
Almacenar conjuntos de datos
Puede almacenar los conjuntos de datos utilizando una tarea de almacenamiento de datos. La tarea de almacenamiento de datos consume los datos que una tarea de ubicación de destino aterrizó en el área de destino en la nube. Puede usar las tablas en una aplicación de análisis, por ejemplo.
-
Puede diseñar una tarea de almacenamiento de datos cuando el estado de la tarea de aterrizaje de datos esté al menos Listo para preparar.
-
Puede preparar una tarea de almacenamiento de datos cuando el estado de la tarea de aterrizaje de datos esté al menos Listo para ejecutar.
La tarea de almacenamiento de datos utilizará el mismo modo de operación (Carga completa o Carga completa y CDC) que la tarea de datos de destino consumidos. Las propiedades de configuración son diferentes entre los dos modos de funcionamiento, así como las opciones de supervisión y control. Si usa una tarea de aterrizaje de datos en la nube solo con carga completa, la tarea de almacenamiento de datos creará vistas para las tablas de aterrizaje en lugar de generar tablas físicas.
Además de almacenar tablas en el almacén de datos, también puede almacenar tablas como tablas Iceberg administradas por la plataforma de datos. Esta opción solo está disponible actualmente con los proyectos de Snowflake. Esto se hace seleccionando las tablas Iceberg administradas por Snowflake en Tipo de tabla en la configuración de la tarea.
Crear una tarea de almacenamiento de datos
Puede crear una tarea de almacenamiento de datos de tres formas:
-
Haga clic en ... en una tarea de aterrizaje de datos y seleccione Almacenar datos para crear una tarea de almacenamiento de datos basada en este activo de aterrizaje de datos.
-
En un proyecto de canalización, haga clic en Crear y, a continuación, en Almacenar datos. En este caso, deberá especificar qué tarea de aterrizaje de datos usar.
-
Cuando incorpora datos, se crea una tarea de almacenamiento de datos. Está conectado a la tarea de datos de destino/aterrizaje, que también se crea al embarcar los datos.
Para más información, vea Incorporar datos a un almacén de datos.
Cuando haya creado la tarea de almacenamiento de datos:
-
Abra la tarea de almacenamiento de datos haciendo clic en ... y seleccionando Abrir.
Se abre la tarea de almacenamiento de datos y puede obtener una vista previa de los conjuntos de datos de salida en función de las tablas del activo de aterrizaje de datos. -
Haga todos los cambios necesarios en los conjuntos de datos incluidos, como transformaciones, filtrado de datos o adición de columnas.
Para más información, vea Administrar conjuntos de datos.
-
Cuando haya agregado las transformaciones que desea, puede validar los conjuntos de datos haciendo clic en Validar conjuntos de datos. Si la validación encuentra errores, corríjalos antes de continuar.
Para más información, vea Validar y ajustar los conjuntos de datos.
-
Crear un modelo de datos
Haga clic en Modelo para establecer las relaciones entre los conjuntos de datos incluidos.
Para más información, vea Crear un modelo de datos.
-
Haga clic en Preparar para preparar la tarea de datos y todos los artefactos necesarios. Esto puede tomar un poco de tiempo.
Puede seguir el progreso en Progreso de la preparación en la parte inferior de la pantalla.
-
Cuando el estado muestra Listo para ejecución, puede ejecutar la tarea de datos.
Haga clic en Ejecutar.
La tarea de datos ahora comenzará a crear conjuntos de datos para almacenar los datos.
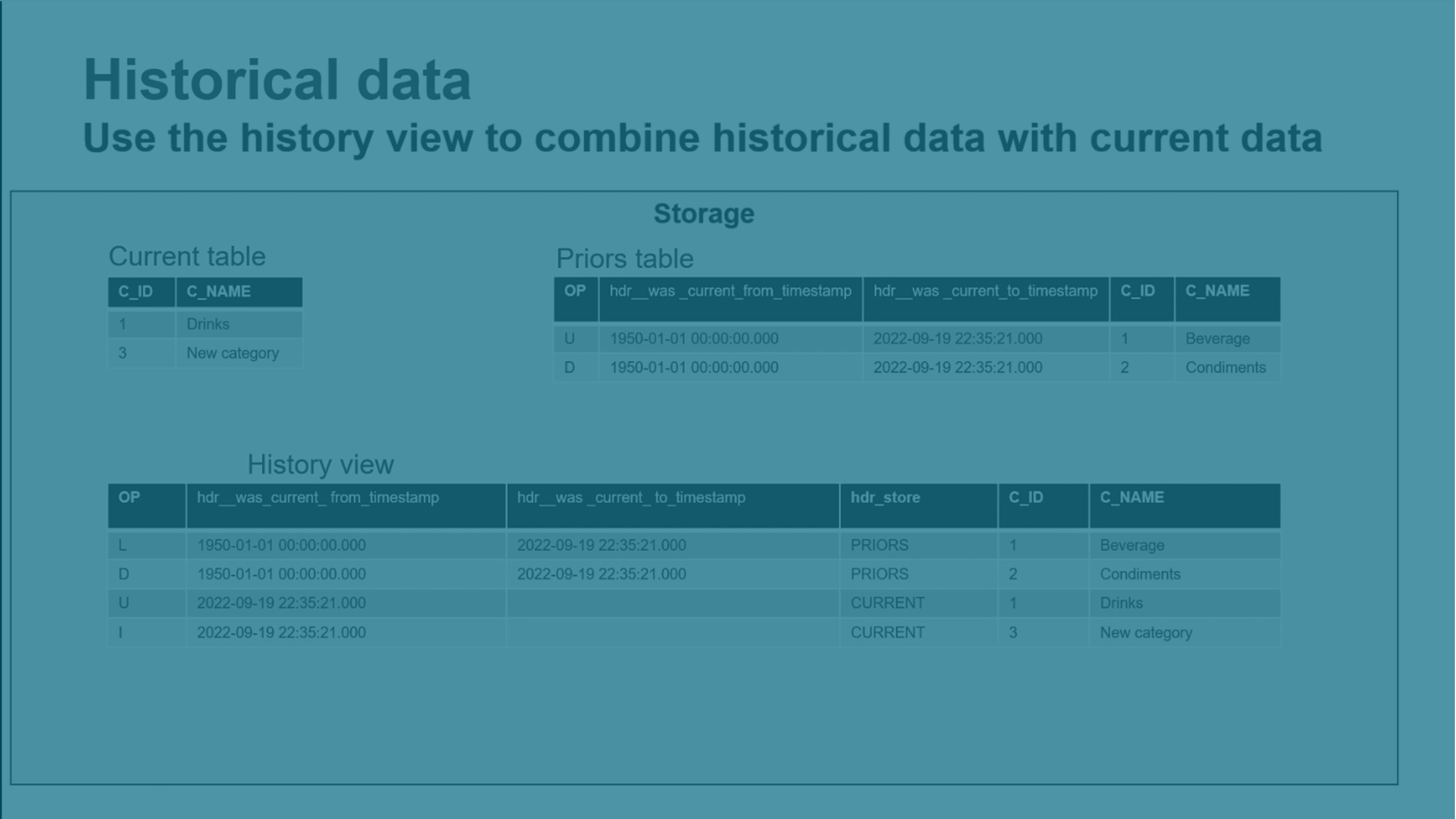
Mantener datos históricos
Puede conservar los datos de cambios históricos de tipo 2 para permitirle recrear fácilmente los datos tal como se veían en un punto específico en el tiempo. Esto crea un almacén de datos históricos completo (HDS).
-
Se admiten las dimensiones de cambio lento de tipo 2.
-
Cuando se fusiona un registro modificado, crea un nuevo registro para almacenar los datos modificados y deja intacto el registro anterior.
-
Los nuevos registros de HDS se marcan automáticamente con la hora, para permitirle crear análisis de tendencias y otros data marts analíticos orientados al tiempo.
Puede habilitar los datos históricos haciendo clic en:
-
Replicación con datos actuales y el historial de datos anteriores en Configuración cuando incorpora datos.
-
Mantener registros de cambios históricos y cambiar el archivo de registros en el cuadro de diálogo Configuración de una tarea de almacenamiento.
Los datos HDS se almacenan en la tabla anterior en el esquema de datos interno. Puede usar las vistas de historial y las vistas de historial en vivo en el esquema de datos externos para ver datos históricos.
-
La vista de historial combina datos de la tabla actual y la tabla anterior. Esta vista incluye todos los cambios que se fusionaron.
-
La vista de historial en vivo combina datos de la tabla actual, la tabla anterior y la tabla de cambios. Esta vista también incluye todos los cambios que aún no se fusionaron.
Para más información, vea Arquitectura de conjuntos de datos en un almacén de datos en la nube.
Almacenamiento
Programar una tarea de almacenamiento
Puede programar una tarea de almacenamiento para que se actualice periódicamente.
-
Si la tarea de entrada y aterrizaje de datos utiliza Carga completa y CDC, solo puede establecer una programación basada en el tiempo.
-
Si la tarea de entrada y aterrizaje de datos utiliza Carga completa, puede establecer una programación basada en el tiempo o configurar la tarea para que se ejecute cuando la tarea de entrada y aterrizaje de datos haya terminado de ejecutarse.
Nota informativaCuando ejecuta una programación basada en el tiempo con una tarea de entrada y aterrizaje de datos usando Carga completa, tenga en cuenta que todas las tablas completadas en el aterrizaje están disponibles mientras la tarea de aterrizaje aún se está ejecutando. Esto le permite ejecutar el aterrizaje y el almacenamiento al mismo tiempo, lo que puede mejorar el tiempo de carga total. -
Si el proyecto almacena datos en tablas Iceberg, puede establecer una programación o calendario basado en el tiempo, o configurar la tarea para que se ejecute cuando se cierre cualquier partición de datos de cambios.
Haga clic en ... en una tarea de datos y seleccione Programación para crear una programación. La configuración de programación predeterminada se hereda de la configuración del proyecto de canalización. Para obtener más información sobre la configuración predeterminada, vea Valores predeterminados de almacenamiento. Siempre debe establecer Programación en Activado para habilitar la programación.
Programaciones basadas en el tiempo
Puede utilizar una programación basada en el tiempo para ejecutar la tarea de almacenamiento de datos independientemente del tipo de aterrizaje.
-
Seleccione A una hora específica en Ejecutar la tarea de datos.
Puede establecer una programación por hora, diaria, semanal o mensual.
Programaciones basadas en eventos
-
Seleccione Al finalizar con éxito cualquier tarea de entrada de datos en Ejecutar la tarea de datos.
La tarea de almacenamiento se ejecutará cada vez que la tarea de entrada de datos de aterrizaje se haya completado con éxito.
Supervisar una tarea de almacenamiento
Puede supervisar el estado y el progreso de una tarea de almacenamiento haciendo clic en Supervisar.
Para más información, vea Supervisar una tarea individual de datos.
Resolución de problemas en una tarea de almacenamiento de datos
Cuando hay problemas con una o más tablas en una tarea de almacenamiento de datos, es posible que tenga que recargar o volver a crear los datos. Existen varias opciones para hacer esto. Considere qué opción utilizar en el siguiente orden:
-
Puede recargar el conjunto de datos en el aterrizaje. La recarga del conjunto de datos en el aterrizaje desencadenará el proceso de comparación en el almacenamiento y corregirá los datos conservando el historial de tipo 2. Esta opción también debe considerarse cuando:
-
La carga completa se realizó hace mucho tiempo y hay un gran número de cambios.
-
Si la carga completa y los registros de la tabla de cambios que se han procesado se han eliminado como parte del mantenimiento de la zona de aterrizaje.
-
-
Puede recargar datos durante la tarea de datos de almacenamiento.
Si los datos históricos están activados, una recarga en el almacenamiento puede causar una pérdida de datos históricos. Si esto es un problema, considere la posibilidad de volver a cargar el aterrizaje desde la fuente en su lugar.
-
Puede volver a crear las tablas. Esto vuelve a crear los conjuntos de datos a partir de la fuente.
-
Haga clic en ... y después clic en Volver a crear las tablas. Al volver a crear una tabla, la tarea posterior reaccionará como si se hubiera producido una acción de truncamiento y recarga en los conjuntos de datos de origen.
Nota informativaSi hay problemas con las tablas individuales, se recomienda intentar primero recargar las tablas en lugar de volver a crearlas. La recreación de tablas puede provocar una pérdida de datos históricos. Si hay cambios importantes, también debe preparar tareas de datos posteriores que consuman las tareas de los datos creados de nuevo para volver a cargar los datos.
-
Recargar datos
Puede realizar una recarga manual de las tablas. Esto resulta útil cuando hay problemas con una o más tablas.
-
Abra la tarea de datos y seleccione la pestaña Supervisar.
-
Seleccione las tablas que desea cargar.
-
Haga clic en Cargar tablas.
La recarga se producirá la próxima vez que se ejecute la tarea y se realiza de la siguiente manera:
-
Truncando las tablas.
-
Cargando los datos de aterrizaje en las tablas.
-
Cargando los cambios acumulados desde el momento de la recarga.
En general, lo mejor es recargar el conjunto de datos durante el aterrizaje. Esto es especialmente cierto en los siguientes casos:
-
Si los datos históricos están activados, una recarga en el almacenamiento puede causar una pérdida de datos históricos. La recarga del conjunto de datos en el aterrizaje desencadenará el proceso de comparación en el almacenamiento y corregirá los datos conservando el historial de tipo 2.
-
Cuando la carga completa se realizó hace mucho tiempo y hay un gran número de cambios.
-
Si la carga completa y los registros de la tabla de cambios que se han procesado se han eliminado como parte del mantenimiento de la zona de aterrizaje.
Las tareas posteriores se recargarán para aplicar los cambios y evitar la retroactivación. Si se realiza una recarga truncando y recargando, todos los objetos posteriores se recargarán también truncando y recargando.
Impacto en sentido descendente tras recargar una tarea de datos de aterrizaje o almacenamiento

El impacto en sentido descendente depende del tipo de operación de recarga ejecutada y del tipo de conjunto de datos inmediatamente posterior. El procesamiento estándar significa que el conjunto de datos reaccionará y procesará los datos utilizando el método configurado para el conjunto de datos específico.
-
En tareas de transformación posteriores:
Las transformaciones de conjuntos de datos se recargan truncando y cargando.
Las transformaciones de SQL y los flujos de transformación se recargan comparándolos con la carga completa y aplicando los cambios.
-
Las tareas del data mart inmediatamente posteriores a una tarea de almacenamiento se recargan truncando y cargando.
Puede cancelar la recarga de las tablas pendientes de recarga haciendo clic en Cancelar recarga. Esto no afectará a las tablas que ya estén recargadas, y las recargas que se estén ejecutando en ese momento se completarán.
Evolución del esquema
La evolución del esquema le permite detectar fácilmente cambios estructurales en múltiples fuentes de datos y luego controlar cómo se aplicarán esos cambios a su tarea. La evolución del esquema puede utilizarse para detectar cambios de DDL realizados en el esquema de datos de origen. También puede aplicar algunos cambios automáticamente.
Para cada tipo de cambio, puede seleccionar cómo administrar los cambios en la sección Evolución del esquema de la configuración de tareas. Puede aplicar los cambios, ignorarlos, suspender la tabla o detener el procesamiento de tareas.
Puede definir qué acción usar para gestionar los cambios en los DDL en cada tipo de cambio. Algunas acciones no están disponibles para todos los tipos de cambios.
-
Aplicar al objetivo
Aplica los cambios automáticamente.
-
Ignorar
Ignora los cambios.
-
Suspender tabla
Suspende la tabla. La tabla se mostrará como que da error en Supervisar.
-
Detener tarea
Detiene el procesamiento de la tarea. Esto es útil si desea manejar todos los cambios de esquema manualmente. Esto también detendrá la programación, es decir, no se realizarán las ejecuciones programadas.
Se admiten los siguientes cambios:
-
Añadir columna
-
Crear tabla que coincida con el patrón de selección
Si ha utilizado una regla de selección para añadir conjuntos de datos que coinciden con un patrón, se detectarán y añadirán nuevas tablas que cumplan el patrón.
Para más información sobre la configuración de tareas, consulte Evolución del esquema
Limitaciones en la evolución del esquema
Las siguientes limitaciones se aplican a la evolución del esquema:
-
La evolución de un esquema solo se admite cuando se utiliza CDC como método de actualización.
-
Cuando haya modificado las opciones de evolución del esquema, deberá preparar de nuevo la tarea.
-
Si cambia el nombre de las tablas, no se admitirá la evolución del esquema. En ese caso deberá actualizar los metadatos antes de preparar la tarea.
-
Si está diseñando una tarea, debe actualizar el navegador para recibir los cambios de evolución del esquema. Puede configurar notificaciones para recibir alertas sobre los cambios.
-
En las tareas de ubicación de destino/aterrizaje, no es posible soltar una columna. Si elimina una columna y la añade, se producirá un error en la tabla.
-
En las tareas de ubicación de destino o aterrizaje, una operación de soltar tabla no soltará la tabla. Si se elimina una tabla y luego se añade otra, solo se truncará la tabla antigua y no se añadirá una nueva tabla.
-
Modificar la longitud de una columna no es posible para todos los objetivos dependiendo del soporte en la base de datos de destino.
-
Si se cambia el nombre de una columna, las transformaciones explícitas definidas utilizando esa columna no surtirán efecto, ya que se basan en el nombre de la columna.
-
Las limitaciones para actualizar los metadatos también se aplican a la evolución de los esquemas.
-
Si una tarea contiene cambios de diseño que aún no se han preparado y se detectan cambios de evolución del esquema de origen cuando se ejecuta la tarea, la tarea se detendrá para evitar conflictos. Prepare los cambios de diseño pendientes y ejecute la tarea de nuevo.
Al capturar cambios DDL, se aplican las siguientes limitaciones:
-
Cuando se produce una secuencia rápida de operaciones en la base de datos de origen (por ejemplo, DDL>DML>DDL), Qlik Talend Data Integration podría analizar el registro en el orden incorrecto, lo que provocaría la falta de datos o un comportamiento impredecible. Para minimizar las posibilidades de que esto ocurra, la mejor práctica consiste en esperar a que los cambios se apliquen al objetivo antes de realizar la siguiente operación.
Como ejemplo de ello, durante la captura de cambios, si una tabla de origen se renombra varias veces en rápida sucesión (y la segunda operación la nombra de nuevo como su nombre original), puede producirse un error que indique que la tabla ya existe en la base de datos de destino.
- Si cambia el nombre de una tabla utilizada en una tarea y luego detiene la tarea, Qlik Talend Data Integration no capturará ningún cambio realizado en esa tabla después de reanudar la tarea.
-
No es posible renombrar una tabla de origen mientras una tarea está detenida.
- No se admite la reasignación de las columnas de clave primaria de una tabla (y, por tanto, no se escribirá en la tabla de control del historial de DDL).
- Cuando se cambia el tipo de datos de una columna y luego se cambia el nombre de la (misma) columna mientras la tarea está detenida, el cambio de DDL aparecerá en la tabla de control del Historial de DDL como "Soltar columna" y luego como "Añadir columna" cuando se reanude la tarea. Tenga en cuenta que el mismo comportamiento también puede producirse como resultado de una latencia prolongada.
- Las operaciones CREATE TABLE realizadas en el origen mientras una tarea está detenida se aplicarán en el destino cuando se reanude la tarea, pero no se registrarán como DDL en la tabla de control del Historial de DDL.
-
Las operaciones asociadas a cambios en los metadatos (como ALTER TABLE, reorg, reconstrucción de un índice agrupado, etc.) pueden provocar un comportamiento impredecible si se realizan:
-
Durante la carga completa
O bien:
-
Entre la hora especificada en Comenzar a procesar cambios desde y la hora actual (es decir, el momento en que el usuario hace clic en Aceptar en el cuadro de diálogo Opciones de ejecución avanzadas ).
Ejemplo:
SI:
La hora especificada para Comenzar a procesar cambios desde son las 10:00 horas.
Y:
Se ha añadido una columna denominada Edad a la tabla de Empleados a las 10:10 horas.
Y:
El usuario hace clic en Aceptar en el cuadro de diálogo Opciones de ejecución avanzadas a las 10:15 horas.
ENTONCES
Los cambios ocurridos entre las 10:00 y las 10:10 pueden provocar errores en el CDC.
Nota informativaEn cualquiera de los casos anteriores, la(s) tabla(s) afectada(s) deberá(n) recargarse para que los datos se transfieran o desplazado correctamente al destino.
-
- La sentencia
ALTER TABLE ADD/MODIFY <column> <data_type> DEFAULT <>del DDL no replica el valor por defecto en el destino y la columna nueva/modificada se establece en NULL. Tenga en cuenta que esto puede ocurrir incluso si el DDL que añadió/modificó la columna se ejecutó en el pasado. Si la columna nueva/modificada es anulable, el punto final de origen actualiza todas las filas de la tabla antes de registrar el propio DDL. Como resultado, Qlik Talend Data Integration captura los cambios pero no actualiza el destino. Como la columna nueva/modificada se establece en NULL, si la tabla de destino no tiene clave primaria/índice único, las actualizaciones posteriores generarán un mensaje de "cero filas afectadas". -
Las modificaciones de las columnas de precisión TIMESTAMP y DATE no se capturarán.
Ver la información de la tarea
Haga clic en ![]() en la barra de menú para ver la información de la tarea, como:
en la barra de menú para ver la información de la tarea, como:
-
Propietario
-
Espacio
-
Plataforma de datos
-
ID de proyecto
-
ID del tiempo de ejecución de la tarea de datos
Configuración de almacenamiento
Puede establecer propiedades para la tarea de almacenamiento de datos cuando la plataforma de datos es un almacén de datos en la nube. Si utiliza Qlik Cloud como plataforma de datos, vea Configuración del almacenamiento para proyectos con Qlik Cloud como plataforma de datos.
-
Haga clic en Configuración.
Configuración general
-
Base de datos
Base de datos que se utilizará en el origen de datos.
-
Esquema de tarea
Puede cambiar el nombre del esquema de la tarea de almacenamiento de datos. El nombre predeterminado es el nombre de la tarea de almacenamiento.
-
Esquema interno
Puede cambiar el nombre del esquema de activos de datos de almacenamiento interno. El nombre predeterminado es el nombre de la tarea de almacenamiento con el sufijo _internal adjunto.
-
Mayúsculas por defecto en el nombre del esquema
Puede establecer el uso de mayúsculas por defecto para todos los nombres de esquema. Si su base de datos está configurada para obligar al uso de mayúsculas, esta opción no tendrá efecto.
- Prefijo para todas las tablas y vistas
Puede establecer un prefijo para todas las tablas y vistas creadas con esta tarea.
Nota informativaDebe usar un prefijo único cuando desee usar un esquema de base de datos en varias tareas de datos. -
Historial
Puede conservar los datos de cambios históricos para permitirle recrear fácilmente los datos tal y como se veían en un punto específico en el tiempo. Puede usar las vistas del historial y las vistas del historial en vivo para ver los datos históricos. Seleccione Mantener registros históricos y el archivo de registro de cambios para habilitar los datos de cambios históricos.
-
Al comparar el almacenamiento con el aterrizaje en destino, puede elegir cómo administrar los registros que no existen en el destino.
-
Marcar como eliminado
Esto realizará una eliminación temporal de los registros que no existen en el destino.
-
Mantener
Esto mantendrá todos los registros que no existen en el rellano.
Nota informativaLos conjuntos de datos en la tarea de almacenamiento de datos deben tener un conjunto de claves principales. De lo contrario, cada vez que se vuelvan a cargar los datos de ubicación temporal, se realizará una carga inicial en la tarea de almacenamiento de datos. -
-
Publicar en el catálogo
Seleccione esta opción para publicar esta versión de los datos en el Catálogo como un conjunto de datos. El contenido del catálogo se actualizará la próxima vez que prepare esta tarea.
Para obtener más información sobre el catálogo, consulte Comprender sus datos con las herramientas del catálogo.
Configuración de vistas
-
Vistas en vivo
Utilice las vistas en vivo para leer las tablas con la menor latencia.
Para obtener más información sobre las vistas en vivo, consulte Usar vistas en vivo.
Nota informativaLas vistas en vivo son menos eficientes que las vistas estándar y requieren más recursos, ya que los datos aplicados se han de recalcular.
Ajustes del tipo de vista
La configuración del tipo de vista solo es aplicable para Snowflake.
-
Vistas estándar
Utilice las vistas estándar en la mayoría de los casos.
-
Vistas seguras de Snowflake
Utilice las vistas seguras de Snowflake para aquellas vistas que precisen protección de la privacidad de datos o de la información sensible, como las vistas creadas para limitar el acceso a datos sensibles que no deban estar expuestos a todos los usuarios de las tablas.
Nota informativa Las vistas seguras de Snowflake pueden ejecutarse más lentamente que las vistas Estándar.
Configuración de tiempo de ejecución
-
Ejecución en paralelo
Puede establecer el número máximo de conexiones para cargas completas en un número del 1 al 5.
-
Almacén
El nombre del almacén de datos en la nube. Esta configuración solo se aplica a Snowflake.
Ajustes del tipo de tabla
Estos ajustes solo están disponibles en proyectos con Snowflake como plataforma de datos.
-
Tipo de tabla
Puede seleccionar el tipo de tabla que desea utilizar:
-
Tablas de Snowflake
-
Tablas Iceberg gestionadas por Snowflake
Debe establecer el nombre predeterminado del volumen externo en Volumen externo de Snowflake.
-
-
Carpeta de almacenamiento en la nube que usar
Seleccione la carpeta que se utilizará para el destino/aterrizaje de los datos.
-
Carpeta predeterminada
Esto crea una carpeta con el nombre predeterminado: <nombre de proyecto>/<nombre de la tarea de datos>.
-
Carpeta raíz
Almacene los datos en la carpeta raíz del almacenamiento.
-
Carpeta
Especifique un nombre de carpeta que usar.
-
-
Sincronizar con el catálogo abierto de Snowflake
Actívelo para permitir que Snowflake Open Catalog gestione los archivos del almacenamiento de archivos en la nube.
Evolución del esquema
Seleccione cómo manejar los siguientes tipos de cambios de DDL en el esquema. Cuando haya modificado las opciones de evolución del esquema, deberá preparar de nuevo la tarea. La tabla siguiente describe las acciones disponibles para los cambios de DDL admitidos.
| Cambio de DDL | Aplicar al objetivo | Ignorar | Detener tarea |
|---|---|---|---|
| Añadir columna | Sí | Sí | Sí |
| Crear tabla
Si ha utilizado una regla de selección para añadir conjuntos de datos que coinciden con un patrón, se detectarán y añadirán nuevas tablas que cumplan el patrón. |
Sí | Sí | Sí |
Configuración del almacenamiento para proyectos con Qlik Cloud como plataforma de datos
Puede establecer qué carpeta usar en el almacenamiento cuando la plataforma de datos sea Qlik Cloud como plataforma de datos.
-
Haga clic en Configuración.
-
Seleccione qué carpeta usar en el almacenamiento.
-
Haga clic en Aceptar cuando esté listo.
Operaciones en la tarea de almacenamiento de datos
Puede realizar las siguientes operaciones en una tarea de almacenamiento de datos desde el menú de tareas.
-
Abrir
Esto abre la tarea de almacenamiento de datos. Puede ver la estructura de la tabla y los detalles sobre la tarea de datos y supervisar el estado de la carga completa y los lotes de cambios.
-
Editar
Puede editar el nombre y la descripción de la tarea y agregar etiquetas.
-
Eliminar
Puede eliminar la tarea de datos si no se está ejecutando y no hay dependencias de tareas posteriores en el mismo proyecto.
-
En la vista Proyecto de canalización del proyecto, haga clic en
 en una tarea y seleccione Eliminar.
en una tarea y seleccione Eliminar.
Los artefactos (tablas y vistas) creados por la tarea también se eliminarán, a menos que elija conservarlos.
Nota informativaTenga en cuenta que los artefactos que conserve ya no serán actualizados por la tarea. -
-
Preparar
Esto prepara la tarea para su ejecución. Esto incluye:
-
Validar que el diseño sea válido.
-
Crear o modificar las tablas físicas y las vistas para que coincidan con el diseño.
-
Generar el código SQL para la tarea de datos.
-
Crear o modificar las entradas de catálogo para los conjuntos de datos de salida de la tarea.
Puede seguir el progreso en Progreso de la preparación en la parte inferior de la pantalla.
-
-
Validar conjuntos de datos
Esto valida todos los conjuntos de datos que están incluidos en la tarea de datos.
Amplíe Validar y ajustar para ver todos los errores de validación y cambios en el diseño.
-
Volver a crear las tablas
Esto vuelve a crear los conjuntos de datos a partir de la fuente. Al volver a crear una tabla, la tarea posterior reaccionará como si se hubiera producido una acción de truncamiento y recarga en los conjuntos de datos de origen. Para más información, vea Resolución de problemas en una tarea de almacenamiento de datos.
-
Detener
Puede detener el funcionamiento de la tarea de datos. La tarea de datos no continuará actualizando las tablas.
Nota informativaEsta opción está disponible cuando se está ejecutando la tarea de datos. -
Reiniciar
Puede reanudar la operación de una tarea de datos desde el punto en que se detuvo.
Nota informativaEsta opción está disponible cuando se detiene la tarea de datos. -
Transformar datos
Cree transformaciones de nivel de fila reutilizables basadas en reglas y SQL personalizado. Esto crea una tarea de Transformación de datos.
-
Crear data mart
Cree un data mart para aprovechar sus tareas de datos. Esto crea una tarea de datos de Data Mart.
Limitaciones
-
Si la tarea de datos contiene conjuntos de datos y cambia cualquier parámetro en la conexión, por ejemplo, el nombre de usuario, la base de datos o el esquema, se supone que los datos existen en la nueva ubicación. Si este no fuera el caso, puede elegir una de la opciones siguientes:
-
Mueva los datos desde el origen a la nueva ubicación.
-
Cree una nueva tarea de datos con la misma configuración.
-
-
No es posible cambiar claves principales en tareas de almacenamiento en proyectos con Qlik Cloud (QVD) como destino. Actualice las claves principales en la tarea de aterrizaje, vuelva a crear la tarea de aterrizaje y luego vuelva a crear la tarea de almacenamiento.
-
Al utilizar el almacenamiento de Iceberg, las columnas de datos JSON se almacenarán como STRING.