Retirer des données de Redshift et les ajouter dans des fichiers S3
Procédure
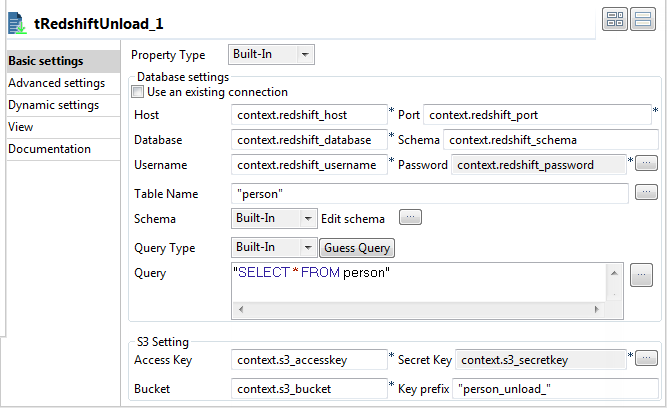
Double-cliquez sur le tRedshiftUnload pour ouvrir sa vue Basic settings dans l'onglet Component.
Renseignez les champs Host, Port, Database, Schema, Username et Password avec les variables de contexte correspondantes.
Renseignez les champs Access Key, Secret Key et Bucket avec les variables de contexte correspondantes.
Dans le champ Table Name, saisissez le nom de la table de laquelle lire les données. Dans cet exemple, saisissez person.
Cliquez sur le bouton [...] à côté du champ Edit schema et, dans la fenêtre qui s'ouvre, définissez le schéma en ajoutant deux colonnes : ID, de type Integer et Name, de type String.
Dans le champ Query, saisissez l'instruction SQL suivante à partir de laquelle les résultats seront retirés.
"SELECT * FROM person"
Dans le champ Key prefix, saisissez le préfixe du nom pour les fichiers à retirer. Dans cet exemple, saisissez person_unload_.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – faites-le-nous savoir.