création de clé primaire ou d'index unique sur la cible après la fin du chargement complet.
Note InformationsCes paramètres ne sont pas disponibles pour les tâches qui utilisent un connecteur d'applications SaaS. - Arrêter la tâche : Note Informations
Ces paramètres ne sont pas disponibles lors de la réplication dans des cibles de type entrepôt de données.
Avant l'application des modifications mises en cache : Sélectionnez cette option pour arrêter la tâche après la fin du chargement complet.
Après l'application des modifications mises en cache : Sélectionnez cette option pour arrêter la tâche dès que les données sont cohérentes sur l'ensemble des tables de la tâche.
Note InformationsLors de la configuration de la tâche de sorte qu'elle s'arrête après la fin du chargement complet, notez les points suivants :
- La tâche ne s'arrête pas immédiatement à la fin du chargement complet. Elle s'arrête uniquement après la capture du premier lot de modifications (car c'est cela qui déclenche l'arrêt de la tâche). Cela peut prendre un certain temps, suivant la fréquence de mise à jour de la base de données source. Après l'arrêt de la tâche, les modifications ne sont pas appliquées à la cible tant que la tâche n'a pas repris.
- La sélection de l'option Avant l'application des modifications mises en cache peut avoir un impact sur les performances, car les modifications mises en cache seront appliquées aux tables (même à celles pour lesquelles le chargement complet est déjà terminé) uniquement après la fin du chargement complet de la dernière table.
- Lorsque cette option est sélectionnée et qu'une opération DDL est exécutée sur une des tables sources lors du processus Chargement complet (dans une tâche Chargement complet et Appliquer les modifications), la tâche de réplication actualise la table. Cela signifie effectivement que toute opération DML exécutée sur les tables sources sera répliquée dans la cible avant l'arrêt de la tâche.
Pour le chargement initial
| Utiliser les données en cache |
Cette option vous permet d'utiliser les données en cache qui ont été lues lors de la génération des métadonnées avec Scan de données complet sélectionné. Cela génère moins de frais généraux en ce qui concerne les quotas et l'utilisation des API, car les données sont déjà lues de la source. Toute modification depuis le scan de données initial peut être capturée via Change Data Capture (CDC). |
| Charger les données de la source |
Cette option effectue un nouveau chargement depuis la source de données. Cette option est utile dans les cas suivants :
|
Appliquer les modifications
Ces paramètres sont disponibles uniquement lorsque le mode de réplication Appliquer les modifications est activé.
Basic (Basique)
Sélectionnez le type de modifications DDL à appliquer à la cible
Les options suivantes déterminent si les opérations DDL effectuées sur la table source correspondante seront également effectuées sur la table cible.
Abandonner la table : Sélectionnez cette option pour abandonner la table cible lorsque la table source est abandonnée.
Note InformationsNon supporté lorsque Kafka est la plateforme cible.Tronquer la table : Sélectionnez cette option pour tronquer la table cible lorsque la table source est tronquée.
Note InformationsNon supporté lorsque Microsoft Fabric est la plateforme cible.Modifier la table : Sélectionnez cette option pour modifier la table cible lorsque la table source est modifiée.
Note InformationsLe renommage d'une table n'est pas supporté lorsque Kafka est la plateforme cible.
Modifier le réglage du traitement
Appliquer les modifications par lots à plusieurs tables en même temps : La sélection de cette option peut améliorer les performances lors de l'application de modifications provenant de différentes tables sources.
Note InformationsCette option est supportée uniquement dans les cas suivants :
- Le mode Appliquer les modifications est défini sur Optimisation par lots. Pour plus d'informations, consultez Paramètres de réplication.
- Les cibles de réplication ne sont pas MySQL, PostgreSQL, Oracle ni Google BigQuery.
Nombre maximal de tables : Nombre maximal de tables auxquelles simultanément appliquer les modifications par lots. La valeur par défaut est cinq, la valeur maximale est 50 et la valeur minimale est deux.
Lorsque l'option Appliquer les modifications par lots à plusieurs tables en même temps est activée, les limitations suivantes s'appliquent :
Les valeurs par défaut de la stratégie de traitement des erreurs des tâches resteront identiques pour les erreurs de types Environnement et Table, mais les valeurs par défaut des erreurs de types Données et Conflits d'application seront les suivantes :
- Erreurs de données :
- Erreurs de troncation de données : Consigner l'enregistrement dans la table d'exceptions
- Autres erreurs de données : Suspendre la table
- Erreurs de conflits d'application :
- Suppressions : Ignorer l'enregistrement
Insertions : METTRE À JOUR l'enregistrement cible existant
Note InformationsCela ne s'applique pas pour une cible Snowflake (car Snowflake ne supporte pas les clés primaires).- Mises à jour : Ignorer l'enregistrement
- Action de remontée :
- L'Action de remontée des erreurs de types Données et Conflits d'application n'est pas supportée.
- La table de contrôle attrep_apply_exception n'est pas supportée.
- Pour les erreurs de données :
- L'option Consigner l'enregistrement dans la table d'exceptions est disponible uniquement pour les erreurs de troncation de données.
- Il n'existe pas d'option Ignorer.
- Pour les conflits d'application :
- L'option Consigner l'enregistrement dans la table d'exceptions n'est pas disponible.
L'option Ignorer est disponible uniquement pour le conflit d'application Enregistrement introuvable pour l'application d'une opération UPDATE.
- Erreurs de données :
Consultez aussi : Traitement des erreurs.
Limitez le nombre de modifications appliquées par instruction de traitement des modifications à : Pour limiter le nombre de modifications appliquées dans une seule instruction de traitement des modifications, cochez cette case, puis modifiez éventuellement la valeur par défaut. La valeur par défaut est 10 000.
Note InformationsCette option est supportée uniquement avec les cibles suivantes : MySQL, PostgreSQL, Oracle et Google BigQuery.
Avancé
Consultez Modifier le réglage du traitement.
Stocker les modifications
Ces paramètres sont disponibles uniquement lorsque le mode de réplication Stocker les modifications est activé.
Basic (Basique)
Options DDL
Sélectionnez une des options suivantes pour déterminer le mode de traitement des opérations DDL sur les tables sources :
- Appliquer à la table de modifications : Les opérations DDL appliquées aux tables sources (telles que l'ajout d'une colonne) le seront uniquement aux tables de modifications correspondantes.
- Ignorer : toutes les opérations DDL appliquées aux tables sources seront ignorées.
Avancé
Lors de la mise à jour
Sélectionnez Stocker l'image précédente et l'image suivante pour stocker les données pré-UPDATE et les données post-UPDATE. Si cette option n'est pas sélectionnée, seules les données post-UPDATE seront stockées.
Création de table de modifications
La section suivante décrit les options disponibles lors du stockage des modifications dans les tables de modifications.
- Suffixe : spécifie une chaîne à utiliser comme suffixe pour l'ensemble des tables de modifications. La valeur par défaut est __ct. Les noms des tables de modifications correspondent au nom de la table cible avec le suffixe ajouté. Par exemple, si on utilise la valeur par défaut, le nom de la table de modifications sera HR__ct.
- Préfixe de colonne d'en-tête : spécifie une chaîne à utiliser comme préfixe pour l'ensemble des colonnes d'en-tête des tables de modifications. La valeur par défaut est header__. Par exemple, si on utilise la valeur par défaut, la colonne d'en-tête stream_position sera intitulée header__stream_position.
Pour plus d'informations sur les tables de modifications, voir Utilisation de tables de modifications.
S'il existe une table de modifications lors du démarrage du processus Chargement complet : Sélectionnez une des options suivantes pour déterminer comment charger les tables de modifications lorsque la réplication Chargement complet démarre :
- Abandonner et créer la table de modifications : la table est abandonnée et une nouvelle table est créée à sa place.
Supprimer les anciennes modifications et stocker les nouvelles modifications dans la table de modifications existante : les données sont tronquées et ajoutées sans affecter les métadonnées de la table.
Note InformationsNon supporté lorsque Microsoft Fabric est la plateforme cible.- Conserver les anciennes modifications et stocker les nouvelles modifications dans la table de modifications existante : les données et les métadonnées de la table de modifications existante ne sont pas affectées.
Colonnes d'en-tête de table
Les colonnes d'en-tête de la table de modifications fournissent des informations sur les opérations Traitement des modifications telles que le type d'opération (par ex., INSÉRER), l'heure de validation, etc. Si vous n'avez pas besoin de l'ensemble de ces informations, vous pouvez configurer la tâche déplacement de sorte à créer les tables de modifications avec les colonnes d'en-tête sélectionnées (ou aucune), ce qui vous permet de réduire leur empreinte dans la base de données cible.
Pour une description des colonnes d'en-tête, voir Tables de modifications.
Traitement des erreurs
Basic (Basique)
Conflits d'application
Dupliquer la clé lors de l'application de INSÉRER : Sélectionnez l'action à entreprendre en cas de conflit avec une opération INSÉRER.
Ignorer : la tâche se poursuit et l'erreur est ignorée.
Opération UPDATE sur l'enregistrement cible existant : l'enregistrement cible présentant la même clé primaire que celle de l’enregistrement source INSÉRÉ est mis à jour.
- Consigner l'enregistrement dans la table d'exceptions (par défaut) : la tâche se poursuit et l'erreur est écrite dans la table d'exceptions.
Suspendre la table : la tâche se poursuit, mais les données de la table comportant l'enregistrement d'erreur passent à l'état d'erreur et ne sont pas répliquées.
- Arrêter la tâche : la tâche est arrêtée et une intervention manuelle est requise.
Enregistrement introuvable pour l'application d'une MISE À JOUR : Sélectionnez l'action à entreprendre en cas de conflit avec une opération METTRE À JOUR.
- Ignorer : la tâche se poursuit et l'erreur est ignorée.
INSÉRER l'enregistrement cible manquant : l'enregistrement cible manquant sera inséré dans la table cible. Lorsque le point de terminaison source est Oracle, la sélection de cette option nécessite l'activation d'une journalisation supplémentaire pour toutes les colonnes de tables sources.
- Consigner l'enregistrement dans la table d'exceptions (par défaut) : la tâche se poursuit et l'erreur est écrite dans la table d'exceptions.
Suspendre la table : la tâche se poursuit, mais les données de la table comportant l'enregistrement d'erreur passent à l'état d'erreur et ne sont pas répliquées.
- Arrêter la tâche : la tâche est arrêtée et une intervention manuelle est requise.
Avancé
Le traitement des erreurs de données est supporté en mode de réplication Appliquer les modifications uniquement (et non en mode Chargement complet).
Erreurs de données
Pour les erreurs de troncation de données : Sélectionnez ce que vous souhaitez qu'il se passe en cas de troncation dans un ou plusieurs enregistrements spécifiques. Vous pouvez sélectionner un des comportements suivants dans la liste :
- Ignorer : La tâche se poursuit et l'erreur est ignorée.
- Consigner l'enregistrement dans la table d'exceptions (par défaut) : La tâche se poursuit et l'erreur est écrite dans la table d'exceptions.
- Suspendre la table : La tâche se poursuit, mais les données de la table comportant l'enregistrement d'erreur passent à l'état d'erreur et ne sont pas répliquées.
- Arrêter la tâche : La tâche est arrêtée et une intervention manuelle est requise.
Pour d'autres erreurs de données : Sélectionnez ce que vous souhaitez qu'il se passe en cas d'erreur dans un ou plusieurs enregistrements spécifiques. Vous pouvez sélectionner un des comportements suivants dans la liste :
- Ignorer : La tâche se poursuit et l'erreur est ignorée.
- Consigner l'enregistrement dans la table d'exceptions (par défaut) : La tâche se poursuit et l'erreur est écrite dans la table d'exceptions.
- Suspendre la table : La tâche se poursuit, mais les données de la table comportant l'enregistrement d'erreur passent à l'état d'erreur et ne sont pas répliquées.
- Arrêter la tâche : La tâche est arrêtée et une intervention manuelle est requise.
Remonter le traitement des erreurs lorsque d'autres erreurs de données atteignent (par table) : Cochez cette case pour faire remonter le traitement des erreurs lorsque le nombre d'erreurs de données hors troncation (par table) atteint la quantité spécifiée. Les valeurs valides vont de 1 à 10 000.
Action de remontée : Sélectionnez ce qui doit se produire en cas de remontée du traitement des erreurs. Notez que les actions disponibles dépendent de l'action sélectionnée dans la liste déroulante Pour d'autres erreurs de données décrite ci-dessus.
Suspendre la table (par défaut) : La tâche se poursuit, mais les données de la table comportant l'enregistrement d'erreur passent à l'état d'erreur et ne font pas l'objet d'une tâche déplacé.
Note InformationsLe comportement varie en fonction du mode de traitement des modifications :
En mode Application transactionnelle, les dernières modifications ne feront pas l'objet d'une tâche déplacé.
En mode Application avec optimisation par lots, il peut arriver que les données ne fassent pas l'objet d'une tâche déplacé du tout, ou qu'elles fassent l'objet d'une tâche déplacé partiellement uniquement.
- Arrêter la tâche : La tâche est arrêtée et une intervention manuelle est requise.
- Consigner l'enregistrement dans la table d'exceptions : La tâche se poursuit et l'enregistrement est écrit dans la table d'exceptions.
Erreurs de table
Lorsque vous rencontrez une erreur de table : sélectionnez l'un des éléments suivants dans la liste déroulante :
- Suspendre la table (par défaut) : la tâche se poursuit, mais les données de la table comportant l'enregistrement d'erreur passent à l'état d'erreur et ne sont pas répliquées.
- Arrêter la tâche : la tâche est arrêtée et une intervention manuelle est requise.
Remonter le traitement des erreurs lorsque les erreurs de table atteignent (par table) : cochez cette case pour faire remonter le traitement des erreurs lorsque le nombre d'erreurs de table (par table) atteint la quantité spécifiée. Les valeurs valides vont de 1 à 10 000.
Action de remontée : la stratégie de remontée des erreurs de table est définie sur Arrêter la tâche et ne peut pas être modifiée.
Conflits d'application
Enregistrement introuvable pour l'application de SUPPRIMER : sélectionnez l'action à entreprendre en cas de conflit avec une opération SUPPRIMER.
- Ignorer : la tâche se poursuit et l'erreur est ignorée.
- Consigner l'enregistrement dans la table d'exceptions : la tâche se poursuit et l'enregistrement est écrit dans la table d'exceptions.
- Suspendre la table : la tâche se poursuit, mais les données de la table comportant l'enregistrement d'erreur passent à l'état d'erreur et ne sont pas répliquées.
- Arrêter la tâche : la tâche est arrêtée et une intervention manuelle est requise.
Remonter le traitement des erreurs dans la hiérarchie lorsque des conflits d'application atteignent (par table) : cochez cette case pour faire remonter le traitement des erreurs lorsque le nombre de conflits d'application (par table) atteint la quantité spécifiée. Les valeurs valides vont de 1 à 10 000.
Action de remontée : Sélectionnez ce qui doit se produire en cas de remontée du traitement des erreurs :
- Consigner l'enregistrement dans la table d'exceptions (par défaut) : la tâche se poursuit et l'erreur est écrite dans la table d'exceptions.
Suspendre la table : la tâche se poursuit, mais les données de la table comportant l'enregistrement d'erreur passent à l'état d'erreur et ne sont pas répliquées.
Note InformationsLe comportement varie en fonction du mode de traitement des modifications :
En mode Application transactionnelle, les dernières modifications ne seront pas répliquées.
En mode Application avec optimisation par lots, il est possible qu'il n'y ait pas de réplication de données ou que la réplication de données soit partielle.
Arrêter la tâche : la tâche est arrêtée et une intervention manuelle est requise.
Erreurs d'environnement
Nombre maximal de nouvelles tentatives : Sélectionnez cette option, puis spécifiez le nombre maximal de nouvelles tentatives d'exécution d'une tâche en cas d'erreur d'environnement récupérable. Une fois que l'exécution de la tâche a été tentée le nombre de fois spécifié, la tâche est arrêtée et une intervention manuelle est requise.
Pour ne jamais retenter l'exécution d'une tâche, décochez la case ou spécifiez la valeur "0".
Pour retenter l'exécution d'une tâche un nombre infini de fois, spécifiez la valeur "-1".
Intervalle entre les nouvelles tentatives (secondes) : Utilisez le compteur pour sélectionner une valeur ou saisissez le nombre de secondes pendant lequel le système attend entre les tentatives de réexécution d'une tâche.
Les valeurs valides vont de 0 à 2 000.
- Augmenter l'intervalle de nouvelle tentative pour les longues interruptions : Cochez cette case pour augmenter l'intervalle de nouvelle tentative pour les longues interruptions. Lorsque cette option est activée, l'intervalle entre chaque nouvelle tentative et la suivante est multiplié par deux, jusqu'à atteindre l'Intervalle de nouvelle tentative maximal (et les tentatives se poursuivent conformément à l'intervalle maximal spécifié).
- Intervalle de nouvelle tentative maximal (secondes) : Utilisez le compteur pour sélectionner une valeur ou saisissez le nombre de secondes d'attente entre les tentatives de réexécution d'une tâche lorsque l'option Augmenter l'intervalle de nouvelle tentative pour les longues interruptions est activée. Les valeurs valides vont de 0 à 2 000.
Modifier le réglage du traitement
Réglage du déchargement des transactions
Décharger les transactions en cours sur le disque si :
La tâche de réplication conserve généralement les données de transaction en mémoire jusqu'à ce qu'elles soient entièrement validées dans la source et/ou la cible. En revanche, les transactions dont la taille est supérieure à la mémoire allouée ou qui ne sont pas validées dans le délai spécifié seront déchargées sur le disque.
- La taille de mémoire de transactions totale dépasse (Mo) : taille de mémoire maximale occupée par l'ensemble des transactions avant leur déchargement sur le disque. La valeur par défaut est 1 024.
- La durée des transactions dépasse (secondes) : durée maximale pendant laquelle chaque transaction peut rester en mémoire avant son déchargement sur le disque. La durée est calculée à partir du moment où la tâche de réplication démarre la capture de la transaction. La valeur par défaut est 60.
Réglage des lots
Les paramètres de cet onglet sont déterminés par le mode Appliquer les modifications.
Paramètres disponibles uniquement lorsque l'option « Mode d'application » est définie sur « Optimisation par lots »
- Appliquer les modifications par lots par intervalles :
Supérieur à : durée d'attente minimale entre chaque application de modifications par lots. La valeur par défaut est 1.
L'augmentation de la valeur Supérieurs à réduit la fréquence d'application des modifications à la cible tout en augmentant la taille des lots. Cela peut améliorer les performances lors de l'application de modifications à des bases de données cibles optimisées pour le traitement de lots volumineux.
- Inférieur à : durée d'attente maximale entre chaque application de modifications par lots (avant la déclaration d'une expiration de délai). En d'autres termes, il s'agit de la latence maximale acceptable. La valeur par défaut est 30. Cette valeur détermine la durée d'attente maximale avant l'application des modifications, une fois la valeur Supérieurs à atteinte.
Forcer l'application d'un traitement par lots lorsque la mémoire de traitement dépasse (Mo) : quantité maximale de mémoire à utiliser pour le prétraitement en mode Application avec optimisation par lots. La valeur par défaut est 500.
Pour une taille de lot maximale, définissez cette valeur sur la plus grande quantité de mémoire que vous puissiez allouer à la tâche de réplication. Cela peut améliorer les performances lors de l'application de modifications à des bases de données cibles optimisées pour le traitement de lots volumineux.
Paramètres disponibles uniquement lorsque l'option « Mode d'application » est définie sur « Transactionnel »
Les paramètres suivants sont disponibles uniquement lorsque vous travaillez en mode d'application « Transactionnel ». Notez que le mode « Transactionnel » est le seul mode d'application disponible (et donc non sélectionnable) lors de la réplication vers Snowflake, et que la Méthode de chargement est Snowpipe Streaming.
Nombre minimal de modifications par transaction : nombre minimal de modifications à inclure dans chaque transaction. La valeur par défaut est 1 000.
Note InformationsLes modifications seront appliquées à la cible SOIT lorsque le nombre de modifications est supérieur ou égal à la valeur Nombre minimal de modifications par transaction, SOIT lorsque la valeur Durée maximale de mise en lots des transactions avant application (secondes) décrite ci-dessous est atteinte - suivant la première occurrence. Étant donné que la fréquence des modifications appliquées à la cible est contrôlée par ces deux paramètres, il se peut que les modifications appliquées aux enregistrements sources ne soient pas immédiatement reflétées dans les enregistrements cibles.
- Durée maximale de mise en lots des transactions avant application (secondes) : durée de collecte maximale des transactions par lots avant la déclaration de l'expiration du délai. La valeur par défaut est 1.
Interval
Lire les modifications toutes les (minutes)
Intervalle de relevé des modifications de la source en minutes. La plage valide est comprise entre 1 et 1 440.
Note InformationsCette option est uniquement pour les tâches utilisant :
- Passerelle de déplacement des données
- Méthode de mise à jour Appliquer les modifications ou Stocker les modifications
Consulter les modifications
En fonction de l'intervalle d'extraction du delta : Lorsque cette option est sélectionnée, la tâche de données vérifie les modifications selon l'Intervalle d'extraction du delta.
Note InformationsL'intervalle commencera après chaque « cycle ». Un cycle peut être défini comme le temps nécessaire à la tâche de données pour lire les modifications des tables sources et les envoyer à la cible (sous la forme d'une seule transaction). La durée d'un cycle varie en fonction du nombre de tables et de modifications. Ainsi, si vous spécifiez un intervalle de 10 minutes et si un cycle prend 4 minutes, le temps réel entre les vérifications des modifications sera de 14 minutes.Intervalle d'extraction du delta : fréquence à laquelle les deltas seront extraits de votre système. La valeur par défaut est toutes les 60 secondes.
Comme planifié : lorsque cette option est sélectionnée, la tâche de données extraira le delta une seule fois, puis s'arrêtera. Elle continuera ensuite à s'exécuter comme planifié.
Note InformationsCette option n'est pertinente que si l'intervalle entre les cycles CDC est de 24 heures ou plus.Pour plus d'informations sur la planification :
« Tâches de réplication de données » dans un projet de réplication, consultez Planification de tâches
Réglage divers
Taille de cache des instructions (nombre d'instructions)
Nombre maximal d'instructions préparées à stocker sur le serveur pour une exécution ultérieure (lors de l'application des modifications à la cible). La valeur par défaut est 50. La valeur maximale est 200.
DELETE et INSERT lors de la mise à jour d'une colonne de clé primaire
Cette option est uniquement disponible lorsque le mode de réplication Stocker les modifications est activé, et elle requiert l'activation de la journalisation supplémentaire complète dans la base de données source.
Envoyer un message tombstone sur DELETE
Lorsque cette option est sélectionnée, seule la clé du message sera renseignée ; le message lui-même sera nul, indiquant que l'élément a été supprimé. Cela peut aider les consommateurs à détecter qu'une opération DELETE a été effectuée.
Enregistrer les données de récupération de la tâche dans la base de données cible
Sélectionnez cette option pour stocker les informations de récupération propres à la tâche dans la base de données cible. Lorsque cette option est sélectionnée, la tâche de réplication crée une table nommée attrep_txn_state dans la base de données cible. Cette table contient des données de transaction qui peuvent être utilisées pour récupérer une tâche en cas de corruption des fichiers du dossier Data Passerelle de déplacement des données ou d'échec du dispositif de stockage contenant le dossier Data.
Appliquer les modifications via SQL MERGE
Lorsque cette option n'est pas sélectionnée, la tâche de réplication exécute les instructions INSERT, UPDATE et DELETE distinctes en bloc pour chacun des types de modifications différents de la table Net Changes.
Même si cette méthode est très efficace, l'activation de l'option Appliquer les modifications via SQL MERGE s'avère encore plus efficace lors de l'utilisation de points de terminaison qui supportent cette option.
Cela s'explique par les raisons suivantes :
- Cela réduit de trois à une instruction le nombre d'instructions SQL exécutées par table de trois à une. La plupart des opérations UPDATE effectuées dans des bases de données cloud à base de fichiers immuables volumineuses (telles que Google Cloud BigQuery) impliquent la réécriture des fichiers affectés. Avec des opérations de ce type, la réduction des instructions SQL par table de trois à une est considérable.
- La base de données cible n'a besoin de scanner la table Net Changes qu'une seule fois, ce qui réduit considérablement les E/S.
Optimisation des insertions
Lorsque l'option Appliquer les modifications via SQL MERGE est sélectionnée avec l'option Optimiser les insertions et que les modifications sont constituées uniquement d'opérations INSERT, la tâche de réplication effectue des opérations INSERT au lieu d'opérations SQL MERGE. Notez que même si cela améliore généralement les performances et réduit par conséquent les coûts, cela peut produire également des enregistrements en double dans la base de données cible.
- Les options Appliquer les modifications via SQL MERGE et Optimiser les insertions sont disponibles pour les tâches configurées avec les points de terminaison cibles suivants uniquement :
- Google Cloud BigQuery
- Databricks
- Snowflake
- Les options Appliquer les modifications via SQL MERGE et Optimiser les insertions ne sont pas supportées avec les points de terminaison sources suivants :
- Salesforce
- Oracle
Lorsque l'option Appliquer les modifications via SQL MERGE est activée :
- Les erreurs de données non fatales ou les erreurs de données qui ne peuvent pas être rétablies seront traitées comme des erreurs de table.
- La Stratégie de traitement des erreurs de conflits d'applications ne pourra pas être modifiée avec les paramètres suivants.
- Enregistrement introuvable pour l'application de DELETE : Ignorer l'enregistrement
Dupliquer la clé lors de l'application de INSÉRER : METTRE À JOUR l'enregistrement cible existant
Note InformationsSi l'option Optimiser les insertions est également sélectionnée, l'option Dupliquer la clé lors de l'application de l'opération INSERT sera définie sur Autoriser les doublons dans les cibles.- Enregistrement introuvable pour l'application d'une MISE À JOUR : INSERT sur l'enregistrement cible manquant
- Action de remontée : Consigner l'enregistrement dans la table d'exceptions
- Les options Pour d'autres erreurs de données et Stratégie de traitement des erreur de données ne seront pas disponibles :
- Ignorer l'enregistrement
- Consigner l'enregistrement dans la table d'exceptions
- L'opération SQL MERGE effective sera effectuée uniquement sur les tables cibles finales. Les opérations INSERT seront effectuées sur les tables de modifications intermédiaires (lorsque le mode de réplication Appliquer les modifications ou Stocker les modifications est activé).
Application transactionnelle
Lors de la réplication dans des cibles de type entrepôt de données ou si vous travaillez sans Passerelle de déplacement des données, ces options ne s'appliquent pas, car le Mode d'application est toujours Optimisé par lots, à une exception près.
L'exception à cette règle se produit lorsque la réplication s'effectue vers Snowflake et que la Méthode de chargement est définie sur Snowpipe Streaming.
Les paramètres suivants sont disponibles uniquement lorsque vous travaillez en mode d'application Transactionnel. Lors de la réplication vers des bases de données, le Mode d'application peut être défini sur Optimisé par lots ou sur Transactionnel. Cependant, si la réplication s'effectue vers une cible Snowflake et si la Méthode de chargement est définie sur Snowpipe Streaming, le mode d'application est toujours Transactionnel et ne peut donc pas être défini.
Nombre minimal de modifications par transaction : nombre minimal de modifications à inclure dans chaque transaction. La valeur par défaut est 1 000.
Note InformationsLa tâche de réplication applique les modifications à la cible soit lorsque le nombre de modifications est supérieur ou égal à la valeur Nombre minimal de modifications par transaction, soit lorsque la valeur de délai d'expiration du lot est atteinte (voir ci-dessous) - suivant la première occurrence. Étant donné que la fréquence des modifications appliquées à la cible est contrôlée par ces deux paramètres, il se peut que les modifications appliquées aux enregistrements sources ne soient pas immédiatement reflétées dans les enregistrements cibles.- Durée maximale de mise en lots des transactions avant application (secondes) : durée de collecte maximale des transactions par lots avant la déclaration de l'expiration du délai. La valeur par défaut est 1.
Évolution automatique du schéma
Choisissez comment gérer les types suivants de modifications des DDL dans le schéma. Si vous avez modifié les paramètres d'évolution du schéma, vous devez préparer de nouveau la tâche. Le tableau ci-dessous décrit les actions disponibles pour les modifications des DDL supportées.
| Modification de DDL | Appliquer à la cible | Ignoré | Suspendre la table | Arrêter la tâche |
|---|---|---|---|---|
| Ajouter une colonne | Oui | Oui | Oui | Oui |
| Modifier le type de données de la colonne | Oui | Oui | Oui | Oui |
| Renommer la colonne | Oui | Non | Oui | Oui |
Renommer la table Note InformationsNon supporté lorsque Kafka est la plateforme cible. | Non | Non | Oui | Oui |
| Supprimer la colonne | Oui | Oui | Oui | Oui |
Abandonner la table Note InformationsNon supporté lorsque Kafka est la plateforme cible. | Oui | Oui | Oui | Oui |
| Créer une table Si vous avez utilisé une Règle de sélection pour ajouter des jeux de données correspondant à un pattern, les nouvelles tables répondant au pattern seront détectées et ajoutées. | Oui | Oui | Non | Non |
Substitution de caractère
Vous pouvez substituer ou supprimer des caractères sources dans la base de données cible et/ou vous pouvez substituer ou supprimer des caractères sources non pris en charge par un jeu de caractères sélectionné.
Tous les caractères doivent être spécifiés sous forme de points de code Unicode.
- La substitution de caractères sera également appliquée aux tables de contrôle.
Les valeurs non valides seront indiquées par un triangle rouge dans le coin supérieur droit de la cellule de table. Le survol du triangle à l'aide du curseur de la souris affichera le message d'erreur.
Toute transformation globale ou au niveau de la table définie pour la tâche sera effectuée à la fin de la substitution de caractères.
Les actions de substitution définies dans la table Substituer ou supprimer des caractères sources sont effectuées avant l'action de substitution définie dans la table Substituer ou supprimer des caractères sources non pris en charge par le jeu de caractères sélectionné.
- La substitution de caractères ne prend pas en charge les types de données LOB.
Substitution ou suppression de caractères sources
Utilisez la table Substituer ou supprimer des caractères sources pour définir les remplacements de caractères sources spécifiques. Cela peut s'avérer utile, par exemple, lorsque la représentation Unicode d'un caractère est différente sur les plates-formes source et cible. Par exemple, sous Linux, le caractère moins du jeu de caractères Shift_JIS est représenté par U+2212, alors que, sous Windows, il est représenté par U+FF0D.
| Pour | Procédez comme suit |
|---|---|
Définissez des actions de substitution. |
|
Édition du caractère source ou cible spécifié | Cliquez sur |
Suppression d'entrées de la table | Cliquez sur |
Substitution ou suppression de caractères sources non pris en charge par le jeu de caractères sélectionné
Utilisez la table Caractères sources non pris en charge par jeu de caractères pour définir un seul caractère de remplacement pour tous les caractères non pris en charge par le jeu de caractères sélectionné.
| Pour | Procédez comme suit |
|---|---|
Définir ou modifier une action de substitution. |
|
Désactiver l'action de substitution. | Sélectionnez l'entrée vide dans la liste déroulante Jeu de caractères. |
Autres options
Ces options ne sont pas exposées dans l'IU, car elles s'appliquent uniquement à des versions ou des environnements spécifiques. Par conséquent, n'activez pas ces options, sauf si Qlik Support ou la documentation produits vous le demande explicitement.
Pour activer une option, il suffit de la copier dans le champ Ajouter un nom de fonction et de cliquer sur Ajouter. Définissez ensuite la valeur ou activez l'option en fonction des instructions que vous avez reçues.
Chargement de segments de jeu de données en parallèle
Lors du chargement complet, vous pouvez accélérer le chargement de grands jeux de données en divisant le jeu de données en segments, qui seront chargés en parallèle. Les tables peuvent être divisées par plages de données, toutes les partitions, toutes les sous-partitions ou des partitions spécifiques.
Pour plus d'informations, consultez Réplication de segments de jeu de données en parallèle.
Planification de tâches
Dans certains cas, vous devrez peut-être planifier votre tâche pour propager les modifications de la source de données à la plateforme cible.
Pour plus d'informations, consultez Scheduling tasks.