Charger les données du fichier de S3 dans Redshift
Procédure
-
Double-cliquez sur le tRedshiftBulkExec pour ouvrir sa vue Basic settings dans l'onglet Component.
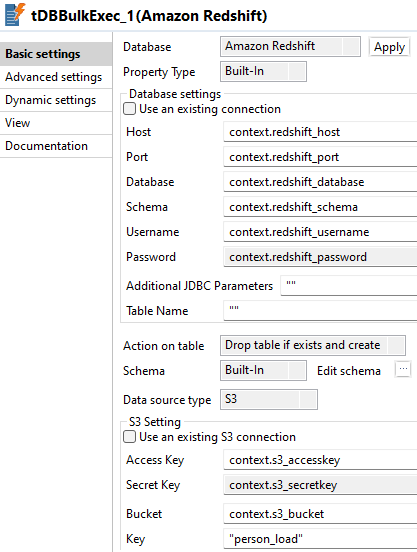
-
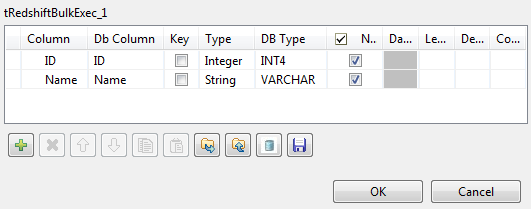
Cliquez sur le bouton [...] à côté du champ Edit schema et, dans la fenêtre qui s'ouvre, définissez le schéma en ajoutant deux colonnes : ID, de type Integer et Name, de type String.